xv6-kernel下
xv6
内核模式的中断处理
当一个进程获得一个 trap 时,会调用 stvec 寄存器中存储的 uservec 然后进入 usertrap 函数,在函数中会进入内核处理状态,并且将内核中断向量 kernelvec 写入到 stvec 寄存器中。所以在内核模式下发生中断的话会进入 kernelvec ,然后进入 kerneltrap 中。处理结束之后再从中退出到主管模式中去。在 usertrapret 中会将 uservec 写入 stvec 寄存器,然后退出用户模式,以此来保证用户模式下发生中断会在用户中断处理中进行处理
kernelvec
这个是在内核模式下发生中断时运行的第一行代码,这里将会保存原先的内核寄存器,然后进入 kerneltrap 函数进行处理中断,然后返回之后重新加载寄存器,回到原来的进程继续处理
1 | .globl kerneltrap |
kerneltrap
被 kernelvec 调用,在这里处理内核模式下产生的中断
其中设备中断对应的 devintr()
- 0:error
- 1:UART/DISK
- 2:TIMER
1 | void kerneltrap() { |
devintr
用于检查是否是一个外部的中断或者是软件中断,并且进行处理。返回值
- 2:定时器中断
- 1:其它设备
- 0:错误
1 | int devintr() { |
clockintr
在函数中就是将全局的计数器自增。由于 xv6 中没有真实的时钟,只能通过这种方式来计时。 全局变量 ticks 被自旋锁 tickslock 所保护。自增之后唤醒所有正在等待时钟信号的进程
1 | void clockintr() { |
PLIC
平台级中断控制器。例如对于一个计算机,会有很多 I/O 设备,例如磁盘,键盘等。例如当按下键盘一个按键时,系统获得一个输入到 PLIC ,然后它需要被分配到某个内核中去处理。 PLIC 通知 cpu 有一个待处理中断,其中一个 cpu 会 claim 接收中断。所以一旦有数据输入就会产生一个中断,然后 CPU 会通过总线直接与设备通信,然后获得设备的信息。 cpu 处理完中断后会通知 PLIC ,然后 PLIC 接收到通知就会移除掉这个中断信息
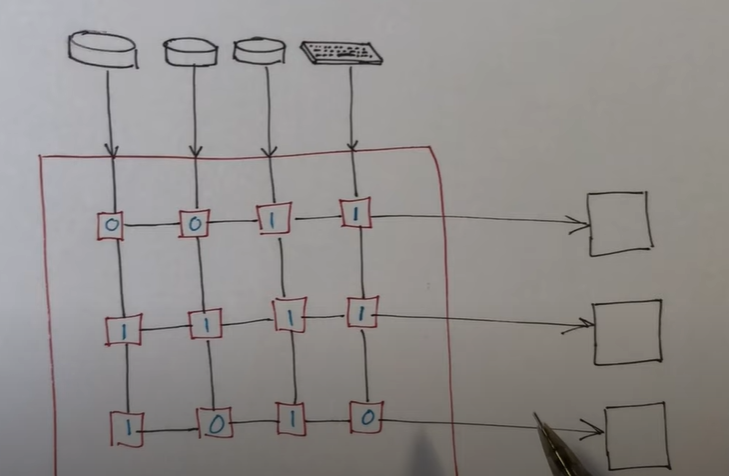
这是一个大的使能矩阵,也是一个位的矩阵,展示了哪个设备可以将中断发送到哪个内核里,这个大的使能矩阵在初始化过程中被设置,并且不会改变。其中如果是 1 就表示该设备的中断可以被该内核处理,否则不可以被该内核处理
PLIC硬件连接
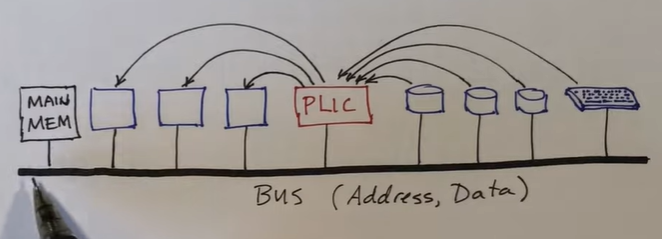
PLIC 连接着设备和内核,并且设备和内核和与主存之间有着互相连接的总线(如图所示)。所以如果一个内核想要读或者写主存,它会发送一个请求到这个总线上,这个信号将被送到主存和内核中。如果内核想要操作某一个设备,一般会使用内存映射的 I/O 寄存器,所以这些设备每一个都映射到某一个物理地址空间中。而且 PLIC 也会映射到某一个物理地址,所以它将会在初始化时被设置,其中有一些寄存器需要其中一个内核在初始化的时候去设置。
当内核想要操作设备或者是对主存进行操作时,需要向总线上写入一个请求,然后对应的设备或者主存就会进行相应的操作。其中对于一个设备想要传输给内核一个数据时,需要通过 PLIC ,由 PLIC 通知 CPU 有一个设备中断,然后对应的 CPU 就会向总线上发送请求然后获取该设备的数据。
有一些设备会被设置在芯片上被认为是内核,其它的被认为是外部设备。一般来说一个芯片上会有多个内核,而 PLIC 被综合到芯片上作为一个内核。以前是被分开在不同的芯片上的,因为单个芯片不支持多核
PLIC 处理中断流程:
- 外部中断源发送中断请求,相对应的中断
gateway处理请求 - 中断
gateway将处理好的请求转至给PLIC内核,同时响应外部中断源的中断pending挂起,也就是对应中断源的pending位置位(SOURCE INTERRUPT PENDING BIT置为 1) PLIC根据配置对多个中断请求进行仲裁,并将仲裁胜利的中断通知给中断目标——内核- 内核接收到中断请求,向
PLIC内核发送一个请求claim,拿到最高优先级的pending中断的 id- 读
claim寄存器,PLIC内核清除相对应的外部中断源的pending位,这个不是全局中断的pending位(EIP),并且这时gateway不能将同一个外部中断源的下一个中断请求转进来,因为gateway没有收到服务完成通知,清除pending位只是表示相对应的外部中断源的中断请求pending状态结束,因为这时候中断请求已经开始被处理,并且将其从仲裁队列中删除,也就是不参与接下来的仲裁
- 读
- 中断内核执行中断处理,处理完成之后向对应的
gateway发送中断完成消息,也就是向compete寄存器中写入中断 id 值 - 中断
gateway收到之前中断服务完成之后,这时候同一个外部中断源的下一个中断请求可以进入gateway中
当 pending 被置位时
- 所有在使能矩阵中对该设备使能的内核都会被通知,其中需要决定哪一个内核去处理这个中断,被选中的内核将会做
- 一个外部中断被挂起
- 如果此时这个内核使能中断,一个 trap 将会发生,否则不会发生(挂起)
- 当 trap 发生时,在中断处理代码中第一件事就是配合
PLIC请求 (claim)中断。在 claim 中发生的是- 读取一个
PLIC中的一个内存映射寄存器,将会得到中断设备的 id 号 PLIC将会清除这个SOURCE INTERRUPT PENDING BIT
- 读取一个
- 多个内核被通知时,都会请求 claim 中断
- 只有一个内核将会得到中断的 id 号,其它的都会返回 0
- 中断处理程序将会运行并且处理设备中断
- 处理信号,中断处理结束,下一个中断的信号可以进来
- 写入在
PLIC中的内存映射寄存器,写入中断完成标志
- 写入在
PLIC将会查看SOURCE INTERRUPT PENDING BIT- 当其再次被置位时,
PLIC产生另一个中断信号
- 当其再次被置位时,
level sensitive
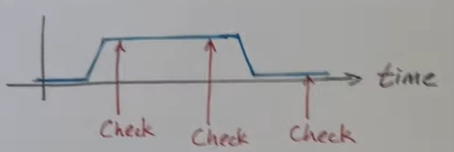
PLIC 将会检查该线上的电平,如果是高电平将会产生一个中断,然后进行中断处理。中断处理结束之后会再次检查线上的电平,如果还是高电平,不论中间发生了什么,都会再次产生一个中断信号。如果检测到是一个低电平信号,那就不产生中断信号
edge triggered

当从低电平变为高电平,这个上升沿将会产生一个中断信号,有两种 gateway 的方式
- one bit
- 获得边沿上升信号时设置位
- 保持置位直到中断处理结束,如果期间有上升沿信号产生也不会去处理,忽略掉
- counter
gateway会有一个计数器- 每一个上升沿计数器增加
- 当中断处理开始执行,计数器自减
- 处理完成之后,如果计数器依旧是正数就产生下一个中断信号
details and complictaions
- 设备号为 1-1023,0 代表 none
- 每一个内核可以包含超过一个硬件线程(hardware thread,hart)
SUPERSCALAR/SIMMULTANEOUS MULTITHEREADING即SMT,想法是核心同时运行两个线程
- 在 risc-v 中,处于每一种模式下都可以被中断,但是中断只可能会被发送到机器模式和主管模式
- 上述内容被称为多目标,也就是每一个设备,每个核心都是一个单独的目标,而且每种模式都是其中的一个单独的目标,所以算起来一共有 15782 种目标,也就是该规范可以处理 15782 种不同的目标,尽管实际的物理实现不可能处理这么多的设备或者说是目标
- 每一个设备都被设置了一个优先级,对于高优先级的中断通常会率先处理
- 每一个内核(目标)都被分配了一个阈值
- 如果设备优先级超过了内核的阈值,设备只会中断内核
PLIC Memory-Mapped Registers
平台级中断控制器。一个进程通过读取和写入内存映射的 I/O 寄存器来控制平台级中断控制器,它们将会占用一定的内存
下面是这些寄存器
- 设备优先级寄存器: 1023 * 4 bytes,这些优先级在启动时初始化。通过将所有设备写入或者存储到这些特定的位置来设置优先级
- 使能位矩阵:1023 * 15782 bits,将在启动时初始化
- 每个核心的优先级阈值:15782 * 4 bytes,将在启动时初始化
- 挂起位(待处理位):1023 * 1 bit,可以看到哪个设备有待处理的中断
- 声明字:15782 * 4 bytes,每一个目标都有一个声明字,可以加载到
CLAIM或者存储到COMPLETE。CLAIM:当有一个中断发生时,在特定的内核上发出信号,该内核将从特定的位置上加载一个四字节的值,该值将会是请求中断的设备的 id,或者当其它内核首先达到该位置时,该值可能是 0COMPLETE:完成完整的操作通过存储到该字中来完成的,在这中情况下,存储到该字中的值就是刚刚处理完中断的设备的 id 号- 一个内核可能会同时处理多个中断,并且它可以声明多个中断,并且独立完成几个
以上的所有内存映射都被存储到一个 64 MB 内存大小的位置。但是其中有很多保留位和未被使用的位,所以在映射中不会全部映射
PLIC处理
实际上在 xv6 中,是通过 qemu 来仿真的,也就是没有真实的物理电路来实现此操作,都是虚拟仿真的
在 xv6 中的 CPU 的数量是由代码中的 NCPU 宏定义决定的,正好是 8。在 qemu 中,中断只能被发送到机器模式或者是主管模式,而且有 8 个 CPU,所以就有 16 个目标。但是在实际使用中,几乎不会用到机器模式中断,所有的中断都发生在主管模式。而且实际中一共有两个设备会产生中断,对应的 id 号
- 1:
VIRTIO0_IRQ虚拟设备 I/O 磁盘 - 10:
UART0_IRQ串口设备
所以在初始化时会有
- 设置两个设备的优先级都为 1
