前言
概率分布(probability distribution)是给出事件发生的概率的函数,它是一种通过样本空间(sample space)和事件的概率描述随机事件的方式,下面有一些需要了解到的概念
边缘分布
假设有一个和两个变量相关的概率分布 p(x,y) ,关于其中一个特定变量的边缘分布则为给定其他变量的条件概率分布如下
p(x)=y∑p(x,y)=y∑p(x∣y)p(y)
偏度
偏度(Skewness)衡量数据分布的对称性,计算公式如下
Skewness=σ3E[(x−μ)3]
- μ 是均值
- σ 是标准差
- E 是期望值
- Skewness=0 分布对称
- Skewness>0 分布右偏,右侧尾部长
- Skewness<0 分布左偏,左侧尾部长
峰度
峰度(Kurtosis)反映数据分布的尖锐程度和尾部厚度
Kurtosis=σ4E[(x−μ)4]
- Kurtosis=3 正态分布的峰度
- Kurtosis>3 分布更尖锐,尾部更厚
- Kurtosis<3 分布更平坦,尾部更薄
离散均匀分布
离散均匀分布(Discrete Uniform Distribution) 是最简单的离散概率分布之一,描述了一个随机变量在有限个取值上具有相同概率的情况
离散均匀分布的概率质量函数
f(X=x)=n1x=x1,...xn
- X 是随机变量,取值为 x1,…xn
- n 是取值的个数
- 每个取值的概率相等,均为 n1
对于取值是连续的整数,例如 x=a,a+1,…b ,则概率质量函数可以表示为
f(X=x)=b−a+11x=a,a+1,…b
性质
- 期望值为 E[X]=n1∑inxi
- 方差为 Var(X)=n1∑in(xi−E[X])2
- 离散均匀分布是对称的,即所有取值的概率相等
- 离散均匀分布是连续均匀分布的离散版本
- 当多项分布的所有类别概率相等时,退化为离散均匀分布
连续均匀分布
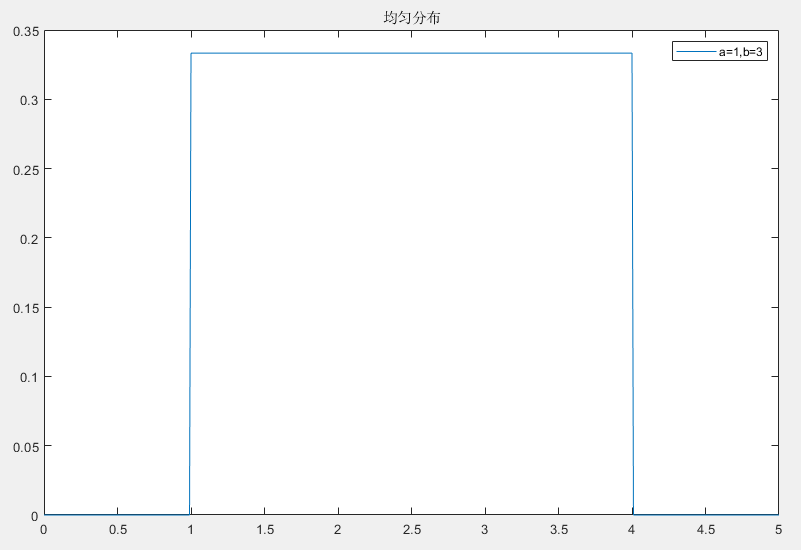
连续均匀分布(Continuous Uniforom Distribution)是概率论中最简单且常见的概率分布之一,它描述了一个随机变量在一定区间内取值的概率是均匀的
连续均匀分布的概率密度函数
连续均匀分布定义在一个区间 [a,b] 中,随机变量在该区间内取值的概率密度是常数
f(x)=⎩⎪⎨⎪⎧b−a10如果x∈[a,b]其他
- a 是区间下限, b 是区间上限, b>a
性质
- 期望值为 E[X]=2a+b
- 方差 Var(X)=12(b−a)2
- 累积分布函数 F(x)=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧0b−ax−a1x<ax∈[a,b]x>b
- 形状:概率密度在 [a,b] 区间上是平坦的,区间外为 0
伯努利分布
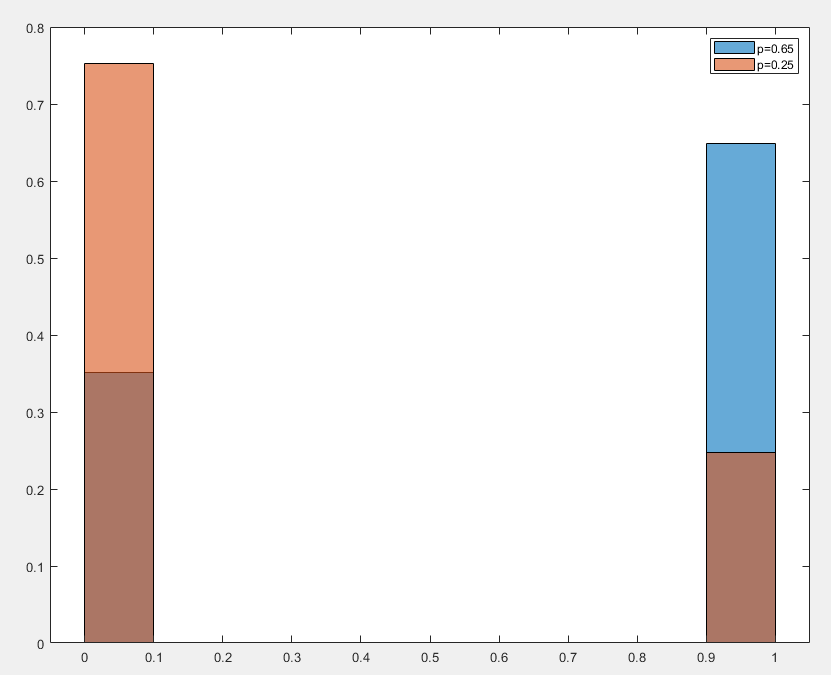
伯努利分布(Bernoulli Distribution) 是概率论中最简单的离散概率分布之一,用于描述只有两种可能结果的随机试验
定义
伯努利分布描述了一个随机试验,结果只有两种可能,其概率质量函数为
p(x)={p1−px=1x=0
- x 是随机变量,只能取 0 或 1
- p 是成功的概率 0≤p≤1
性质
- 期望值为 E[X]=p
- 方差为 Var(X)=p(1−p)
- 偏度为 Skewness=p(1−p)1−2p
- 峰度为 Kurtosis=p(1−p)1−3p(1−p)
高斯分布
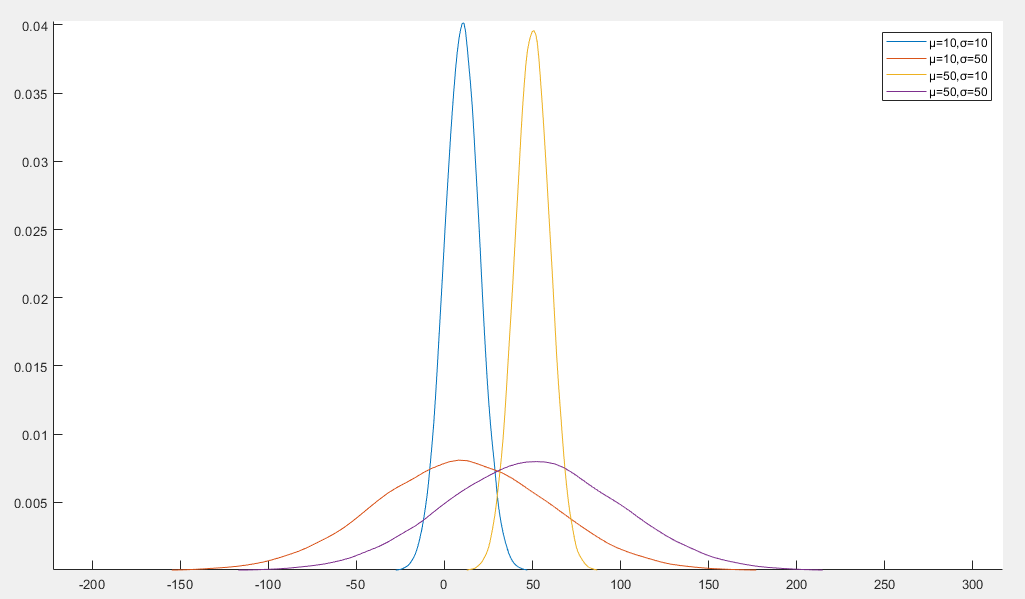
高斯分布(Gaussian Distribution)又称为正态分布(Normal Distribution)
概率密度函数
f(x)=2πσ21exp(−2σ2(x−μ)2)
- μ 是均值,决定分布的中心值
- σ2 是方差
性质
- 对称性:关于均值对称
- 钟形曲线:呈单峰钟形,峰值在 x=μ 处
- 标准正态分布的累积分布函数为 Φ(x)=2π1∫−∞xe−t2/2dt
- 高斯分布的累积分布函数为 F(x)=Φ(σx−μ)
- 有 68% 在 μ±σ 内
- 有 95% 在 μ±2σ 内
- 有 99.7% 在 μ±3σ 内
- 线性变换:若 x∼N(μ,σ2) 则 aX+b∼N(aμ+b,a2σ2)
标准正态分布
当 μ=0 且 σ=1 时称为标准正态分布,概率密度函数为
f(x)=2π1exp(−2x2)
混合高斯分布
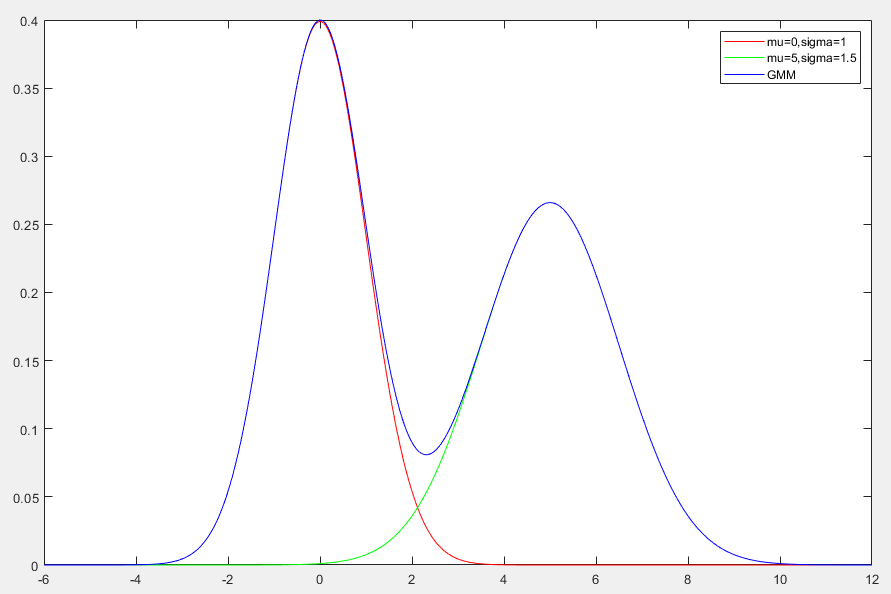
混合高斯分布(Gaussian Mixture Model, GMM)是由多个高斯分布线性组合而成的概率分布,常用于对复杂数据分布的建模
概率密度函数
p(x)=k∑KπkN(x∣μk,Σk)
- K 是高斯分布的数量
- πk 是第 k 个高斯分布的混合系数(权重),满足 ∑kKπk=1,πk≥0
- N(x∣μk,Σk) 是第 k 个高斯分布的概率密度函数, μk 是均值, Σk 是协方差
性质
- 期望值为 E[X]=∑kKπkμk
- 协方差矩阵为 Cov(X)=∑kKπk(Σk+(μk−E[X])(μk−E[X])T)
- 灵活性:通过调整高斯分布的数量 K 和参数,可以模拟各种复杂分布
- 多峰性:混合高斯分布可以描述多峰数据,而单一高斯分布只能描述单峰数据
多元高斯分布
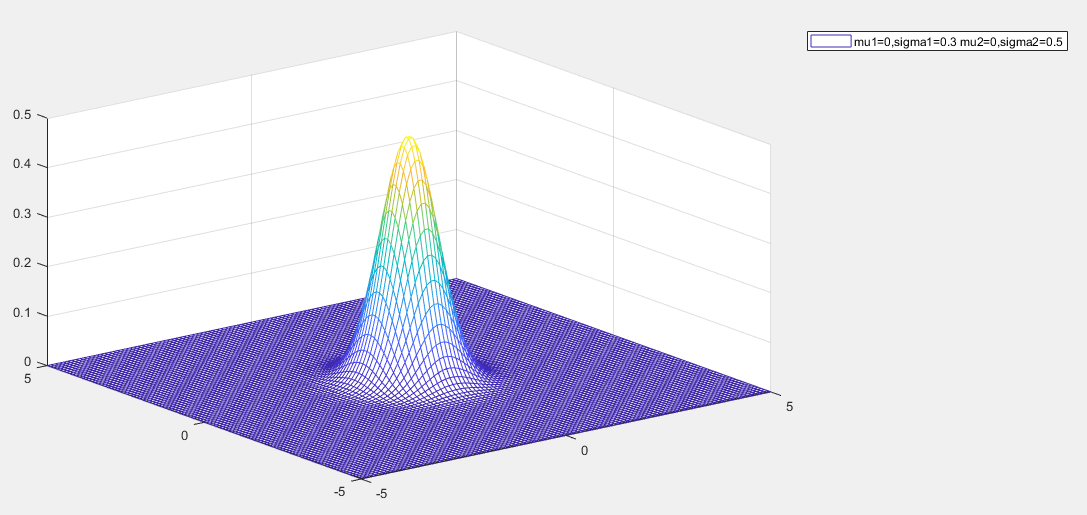
