操作系统
前言
这个笔记是跟着 jyy 老师学的,有兴趣的话可以看看原视频,讲的很不错
读手册,读手册,读手册
http://jyywiki.cn/pages/OS/2022/demos/
绪论
- 操作系统是服务于程序的,程序就是状态机,计算机每执行一条指令计算机的内存和寄存器都会发生变化
- 操作系统=对象(文件,进程,管道)+API(操纵对象的API)
- 用简单的硬件实现对象和API,操作系统可以用c程序实现
- 广义的操作系统:基于下层的支撑为上层提供服务
程序
程序就是状态机,作为一个状态机是没有办法自己销毁自己的,只能以死循环或者以一个系统调用(告诉操作系统该销毁了)结束,程序的状态机模型
- 状态 = 堆 + 栈
- 初始状态 =
main的第一条语句 - 迁移 = 执行第一条语句
任何 C 程序都可以改写成非复合语句的 C 代码,所有程序都是运行在计算机上的,计算机就相当于是状态机,C程序的所有代码都会被推入栈中,之后在运行过程中依次调用,每执行一条指令计算机的状态也会发生改变,指令是从pc取出来的,确定性的指令,状态是一条直线
系统调用 syscall
这个指令就是把系统完全交给操作系统,任其修改,实现操作系统中的和其他对象交互
- 读写文件
- 操作系统状态
- 改变进程
- 创建/销毁进程
程序 = 计算 + syscall + 计算
代码实现最小的 helloworld
可以先利用 C 语言写一个自认为最小的 helloworld 程序
1 |
|
使用 gcc 静态编译 gcc -static a.c ,再使用 ojbdump -d a.out 查看会发现它的代码量其实很多,可使用 ls -l a.out 或者 size a.out 来查看代码大小,所以这个肯定不是最小的 helloworld
由于只打印字符串,所以可以将 printf 优化为 puts ,重新编译之后发现代码大小并没有什么变化,所以可知编译器已经把 printf 优化为 puts 了
接下来可以去除程序中的符号表,使用 nm 指令查看程序中的符号表,对于尽可能小的文件,符号表就显得可有可无了,所以可以去掉符号表,使用 strip 指令或者是再编译中去除符号表,两种方法效果是一样的
1 | nm a.out |
最终得到的文件也非常大,所以这里可以使用汇编语言来重写程序
1 | #include <sys/syscall.h> |
这里直接使用系统调用代替掉标准库,但是这个代码是不能直接编译的,会产生未定义 main 函数的结果,但是可以静态编译为可重定位目标文件,再经过链接得到可执行目标文件
1 | gcc -c a.s |
最后可以得到可执行目标文件 a.out ,事实上这个并不会是最小的 helloworld 代码,毕竟这里的大小也有 4700 多字节
编译器
编译器是将高级语言编译为机器语言的工具
正确的编译
正确的编译就是所有不可优化的代码都正确的编译到汇编代码上就是正确的编译,在C代码与汇编代码中,只有不可以优化的部分是完全相同的,其他部分可以不相同,因为现代编译器会对指令进行重排,以此来优化程序的性能
编译优化的前提
- 内联汇编也会参与优化,其它的优化可能不会跨过带着障碍的
asm volatile - Eventual memory consistency 即需要保证最终磁盘的一致性
- 调用外部CU =回写可见内存
例如
1 | extern int a; |
C语言代码的第一条指令
可以利用 gdb 来寻找 C 语言程序的第一条指令,进入调试之后,使用 starti 指令,可以看到第一条指令为 _start 函数的指令 mov %rsp, %rdi
使用 info proc mappings 打印进程内存。并且在 main 函数之前调用了 ld-linux-x86-64.so 加载 libc 之后就对 libc 完成了初始化
对于一个程序,可以创建 attribute 函数分别在 main 函数构建之前和构建之后运行