- 每个核心都为设备设置使能位,也就是每个内核都能处理两个设备的中断,任何设备都能中断任何内核。也就是说,该中断会向所有的内核发送中断信号,只有最快最空闲的内核会率先得到声明该中断,然后进行中断处理,而其它之后声明的得到的就是 null,所以首先声明的内核就是期望的内核(更快的处理中断信息)
- 每个内核都将中断阈值设置为 0,这将不会阻止任何中断
一些宏定义
PLIC平台级中断控制器的虚拟地址空间,这里只映射了 4MB,实际上这里应该映射 64 MB 的内存空间,但是实际上没有影响PLIC_PRIORITY平台级中断控制器的优先级PLIC_PENDING平台级中断控制器的待处理位PLIC_MENABLE(hart)平台级中断控制器的对应内核下的机器模式使能位PLIC_SENABLE(hart)平台级中断控制器的对应内核下的主管模式使能位PLIC_MPRIORITY(hart)平台级中断控制器的对应内核下的机器模式优先级PLIC_SPRIORITY(hart)平台级中断控制器的对应内核下的主管模式优先级PLIC_MCLAIM(hart)平台级中断控制器的对应内核下的机器模式下的CLAIM存储的地址PLIC_SCLAIM(hart)平台级中断控制器的对应内核下的主管模式下的CLAIM存储的地址
plicinit
将所有设备的优先级设置为 1
1 | void |
plicinithart
对于每一个内核都为内核模式设置使能位为串口和虚拟磁盘设备,然后设置优先级阈值为 0,不会阻止任何中断
1 | void |
plic_claim
声明中断,也就是询问 PLIC 应该处理哪个中断,并且读取中断的设备 id 号
1 | int |
plic_complete
完成中断的处理,向其中写入完成中断处理的设备 id 号
1 | void |
文件系统
磁盘设备
当把数据传输到主存或者从主存中传输数据时,都是以字节为单位的。对于磁盘,使用更大的单位来传输,称作 BLOCK 块。在 xv6 中 BLOCK 是固定大小的字节,每一个块的大小为 1024 个字节 BSIZE ,其它系统用也会使用不同大小的块,但是其大小总是固定的。而磁盘只不过被视作块的序列,所以编号从 0,1,2 开始。第二个块也就是 BLOCK1 是一个特殊的块,包含 superblock ,它的内容是固定的,不会改变,包含很多参数,其中包含记录磁盘中块的数量的参数,也就是磁盘中有多少个块是可用的,以便存储在磁盘中文件系统
有时候会使用扇区 SECTOR 来进行数据的读写,有时候它们被用作同义使用,但是却是不同的事情,一般来说扇区比块要小一些。
但是如果让操作系统按照块的大小对磁盘进行读写,那就可以忽略磁盘驱动器不同的扇区的 大小,如果要对一整个磁盘或者块进行读写,这将导致设备驱动程序读写多个扇区。由于磁盘是一个旋转的设备,会有不同的延迟,对不同的扇区进行读写时,需要等待磁盘转动到特定的地方才能进行读写。通过将扇区分组为一个块就可以确保当读取或者写入大多数扇区时都是顺序读取的,所以就只需要确定第一个扇区读取的第一个位置就可以了,其它的读取都可以直接顺序进行,这就会极大的提高效率。
但是实际上使用块作为读写内存的单位,这将导致文件的最小大小就是一个块的大小,而且文件的最后一页也占据着一整块,这将导致内存的浪费,但是性能确实提高。
而在 xv6 中,使用的是 qemu 进行的系统仿真,所以其中的磁盘设备是 VIRTIO-DISK , 这个东西是标准化设备驱动程序和实际硬件之间的接口的尝试,有着不同的接口,例如 virtio , uart 以及其它 xv6 系统中不使用的一些东西
virtio_disk_rw
可以进行读写操作
- 读:
virtio_disk_rw(buf_ptr, 0) - 写:
virtio_disk_rw(buf_ptr, 1)
该函数第一个参数是指向缓冲区的 buff 结构的指针,并且这个缓冲区将包含足够的空间用于块(1024 bytes)。第二个参数就是操作的特定编号,0 表示读取,1 表示写入。在 xv6 中,该函数没有任何错误报告,也不会有任何返回值,如果出现任何故障,将会屏蔽故障,并且在函数中进行处理。如果发生簧片故障,校验和故障或者其它问题,那么扇区或者块就会重新读取,直到在模拟器中获取到数据。由于该磁盘是在主机上的文件系统模拟的,但是也会出现一些问题
这个函数可能会休眠,例如要读取一个缓冲区,该函数将进行读取操作,然后将进入 sleep ,当请求读取操作完成之后,磁盘将会发送一个中断,然后进入磁盘中断处理程序,并且将唤醒此函数,然后开始读写操作。需要注意的是,这个函数中的指令不会被编译器重新排序,而是完全按照调用该函数的顺序执行的操作
buf
这个结构体用于磁盘上块的缓存,结构体内有固定数量的缓冲区,这些缓冲区在内核启动时预先被分配,通过宏定义控制 buf 的数量。每一个 buf 结构体中都有一个块的内存(缓冲区),也就是 1024 bytes,每一个 buf 都有一个关于数据块的编号,用于确定位于缓冲区中的是哪个数据块中的内容。还有一些其它的字段用于同步
buf 可以是空闲的,也可以是被使用中,所以有一个空闲的缓冲区列表,其它的都是被使用中
1 | struct buf { |
bcache
缓冲区缓存 buff cache 是 buf 结构的链表,用于保存磁盘块内容的缓存副本。 在内存中缓存磁盘块可减少磁盘读取次数,并为多个进程使用的磁盘块提供同步点。
这个结构体是用来管理 buf 的,实际上是把 buf 组织成一个双向链表,如图
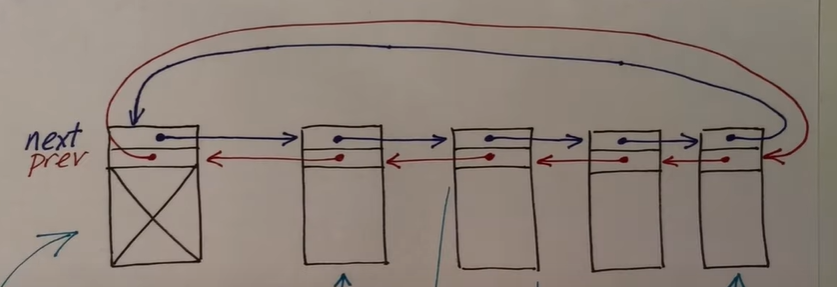
其中第一个是一个特殊的 buf 就是双向循环链表的头部,它不会包含任何数据,只是用于指向前一个或者是后一个的指针。而且结构体中一共有 30 个缓冲区,这些缓冲区在双向链表中的排序根据最近使用次数从大到小排序的,所以可以根据 head 的 next 指针找到最近使用的 buf ,根据 head 的 prev 指针找到最不常用的 buf 。使用双向循环链表来定位最近最少使用的元素,就可以轻松的删除一个元素。对于这个双向循环链表,只是在初始化的期间才会访问它。
1 |
|
其中的 lock 用于保护整个链表,其实就是保护 next, prev, refcnt, dev, blockno 等 buf 的元素,所以在获取缓冲区或者释放缓冲区时,都需要持有锁
该结构体有特定的接口
bread获取特定磁盘块的缓冲区bwrite更改缓冲区数据之后,将其写入磁盘brelse使用完缓冲区之后释放缓冲区,调用完之后不能再次使用对应的缓冲区- 同一个时刻只有一个进程能使用缓冲区,所以不要长期持有缓冲区
对于这个双向链表的维护,为了按照使用的次数排序,可以在每次使用时都将其取出,然后放入时就将其放到较为开头的部分,从而可以实现使用次数少的缓冲区都在双向链表的尾部
binit
这个初始化函数在内核启动时调用
buf 中有一些变量没被初始化,例如 refcnt, dev, blockno ,实际上这些变量被隐式初始化为 0
1 | void |
bget
寻找到一个对应设备号和磁盘块编号的缓冲区,如果没有,则从后往前找到一个引用数量为 0 的缓冲区,然后初始化该缓冲区,将其引用数量加一,然后设置为无效的缓冲区,之后会在 bread 中进行读取磁盘数据然后设置为有效的。在函数中会获得对应缓冲区的睡眠锁,因为会对缓冲区中的数据进行读写操作
在所有缓冲区中查看对应内存块的 buf ,如果未找到,需要分配缓冲区,无论哪种情况,都返回锁定的缓冲区。
1 | static struct buf* |
bread
该函数返回一个包含指定磁盘块内容的锁定的 buf
如果当前已经有一个 buf 包含着该磁盘的内容,那就直接返回,否则就需要重新从磁盘中读取数据,然后设置为有效的缓冲区
1 | struct buf* |
bwrite
向磁盘中写入缓冲区的内容,前提是必须持有该缓冲区的锁,用于保证每次只有一个进程对磁盘进行写入,防止发生数据竞争。该函数并不会释放缓冲区
1 | void bwrite(struct buf *b) { |
brelse
释放锁住的缓冲区,将缓冲区移动到双向循环链表的头部
1 | void brelse(struct buf *b) { |
bpin
固定缓冲区,或者说向缓冲区添加引用,如果其他人已经正在使用该缓冲区,可以使用该函数直接增加引用数
1 | void bpin(struct buf *b) { |
bunpin
取消固定缓冲区,向缓冲区减少引用,允许其它线程来释放该缓冲区
1 | void bunpin(struct buf *b) { |
磁盘日志文件系统
文件系统崩溃
首先看文件系统的崩溃
- 复杂的数据结构
- 一个更新需要几个写入的操作
- 在其中可能会发生崩溃
- 数据结构可能处于一个不一致的状态
例如一个单向链表,需要更改两个节点之间的位置,就需要更改三个指针,所以当崩溃发生在更改某一个指针时,这就会导致链表的顺序发生错误,也就是文件系统的数据结构出现了不一致的情况
这个问题要去解决需要解决文件系统的问题
- 数据结构保存在磁盘上,并且用于表示文件,目录,
i-nodes和空闲映射 - 每次写入都会更新一整个块,并且特定的更新可能涉及多个块,可能需要将多个块写入磁盘
- 每次的崩溃都不允许将文件系统弄乱
所以就是在发生更新时执行所有更改,没有发生更新时不执行任何更改
具体例子
对于一个文件,希望能增大文件的大小,需要两个操作
- 从空闲池列表中删除一个块
- 将块添加到文件后执行数据结构更新
这两个操作需要获得两个锁,空闲池链表的锁和块的锁。但是这时候计算机崩溃了,一个写入操作完成了,但是第二个操作未完成,那文件系统就会处于不一致的情况下
方法1
如果按照上述的顺序来执行,从空闲池中删除完一个块了,但是在添加到文件中之前计算机崩溃了,这将导致永久的丢失了一个块的内存,这样是肯定不行的。
方法2
先将块添加到文件中执行完数据结构更新,再从空闲池列表中删除。如果在添加完成之后发生崩溃,重启之后就会发现有一个块既处于空闲池列表中,也存在于文件中,这也是一个大问题
目标
要么两个操作都完成,要么两个操作都不执行
更普遍来说,将几个磁盘的更新分为一个事务组,每一个事务组要么什么都没有发生,要么已经执行结束
在 xv6 中的实现
调用程序的顺序就是
begin_op → bread → … → bread → … → log_write → … → log_write → … → end_op