多元高斯分布(Multivariate Gaussian Distribution)是单变量高斯分布在多维空间中的推广,用于描述多个随机变量的联合分布
概率密度函数
p(x)=(2π)n/2∣Σ∣1/21exp(−21(x−μ)TΣ−1(x−μ))
- x 是 n 维随机向量
- μ 是均值向量,表示各变量的期望值
- Σ 是协方差矩阵
- ∣Σ∣ 是协方差矩阵的行列式
性质
- 均值向量 μ 决定分布的中心位置
- 协方差矩阵 Σ 控制分布的形态和方向
- 若协方差矩阵为对角矩阵,变量间相互独立
- 对多元高斯随机向量进行线性变换,结果仍为多元高斯分布
瓦尔德分布
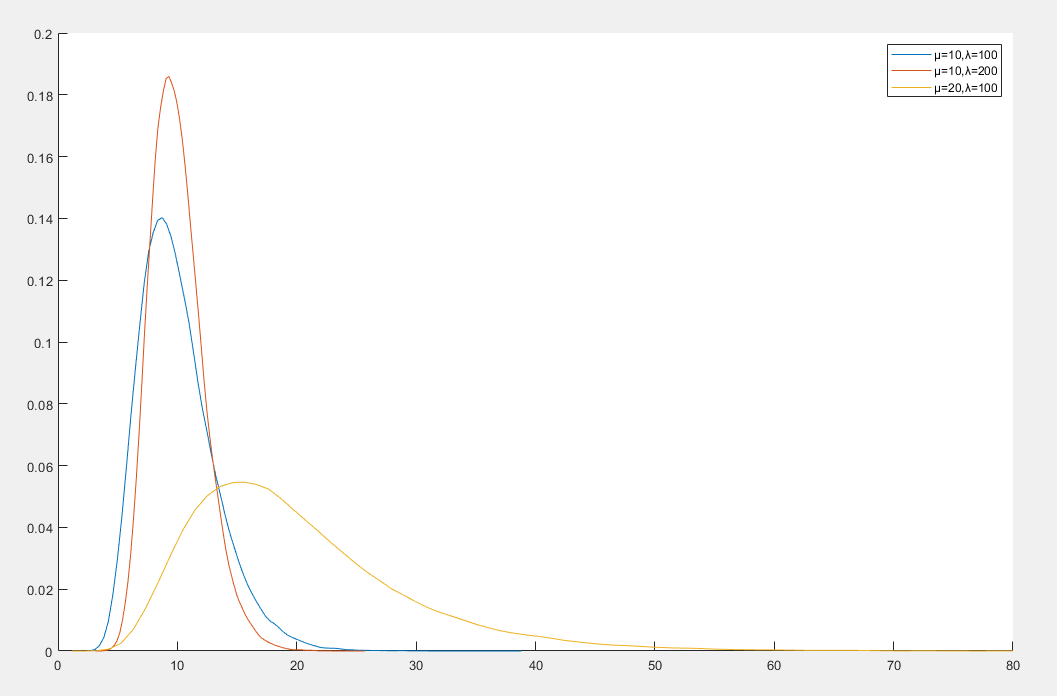
瓦尔德分布(Wald Distribution)也称为逆高斯分布(Inverse Gaussian Distribution),是一种连续概率分布,常用于描述正偏态数据
瓦尔德分布的概率密度函数
f(x)=2πx3λexp(−2μ2xλ(x−μ)2)x>0
- x 是随机变量
- μ 是均值
- λ 是形状参数
性质
- 期望值为 E[X]=μ
- 方差为 Var(X)=λμ3
- 瓦尔德分布描述了布朗运动首次达到某一固定水平的时间分布
- 可加性:对于两个独立的瓦尔德分布随机变量 X1∼Wald(μ1,λ1) 和 X2∼Wald(μ2,λ2) ,则它们的和也服从瓦尔德分布 X1+X2∼Wald(μ1+μ2,(λ1−1+λ2−1)−1)
- 当 λ→∞ 时,瓦尔德分布趋近于正态分布
- 瓦尔德分布与伽马分布有相似的性质,但瓦尔德分布更适合描述正偏态数据
卡方分布
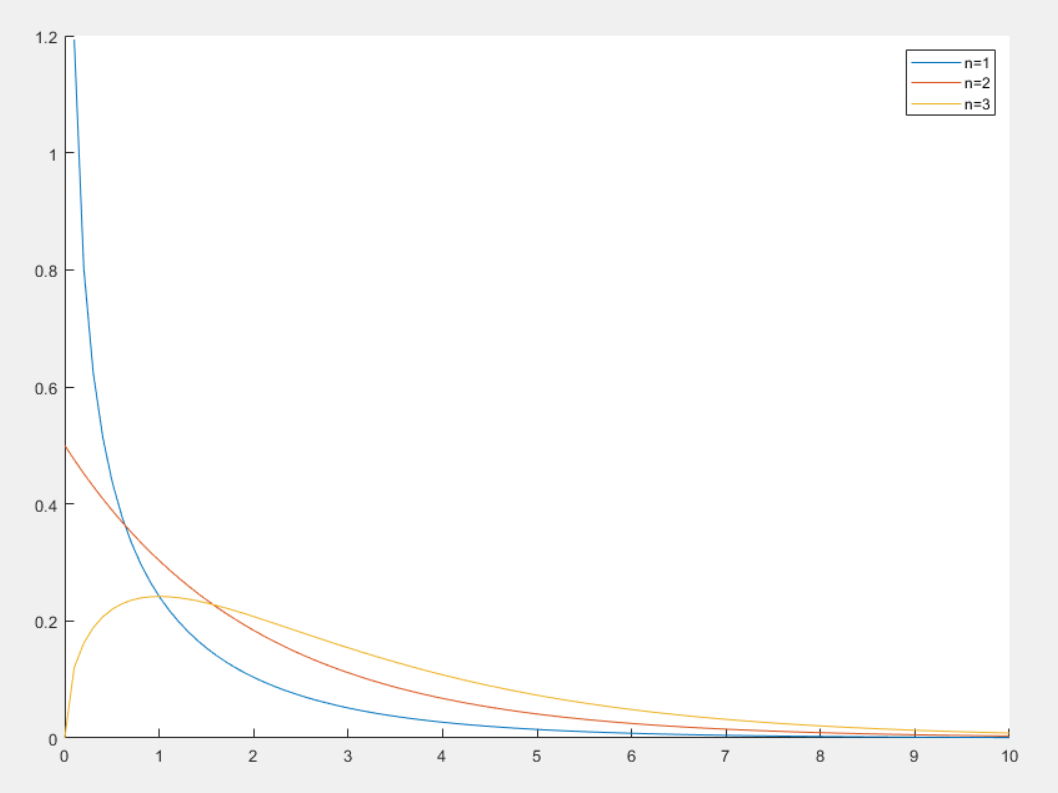
卡方分布(Chi-Square Distribution)是概率论与统计学中常用的一种连续概率分布,常用于假设检验和置信区间的计算
定义
设 x1,…xn∼N(0,1) ,令 X=∑inxi2 ,则称 X 是自由度为 n 的 χ2 分布,记作 X∼χ2
对于随机变量 X∼χ2 ,其概率密度函数如下
f(x)=⎩⎪⎪⎨⎪⎪⎧22nΓ(2n)x2n−1e−2x0x>0x≤0
其中 Γ(x)=∫0∞tx−1e−tdt(x>0)
性质
- 卡方分布的定义域为 x>0 ,卡方随机变量总是非负的
- 期望值为 E[X]=n
- 方差为 Var(X)=2n
- 当自由度 n 较小时,卡方分布右偏,随着 n 增大,分布逐渐对称并接近正态分布
- 对于随机变量 X∼χn2 有 E(X)=n,Var(X)=2n
- 对于两个随机变量 Z1∼χn12 和 Z2∼χn22 ,并且两个随机变量相互独立,则 Z1+Z2∼χn1+n22
- 当 n→∞ 时,卡方分布趋近于正态分布 N(n,2n)
t 分布
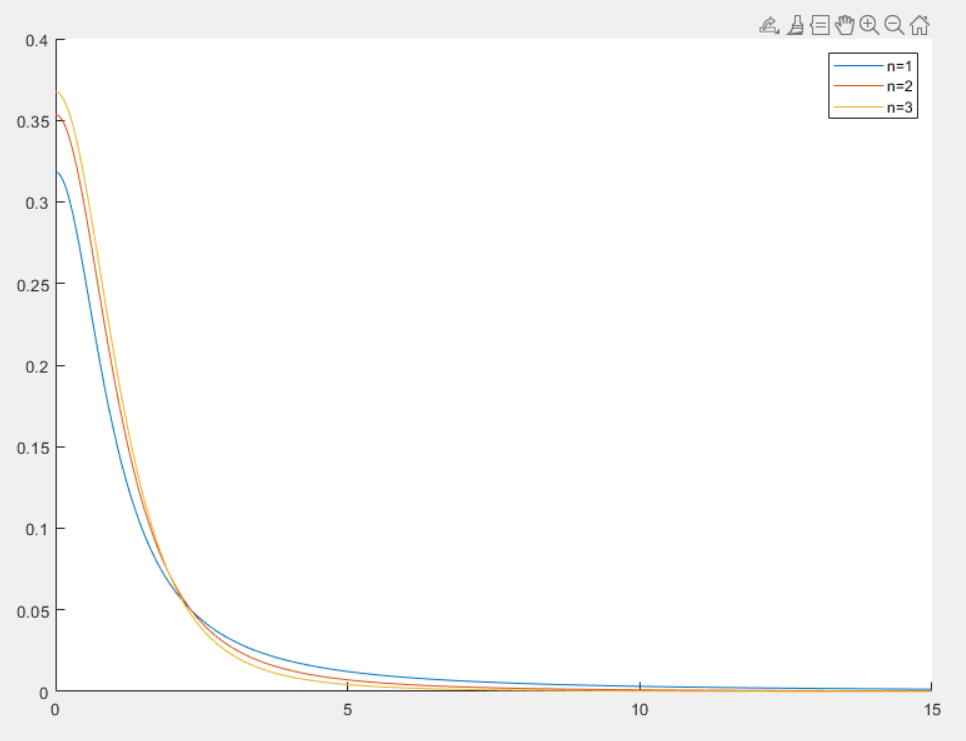
t 分布(Student’s t-distribution)是统计学中常用的一种连续概率分布,主要用于小样本情况下的假设检验和置信区间估计
定义
设随机变量 X∼N(0,1) 和 Y∼χn2 ,且 X 和 Y 独立,则称
T=nYX
为自由度 n 的 t 变量,其分布称为自由为 n 的 t 分布,记作 T∼tn
对于随机变量 T∼tn ,其密度函数如下
f(x)=Γ(2n)nπΓ(2n+1)(1+nx2)−2n+1x∈(−∞,+∞)
性质
- 期望值为 E[T]=0n>1
- 方差为 Var(T)=n−2nn>2 ,否则方差不存在
- 对于随机变量 T∼tn ,则当 n≥2 时,均值 E(T)=0 。当 n≥3 时,方差 Var(T)=n−2n
- 当 n→∞ 时,t 变量的极线分布为 N(0,1)
F 分布
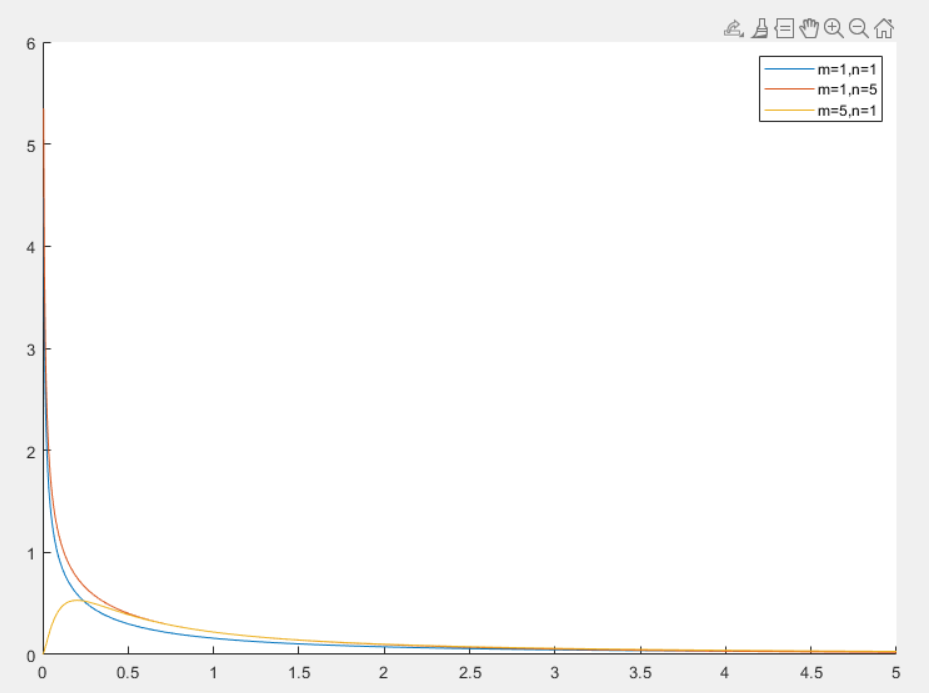
F 分布(F-distribution)是统计学中常用的一种连续概率分布,主要用于比较两个样本方差的分布情况
定义
对于两个随机变量 X∼χm2 和 Y∼χn2 ,并且两个变量相互独立,则称
F=Y/nX/m
为自由度分别是 m 和 n 的 F 变量,其分布称为自由度分别是 m 和 n 的 F 分布,记作 F∼Fm,n
对于随机变量 X∼Fm,n 其概率密度函数如下
fm,n(x)=⎩⎪⎪⎨⎪⎪⎧Γ(2n)Γ(2m)Γ(2m+n)m2mn2nx2m−1(n+mx)−2m+n0x>0x≤0
性质
- 期望值为 E[F]=n−2nn>2
- 方差为 Var(F)=m(n−2)2(n−4)2n2(m+n−2)n>4
- 若 X∼Fm,n 则 X1∼Fn,m
- 若 X∼tn 则 X2∼F1,n
- Fm,n(1−α)=Fn,m(α)1
- 当 m 和 n 较小时,分布偏右,随着逐渐增大,分布逐渐对称
二项分布
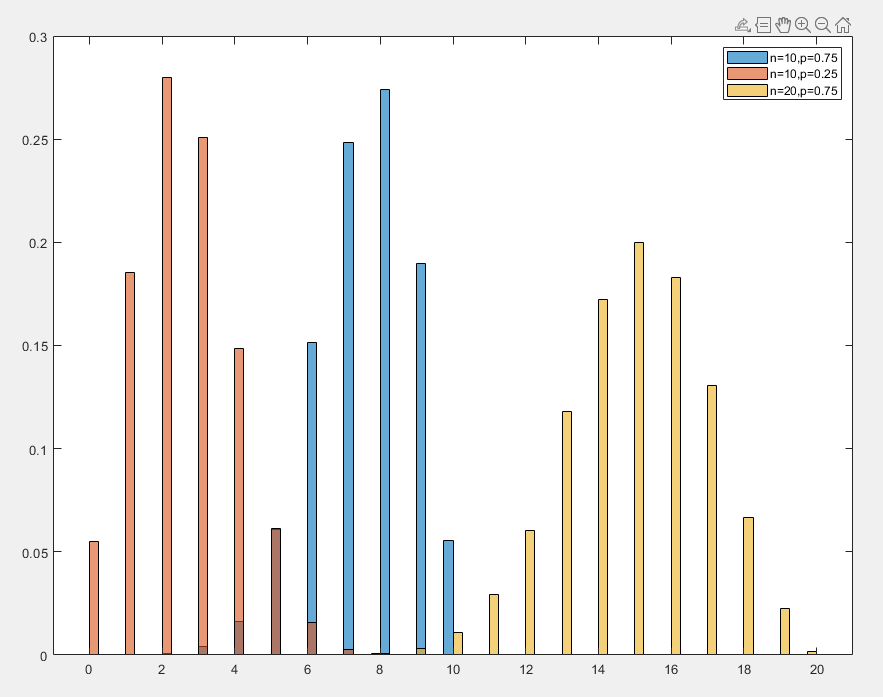
二项分布(Binomial Distribution)是一种离散概率分布,用于描述在 n 次独立实验中,某事件正好发生 k 次的概率。对于一个随机变量 X ,如果其满足二项分布,则称其 X∼Binomial(n,p)
概率质量函数
P(X=k)=(nk)pk(1−p)n−kk=0,1,....n
- X 是随机变量,表示事件发生的次数
- k 是事件发生的具体次数
- n 是试验的总次数
- p 是每次实验中事件发生的概率
- (nk) 是组合数,表示从 n 次试验中选出 k 次成功的方式数 (nk)=k!(n−k)!n!