1 |
|
可以通过使用 strace 工具查看程序用到了哪些系统调用, strace a.out 可以看到代码运行过程中调用的系统 API。也可以使用 strace -f gcc -c a.c &| vim - 查看编译过程调用的 API 并且使用 vim 查看,在其中使用命令 :%!grep execve 查看编译过程中调用了哪些其它的进程,为了方便查看,可以使用 set nonu 不显示行号,使用 :%!grep:%s/, /\\\\\\\\r /g 把逗号空格换成换行
在 gdb 中可以使用 info proc * 查看当前进程的信息
也可以使用 strace xedit 来查看图形化界面的系统调用
窗口管理器调用的 API 主要是管理设备和屏幕 read/write/mmap,进程之间的通信 send/recv
任务管理器调用的 API 主要是访问操作系统提供的进程对象 readdir/read
并发编程
多处理器编程
c 语言的多线程库 pthread.h 库是动态链接库,所以编译时需要动态链接 -lpthread
使用 man 7 pthread 来查看多线程库的手册
多处理器中的线程的代码同时执行同一条指令就会出现错误,这时候可以对进程加锁
并发
从程序执行开始,初始状态和过程状态都确定,这就是一个固定的程序,但是对于并发,程序会有一定的随机性,进程会共用程序的状态
并发程序的基本单位:线程
线程是共享内存的多个数据流,使用 thread.h 中的函数创建一个多线程的程序,但是在编译时需要加上 -lpthread ,多线程是共享内存的,但是每个线程都具有独立的堆栈
可以使用 top 指令查看 CPU 的占有率。
原子性
- 单线程:程序运行时可能被中断切换到另一个程序执行
- 多线程:程序并发执行
- 原子性互斥,互斥锁,进程锁,原子锁
- 实现原子性:实现两个API
lock(&lk)unlock(&lk)
99% 的并发问题都可以使用一个队列完成,把大任务切分成可以并行的小任务,除去不可并行的其他的可以获得线性的,这就是说,实际上多线程并发程序实际上不是同时执行的,线程是在一个进程中轮换着执行的,所以也就可以使用一个队列完成
对于下面的代码,这是一个多线程执行累加的代码
1 |
|
这个代码会发生数据竞争,最终的输出结构应该是 200000000 的,但是由于数据竞争,这个数据是不确定的,有时候甚至 <N ,但是对于不同的编译优化等级结果是不一样的
- 对于O1优化,相当于是每一个进程分别进行优化,每个进程优化之后就是 sum = 1000000,最后结果为 sum = 1000000
- 对于O2优化,程序优化之后,两个ADD很接近,容易出现错误,一般会输出结果为 200000000
对于程序的处理都是有顺序的 fetch(取)->issue(发行)->execute(执行)->commit(提交)
当前的电脑可以同时处理多条issue指令,乱序执行,可以在一个时钟周期里取出多条指令同时执行
对于多处理器,无法满足单处理器 eventual memory consistency 的执行,在多处理器上可能无法序列化,甚至会有多条代码在一个时钟周期里执行。在写入时会发生 cache miss(缓存未命中),如果 x 发生 cache miss 那么就会让 读取 y 先开始。满足尽可能的执行 UOP 的原则,最大化处理器性能
宽松内存模型
宽松内存模型目的是使单个处理器的执行更加高效
例如 ARM / RISC-V 是一个分布式系统,相当于是没有共享内存,每一个线程有一个单独的内存,单独的内存之间又有交互,而对于X86结构的处理器,每一个线程都有一个单独的存放数据的堆栈,可以延迟任意长时间之后再写入内存
多处理器编译:不原子,乱序编译,不立即可见
并发程序 = 多个执行流,共享内存的状态机
线程互斥算法
互斥:保证两个线程不能同时执行同一段代码