在这个流程中, begin_op 相当于就是整个事务开始执行,然后 end_op 就是整个事务执行结束,而在最后的 end_op 将会将整个事务提交,进行更新,所以就是整个事务要么都发生,要么不发生,这操作就是延迟对磁盘的实际写入,将这写写入操作几乎放在一起完成
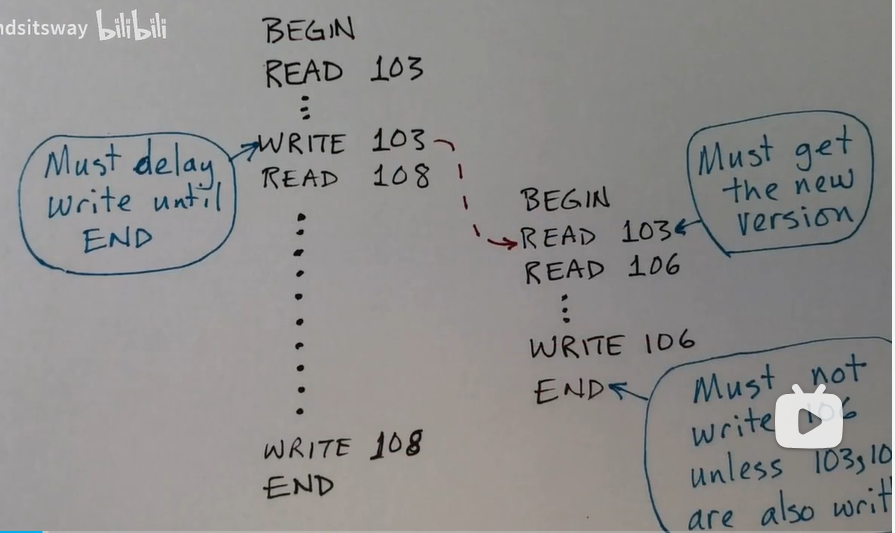
如图所示,在右侧的 END 处不进行写入 106 的操作,除非 103 和 108 写入操作也在执行,而且需要将 103 的写入操作移动到最后 END 处,与 108 写入操作一起执行。所以就是多个磁盘写入操作同时执行。直到这个事务的所有操作完成之后才进行提交操作
上述中所有事务操作都包含 begin , read , write , end 四个操作
begin这个操作是在begin_op函数中完成的,每一个事务的开始都需要调用该函数。如果另一个线程正在提交状态,那就进入睡眠等待。如果没有足够的日志块,那就进入睡眠等待。当一切正常时就增加一个计数器,这个计数器就是记录当前正在进行多少事务read实际上就是调用bread,查找缓冲区高速缓存,如果找到对应的磁盘区的缓冲区就直接使用,否则重新选择一个缓冲区并且从磁盘中读取write这个操作就是调用log_write来实现的。先 PIN 固定缓冲区,基本上就是给缓冲区设置一个标志来指示这个缓冲区不应该被释放。然后找到下一个可以使用的日志块,在header的日志数组中添加条目,然后将使用日志的数量增加- 实际上首先会先查找需要写入的块是否已经存在于日志块中,因为正在写入的块可能已经被写入,所以就直接使用该日志块就可以。
end实际上是调用end_op函数。需要减少计数器,如果计数器 > 0,那就什么都不做,立即返回。否则就意味着这是最后一个事务,可以继续进行提交,提交操作将执行所有写入操作,而在写操作中并没有实际写入磁盘,只是将内容保存到内存中。写入之后清空日志,可以唤醒所有被卡在begin操作的进行
磁盘分布
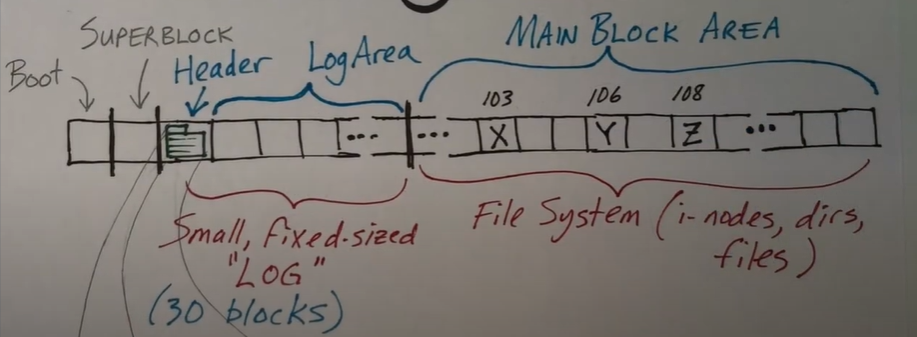
其中每个小方块都代表着磁盘上的一个块,而磁盘不过是一组连续的块
- 其中
Boot是引导记录或者主引导记录 SUPERBLOCK包含很多固定参数,是只读的,在启动时内核将读取这个块,其中还包含日志块开始的位置以及数量,主块区开始的位置以及数量和磁盘上一共有多少个块- 其中日志块是由一个标头和一块用于存储多个日志块的地址,在 xv6 中正好是 30 块,实际上日志块并不会考虑主块区域的组织形式,所以在它看来不过是一组块的集合
- 标头块在启动时被读入内存并且存储在一个结构中,所以这是保存在内存中的结构体,并且时不时的需要写回到磁盘上。包含一个计数
n,用来存储正在使用的日志块的数量。并且每一块日志在数组中都有一个条目,所以这个计数n用于说明多少个日志块正在被使用,数组元素正在使用中
- 标头块在启动时被读入内存并且存储在一个结构中,所以这是保存在内存中的结构体,并且时不时的需要写回到磁盘上。包含一个计数
- 主块区域是文件系统的存储位置,文件系统包含各种内容,目录,文件,索引节点等
Commit
这个操作涉及到四个函数
commit提交操作write_log写入日志write_head写入日志标头install_trans将被提交的块复制到磁盘中
提交有两个阶段
- 将块的更新的版本移动到磁盘上的日志区域中,然后将日志表头写入磁盘,如果崩溃发生在写入标头之前,这些操作将不会发生,如果在写入标头之后,这些操作将会成功执行
- 遍历日志数组,将块写入磁盘的主块区域。写入完成之后,将
header中的计数器设为 0,然后将其写回到磁盘中
Crash + Reboot
重启需要调用的函数
initlog初始化日志文件fsinit初始化文件系统recover_from_log从日志中恢复install_trans将被提交的块复制到磁盘中read_head读取日志标头write_head写入日志标头
发生崩溃之后重启,进行的操作有
由于重启是不知道系统是否崩溃的,所以无论是否发生过崩溃,开机时都会读取日志标头。
- 如果标头的计数器为 0,那就什么也不做,也就是进行的事务由于崩溃而丢失,将被忽略,这样事务或者提交就不会发生。
- 如果标头的计数器不为 0,那就是成功将标头数据写入到了磁盘中,所以需要重新进行提交的第二个操作,以保证所有的内容都被写入到了主存中
一旦成功,就可以将标头的计数器设为 0,然后将标头写入到磁盘中
logheader
日志标头,包含一个计数器 n 和 LOGSIZE 个日志块
1 | struct logheader { |
log
所有与日志操作相关的变量都集合在这个结构体中,而且这个结构体只有一个实例
1 | struct log { |
其中
lock用于保护outstanding和committing两个变量start表示日志在磁盘上开始的位置,常量,实际上是日志标头的地址size表示日志在磁盘上的大小,常量outstanding一个计数器,每次执行开始操作时,都会增一,执行结束操作时都会减一committing一个布尔量。如果正处于提交中,这个标志位将置为true,这会导致其它操作处于等待状态dev设备,一般来说一个设备对应着一个log结构体,但是在 xv6 中只有一个磁盘设备,但是依旧保留了此字段,用于表示当前日志是哪个设备的日志
initlog
初始化日志,这个函数在内核启动时被调用,这个函数被 fsinit 函数调用,而 fsinit 在第一次调用 forkret 函数时调用。在这个函数中需要执行一些恢复操作,执行恢复操作时可能需要访问磁盘,这就涉及到了 sleep ,所以需要在用户模式下运行,所以在 forkret 中调用。这个函数在第一个时间片中调用,作为用户模式的第一部分运行
传入的参数为
dev初始化的设备编号sb对应的superblock的地址
函数中做的操作:首先初始化锁,初始化一些固定的变量,之后从日志中恢复数据。在 recover_from_log 中会先读取头块,如果 n 非 0,它将执行恢复操作
1 | void |
begin_op
每一个事务开始时需要调用,这个函数主要做的就是增加未完成的事务的计数器,该计数器受到 log.lock 这个自旋锁保护。首先需要检查是否有其它线程正在提交,是否有足够的日志块来执行该事务,不满足条件就会进入 sleep ,并且将 log.lock 短暂的释放掉,当其它进程完成提交操作之后就会唤醒该进程,被唤醒之后还需要重新检查是否满足条件。
1 | void |
log_write
在调用时已经修改 b->data 并且完成缓冲区,通过增加 refcnt 在缓存中记录块号和 pin ,实际上这个函数并不执行实际的写入操作,但是会安排这个写入操作,可能会做更多的修改,并且再次调用 log_write 操作写入
1 | void |
end_op
用于事务结束的操作,会在每个文件系统系统调用之后执行,如果当前事务是最后一个事务,提交数据,也就是把数据写入磁盘中
1 | void |
commit
提交操作
1 | static void |
write_log
将修改后的块从缓冲区写入到日志文件中,这个函数仅仅在 commit 中调用
1 | static void |
write_head
将日志标头写入到磁盘中
1 | static void |
install_trans
在 commit 函数中被调用,从日志中复制提交的块到磁盘空间中,将缓冲区中对应的块写入到对应的磁盘区域中。如果在提交函数中调用 recovering=false ,如果在恢复函数中调用就是 recovering=true
1 | static void |
recover_from_log
从日志中恢复数据,这个函数仅被 initlog 调用,只在初始化时调用
1 | static void |
read_head
从磁盘中读取日志标头结构体,仅被 recover_from_log 中调用
1 | static void |
文件系统
磁盘布局
在磁盘上只有一组连续的磁盘块,对磁盘操作的几个函数
bread提供磁盘的块号,它从缓存中分配一个缓冲区,将磁盘块读入内存并且返回一个缓冲区指针,log_write提供一个指向缓冲区的指针,将缓冲区的数据写回到磁盘上。实际上这个函数并不执行实际的写入操作,但是会安排这个写入操作,可能会做更多的修改,并且再次调用log_write操作写入brelse释放该磁盘块的缓冲区,在bread与brelse之间,缓冲区被强制独占,该缓冲区只有该线程可以访问
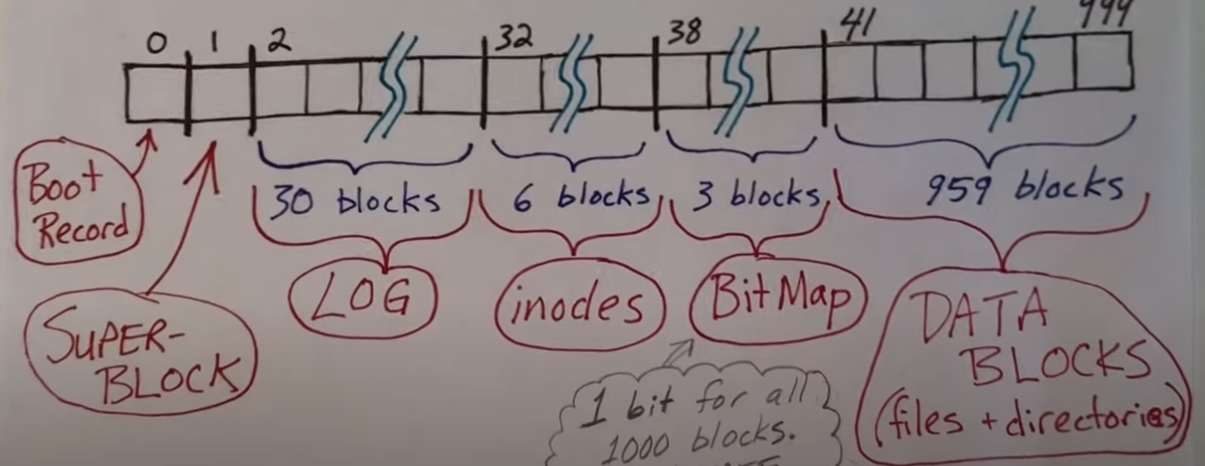
这是更加细致的磁盘布局
Boot Record引导块,既不被内核读取,也不修改的块,仅在引导和启动过程中使用,以便将内核加载到内存中SUPER BLOCK里面包含很多参数,被内核读取,但是不会被修改,记录磁盘上其它项目的位置Log日志块inodes每个inode都是固定大小的,并且被存储到一个数组中,数组被保存在这些块中,这些块仅用来分配inode的存储BitMap在这里面,磁盘上的每一块都对应着一个位,用来表示该块是否正在使用,这对于数据块很有用。但是这里面只有 1000 个块,也就有 1000 个位与之对应,其中前 41 个块都是被使用中- 1:被使用中
- 0:空闲
Data Blocks这里是文件和目录实际存储的地方
文件系统
文件系统包含一个单个目录树以及其中的一堆文件。而所有的这些目录都位于一个设备上,例如磁盘或者 USB 驱动器。目录被组织为一棵树,没有循环,但是不是有向无环图。
下图是一个文件系统的示例,其中红色表示文件目录,绿色表示文件。可以看出目录是一棵树,除了根目录以外,每个目录都有父目录。对于文件来说可能有多个父目录。如图所示,文件并没有文件名,只是通过路径来引用它,还可以用另一个路径引用同一个文件
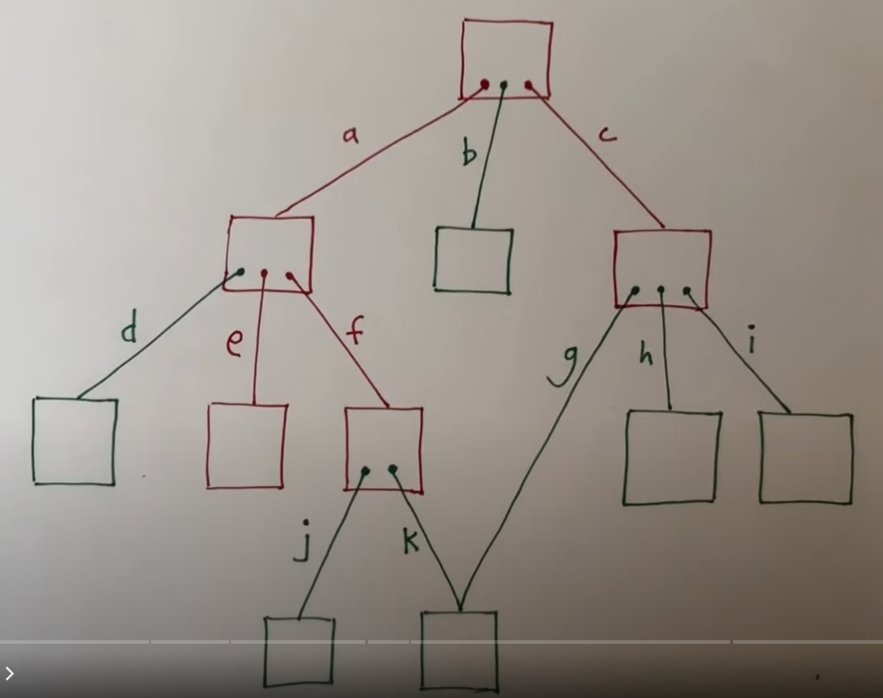
由于目录本身就是一个文件,所以在 xv6 中多种文件类型
- 常规文件
- 目录
- 设备
但是在 unix/linux 中实现了其它的标准的文件系统 POSIX ,但是这些在 xv6 中是无法使用的。例如