性质
- 期望值为 E[X]=np
- 方差为 Var(X)=np(1−p)
- 矩生成函数 MX(t)=(1−p+pet)n
- 特征函数为 ΦX(t)=(1−p+peit)n 其中 i 是虚数单位
- 可加性:对于两个独立的二项随机变量 X1∼Binomial(n1,p) 和 X2∼Binomial(n2,p) ,则它们的和也满足二项分布 X1+X2∼Binomial(n1+n2,p)
负二项分布
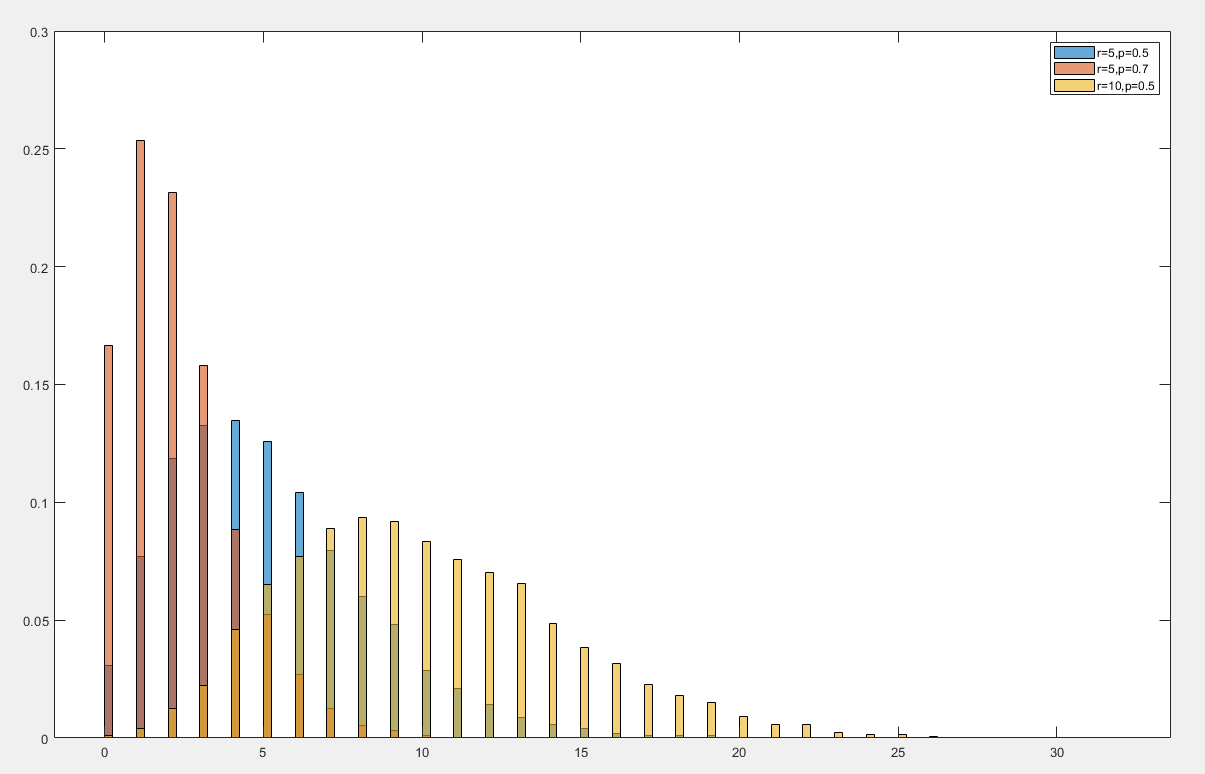
负二项分布(Negative Binomial Distribution)是一种离散概率分布,用于描述在一系列独立伯努利试验中,达到指定次数的成功所需的试验次数
负二项分布的概率质量函数
-
根据试验次数定义:随机变量 X 表示达到 r 次成功所需要的总实验次数,包括成功的
P(X=k)=(k−1r−1)pr(1−p)k−rk=0,1...
-
根据失败次数定义:随机变量 Y 表示达到 r 次成功前的失败次数
P(Y=k)=(k+r−1r−1)pr(1−p)k−rk=0,1...
其中
- k 是试验次数或者失败次数
- r≥1 是成功次数
- p 是每次试验的成功概率
- 1−p 是每次试验中失败的概率
- (nk) 是组合数,表示从 n 次试验中选出 k 次成功的方式数 (nk)=k!(n−k)!n!
性质
- 期望值为 E[X]=prE[Y]=pr(1−p)
- 方差为 Var(X)=p2r(1−p)Var(Y)=p2r(1−p)
- 矩生成函数为 MX(t)=(1−(1−p)etpet)rMY(t)=(1−(1−p)etpet)rt<−ln(1−p)
- 可加性:对于两个独立的负二项随机变量 X1∼NegativeBinomial(r1,p) 和 X2∼NegativeBinomial(r2,p) ,则它们的和也满足二项分布 X1+X2∼NegativeBinomial(r1+r2,p)
- 当 r=1 时退化为几何分布,几何分布描述第一次成功所需的试验次数,而负二项分布描述第 r 次成功所需的试验次数
- 当 r→∞,p→1 时,负二项分布可近似为泊松分布
- 二项分布描述固定试验次数中的成功次数,而负二项分布描述固定成功次数所需的试验次数
泊松分布
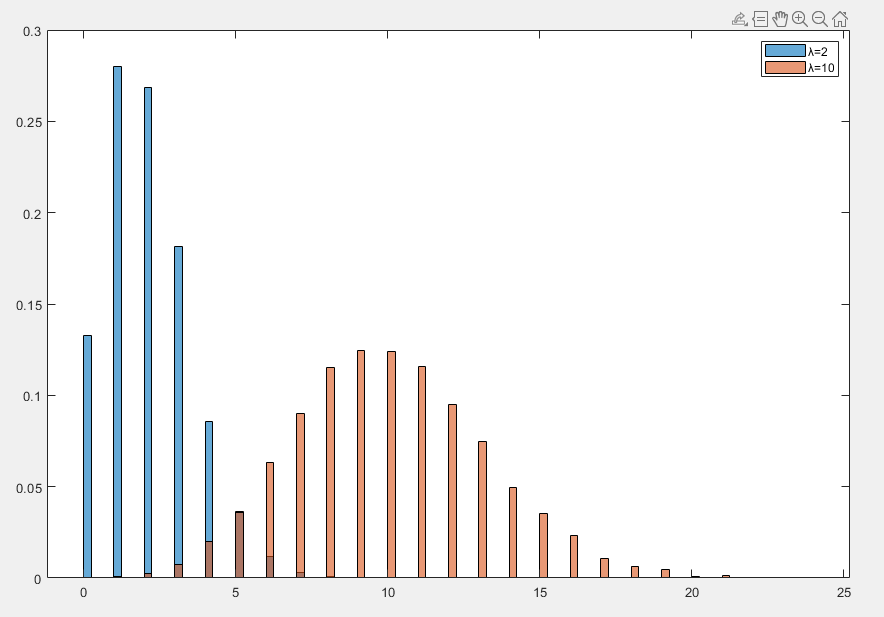
泊松分布(Poisson Distribution)是一种离散概率分布,用于描述在固定时间或空间内某事件发生的次数的概率分布。对于一个随机变量 X ,如果其满足泊松分布,则称其 X∼Poisson(λ)
概率质量函数
泊松分布的概率质量函数为
P(X=k)=k!λke−λk=0,1,....n
- X 是随机变量,表示事件发生的次数
- k 是事件发生的具体次数
- λ 是分布的参数,示在固定时间或空间内事件发生的平均次数
- e 是自然对数的底
性质
-
期望值为 E[X]=λ
-
方差为 Var(X)=λ
-
矩生成函数为 MX(t)=exp(λ(et−1))
-
特征函数 ΦX(t)=exp(λ(eit−1)) ,其中 i 是虚数单位
-
可加性:对于两个独立的泊松随机变量 X1∼Poisson(λ1) 和 X2∼Poisson(λ2) ,则它们的和也满足泊松分布 X1+X2∼Poisson(λ1+λ2)
-
泊松分布可以看作是二项分布的极限情况,当二项分布的试验次数 n 很大时,并且单次成功概率很小,并且 λ=np 保持常数时,二项分布近似于泊松分布
Binomial(n,p)≈Poisson(λ=np)n→∞,p→0
几何分布
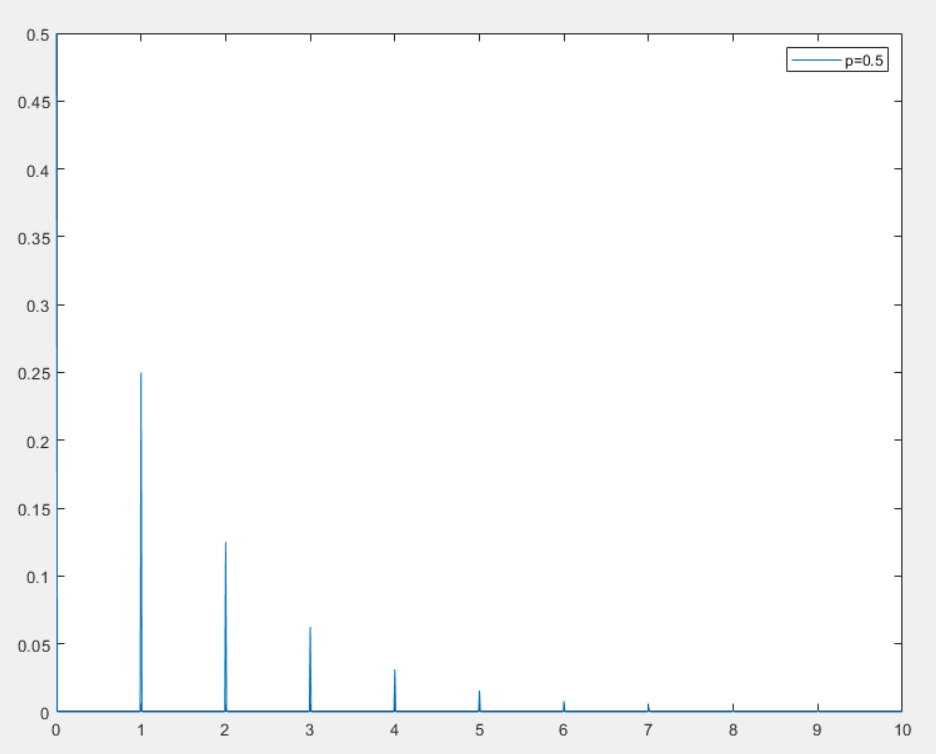
几何分布(Geometric Distribution)是一种离散概率分布,用于描述在一系列独立伯努利试验中,第一次成功所需的试验次数
几何分布的概率质量函数
-
对于第一次成功所需要的试验次数
P(X=k)=(1−p)k−1pk=1,2,....
-
对于第一次成功前的失败次数
P(Y=k)=(1−p)kpk=1,2,....
其中
- k 是失败的次数或者试验次数
- p 是每次试验中成功的概率
性质
-
期望值为 E[X]=p1E[Y]=p1−p
-
方差为 Var(X)=p21−pVar(Y)=p21−p
-
矩生成函数为 MX(t)=1−(1−p)etpetMY(t)=1−(1−p)etpett<−ln(1−p)
-
无记忆性:几何分布是唯一具有无记忆性的离散分布,过去的失败对未来成功的概率没有影响
P(X>k+n∣X>k)=P(x>n)k,n>0
-
几何分布是负二项分布的特例,当负二项分布的成功次数 r=1 时,负二项分布退化为几何分布
超几何分布
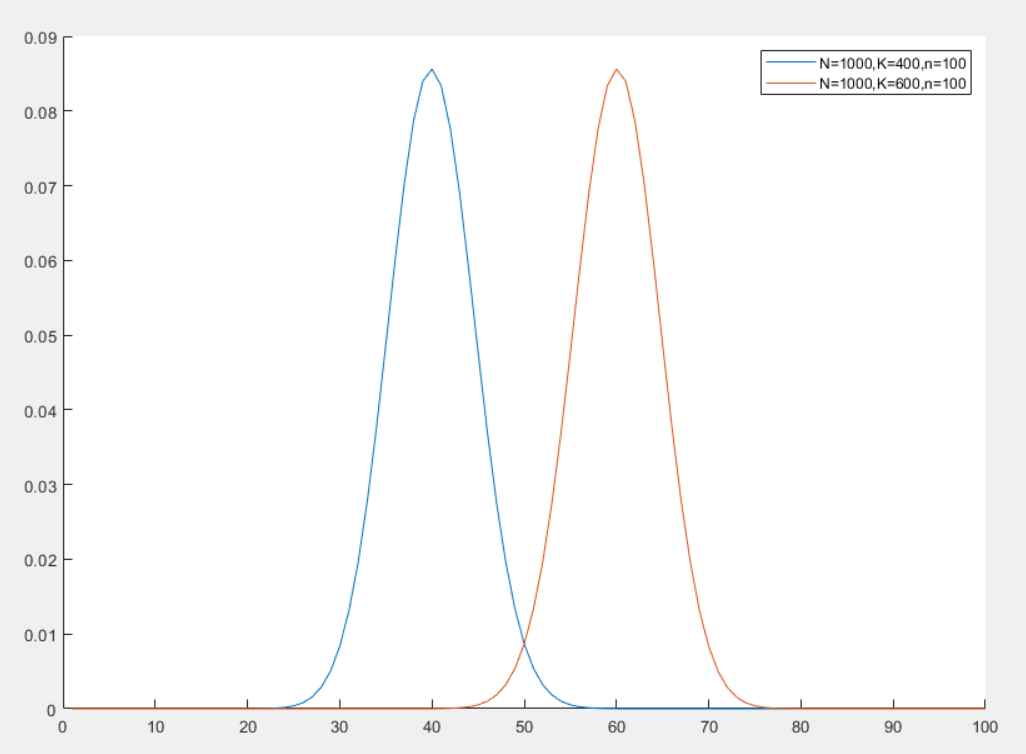
超几何分布(Hypergeometric Distribution)是一种离散分布,用于描述在不放回抽样中成功次数的分布
超几何分布的概率质量函数
超几何分布描述的是从有限的 N 个物品中不放回的抽取 n 个物品,其中包含 K 个成功物品和 N−K 个失败物品,成功物品的个数服从超几何分布,其概率质量函数为
P(X=k)=(Nn)(Kk)(N−Kn−k)
- (nk) 是组合数,表示从 n 次试验中选出 k 次成功的方式数 (nk)=k!(n−k)!n!
性质
- 期望值为 E[X]=nNK
- 方差为 Var(X)=nNK(1−NK)N−1N−n
- 当 N 很大而 n 相对较小时,超几何分布近似于二项分布 B(n,p) ,其中 p=NK
指数分布
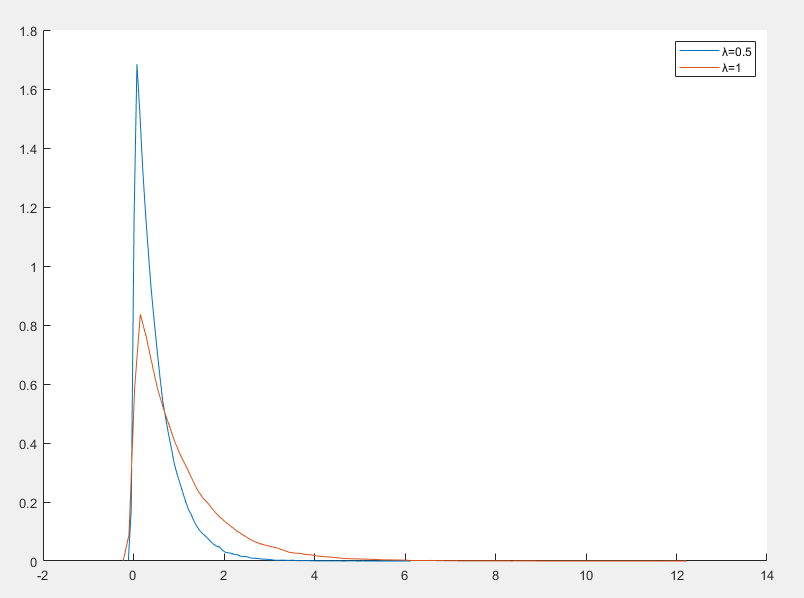
指数分布(Exponential Distribution)是一种连续概率分布,通常用于描述事件之间的时间间隔或等待时间,是唯一具有无记忆性(Memoryless Property)的连续分布
指数分布的概率密度函数
f(x∣λ)=λe−λxx≥0
- x 是随机变量,表示事件之间的事件间隔或等待时间
- λ>0 是速率参数,表示单位时间内事件发生的平均次数
也可以用尺度参数 θ=λ1 来表示
f(x∣θ)=θ1e−x/θ
- θ 是尺度参数,表示事件之间的平均时间间隔
性质
-
期望值为 E[X]=λ1=θ
-
方差为 Var(X)=λ21=θ2
-
矩生成函数为 MX(t)=λ−tλt<λ
-
特征函数为 MX(t)=λ−itλ
-
无记忆性:过去的事件对未来事件的概率没有影响
P(X>s+t∣X>s)=P(X>t)s,t>0
-
如果事件在单位时间内发生的次数服从泊松分布 Poisson(λ) ,则事件之间的时间间隔服从指数分布 EXP(λ)
-
指数分布是伽马分布的特例,当伽马分布的形状参数 k=1 时伽马分布退化为指数分布
-
指数分布是几何分布的连续版本
伽马分布
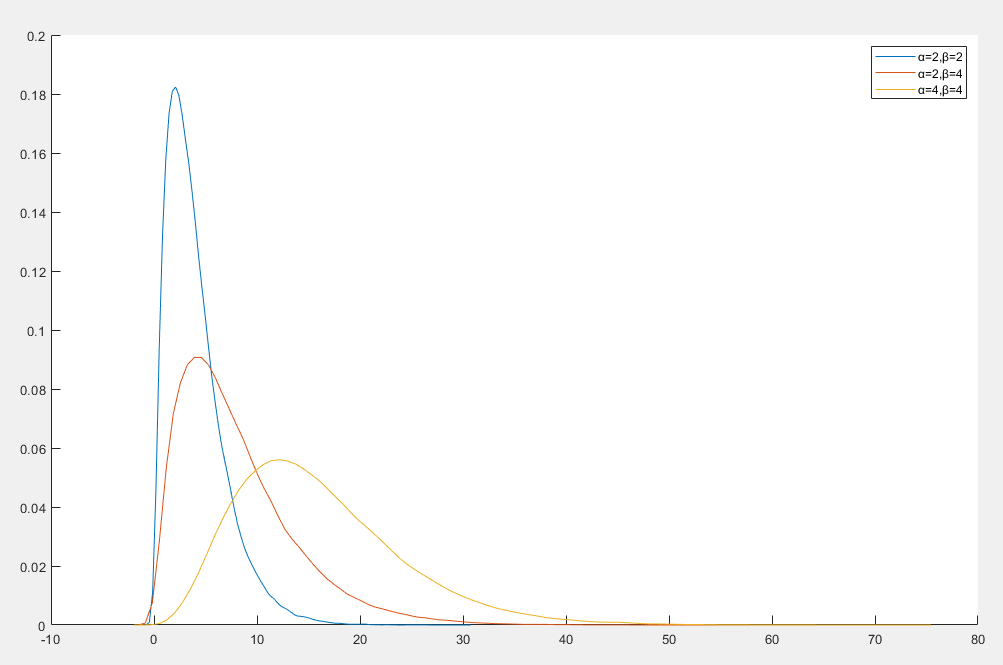
伽马分布是一种连续概率分布,用于建模正实数值的随机变量,如果一个随机变量服从于伽马分布,记作 X∼Γp(α,β)
概率密度函数
f(x∣α,β)=Γ(α)βαxα−1e−βxx>0
- x>0 是随机变量
- α>0 是形状参数
- β>0 是尺度参数
- Γ(α)=∫0∞xα−1e−xdx 是伽马参数
性质
- 期望值为 E[X]=βα
- 方差值为 Var(X)=β2α
- 当 α=1 时,伽马分布退化为指数分布
- 当 α=2n 并且 β=21 时,伽马分布就是自由度为 n 的卡方分布
- 可加性,对于两个独立的随机变量 X∼Γp(a,β) 和 Y∼Γp(b,β) ,则 Z=X+Y∼Γp(a+b,β)
- 特征函数 ΦX(t)=(1−i⋅θt)−k ,其中 i 是虚数单位
- 矩生成函数 MX(t)=(1−θt)−kt<θ1
逆伽马分布
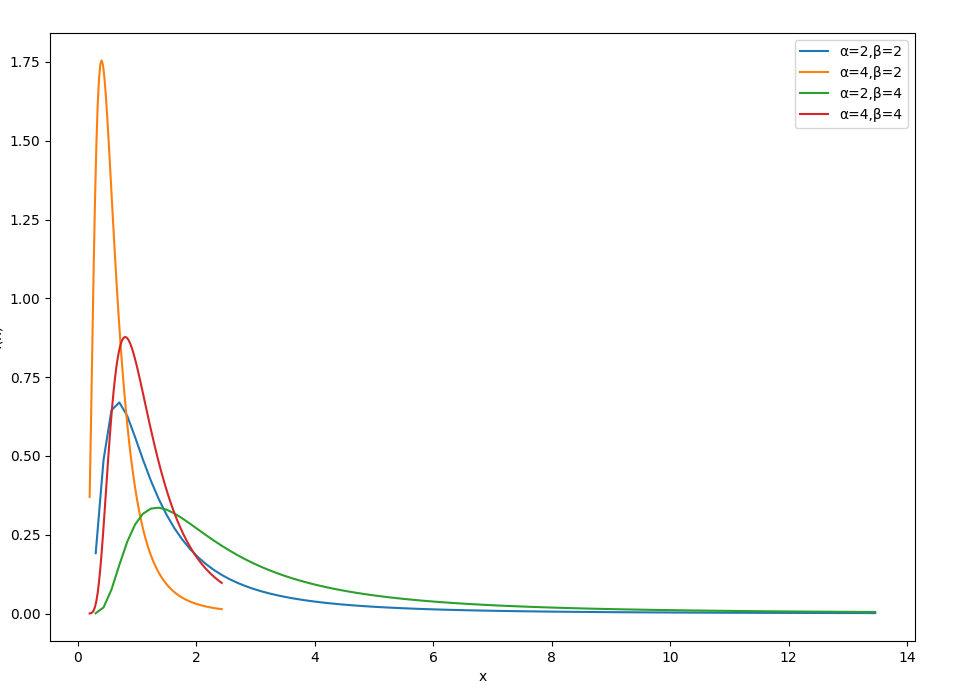
逆伽马分布(Inverse gamma distribution)是伽马分布的逆分布,通常用于建模正实数值的随机变量,如果一个随机变量服从于逆伽马分布,记作 X∼Γp−1(α,β)
概率密度函数
f(x∣α,β)=Γ(α)βαx−α−1e−βxx>0
- α>0 是形状参数
- β>0 是尺度参数
性质
- 如果 X∼Γp(α,β) ,则 Y=X1∼Γp−1(α,β)
- 期望值为 E[X]=α−1βα>1
- 方差为 Var(X)=(α−1)2(α−2)β2α>2
威沙特分布
威沙特分布(Wishart Distribution)是多元高斯分布的协方差矩阵的分布,通常用于建模正定对称矩阵
威沙特分布的概率密度函数
f(X)=22np∣Σ∣2nΓp(2n)∣X∣2n−p−1exp(−21tr(Σ−1X))
对于 X∈Rn×p 的随机矩阵,其列向量独立同分布于 Np(M,Σ) ,则 W=XTX 服从自由度为 n ,非中心参数矩阵 Ω=MTΣ−1M 的非中心威沙特分布,记作 W∼Wp(n,Σ,Ω)
- p 维度
- n≥p 自由度
- Σ∈Rp×p 协方差矩阵
- Ω∈Rp×p 的非中心参数矩阵
- tr 表示矩阵的迹
特别的,当 M=0 时 W=XTX 服从于自由度为 n 的中心威沙特分布,记作 W∼Wp(n,Σ)
性质
- 非中心威沙特分布的期望值为 E[W]=nΣ+MTM
- 中心威沙特分布的期望值为 E[W]=nΣ
- 协方差为 Cov(Wij,Wkl)=n(ΣikΣjl+ΣilΣjk)
- 非中心威沙特分布特征函数为 ΦW(T)=∣Ip−2iΣT∣−n/2exp(i⋅tr(T(Ip−2iΣT)−1Ω)) 其中 i 是虚数单位
- 非中心威沙特分布特征函数为 ΦW(T)=∣Ip−2iΣT∣−n/2
- 可加性:若 W1∼Wp(n1,Σ) 和 W2∼Wp(n2,Σ) 相互独立,则 W1+W2∼Wp(n1+n2,Σ)
逆威沙特分布
逆威沙特分布是威沙特分布的逆分布,通常用于建模正定对称矩阵的逆矩阵,如果一个随机变量服从于逆伽马分布,记作 X∼Wp−1(v,Ψ)
逆威沙特分布的概率密度函数