char deviceblock devicesymbolic linknamed pipesockets
POSIX
POSIX(Portable Operating System Interface,可移植操作系统接口)是由 IEEE(Institute of Electrical and Electronics Engineers)定义的一组操作系统接口标准。它的目标是为应用程序提供一套与操作系统无关的接口,使得这些应用程序能够在不同的 POSIX 兼容系统上编译和运行。
POSIX 标准包含了进程管理、文件管理、网络通信、线程和同步、信号处理等方面的功能。这些接口定义了函数、数据类型和常量等,为开发者提供了一个可移植的方法来与操作系统进行交互
POSIX 接口的设计基于 Unix 操作系统的经验和理念。它通过定义一组通用的 API,将底层操作系统的功能封装起来,从而提供了与具体操作系统无关的高级功能。
POSIX 接口定义了一系列函数、数据类型和常量,这些接口分为不同的模块,涵盖了进程管理、文件管理、网络通信、线程和同步、信号处理等各个方面的功能。开发者可以使用这些接口来编写可移植的应用程序,而无需关心底层操作系统的实现细节。
以下是 POSIX 标准定义的主要接口,包括 ioctl 接口
- 进程管理接口
exit:进程终止fork:创建子进程wait:等待子进程结束
- 文件管理
open:打开文件close:关闭文件read:读取文件内容write:写入文件内容
- 目录管理
opendir:打开目录readdir:读取目录项closedir:关闭目录
- 网络通信
socket:创建套接字bind:绑定套接字到地址listen:监听传入连接accept:接受传入连接
- 线程和同步
pthread_create:创建线程pthread_join:等待线程结束pthread_mutex_lock:加锁互斥量pthread_cond_signal:发送条件变量信号
- 信号处理
signal:注册信号处理函数kill:向进程发送信号sigaction:设置信号处理动作
- 时间和日期
time:获取当前时间clock:获取时钟时间strftime:格式化时间
- 共享内存
shmget:获取共享内存标识符shmat:连接到共享内存shmdt:分离共享内存
ioctl接口ioctl:控制设备操作
POSIX 接口在很多场景中有广泛的应用,为开发者提供了一种标准化、可移植的方法来编写应用程序
- 系统编程:POSIX 接口提供了开发者直接访问底层操作系统功能的能力,适用于系统级别的开发任务
- 跨平台开发:POSIX 接口的可移植性使得开发者能够在多个 POSIX 兼容的操作系统上进行编译和运行,从而实现跨平台开发
- 高性能计算:POSIX 接口提供了线程和同步机制的支持,适用于并行和并发的高性能计算任务
- 嵌入式系统开发:POSIX 接口的轻量级特性使其成为嵌入式系统开发的重要工具,可以方便地控制硬件资源和执行实时任务
Hard Links
在 xv6 和 unix/linux 中都实现了硬链接。常规文件有多个指向它的硬链接,也就是一个常规文件可以有多个父项。但是每个目录文件只能有一个父项,就是说文件系统必须是一棵树,不能是一个图。硬链接需要所有的链接的文件都位于一个文件系统中
Symbol Links
符号链接有时候称作 soft link 软链接,但是在 xv6 中没有实现软链接。符号链接就是另一种文件类型。符号链接的文件中没有包含数据,只是包含了一个路径名,当用到该链接文件时,就直接使用链接文件中目录来定位目标文件的位置。而且符号链接可能会有错误,也就是链接的是一个不存在的路径。符号链接一个有点就是可以指向其它文件系统中的某一个设备文件
i-number
每一个文件有一个不唯一的路径名称,可以更改,是内核使用一个数字来识别和处理文件,也就是 i-number ,这个数字是一个整数,在创建文件时将其分配给文件,当文件被删除之后,可以将其回收,重新用于新的文件。对于目录是有固定的 i-number ,为 1,以便内核可以定位根目录。文件系统的编号从 1 开始,用 0 表示未使用
i-node
是一个小型的固定大小的结构体,保存在磁盘上,不保存在任何文件中,保存在磁盘中单独的某个区域内,因此在磁盘的某个位置本质上有个数组,该数组中有多个 i-node 结构体,当调用文件时,内核将会把 i-node 的数组加载到缓存中。这个结构体被保存在有编号索引的数组中,所以对应的编号就是隐式的编号。
1 | struct dinode { |
其中
type文件类型- 0:free,空闲的,可用于之后的文件
- 1:
T_DIR目录文件 - 2:
T_FILE常规文件 - 3:
T_DEVICE设备文件
major主设备号,只在T_DEVICE文件类型中有效,是一个标识符,用于表示设备的类型minor次设备号,只在T_DEVICE文件类型中有效,表示设备的编号- 主设备号与次设备号本质上就是设备号,设备号是 32 为整数,分为两个 16 位整数,高 16 位表示主设备号,低 16 位表示次设备号
nlink在文件系统中,链接该文件的数目,也就是硬链接的数量size文件的大小,单位是字节addrs磁盘上块序号的队列
文件的属性
与每个文件相关联的有几个属性
i-number用于唯一标识每个文件size需要知道问价的大小,多少个bytestype用于说明文件的类型(directory,regular,device)number of hard link硬链接的数量,也就是在树中父级的数量。如果没有硬链接,那就无法引用到该文件,所以当硬链接数量为 0 时,就会将文件的内存空间回收location on disk数据在磁盘上存储的位置,基本上是有一个块号列表,用于存储文件数据用到的块号
在 unix/linux 中有一些其他的附加属性
modification date/timestamp文件创建的时间和最后修改的时间owner文件的拥有者permissions指示文件权限的标志,用于告诉用户如何访问该文件
Super Block
这个结构体中包含了一些属性,只会被内核读取,但是不会被修改
magic只是一个常量,系统在读取时,会检查这个数字以确保它具有正确的值。如果不是,可能表明这不是我们期望的文件系统类型或者出现了严重错误:0x10203040size在整个磁盘系统中一共有多少个块可用1000nblocks数据块的数量959ninodesinode的数量,这意味着文件的数量不能超过这个数字200nlog日志块的数量30logstart日志块开始的块号2inodestartinode块开始的块号32bmapstartbitmap开始的位置38
这个结构体在启动时从磁盘读取,通过 readsb 来读取,然后它将永不会改变
1 | struct superblock { |
目录
目录存储在文件中,因此对于每个目录都有一个文件,并且该文件包含许多块,目录信息是存储在这些块中的内容。
在 xv6 中目录表示位数组,每个数组条目都对应着一个名称和文件的引用编号。其中这个名称是不能大于 14 个字符的,对目录的查找就是将空字符作为名称的结尾的字符串的匹配,遍历寻找对应的文件名称。但是这样的查找效率太低了,所以最新的 unix/linux 对目录有着不同的组织结构,可以容纳更长的文件名称,而且也允许更快的查找
1 | struct dirent { |
mkfs
make file system 建立文件系统
它是独立的 C 程序,不属于 xv6 内核的一部分,也不是在内核模式下运行的一个用户程序。在主机上编译运行,当运行 make 文件时,它会编译 xv6 内核并且编译所有用户模式程序,并且还会编译此程序,并且运行此程序
它将创建磁盘映像文件,磁盘映像文件名为 fs.img ,这是主机上的一个文件,将会被 qemu 来模拟磁盘,所以磁盘的所有内容都将保存在该文件系统,每当对磁盘进行读写操作,实际上都是对该文件的操作。将会初始化磁盘,并且创建整个文件系统,创建目录树,并将许多文件放入其中,所以当内核启动时,会发现文件系统已经存在。初始化磁盘所做的事情为
- 写入
superblock - 初始化所有的
inodes - 初始化
bitmap - 创建目录结构,并且初始化目录文件
- 对于用户文件,即用户模式可执行文件,将会创建一个文件,并将其添加到文件系统目录中
所以执行结束之后,映像文件将包含一个完整的文件系统,以便内核可以启动并找到文件系统。在 unix/linux 中也有类似的函数,不过不是初始化 fs.img 文件,而是初始化设备,它将会编写初始化该文件结构的组织所需要的任何内容,这将会比 xv6 更加复杂
dinode
数组 dinode 从特定编号的块开始,这个值位于 spuerblocks 中,用于找到该数组的起始位置,它们之间尽可能地紧密排列在一起,在一个块中放入尽可能多的 inode ,然后剩下的空间就是空闲的空间
1 | struct dinode { |
其中
type文件类型- 0:free,空闲的,可用于之后的文件
- 1:
T_DIR目录文件 - 2:
T_FILE常规文件 - 3:
T_DEVICE设备文件
major主设备号,只在T_DEVICE文件类型中有效,是一个标识符,用于表示设备的类型minor次设备号,只在T_DEVICE文件类型中有效,表示设备的编号- 主设备号与次设备号本质上就是设备号,设备号是 32 为整数,分为两个 16 位整数,高 16 位表示主设备号,低 16 位表示次设备号
nlink在文件系统中,链接该文件的数目,也就是硬链接的数量,一般来说根目录的链接数为 0size文件的大小,单位是字节,只在T_FILE文件类型中有效addrs磁盘上块序号的队列,正好有 12 个。如果文件大小增长超过 12 个块的大小,那就会使用间接块,因此最后一个指针可以指向磁盘上的某一块,这一块中存储的就是其他磁盘的块号或者是指向其它块的指针。由于块号大小为 4 字节,所以可以将 256 个额外的指针打包进去。所以在 xv6 中,文件的限制大小是有限的。但是在 unix/linux 中,会有二级间接块甚至三级间接块,也就是间接块中的每个块号都是指向的一个间接块,这样得到的最大文件大小会很大。但是在 xv6 中只有一级间接块