f(X∣v,Ψ)=2vd/2Γd(v/2)∣Ψ∣v/2∣X∣−(v+d+1)/2exp(−21tr(ΨX−1))
- X∈Rp×p 是正定矩阵
- Ψ∈Rp×p 是正定矩阵
- Γd 是多变量伽马分布
- tr 表示矩阵的迹
性质
-
如果一个正定矩阵 W 的逆矩阵遵从自由度为 v 的威沙特分布 W−1∼Wp(v,Σ) 的话,那么该矩阵遵从逆威沙特分布 W∼Wp−1(v,Σ−1)
-
期望 E[X]=v−p−1Ψv>p+1
-
协方差,对于 X 的元素 Xij,Xkl ,协方差为
Cov(Xij,Xkl=(v−p)(v−p−1)(v−p−3)(v−p−1)ΨikΨjl+(v−p−1)ΨilΨjkv>p+3
-
逆的期望 E[X−1]=vΨ−1
狄利克雷分布
狄利克雷分布(Dirichlet Distribution)是概率论中的一种连续多元概率分布,常用于贝叶斯统计和多元数据分析,它是贝塔分布(Beta Distribution)在高维空间中的推广
定义
对于一个 K 维随机向量 X={x1,…xk} ,如果其满足如下条件
- 对于任意 i 都满足 xi≥0
- ∑iKxi=1
并且其概率密度函数为
f(X∣α)=B(α)1i∏Kxiαi−1
- α=(α1,…αK) 是一个正实数,称为浓度参数(concentration parameters)
- B(α)=Γ(∑iKαi)∏iKΓ(αi) 是多元贝塔函数,其中 Γ 是伽马函数
性质
- 期望值为 E[xi]=∑jKαjαi
- 方差 Var(xi)=(∑jKαj)2(∑jKαj+1)αi(∑jKαj−αi)
- 协方差为 Cov(xi,xj)=(∑kKαk)2(∑kKαk+1)−αiαji=j
- 狄利克雷分布是多项分布的共轭先验,即如果先验分布是狄利克雷分布,似然函数是多项分布,那么后验分布也是狄利克雷分布
- 狄利克雷分布具有聚集性质,即对于 p∼Dir(α) ,则 p 的某些分量可以合并,合并之后仍然是狄利克雷分布
- 当所有的 αi 相等时,狄利克雷分布是对称的,分布的形状在各个方向上相同
贝塔分布
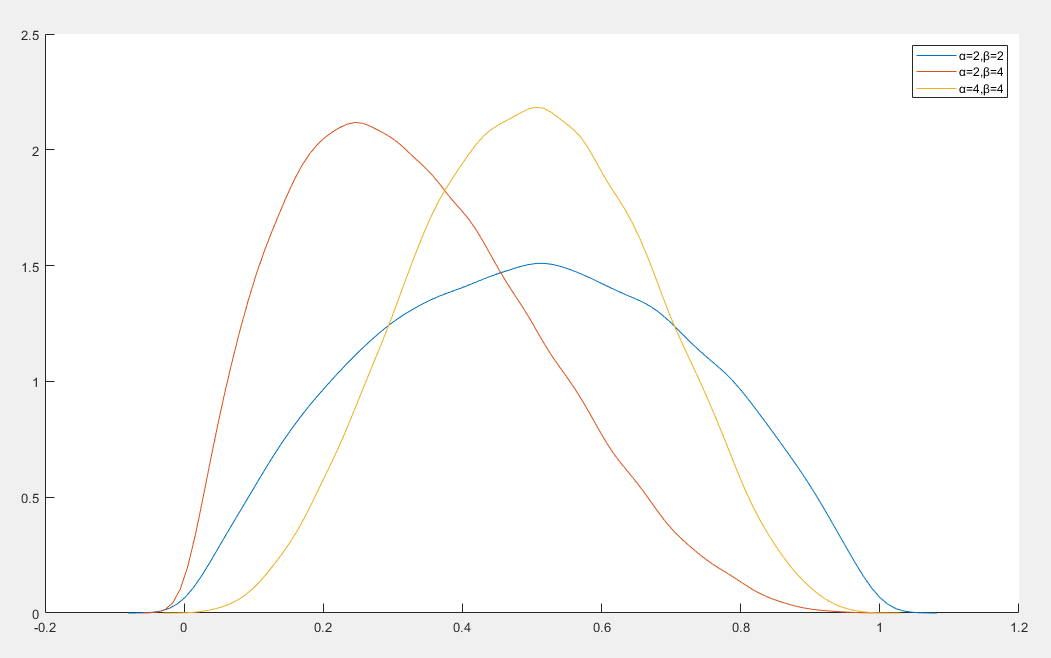
贝塔分布(Beta Distribution)是定义在区间 [0,1] 上的一种连续概率分布,常用于表示概率的概率分布
定义
贝塔分布由两个正实数参数 α 和 β 定义,其概率密度函数为
f(x∣α,β)=B(α,β)xα−1(1−x)β−1
- x∈[0,1] 是随机变量
- α>0 和 β>0 是形状参数
- B(α,β)=Γ(α+β)Γ(α)Γ(β) 是贝塔函数,其中 Γ 是伽马函数
性质
- 期望值为 E[X]=α+βα
- 方差为 Var(X)=(α+β)2(α+β+1)αβ
- 众数为 Mode(X)=α+β−2α−1
- 对称性:
- 当 α=β 时分布是对称
- 当 α>β 时分布左偏
- 当 α<β 时分布右偏
- 当 α=β=1 时,贝塔分布退化为均匀分布
- 形状
- 当 α>1,β>1 时,分布呈单峰
- 当 α<1,β<1 时,分布呈 U 形
- 当 α<1,β≥1 或 α≥1,β<1 时,分布呈 J 形
多项分布
多项分布(Multinomial Distribution)是二项分布的推广,用于描述具有多种可能结果的随机试验
定义
多项分布描述了一个随机试验,有 K 种可能,每种结果的概率分别为 p1,…pK 进行 n 次独立试验之后,每种结果出现的次数服从多项分布。其概率质量函数如下
P(x1,x2,...xK)=x1!x2!...xK!n!p1x1p2x2...pKxK
- xi 表示第 i 种结果出现的次数,并且满足 xi≥0,∑iKxi=n
- pi 是第 i 种结果的概率,满足 pi≥0,∑iKpi=1
- n 是试验总次数
性质
- 第 i 种结果期望值为 E[Xi]=npi
- 第 i 种结果的方差为 Var(Xi)=npi(1−pi)
- 第 i 种结果和第 j 种结果的协方差为 Cov(Xi,Xj)=−npipji=j
- 多项分布的边缘分布式二项分布
广义极值分布
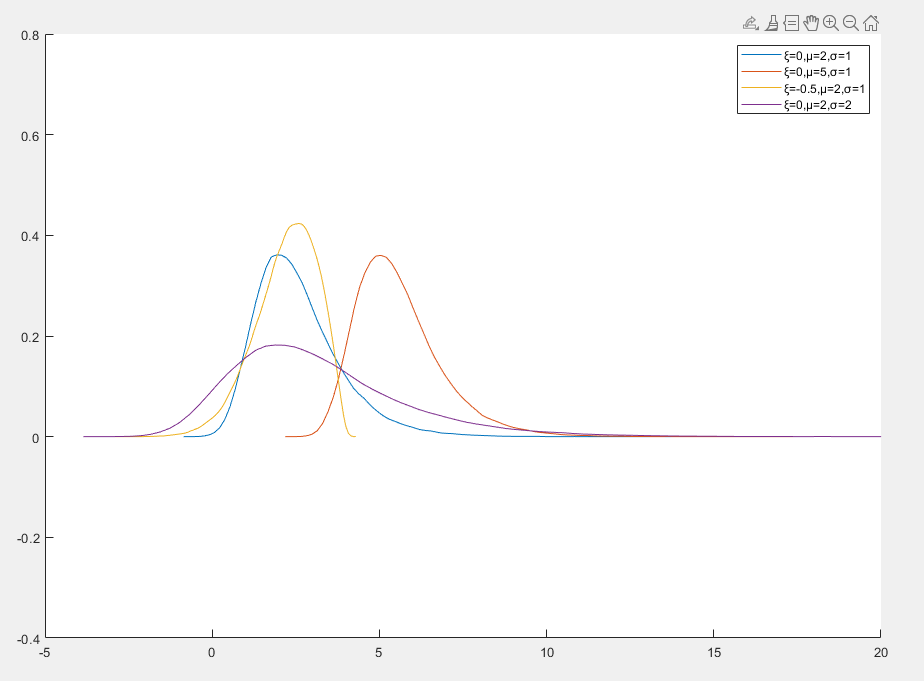
广义极值分布(Generalized Extreme Value Distribution, GEV) 是极值理论中的核心分布,用于描述极端事件(如最大值或最小值)的分布
广义极值分布的概率密度函数
f(x)=σ1[1+ξ(σx−μ)]−1/ξ−1exp{−[1+ξ(σx−μ)]−1/ξ}
- x 是随机变量
- μ 是位置参数
- σ>0 是尺度参数
- ξ 是形状参数,决定了分布的尾部行为
- ξ>0 重尾分布,适合描述极端大值
- ξ=0 轻尾分布,适合描述中等极端事件
- ξ<0 有界分布,适合描述极端小值
性质
- 期望值为 E[X]=μ+ξσ[Γ(1−ξ)−1]ξ<1
- 方差为 Var(X)=ξ2σ2[Γ(1−2ξ)−Γ2(1−ξ)]ξ<0.5
- 累积分布函数为 F(x)=exp{−[1+ξ(σx−μ)]−1/ξ}
- 当 ξ=0 时,广义极值分布退化为 Gumbel 分布
- 当 ξ>0 时,广义极值分布对应于 Frechet 分布
- 当 ξ<0 时,广义极值分布对应于 Weibull 分布
Gumbel 分布
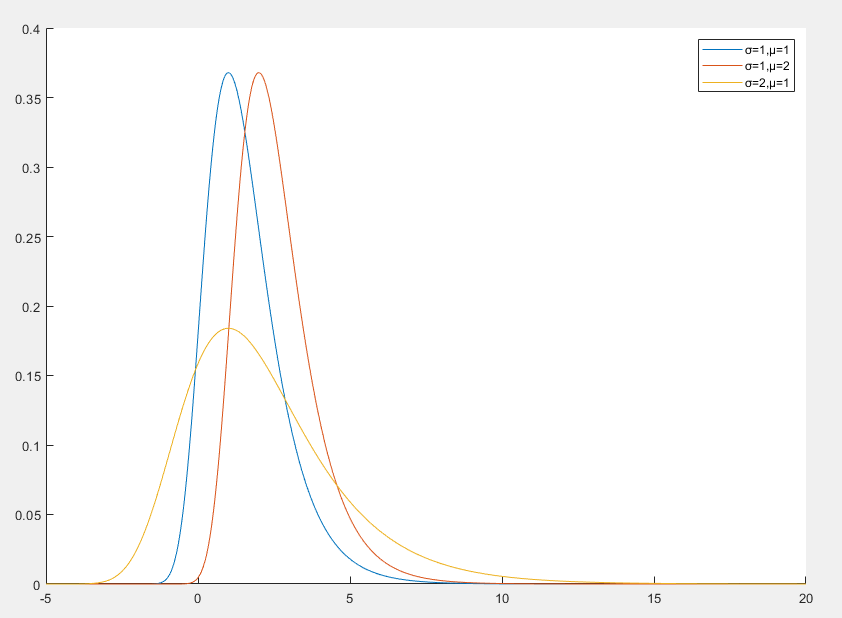
Gumbel 分布 是极值理论中的一种重要分布,用于描述一组独立同分布随机变量的最大值或最小值的分布
Gumbel 分布的概率密度函数
f(x)=σ1exp(−σx−μ−exp(−σx−μ))
- x 是随机变量
- μ 是位置参数,决定分布的中心位置
- σ>0 是尺度参数,决定分布的宽度
性质
- 期望值为 E[X]=μ+σγ ,其中 γ≈0.5772 是欧拉-马歇罗尼常数
- 方差为 Var(X)=6π2σ2
- 累计分布函数为 F(x)=exp(−exp(−σx−μ))
- Gumbel 分布可以看作指数分布的极值分布
Frechet 分布
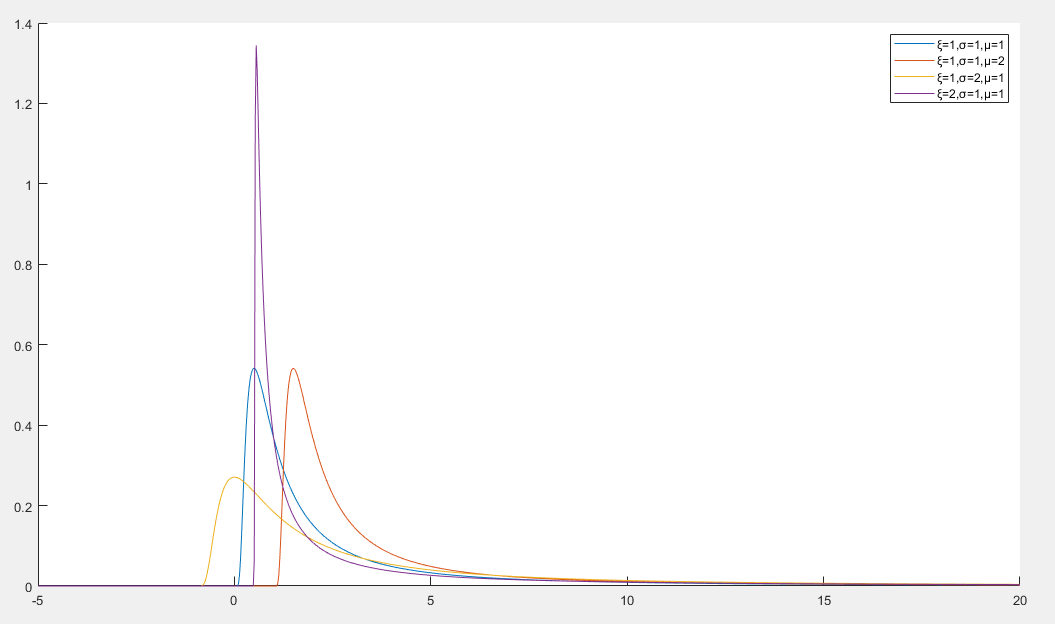
Frechet 分布 是极值理论中的一种重要分布,用于描述一组独立同分布随机变量的最大值的分布
Frechet 分布的概率密度函数
f(x)=σξ(σx−μ)−1−ξexp(−(σx−μ)−ξ)x>μ
- x 是随机变量
- ξ>0 是形状参数,决定分布的尾部行为
- σ>0 是尺度参数,决定分布的宽度
- μ 是位置参数,决定分布下界
性质
- 期望值为 E[X]=μ+σΓ(1−ξ1)ξ>1 ,其中 Γ 是伽马函数
- 方差为 Var(X)=σ2[Γ(1−ξ2)−Γ2(1−ξ1)]ξ>2
- 累积分布函数为 F(x)=exp(−(σx−μ)−ξ)x>μ
Weibull 分布
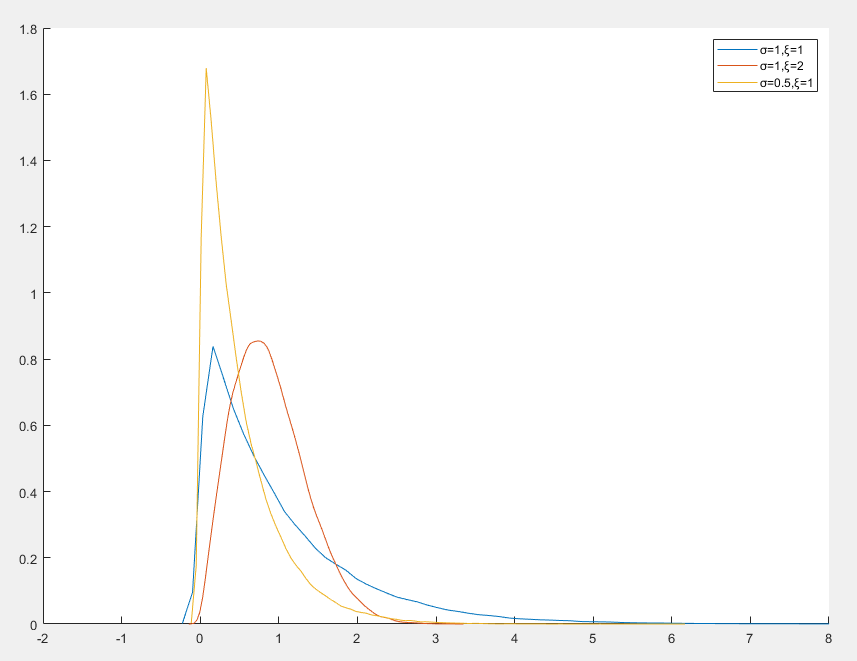
Weibull 分布是一种连续概率分布
Weibull 分布的概率密度函数
f(x)=⎩⎪⎪⎨⎪⎪⎧σξ(σx)ξ−1exp(−(σx)ξ)0x≥0x<0
- x 是随机变量,取值为非负值
- σ>0 是尺度参数,决定分布的密度
- ξ>0 是形状参数,决定分布的形状
- ξ<1 分布呈现递减失效率
- ξ=1 分布退化为指数分布
- ξ>1 分布呈现递增失效率
性质
- 期望值为 E[X]=σΓ(1+ξ1)
- 方差为 Var(X)=σ2[Γ(1+ξ2)−Γ2(1+ξ1)]
- 积累分布函数为 F(x)=⎩⎪⎨⎪⎧1−exp(−(σx)ξ)0x≥0x<0
- 当 ξ=1 时,退化为指数分布
- 当 ξ=2 且 σ=2σ 时,退化为瑞利分布
帕累托分布
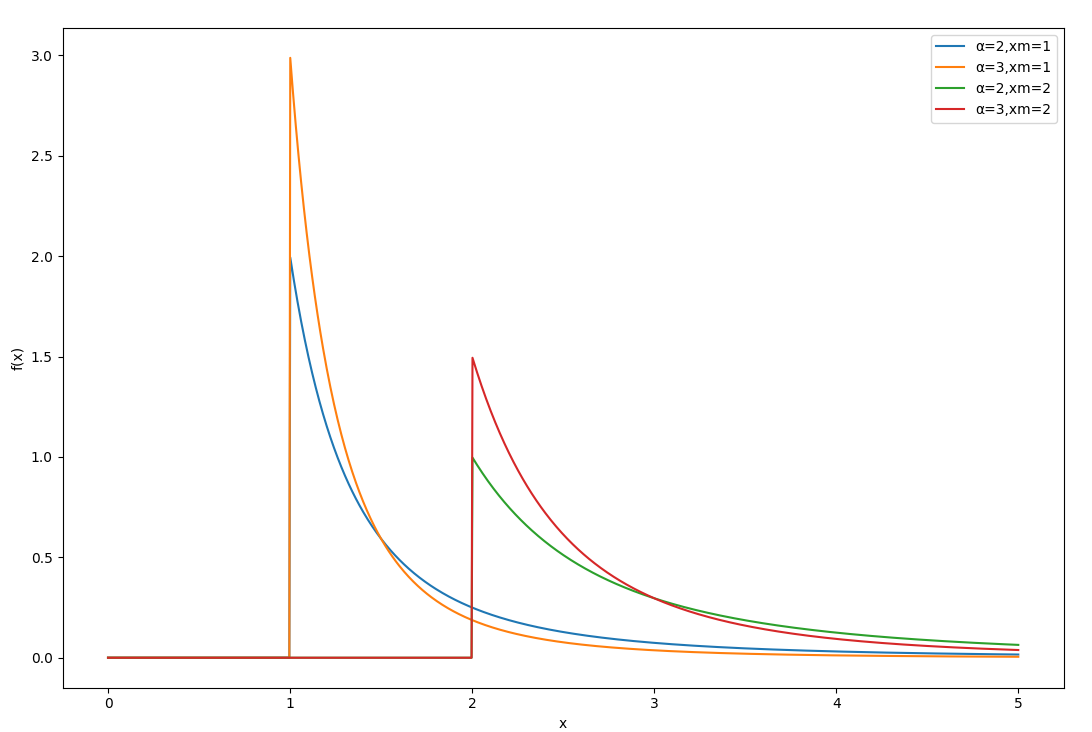
帕累托分布(Pareto Distribution) 是一种连续概率分布,常用于描述具有长尾特性的现象
帕累托分布的概率密度函数
f(x)=⎩⎪⎨⎪⎧xα+1αxmα0x≥xmx<xm
- x 是随机变量,取值为不小于 xm 的实数
- xm 是尺度参数,表示分布的下界
- α>0 是形状参数,决定分布的尾部行为
性质
- 期望值为 E[X]=⎩⎪⎨⎪⎧α−1αxm∞α>1α≤1
- 方差为 Var(X)=⎩⎪⎪⎨⎪⎪⎧(α−1)2(α−2)αxm2∞α>2α≤2
- 累积分布函数为 F(x)=⎩⎪⎨⎪⎧1−(xxm)α0x≥xmx<xm
- 长尾特性:随着 x 的增大,概率密度函数下降得比指数分布更慢
- 当 xm=1 且 α→∞ 时,帕累托分布趋近于指数分布
- 帕累托分布是幂律分布的一种特例
广义帕累托分布
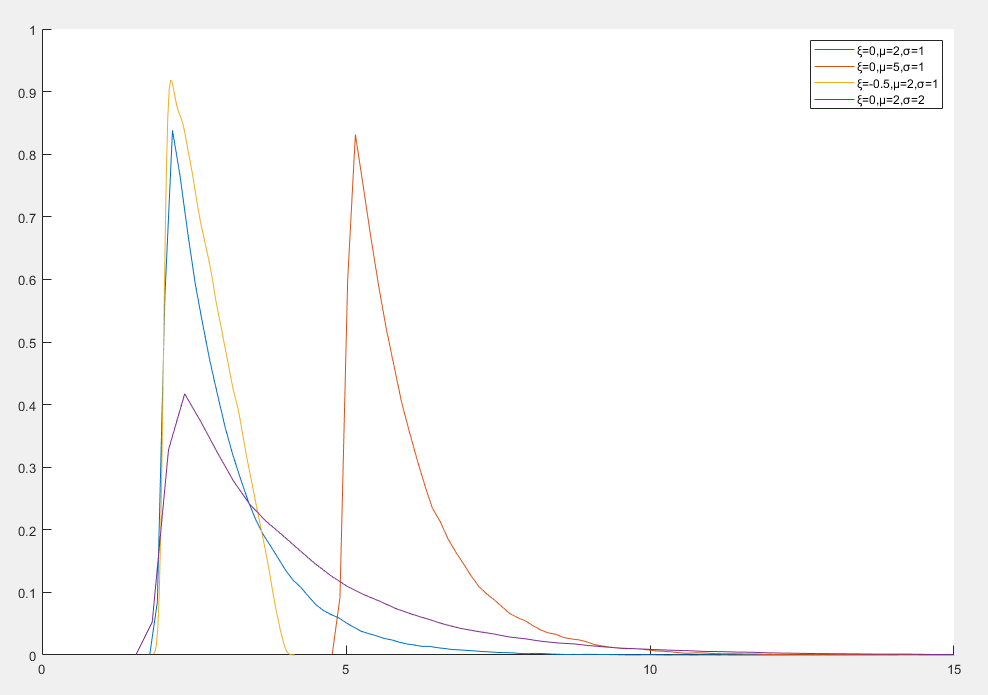
广义帕累托分布(Generalized Pareto Distribution, GPD) 是极值理论中的一种重要分布,用于描述超过某一阈值的极端事件的分布
广义帕累托分布的概率密度函数
f(x)=⎩⎪⎪⎨⎪⎪⎧σ1(1+ξσx−μ)−1/ξ−1σ1exp(−σx−μ)ξ=0ξ=0
- x=⎩⎪⎨⎪⎧[μ,+∞)[μ,μ−ξσ]ξ≥0ξ<0 是随机变量
- μ 是位置参数,表示阈值
- σ>0 是尺度参数,决定分布的宽度
- ξ 是形状参数,决定分布的尾部行为
- ξ>0 重尾分布,适合描述极端大值
- ξ=0 指数衰减尾部,适合描述中等极端事件
- ξ<0 有界分布,适合描述极端小值
性质
- 期望值为 E[X]=μ+1−ξσξ<1
- 方差为 Var(X)=(1−ξ)2(1−2ξ)σ2ξ<0.5
- ξ>0 且 μ=0 时,广义帕累托分布退化为帕累托分布
- 当 ξ=0 时,广义帕累托分布退化为指数分布
- 广义帕累托分布是广义极值分布的尾部近似
莱维分布
莱维分布(Lévy Distribution) 是一种连续概率分布,属于稳定分布家族,具有重尾特性
莱维分布的概率密度函数
f(x)=2πc(x−μ)3/21exp(−2(x−μ)c)x>μ
- x>μ 是随机变量
- μ 是位置参数,表示分布的下界
- c>0 是尺度参数,决定分布的宽度
性质
- 期望值为 E[X]=∞
- 方差为 Var(X)=∞
- 莱维分布的期望和方差均为无穷大,表明其具有极端的重尾特性
- 莱维分布是稳定分布的一种特例,满足稳定分布的性质,若 X1 和 X2 是独立同分布的莱维随机变量,则 X1+X2 也服从莱维分布
- 莱维分布具有重尾特性,其概率密度函数在 x→μ 和 x→∞ 时趋近于 0,但下降速度较慢
- 莱维分布是稳定分布的一种特例,稳定分布还包括正态分布和柯西分布
- 柯西分布也是一种重尾分布,但其概率密度函数的下降速度比莱维分布更慢
厄密特分布
厄密特分布(Hermite Distribution) 是一种离散概率分布,通常用于描述计数数据中具有过度离散(overdispersion)或零膨胀(zero-inflation)特性的情况
厄密特分布的概率质量函数
P(X=k)=k!e−λλk(1+αλ2k(k−1))
- x 是随机变量,取值为非负值
- λ>0 是分布的均值参数
- α 是形状参数,控制分布的过度离散特性
性质
- 期望值为 E[X]=λ
- 方差值为 Var(X)=λ+2α
- 当 α>0 时,方差大于均值,表明分布具有过度离散特性
- 当 α=0 时,厄密特分布退化为泊松分布,厄密特分布可以看作是泊松分布的一个扩展,通过引入额外的参数 α 来描述数据的过度离散特性
- 当 α>0 时,厄密特分布的概率质量函数在 k=0 处的值大于泊松分布,表明分布具有零膨胀特性
- 厄密特分布与负二项分布类似,都用于描述过度离散的计数数据
博雷尔分布
博雷尔分布(Borel Distribution) 是一种离散概率分布,主要用于描述分支过程(branching processes)中的某些特性,特别是在排队论和随机图理论中有应用
博雷尔分布的概率质量函数
P(X=k)=k!e−λk(λk)k−1k=1,2,...