在内存中有关于 dinode 的缓存结构,是一个大小为 50 的 inode 数组,当初始化时,磁盘中会保存 dinode 的数据,而在使用 dinode 时,就会先将其从磁盘中读出来,放在内存的这个缓冲区中。
itable
这里是个 inode 的数组,用于存放 inode 的缓存,一共是 50 个缓存
1 | struct { |
缓存inode
这里面存储的就是 inode 的缓存
1 | struct inode { |
实际上这个缓存 inode 与之前的块的缓存是类似的,其中
dev设备号,用于识别文件inuminode的编号,用于识别文件,在每一个文件系统中都是唯一的,如果有多个文件系统,就需要靠着dev来识别文件了ref引用数量,如果是 0,那就说明是空闲的,可以用于缓存不同的索引节点lock睡眠锁,将会保护valid和下面的inode字段valid是否有效,用于设置是否数据已经从磁盘中读入了,只有是 1 的时候才是读入完成
剩下的就是 dinode 的内容了。其中 dev , inum , ref 这些都受到 itable 中的 lock 的保护
devsw
是一个数组,正好包含 10 个元素,由 NDEV 给定,主设备数,实际上,每个元素在数组中的排序就是它的设备号。每一个数组元素都是一个结构体,结构体中包含两个函数指针
1 | struct devsw { |
例如,其中 1 号元素就是控制台 console ,所以这个函数指针就会指向 consoleread 和 consolewrite ,本质上控制台就是 1 号设备
对于上述的函数,其中
- 参数1:一个布尔值
- 0:内核地址
- 1:用户虚拟地址
- 参数2:地址
- 参数3:字节长度
由于上述函数是函数指针,所以对于不同的设备,可以使用不同的函数
fs.h
ROOTINO文件系统根块的地址BSIZE块的尺寸superblock在启动时读入的块,包含许多不改变的参数FSMAGIC只能赋值给superblock.magicNDIRECT直接块的数量NINDIRECT间接块的数量MAXFILE最大文件数量,是由NDIRECT与NINDIRECT决定的dinode在磁盘上的inode结构体,其中addr是个 13 个长度的数组IPB每一块中inode的数量,如果不能正好放进去,那就会有一点空闲空间,由块的大小和结构体的大小决定IBLOCK磁盘上哪个块包含特定的inodeBPB每一块中包含的bitmap的数量,一个bitmap是一个位BBLOCK磁盘上的那个块包含着特定的bitmapDIRSIZ目录的大小,也就是文件的大小,不能超过 14 个字符dirent目录,包含着编号inode number和目录名称
fs.c
这个文件中的所有函数都是默认在一个事务中处理的
itable保存inode缓存的结构体,有一个自旋锁和一个将用于缓存的inode数组superblock sb这个结构体应当是每个设备都对应一个,但是在 xv6 中只是用一个设备,所以只有一个
file.h
file文件结构体,定义了一些关于文件的东西,之后再说major主设备号位于设备号的高 16 位minor次设备号位于设备号的低 16 位mkdev创建设备号inode位于内存中的inode结构体,实际上用作缓存devsw映射主设备号到对应的设备功能上,每个结构包含两个函数指针CONSOLE定义控制台的设备号为 1
file.c
devsw主设备数组
either_copyout
复制到用户地址或内核地址,具体取决于 user_dst 。成功时返回0,错误时返回-1
其中
user_dst布尔值,表示目标地址是用户地址或内核地址- 1:用户虚拟地址
- 0:内核地址
dst目标地址src源数据len传输数据长度
1 | int either_copyout(int user_dst, uint64 dst, void *src, uint64 len) { |
either_copyin
从用户地址或内核地址复制,具体取决于 user_src 。成功时返回0,错误时返回-1
其中
dst目标地址user_dst布尔值,表示源数据地址是用户地址或内核地址- 1:用户虚拟地址
- 0:内核地址
src源数据地址len传输数据长度
1 | int either_copyin(void *dst, int user_src, uint64 src, uint64 len) { |
iinit
用于初始化 inode 缓存
1 | void |
fsinit
初始化文件系统,包括调用 readsb ,读取 superblock 数据,从磁盘中读取,并将其存储在 sb 结构体中。传入的参数为
dev设备号,初始化对应设备的文件系统
1 | void |
readsb
从磁盘中读取对应文件系统的 superblock 数据,并将其存储在 sb 结构体中
dev设备号,对应文件系统sb用于存储对应文件系统的superblock数据
1 | static void |
bzero
将一整个块都写入 0,这将写入磁盘,这个函数仅在 balloc 中调用。传入的参数为
dev设备号bno块号
1 | static void |
balloc
在分配块的时候使用,分配一个置零的磁盘块。如果磁盘空间不足,则返回 NULL 。查找一个未使用的块,并且在 bitmap 中置 1,指示它正在使用,并且返回块的编号,参数为
dev设备号,也就是从对应的文件系统分配一个块
1 | static uint |
实际上这个函数的搜索做的并不是很好,例如:查找空闲的位图可以按字来搜索,是否为 0xff ,否则就包含空闲块,按位搜索太费时间。而且这里是使用线性搜索,遍历所有的位来找空闲位,实际上太费时间了。可以利用链表+栈来实现,将空闲的块放入栈中,每次分配都从栈中推出,然后进行分配,每一个链表的元素都是一个栈(块),当这个元素分配完之后再进行下一个栈的分配,回收就是反过来
bfree
使用完块之后需要释放掉,将对应的块号放回到对应的文件系统中,文件中的块返回空闲池,释放时只需要找到位图中的对应位并且更改它就可以了
dev设备号b对应的块号
1 | static void |
ialloc
在创建新文件时使用,在对应的文件系统中分配一个 inode ,返回一个指向分配的 inode 的指针。
具体内容就是从磁盘上找到一个未使用的 inode ,用 type=0 来表示空闲,然后设置类型来指示已经被使用,然后调用 iget 并且返回一个指向 inode 的指针
在设备 dev 上分配一个 inode ,通过给它类型 type 将它标记为已分配。返回一个未锁定但已分配和引用的 inode ,如果没有空闲的 inode 则返回 NULL
该函数仅在创建文件的系统调用 create 中调用,用来创建一个 type 类型的新文件
传入的参数
dev对应的文件系统,在那个文件系统创建文件type新文件类型
1 | struct inode* |
iget
查找设备 dev 上编号为 num 的 inode 并返回内存副本(缓存)。不锁定 inode ,也不从磁盘读取它
如果对应编号的 inode 正处于缓存中,那就使用它,否则直接返回一个新的 inode 并且设置好,但是不从磁盘中读取,不论如何都会将其引用数量 +1,用以指示它是被使用中。但是未从磁盘中读取,也不锁定,把它的 valid=0 ,用来表示没有从磁盘中读取,还是无效的
传入的参数为
dev设备号inum对应的inode编号
1 | static struct inode* |
ilock
给对应的 inode 上锁,如果它是无效的 inode ,就从磁盘中读取,存储到这个缓存中
传入的参数
ip指定的inode
1 | void |
iunlock
给对应的 inode 解锁,释放其睡眠锁
传入的参数
ip指定的inode
1 | void |
iupdate
将修改后的内存 inode 写回到磁盘。必须在每次更改 inode 的字段后调用。调用方必须持有该 inode 的锁。
传入的参数
ip指定的inode
1 | void |
idup
需要增加引用计数时可以调用该函数,这个引用计数受到 itable.lock 的保护
传入的参数
ip指定的inode
1 | struct inode* |
iput
删除对内存中索引节点的引用。如果这是最后一次引用,则可以回收 inode 表项。如果这是最后一个引用,并且 inode 没有指向它的链接,则释放磁盘上的 inode (及其内容)。所有对 input 的调用都必须在事务内部,以防必须释放索引节点
如果该 inode 的引用数为 1(表示当前是最后一个引用的文件了)并且硬件链接是 0,就会释放掉这个 inode 和与之相关的空间。锁上这个 inode ,将文件长度截断为 0,并将其文件类型设置为 0 以表示未使用,调用 iupdate 更新 inode ,将其写回到磁盘中,释放掉锁
传入的参数
ip指定的inode
1 | void |
iunlockput
释放对应的 inode 的锁,并且调用 iput 函数
传入的参数
ip指定的inode
1 | void |
bmap
索引节点的内容。与每个 inode 相关联的内容(数据)以块的形式存储在磁盘上,第一个 NDIRECT 块编号列在 ip->addr[] 中。下一个 NDIRECT 块列在块 ip-> address[NDIRECT] 中。返回 inode ip 中第n块的磁盘块地址。如果没有这样的块, bmap 会分配一个。如果磁盘空间不足,则返回 0。
函数会查找直接的和间接的指针,用来定位磁盘上的块,它将会计算其块号。如果对应的块号没有被分配(不在文件中),那将会分配一个空闲的块,然后更新 inode 将该块添加到该文件 inode 中,并且会将该块归 0
该函数仅在 readi 和 writei 中被调用,在 readi 中不会分配块,而在 writei 中可能会分配块
传入的参数
ip指定的inodebn需要申请的第几个文件块,如果超过了直接引用的块数,那就放在间接引用中,如果也满了,就会报错
1 | static uint |
itrunc
截断 inode 文件大小为 0,会丢弃其中的内容,释放所有的数据块,设置大小为 0,调用 iupdate,调用该函数时必须持有该 inode 的锁.