- X 是随机变量,取值为正值
- λ 是分布的参数 0≤λ≤1
性质
- 期望值为 E[X]=1−λ1
- 方差为 Var(X)=(1−λ)3λ
- 概率生成函数为 G(s)=seλ(G(s)−1)
- 博雷尔分布与泊松分布有密切联系,特别是在分支过程和随机图理论中,博雷尔分布描述了某些特定结构的生成
- 当 λ→0 时,博雷尔分布趋近于几何分布
柯西分布
柯西分布(Cauchy Distribution) 是一种连续概率分布,以其重尾特性和缺乏有限的期望和方差而闻名
柯西分布的概率密度函数
f(x)=πγ[1+(γx−x0)2]1
- x∈R 是随机变量
- x0 是位置参数,决定分布的中心位置
- γ>0 是尺度参数,决定分布的宽度
性质
- 期望值为 E[X] 不存在
- 方差为 Var(X) 不存在
- 柯西分布的期望和方差均为无穷大,表明其具有极端的重尾特性
- 柯西分布是关于 x=x0 对称的,即 f(x0+x)=f(x0−x)
- 柯西分布具有重尾特性,其概率密度函数在 x→±∞ 时下降得比正态分布更慢
- 柯西分布是稳定分布的一种特例,满足稳定分布的性质,若 X1 和 X2 是独立同分布的柯西随机变量,则 X1+X2 也服从柯西分布
- 当自由度 k=1 时,t 分布退化为柯西分布
瑞利分布
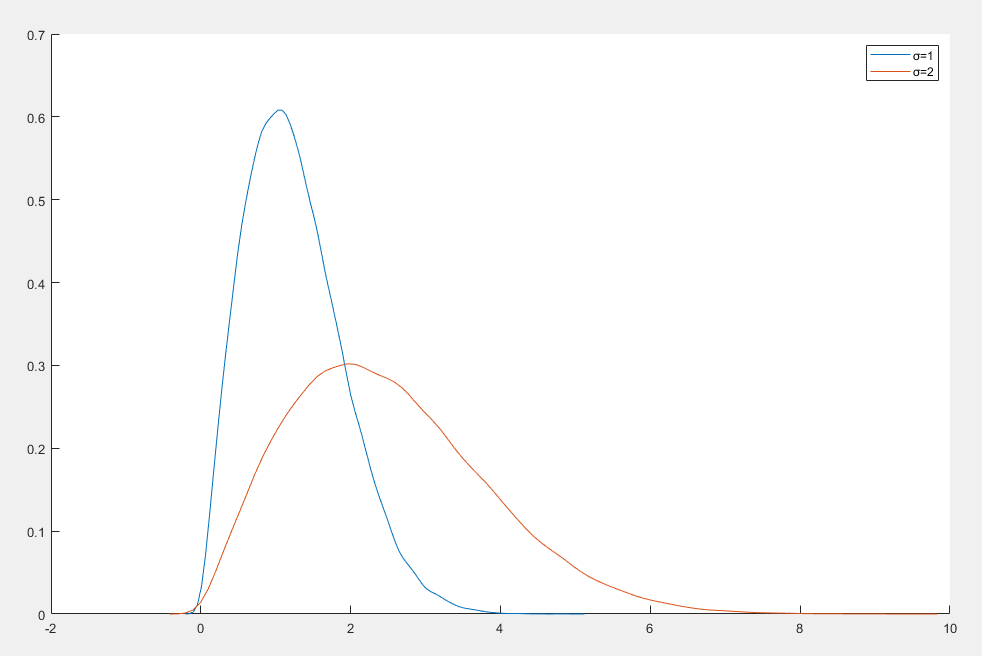
瑞利分布(Rayleigh Distribution) 是一种连续概率分布,通常用于描述二维空间中随机向量的模的分布
瑞利分布的概率密度函数
f(x)=σ2xexp(−2σ2x2)x≥0
- x 是随机变量,取值为非负实数
- σ>0 是尺度参数,决定分布的宽度
性质
- 期望值为 E[X]=σ2π
- 方差为 Var(X)=σ2(2−2π)
- 累积分布函数为 F(x)=1−exp(−2σ2x2)x≥0
- 瑞利分布可以看作是两个独立同分布的正态随机变量的模的分布,即对于两个独立同分布的正态随机变量 X,Y∼N(0,σ2) ,则 Z=X2+Y2∼Rayleigh(σ)
- 瑞利分布的平方服从指数分布,即若 X∼Rayleigh(σ) 则 X2∼Exponential(λ=2σ21)
幂律分布
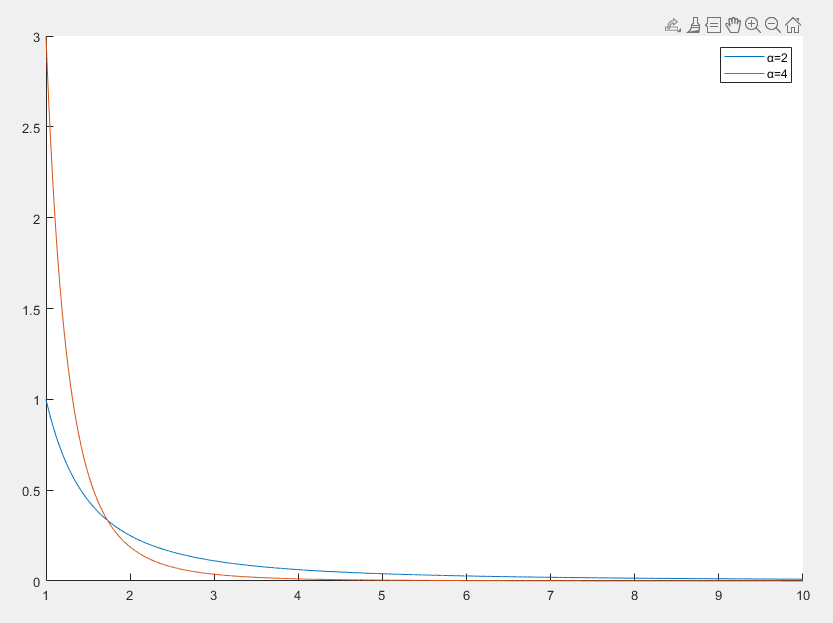
幂律分布(Power-law Distribution) 是一种描述许多自然和社会现象中重尾特性的概率分布
幂律分布的概率密度函数
f(x)=Cx−αx≥xmin
- x 是随机变量
- α>1 是幂律指数,决定分布的尾部行为
- C 是归一化常数,满足 ∫xmin∞f(x)dx=1
归一化常数计算之后得到 C=(α−1)xminα−1 ,幂律分布的概率密度函数可以表示为
f(x)=xminα−1(xminx)−αx≥xmin
性质
- 期望值为 E[X]=α−2α−1x
- 方差为 Var(X)=(α−2)(α−3)α−1xmin2α>3
- 当 α≤2 时期望不存在, α≤3 方差不存在
- 幂律分布具有重尾特性,即随着 x 的增大,概率密度函数下降得比指数分布更慢,这种特性使得幂律分布适合描述极端事件或稀有事件
- 幂律分布具有尺度不变性,即对于任意常数 c>0 有 f(cx)=c−αf(x)
- 帕累托分布是幂律分布的一种特例,当 xmin>0 时,幂律分布退化为帕累托分布
- 当 α→∞ 时幂律分布趋近于指数分布
三角分布
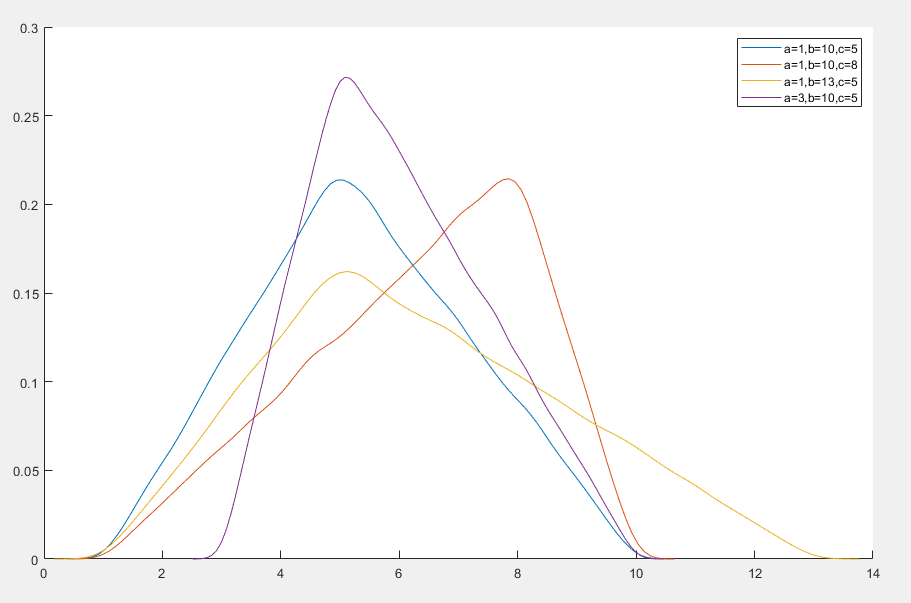
三角分布(Triangular Distribution)是一种连续概率分布,常用于描述在已知最小值、最大值和众数的情况下,随机变量的分布情况
三角分布的概率密度函数
f(x)=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧(b−a)(c−a)2(x−a)(b−a)(b−c)2(b−x)0a≤x≤cc<x≤b
- a 是最小值,是下限
- b 是最大值,上限
- c 是众数,取值范围为 [a,b]
性质
- 期望值为 E[X]=3a+b+c
- 方差为 Var(X)=18a2+b2+c2−ab−ac−bc
- 概率密度函数呈三角形
- 当 c=2a+b 分布是对称的
分段线性分布
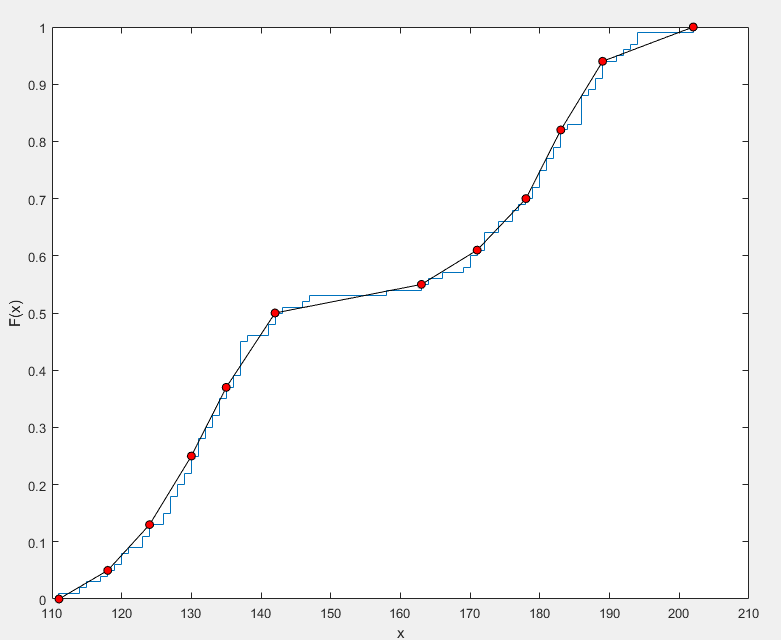
分段线性分布(Piecewise Linear Distribution)是一种通过分段线性函数定义的连续概率分布,其概率密度函数(PDF)由多个线性段组成,通常用于描述具有不同变化趋势的随机变量
分段线性分布的概率密度函数
分段线性分布的概率密度函数由多个线性段组成,每个段在定义域的不同区间内具有不同的斜率,通常,分段线性分布的定义域被划分为若干区间,每个区间内的概率密度函数是线性的
f(x)=⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧m1x+b1m2x+b2...mnx+bn0x0≤x≤x1x1≤x≤x2xn−1≤x≤xn
- mi 是第 i 段的斜率
- bi 是第 i 段的截距
性质
- 期望值为 E[X]=∫xf(x)dx
- 方差为 Var(X)=E(X2)−[E(X)]2
- 非负性: ∀x⇒f(x)≥0
- 归一性:整个定义域上的积分为 1, ∫f(x)dx=1
- 通过调整分段区间的斜率和截距,可以灵活地描述复杂的分布形状
- 由于概率密度函数是线性的,计算期望值和方差时可以使用分段积分
t 位置尺度分布
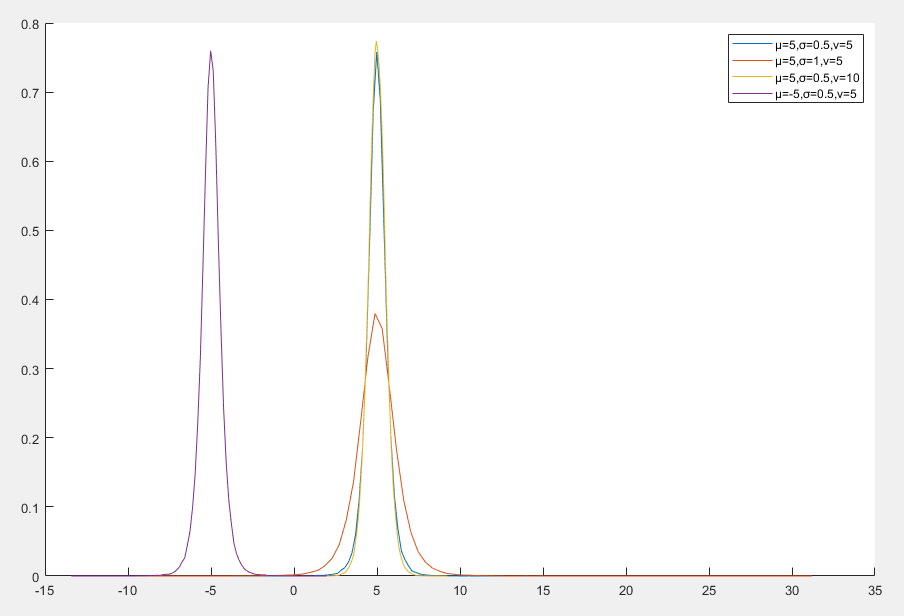
t 位置尺度分布(t Location-Scale Distribution)是统计学中的一种连续概率分布,它是 t 分布 的推广形式,通过引入位置参数和尺度参数,使其更具灵活性。t 位置尺度分布在处理具有重尾特性的数据时非常有用,尤其是在数据中存在异常值或偏离正态分布的情况下
t 位置尺度分布的概率密度函数
f(x)=σvπΓ(2v)Γ(2v+1)(1+v1(σx−μ)2)−2v+1
- μ 是位置参数,分布的均值或中心位置
- σ>0 是尺度参数,分布的标准差或尺度
- v>0 是自由度参数,控制分布的尾部厚度
- 自由度越小,尾部越厚
- 自由度越大,分布越接近正态分布
性质
- 期望值为 E[X]=μv>1
- 方差为 Var(X)=σ2v−2vv>2
- 当 v≤1 时,期望值不存在
- 当 v≤2 时,方差不存在
- 累积分布函数为 F(x)=∫−∞xf(t)dt