传入的参数
ip指定的inode
1 | void |
stati
只是将一些数据从缓存 inode 中复制数据到 stat 中去,调用者必须持有该 inode 的锁
传入的参数
ip指定的inodest指定的stat
1 | void |
readi
从 inode 读取数据到目标地址。调用方必须持有该 inode 的锁,成功的话返回写入的字节数,如果写入失败就返回 -1
传入的参数
ip指定的inodeuser_dst布尔值- 1:用户虚拟地址
- 0:内核地址
dst目标地址off从文件中获取数据的偏移量n传输的字节数
1 | int |
writei
从源数据地址写入数据到 inode 对应的文件中,调用方法时必须持有锁,返回成功写入的字节数,如果小于 n 意味着出错了
传入的参数
ip指定的inodeuser_src布尔值- 1:用户虚拟地址
- 0:内核地址
src源数据地址off向文件中写入数据的偏移量n传输的字节数
1 | int |
namecmp
用于比较文件名称是否相同,直接调用字符串比较,比较的最大值就是 DIRSIZ 就是名称的最大字符数——14 字节
1 | int |
dirlookup
在缓存中的目录中循环查找文件名,如果找到,调用 iget 给该文件的 inode 添加一个缓存,保存文件入口的地址到 poff 中,返回找到的文件的 inode ,否则返回 NULL
传入的参数
dp指向该目录文件的缓存inode的指针name查找的文件的名称poff用于存储找到的文件的入口或者偏移地址
1 | struct inode* |
dirlink
在目录 dp 中写入一个新的目录条目 (name, inum) 。成功时返回 0,失败时返回 -1(例如磁盘块耗尽或者当前目录中已存在这个条目)。并且此函数根据需要从磁盘进行读取以进行检查,添加条目之后,将以以下方式将其写回磁盘
传入的参数
dp指定的目录的inodename新目录条目的名称inum对应目录的inode编号
1 | int |
skipelem
不是访问磁盘的函数,不执行任何读取或者写入,它只是一个字符串处理函数,帮助解析路径名。传入一个指针,内存某处路径名称的字符串。该函数会处理这个路径,会找到第一个元素所在的位置,并将其存储在 name 中,然后 path 指向下一层的目录
例如 path=/a//b//c, name ⇒ name=a, path= b//c
如果 path 是空的,那就返回 null
path传入的路径名称name存放路径名称的变量
1 | static char* |
namex
查找并返回索引节点以获取路径名,将在磁盘上找到这个路径指定的文件或者父级目录。如果 parent != 0 ,则返回父节点的索引节点,并将最后的 path 元素复制到 name 中,该元素必须有容纳 DIRSIZ 字节的空间。必须在事务中调用,因为它调用 input()
传入路径名称,它将在磁盘上找到这个文件,并且将其 inode 添加到 inode 缓存中,并且返回一个指向缓存的 inode 的指针,这样 inode 将被存入缓存,并且引用计数将会增加,如果没有找到,那就会返回 -1。返回有效值不会减少引用计数,否则减少引用计数,在循环内返回需要解锁,循环外返回不需要解锁。
path传入的路径nameiparent是否查找目录的上一级name存放路径名称的变量
1 | static struct inode* |
一个小例子
对于需要的路径 \a\b\c 来说,由于是根目录下的路径,然后获得根目录的 inode ,之后进入循环
- 第一次循环,进入循环内时
path=b\c, name=a, ip=rootinode - 第二次循环,开始循环时
path=c, name=b, ip=a_inode - 第三次循环,开始循环时
path=\0, name=c, ip=b_inode- 此时需要返回父目录的
inode的话,就可以返回ip了,对应的name就是该子文件名称
- 此时需要返回父目录的
- 第四次不进入循环,得到
ip=c_node, path=\0, name=c- 此时返回的
ip就是该文件的inode,对应的name就是该文件名称
- 此时返回的
namei
传入路径名称,它将在磁盘上找到这个路径指定的文件,并且将其 inode 添加到 inode 缓存中,并且返回一个指向缓存的 inode 的指针,这样 inode 将被存入缓存,并且引用计数将会增加,如果没有找到,那就会返回 -1。
直接调用 namex
path传入路径
1 | struct inode* |
nameiparent
传入路径名称,找到这个路径指定的文件的上一级目录,例如查找 a/b/c 找到的为 b ,并且将其 inode 添加到 inode 缓存中,并且返回一个指向缓存的 inode 的指针,这样 inode 将被存入缓存,并且引用计数将会增加,如果没有找到,那就会返回 -1。该函数将会在 name 中保存传入条目所指向的文件的名称,上述例子中返回 c
直接调用 namex
path传入的路径nameiparent是否查找目录的上一级- 1:查找到目录的上一级
- 0:查找到当前目录文件
name保存父目录的名称变量
1 | struct inode* |
管道
在 Unix 中,管道有点像文件,可以向其中写入数据,也可以从其中读取数据,唯一不同的就是,文件保存在磁盘上,而管道保存在内存中。在管道中,一个进程可以向管道内写入数据,而其它进程就可以读取,管道数据保存在内核内存中某个缓冲区中,并且该缓冲区的大小有限,因此如果写入太多的数据到缓冲区中时,内核需要暂停写入,直到缓冲区不再满了,而且其它进程读取管道的数据时,管道空了,内核将会把该进程挂起
与分配文件 inode 缓存不同,每当需要申请分配一个新的管道时,内核都会调用 kalloc 并分配整个页,用完之后返回空闲池。这个结构仅仅使用不到 1k 的内存,剩下的都不被使用,所以可能需要考虑更好的办法来存储 pipe
pipe
在每个打开的管道中,内核将分配一个管道类型的结构体
spinlock自旋锁,用来保护pipe中其它的字段data512 字节的缓冲区,用来存放写入管道的数据,是一个循环的缓冲区,所以两个索引都需要对 512 取模nread索引值,在缓冲区中的读索引,指向下一个读取的数据nwrite索引值,在缓冲区中的写索引,指向下一个写入的位置readopen读取的文件是否还打开着writeopen写入的文件是否还打开着
缓冲区满
缓冲区满了的标志就是 nwrite - nread = PIPESIZE
缓冲区空
缓冲区空的标志就是 nread = nwrite
1 | struct pipe { |
在 pipe 两端的文件描述符类型必须是 FD_PIPE , pipe 的读入一端的文件描述符被标记为可读但是不可写,写入的一段被标记为可写但不可读,这两个文件都会被该进程打开,放入该进程的打开文件的数组中,而且这两个文件中的 pipe 指针会指向对应的管道,这将导致 readopen 和 writeopen 为 true 。当这个文件描述符的引用计数减小为 0 时,就将其释放到空闲的内存中,而且当这个 pipe 的 readopen 和 writeopen 都为 0 时,会将这个 pipe 释放,通过调用 kfree 来释放这一页内存
实际上这个操作需要调用管道系统调用来创建管道并且分配两个文件描述符。具体的操作就是,在当前进程的进程结构体中找到 ofile 中空闲的块,然后就使用这两个块,然后将这两个块返回到用户模式进程,以便进行读写操作。
pipealloc
创建管道并且分配两个文件描述符,设置对应的文件描述符,返回指向两个文件描述符指针的地址,下图中中间块表示文件描述符指针。如果设置成功返回 0,否则返回 -1,并且把分配好的内存都释放掉
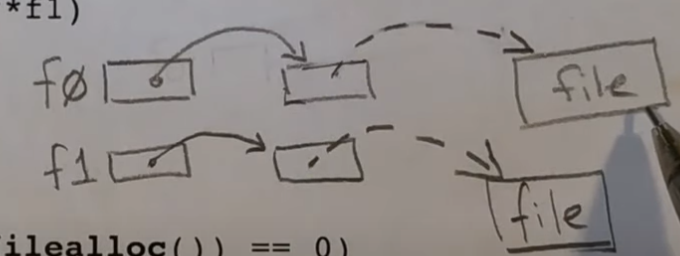
f0是一个指向指针的指针,用于读取端f1是一个指向指针的指针,用于写入端
1 | int |
piperead
处理管道读取,从指定管道 pi 中读取 n 字节数据写入到用户虚拟空间地址 addr 中,正常读取返回读到的字节数,否则返回 -1
实际上当管道没有写入并且已经空了的话,会直接退出,不进行读取
struct pipe *pi指向管道的指针addr从管道读出之后写入对应的用户虚拟空间地址n读取的字节数
1 | int |
pipewrite
从指定用户虚拟空间地址 addr 读取 n 字节数据写入到指定管道 pi 中,成功写入返回写入字节数,否则返回 -1
写函数不像读函数,一般会写完所有 n 个字节(如果不发生错误的话),但是读取函数发生错误或者空了就不再读取了
实际上当管道没有读取的话,会直接退出,不进行读取
1 | int |
pipeclose