- t 位置尺度分布的尾部比正态分布更厚,能够更好地捕捉异常值
- 通过调整自由度参数,可以控制分布的尾部厚度
- 在处理非正态数据时,t 位置尺度分布比正态分布更具鲁棒性
逻辑分布
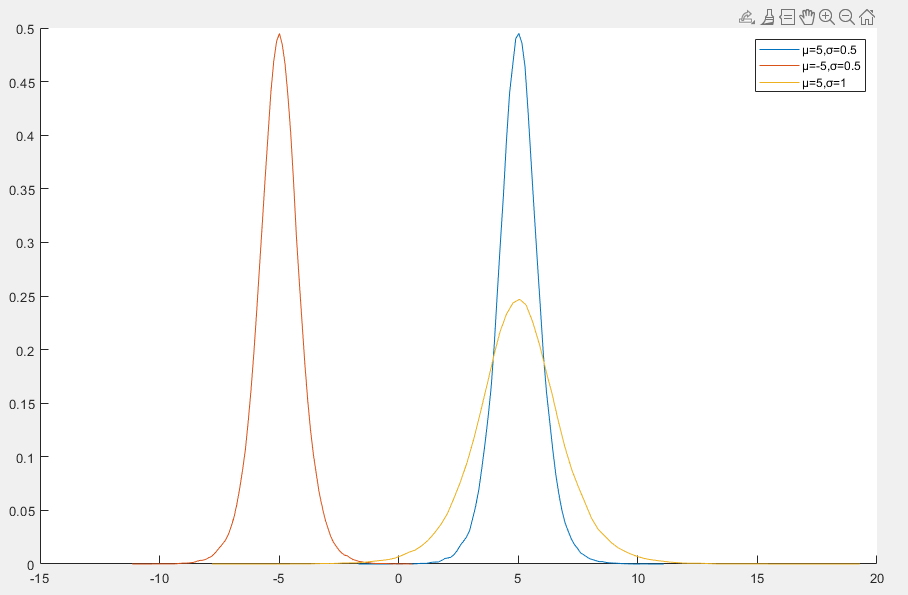
逻辑分布(Logistic Distribution)是一种连续概率分布,常用于统计学和机器学习中的分类问题,它的形状与正态分布类似,但具有更厚的尾部
逻辑分布的概率密度函数
f(x)=s(1+e−sx−μ)2e−sx−μ
- μ 是位置参数,分布的中位数和均值
- s>0 是尺度参数,控制分布的宽度
性质
- 期望值为 E[X]=μ
- 方差为 Var(X)=3s2π2
- 累积分布函数为 F(x)=1+e−sx−μ1
- 逻辑分布的形状与正态分布类似,但尾部更厚,能够更好地捕捉极端值
- 逻辑分布是关于位置参数 μ 对称的
- 逻辑分布的峰度比正态分布更高
半正态分布
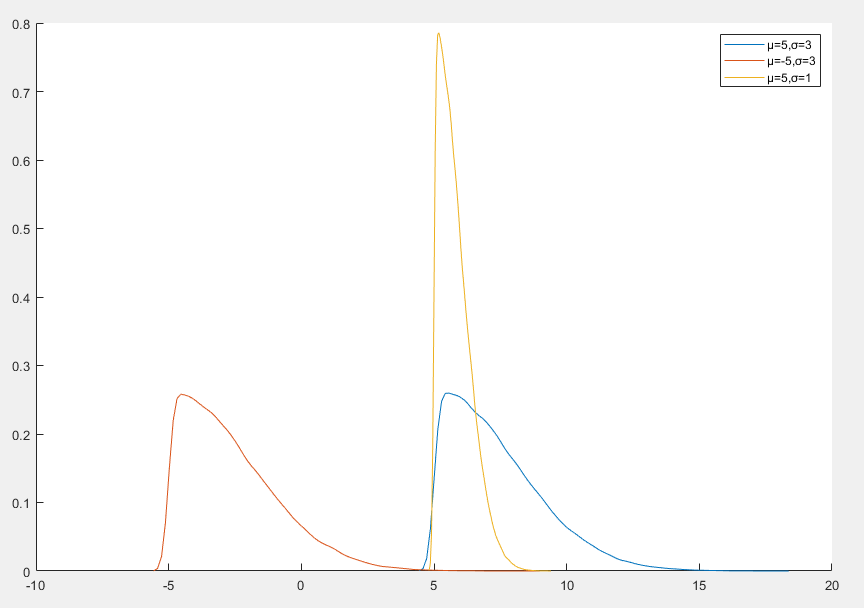
半正态分布(Half-Normal Distribution)是一种连续概率分布,它是将正态分布限制在非负实数域
半正态分布的概率密度函数
f(x)=σπ2exp(−2σ2x2)x≥0
性质
- 期望值为 E[X]=σπ2
- 方差为 Var(X)=σ2(1−π2)
- 累积分布函数为 F(x)=erf(σ2x)x≥0 其中 erf(z)=π2∫0ze−t2dt 是误差函数
- 半正态分布仅定义在非负实数域上
- 半正态分布的形状是单峰的,峰值位于 x=0 处
- 半正态分布是正态分布在 x≥0 上的截断
伯恩鲍姆-桑德斯分布
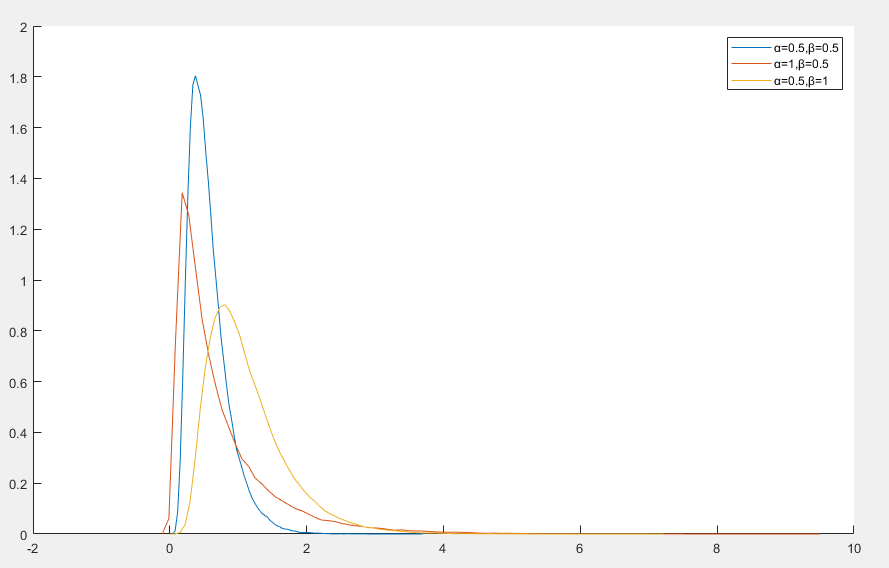
伯恩鲍姆-桑德斯分布(Birnbaum-Saunders Distribution)是一种用于描述材料疲劳寿命的概率分布
伯恩鲍姆-桑德斯分布的概率密度函数
f(x)=2αβ1(xβ+xβ)exp(−2α21(βx+xβ−2))x>0
- x 是随机变量,通常用来表示失效时间或寿命
- α>0 是形状参数,控制分布的偏度和尾部厚度
- β>0 是尺度参数,决定分布的中心,是分布的中位数,即 p(x≤β)=0.5
性质
- 均值为 E[X]=β(1+2α2)
- 方差为 Var(X)=(αβ)2(1+45α2)
- 累积分布函数为 F(x)=Φ(α1(βx−xβ))
Nakagami 分布
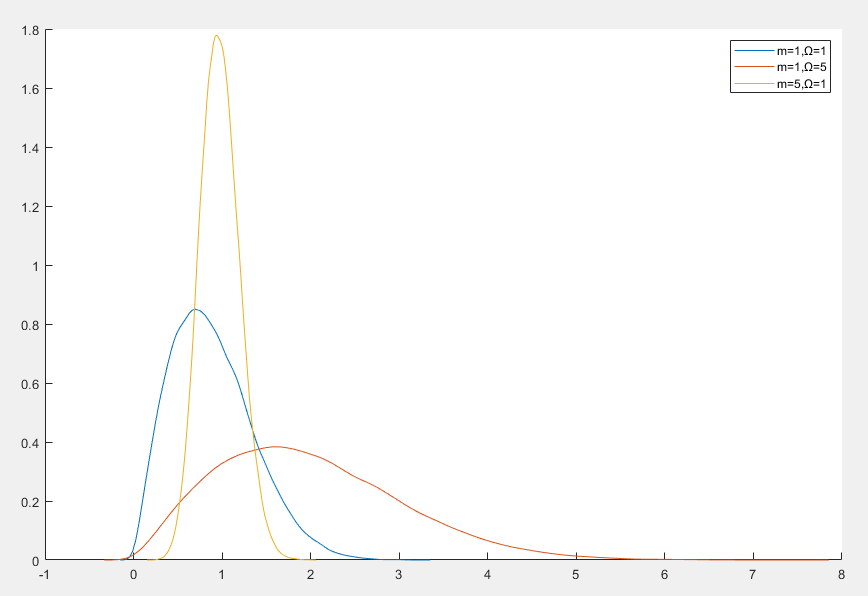
Nakagami 分布(Nakagami Distribution)是一种连续概率分布,常用于无线通信领域,特别是用于建模无线信道的衰落特性
Nakagami 分布的概率密度函数
f(x)=Γ(m)Ωm2mmx2m−1exp(−Ωmx2)x≥0
- m≥0.5 是形状参数,控制分布的形状
- Ω>0 是尺度参数,控制分布的尺度
性质
- 期望值为 E[X]=Γ(m)Γ(m+21mΩ
- 方差为 Var(X)=Ω(1−m1(Γ(m)Γ(m+21))2)
- 累积分布函数为 F(x)=Γ(m)γ(m,Ωmx2)x≥0
- 当 m=1 时 Nakagami 分布退化为瑞利分布
- 当 m=0.5 时 Nakagami 分布退化为单边高斯分布
- Nakagami 分布可以拟合从轻度到重度的衰落信道
- Nakagami 分布仅定义在非负实数域上
莱斯分布
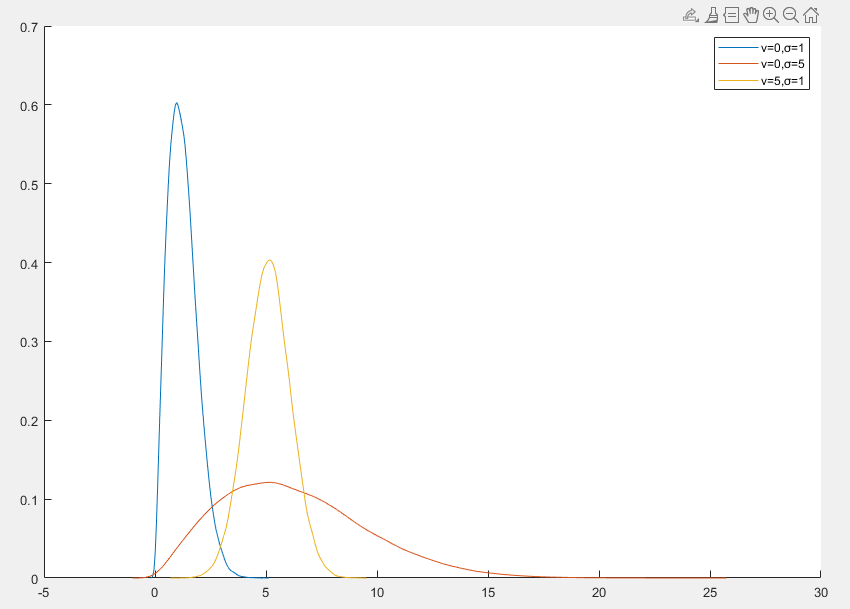
莱斯分布(Rice Distribution)是一种连续概率分布,常用于描述存在主导信号(如直射路径)的随机信号的幅度分布
莱斯分布的概率密度函数
f(x)=σ2xexp(−2σ2x2+v2)I0(σ2xv)x≥0
- v≥0 是非中心参数,主导信号的幅度,较大时分布更集中于主导信号附近
- σ>0 是尺度参数,散射信号的强度
- I0 是零阶修正贝塞尔函数
性质
- 期望值为 E[X]=σ2πL1/2(−2σ2v2) 其中 L1/2 是拉盖尔多项式
- 方差为 Var(X)=2σ2+v2−[σ2πL1/2(−2σ2v2)]2
- 累积分布函数为 F(x)=1−Q1(σv,σx)x≥0 ,其中 Q1(a,b)=∫b∞texp(−2t2+a2)I0(at)dt 是马库姆 Q 函数
- 当 v=0 时,莱斯分布退化为瑞利分布
- 莱斯分布仅定义在非负实数域上
稳定分布
稳定分布(Stable Distribution)是一类重要的概率分布,具有稳定性和广义中心极限定理的特性
稳定分布的特征函数
稳定分布的概率密度函数通常没有闭式表达式,但其特征函数可以显式表示
ϕ(x)=exp{ixδ−γα∣x∣α(1−iβsgn(x)w(x,α))}
- 0<α≤2 稳定性参数,控制分布的尾部厚度
- −1≤β≤1 偏度参数,控制分布的对称性
- γ<0 尺度参数,控制分布的尺度
- δ 位置参数,控制分布的位置
- sgn(x) 是符号函数
- w(x,α)=⎩⎪⎪⎨⎪⎪⎧tan(2πα)−π2log∣t∣α=1α=1 是一个与参数 α 相关的函数
性质
- 当 1<α≤2 时,期望值为 δ ,否则期望值不存在
- 当 α<2 时,稳定分布的方差不存在,当 α=2 时,方差为 2γ2
- 稳定性:如果两个独立且服从稳定分布的随机变量 X1 和 X2 ,则对于任意常数 a,b>0 ,存在常数 c 和 d ,使得 aX1+bX2∼cX+d ,其中 X 也服从稳定分布
- 广义中心极限定理:对于独立同分布的随机变量,其标准化和的极限分布是稳定分布
- 当 α=2 时,稳定分布退化为正态分布,此时 β 无效
- 当 α=1 且 β=2 时,稳定分布退化为柯西分布
- 当 α=0.5 且 β=1 时,稳定分布退化为莱维分布
伯尔分布
伯尔分布(Birnbaum-Saunders Distribution),也称为疲劳寿命分布,是一种连续概率分布,常用于描述材料的疲劳寿命或失效时间
伯尔分布的概率密度函数
f(x)=2αβ1(βx+xβ)exp(−2σ21(βx+xβ−2))x>0
- α>0 是形状参数,控制分布的偏度和尾部厚度
- β>0 是尺度参数,控制分布的位置和尺度
性质
- 期望值为 E[X]=β(1+2α2)
- 方差为 Var(X)=(αβ)2(1+45σ2)
- 累积分布函数为 F(x)=Φ(α1(βx−xβ))x>0 ,其中 Φ 是标准正态分布的累积分布函数
- 伯尔分布仅定义在正实数域上
- 伯尔分布是右偏的