关闭对应管道的某一端,每当关闭读取端或者写入端时,都会调用该函数。如果所有管道的读写口全部被关掉了,就释放掉这个管道
pi对应的管道writable是一个布尔值,关闭写端还是读端,实际上对应file中writable=1的一定是读取端,否则是写入端- 1:关闭写端
- 0:关闭读端
1 | void |
通过管道实现进程间通信
由于 pipe 是临时存在于在内存中的,所以其它进程找不到这个管道,无法调用这个管道
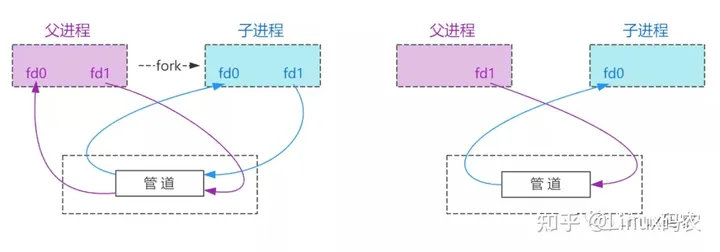
由于 fork() 和 exec() 系统调用可以保证文件描述符的复制品既可供双亲进程使用,也可供它的子女进程使用。也就是说,一个进程用 pipe() 系统调用创建管道,然后用 fork() 调用创建一个或多个进程,那么,管道的文件描述符将可供所有这些进程使用
假设一个进程在创建完一个管道之后,又 fork 了两个子进程,每个进程都会完全复制父进程的数据,也就是子进程也有父进程的文件描述符,对应的管道和文件的引用次数将增加。假设一个进程负责读,一个进程负责写入。那么可以假设读进程会失去写入的文件的描述符,而写进程会失去读的文件的描述符,也会减少对应的引用次数。父进程依旧持有这些文件描述符的指针。读进程可以通过使用“读取文件”的文件描述符发出读取系统调用从管道中获取数据,写进程可以通过使用对应“写入文件”的文件描述符发出写入系统调用向管道中写入数据
所以一个普通的管道仅可供具有共同祖先(或者父子进程)的两个进程之间共享,并且这个祖先(父进程)必须创建对应的子进程之前就已经建立好了供它们使用的管道
文件描述符
文件
在系统中,有三种文件,它们都有共同的参数 inode 和 pathname
- 常规文件
- 目录文件
- 设备文件
在 C 语言中,有个文件描述符结构体 FILE ,这个仅存在于用户模式虚拟地址中,内核不知道它的存在,它有对应的库函数,这些函数并非是系统调用,但是为了完成对应的工作,会调用系统调用
fopen打开文件,调用系统调用openfread读取文件,调用系统调用readfwrite写入文件,调用系统调用writefclose关闭文件,调用系统调用close
所以内核与用户之间使用文件描述符来进行通信,通过文件描述符可以引用设备,管道,常规文件等
在进程结构体 proc 中,有一个 file* 数组 ofile ,存储着该进程中打开的文件的文件描述符,长度为 15,也就是最多打开 15 个文件
在 Unix 中,文件描述符 0 用于标准输入,文件描述符 1 用于标准输出,文件描述符 2 用于标准错误。进程可以连接管道的读取端作为标准输入,而对于标准输出,实际上就是指向一个文件的 inode 并且其中定义 size=900
当进程 fork 一个子进程时,这些文件将也会在子进程中打开
file
文件描述符结构体,其中
type该文件描述符的类型,在被分配时设置FD_NONE文件未使用FD_PIPE管道文件FD_INODE常规文件和目录FD_DEVICE设备文件
ref该文件描述符的引用数目,如果为 0,那就未使用,被ftable中的锁保护readable可读权限writable可写权限pipe指向管道的指针,只在FD_PIPE类型下有效ip指向inode的指针,只在FD_INODE和FD_DEVICE下有效off文件中数据的偏移量,一般来说应当是当前写入多少数据了,或者类似于读文件当前读到的位置,只在FD_INODE下有效,意味着是常规文件或者目录文件。说明下一次进行读取或者写入时在文件中的位置,这个值受到inode中的锁的保护short主设备号,只在FD_DEVICE下有效,在FD_DEVICE中,将会被复制到ip指向的inode中
1 | struct file { |
每个进程都可以打开很多文件,每一个打开的文件都会被赋予一个文件描述符,进程中打开的文件被 proc 中的 ofile 指针所指向。其中文件描述符的引用数就是指向该文件描述符的指针数量, off 受到 inode 中的锁的保护,其它的数据在分配时被初始化,之后不会被改变,所以不需要锁
ftable
文件描述符表,其中存储着 100 个文件描述符,类似于 inode 缓冲区的作用。这些 file 的 ref 被 lock 保护,这些文件描述符要么正在使用,要么空闲以供将来使用
1 | struct { |
fileinit
只做了初始化 ftable 的锁,在 0 号内核中被调用
1 | void fileinit(void) { |
filealloc
分配一个 file 结构体,并且返回对应的指针,在文件描述符表中找到一个未使用的 file 来分配,返回对应的指针,未找到返回 null
1 | struct file* |
filedup
增加文件的引用计数,可以在 fork 子进程时使用
1 | struct file * |
fileclose
释放掉文件描述符,实际上就是删除这个指向对应 file 结构体的指针,减少引用计数,如果引用计数到达 0,那就关闭该文件描述符,实际上就是将引用计数设置为 0,并且文件类型设置为 FD_NONE 表示文件描述符未使用
struct file* f文件描述符
1 | void |
fileread
从文件 f 中读取 n 个字节到用户虚拟地址 addr 中
1 | int |
filewrite
从用户虚拟地址 addr 中读取 n 字节数据,写入到 f 文件中
1 | int |
filestat
这个函数用于 fstat 系统调用。
获取文件 f 元数据到用户虚拟地址 addr 中
1 | int |
argfd
获取第 n 个系统调用参数作为文件描述符,并返回描述符和相应结构体的指针
1 | static int |
sys_fstat
这个函数不需要任何参数,最终会返回到用户的代码,所以返回 0 或 -1,表示成功与否
1 | uint64 |
文件相关的系统调用
read
需要三个参数
int fd文件描述符addr将数据读入到的地址,用户虚拟地址空间n读取的字节数
在用户模式下首先将这三个参数放入到寄存器 a0, a1, a2 中,将在 a7 寄存器中放入一个代码号,这个代码号用来使内核确定使用哪个系统调用,然后用户模式代码将执行。在 risc-v 中,会使用 ecall 指令来执行系统调用,此时内核将获得控制权,并开始保存用户寄存器,然后查看 a7 中的值以确定涉及哪个系统调用。如果是 read 系统调用,将调用 sys_read 函数
在这个函数中,定位参数并且从其最初的存储位置中获取它们
1 | uint64 |
sys_write
需要三个参数
int fd文件描述符addr读取数据的地址,用户虚拟地址空间n读取的字节数
系统调用的写入函数,这个函数本质上就是从寄存器读取数据,然后进入 filewrite 函数来写入
1 | uint64 |
sys_close
系统调用关闭文件
fd需要关闭的文件的文件描述符
1 | uint64 |
sys_dup
传入一个已经打开的文件的文件描述符,将为此文件分配一个新的文件描述符并且返回该新文件描述符,如果没有剩余的 ofile 那就返回 -1
但是对于 Unix 最重要的就是,文件描述符 0 用于标准输入,文件描述符 1 用于标准输出,文件描述符 2 用于标准错误,所以对于 dup 查找就需要注意这一点,当然这 3 个一定是分配不到的
fd对应文件的文件描述符,需要是已经打开的文件的文件描述符
1 | uint64 |
fdalloc
遍历进程的 ofile 数组,找到空位分配一个文件描述符,如果找到返回该文件描述符,否则返回 -1
f对应的文件结构体,为该文件分配一个文件描述符
1 | static int |
sys_fstat
fstat 系统调用,传入两个参数,打开文件的文件描述符和一个用户虚拟空间地址,用于将文件的信息保存到该用户虚拟空间地址
fd对应文件描述符st目标用户虚拟地址空间
1 | uint64 |
sys_chdir
由于每个进程都有当前的工作目录,有时候可以使用该系统调用来更改目录,传入一个字符串,该字符串描述一个文件的路径名,该文件最好存在并且是一个目录,然后就把当前工作目录改为该文件
path将当前进程的运行位置改为path
1 | uint64 |
sys_link
该函数作用就是将当前存在的条目添加到新的条目中,以便使新的路径有效,并且它们将引用同一个文件。正常返回 0,否则返回 -1
existingpath当前存在的路径newpath新的路径
1 | uint64 |
isdirempty
遍历目录文件中所有的 dirent ,是否该目录中仅存在 . 和 .. 两个目录,其它 dirent 的编号必须是 0 表示未使用。如果是空的,返回 -1,否则返回 0
dp传入的文件的inode
1 | static int |
sys_unlink
删除文件硬链接,如果正常,返回 0,否则返回 -1
1 | uint64 |
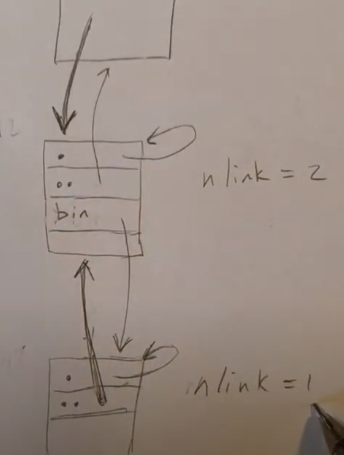
文件系统结构类似于上图。简述一下这个函数成功运行的流程
- 传入路径条目名称
- 根据路径条目名称获得该条目的父目录,并且获得该路径条目对应的文件
inode - 将父级目录中该文件的条目清空,然后减少子文件或子空目录和父目录的硬链接数,如果是非空子目录,那就不操作
- 之后减少两个文件的引用数量,如果子文件或子空目录引用数为 0,就会删除该子文件或子空目录
- 更新所有的
inode,将修改后的inode写回到磁盘
在这个函数中需要注意锁的顺序
create
创建一个对应类型的文件,如果是设备文件的话,会需要 major 和 minor 两个参数,也就是主设备号和次设备号,而其它文件,这两个参数可以传入 0,不会被使用。成功创建之后,返回一个新创建的文件的 inode 指针,并且会对其上锁。这个函数被三个地方调用, open 系统调用, mknod 系统调用和 mkdir 系统调用。成功执行返回创建的文件的 inode 指针,否则返回 null
path例如a/b/c,就是将要把c文件创建在a/b目录下type将要创建的文件的类型T_DIR目录文件T_FILE常规文件T_DEVICE设备文件
major设备文件的主设备号minor设备文件的次设备号
1 | static struct inode * |
sys_mkdir
创建目录的系统调用,读取第一个参数作为路径名称。创建成功返回 0,否则返回 -1
1 | uint64 |
sys_mknod
这个函数将创建一个设备文件,其中会传入指定路径,主设备号和次设备号,如果成功返回 0,否则返回 -1
path创建的文件路径major主设备号minor次设备号
1 | uint64 |
sys_open
传递一个路径名称,是将要打开的文件,以及一个标志值的整数,并且定义了一些位,用来表示在某些情况下该做什么,这将会返回对应文件的文件描述符,需要注意的是该系统调用只能创建常规文件,能打开现存的设备文件,目录和常规文件
path将要打开的文件的路径omode标志位O_RDONLY: 0x000只读,实际上根本没有设置位O_WRONLY: 0x001只写O_RDWY: 0x002读写O_CREATE: 0x200创建对应的文件O_TRUNC: 0x400将文件截断为 0
1 | uint64 |
sys_pipe
管道系统调用,传入一个指向文件描述符数组的指针,该数组有两个元素
该函数调用做的就是,在进程中找到一个未使用的 ofile ,然后将其指向创建出的管道的读取端,在找到另一个指向管道的写入端,最终会在数组中保存两个文件描述符,大小正好是 2,0 号元素为读取端,1 号元素为写入端
1 | uint64 |
ELF file format
ELF 文件是一种用于二进制文件、可执行文件、目标代码、共享库和 core 转存格式文件
不同的系统上使用的文件格式也不一样
| 文件格式 | 系统 |
|---|---|
| ELF | Linux/Unix |
| Mach-O | MacOS, IOS |
| PE | windows |
ELF文件格式
| ELF Header | ELF 文件都以固定格式的文件头开始 |
|---|---|
| Program Headers | 文件头后面紧跟着的就是程序头表,其中的每个程序头完全相同,具有相同的大小 |
| Segments | 很多段,要加载到内存中的实际代码就位于这些段中,这些段有着不同的大小,每个段都被一个程序头指向,并且这将包含对应的段在可执行文件中的位置的信息 |
| Other Stuff | 例如在可重定位文件中,这一部分就是节头表,包含重定位和调试信息 |
ELF Header
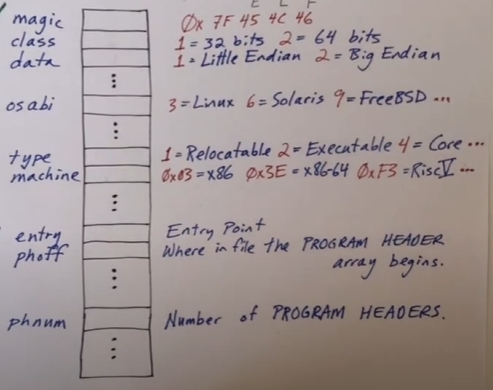
这里并没有展示各个字段的大小和偏移量,因为对于不同版本的 elf 文件都是不一样的,取决于是 32 位还是 64 位
magic这里面包含着四个字节,就是0x7F 0x45 0x4C 0x46,可以通过检验这四个字节确保当前文件是 ELF 文件class用于指定文件是 32 位文件还是 64 位文件- 1:32 位
- 2:64位
data用于指定文件格式是小端模式还是大端模式- 1:小端模式
- 2:大端模式
osabi应用程序二进制接口,用于指示该文件要在哪个操作系统上运行。但是不包括 xv6- 3:Linux
- 6:Solaris
- 9:FreeBSD
type文件类型- 1:可重定位文件格式,由链接器处理生成可执行文件
- 2:可执行文件格式
- 4:内核文件,当系统崩溃或者出现某种错误时,需要捕获主内存的数据进行调试,这时候可以创建内核文件。当然内核文件可以是其他格式的文件
machine当前文件格式所适应的处理器类型0x03: x86x03E: x86-640xF3: Risc-V
entry程序开始执行的地址,这可能是主函数的第一个字节,通常还会有一些序言代码在可执行文件中,prolog代码是实际调用main函数的代码,这时候入口地址就是prolog代码的第一个字节。所以在内核将可执行文件加载到内存中时,它将跳转到入口点,然后开始执行phoff程序头偏移,程序头在文件的位置phnum程序头数量,可以在 ELF 文件中可以找到多少个程序头
在 xv6 中,忽略了很多字段,只会查看 magic , entry , phoff , phnum 等,其它字段都会被忽略
1 | struct elfhdr { |
程序头

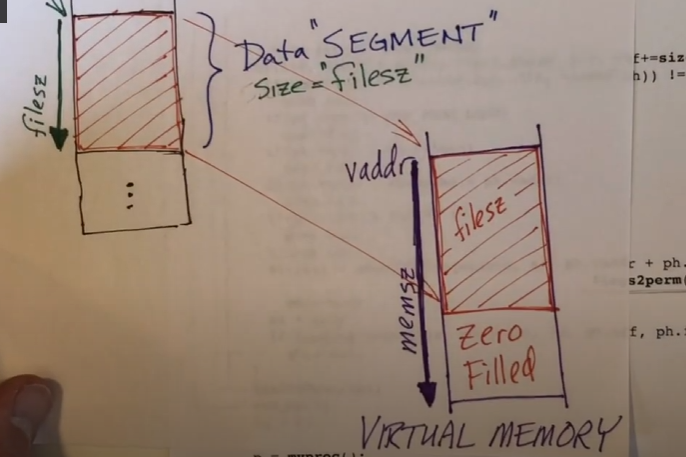
由许多字段组成,大小是固定的
type描述存储段的类型或特殊节的类型- 1:loadable segment,可加载段
flags用于指示该程序头的权限,指示该段在加载到内存中时应该标记的权限。每个权限由一位表示- 可执行
- 可写
- 可读
off偏移量,可以在文件中找到数据的位置,程序头的位置vaddr指出本段首字节的虚拟地址,加载时加载到虚拟内存的哪个位置paddr指出本段首字节的物理地址。通常由操作系统动态确定filesz用于指示该段中有多少数据,多少字节memsz在内存中需要占用多少字节,可以大于或等于filesz但是不能小于,如果大于filesz,剩余空间将被 0 填充align对齐字段,事实上会把程序加载到页面边界对齐的地址中
1 | struct proghdr { |
一些定义的常量
1 |
|
ELF_MAGIC文件头魔数ELF_PROG_LOAD可加载段ELF_PROG_FLAG_EXEC可执行权限ELF_PROG_FLAG_WRITE可写权限ELF_PROG_FLAG_READ可读权限
exec 系统调用
系统调用传入了两个参数
path指向路径名的指针,就是将要加载和执行的可执行文件argv指向数组的指针,这些是将要传递给可执行文件的参数,该数组包含以null结尾的字符串的指针,并且以一个null指针结尾,这些参数位于虚拟地址空间
1 | uint64 |
exec 函数
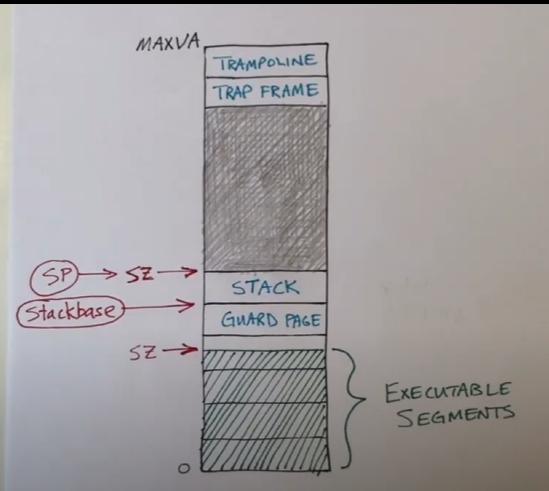
执行成功则会在新的虚拟地址空间中执行新的程序,执行失败返回 -1,该函数传入两个参数,为新的程序分配一系列内存空间,分配一个页表,并且为其分配存放程序的空间,并且加载程序,分配栈和保护页,分配 trampoline 页面和 trap frame 页面
path可执行文件的地址argv指向参数数组的指针,这数组包含指向参数的指针,这些是传递给新的可执行程序的参数
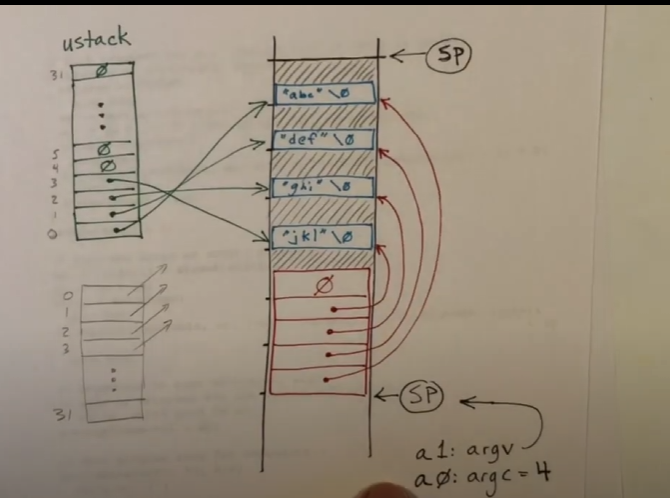
在该函数中,还会为参数分配空间,如图所示,参数都会被分配到栈中,最后分配完之后如图所示,先将参数字符串压入栈中,然后再将指向对应的参数的指针压入栈中
1 | int |
flag2perm
该函数将设定文件权限的标志位转为对应的权限,由于设定文件的权限标志位与页表条目的权限标志位不一致,所以需要该函数来转换
1 | int flags2perm(int flags) |
loadseg
将一个程序段加载到虚拟地址 va 的页表中, va 必须对齐,并且从 va 到 va+sz 的页必须已经映射。成功时返回0,失败时返回-1
pagetable对应进程的页表va在上述页表中的虚拟地址,也是目标地址,需要保证虚拟地址被映射ip对应文件的inodeoffset在文件中的偏移位置,也就是开始读取数据的位置sz需要读取内容的大小
1 | static int |
后记
xv6 内核代码就介绍到这里,内容比较多,一开始是只用了一个文件的,但是内容过于多导致加载太卡了,所以直接从中间分成上下两篇了。之后可能会看看用户模式的代码,并做一些总结