假设一个内存的读/写可以保证运行顺序,原子完成,终端代码输出重定向 > 文件 可以把输出结果导出到文件里,如果两个线程同时执行这段代码就会导致最终输出到文件中的内容式乱的,所以如果保证两个线程不同时执行这一段代码,并且都会及时更新这个文件的写入指针,那就会写入的比较号
对于下面的 python 的代码
1 | def thread: |
这个代码是个死循环,但是是可以返回的,通过 yield 来返回。每一个执行这段代码的都相当于是一个多线程,相当于是C#里的协程,直接运行的话会很乱,但是利用 _next__() 函数就能够保留这个线程的状态来不断运行
互斥锁
一把排他性的锁,共享内存实现互斥,实现互斥的方式:不能同时读/写共享内存
load的时候不能写store的时候不能读
这里用到了内联汇编,在执行这条代码的时候其他指令都不运行
1 | asm volatile("lock addq $1, %0": "+m"(sum));// 就是在这条代码运行时其他代码都不运行 |
这就会实现锁的互斥了
当前的CPU存在 1 级缓存和 2 级缓存,如今的x86架构还是有很大缺点,例如多线程中每个CPU里都有一个数据 m,当一个 CPU 要 lock 时,并且要读取 m,那就需要将所有 CPU 中的 m 剔除
自旋锁
1 | void xchg(volatile int *addr, int newval) |
这里也用到了原子交换代码,自旋锁就是如果没拿到锁就会快速地不断请求锁,所以就是以一种紧凑的循环来实现等待锁的
原子指令的模型
- 保证之前的 store 都写入内存
- 保证 load/store 不与原子指令乱序,如果想要实现长临界区的互斥需要用到系统调用
1 | syscall(SYSCALL_lock, &lk) |
睡眠锁
当其它进程正在持有锁的时候,这个进程请求锁,那就会得不到锁,然后进入 sleep 直到另外的进程释放掉锁并且
两种互斥锁的比较
- 自旋锁
- 在xchg成功之后进入线程
- xchg 失败之后进入等待,浪费cpu
- 睡眠锁
- 上锁失败就进入系统调用睡眠——系统会调用其它进程
- 即便上锁成功也需要进出内核
两种互斥锁结合
- 一条原子指令,上锁成功立即返回
- 上锁失败,执行系统调用睡眠,这一部分可以是模拟操作系统来执行睡眠
- 性能优化的思路: 关注 average case 而不是关注 worst case
futex
先在用户空间自旋
- 如果获得锁,直接进入
- 如果未能获得锁,系统调用
- 解锁之后也需要系统调用
- 软件不够,硬件来凑(自旋锁)
- 用户不够,内核来凑(互斥锁)
- fast/slow paths: 性能优化的重要途径
并发编程:同步
同步实现的方式:条件变量,信号量
同步就是在某一时刻共同达到相互已知的状态,互斥相当于是竞争,同步相当于是协作
生产者和消费者
- 生产者生产一定量的资源,只有当资源数量 < n 的时候才能够创造资源
- 消费者消费资源,只有当资源数量 > 1的时候才能消费资
- 有一个集中管理者,便于对全部的资源进行管理和分配,实际上就是把资源放入栈中,消费者取出资源,集中分配的速度就是程序运行的速度
这个就类似于操作系统的这个结构
条件变量 API
wait(cv, mutex)- 调用时保证获得互斥锁
- 未满足条件,释放互斥锁,进入睡眠状态
signal/notify(cv)- 如果有线程正在等待,唤醒其中的一个
breadcast/notifyAll(cv)- 唤醒正在等待的所有线程
对于等待函数,如果在判断条件之后等待,当再次被唤醒的时候就会没有再次的判断,导致程序出现错误
- 唤醒正在等待的所有线程
正确的打开方式
1 | mutex_lock(&mutex); |
信号量
信号量设计的重点:考虑到每一单位的资源是什么
1 | void creator() |
信号量有两种信号量,也就是empty 和 fill,这一点上和条件变量很像,但是如果是多种变量的话不容易实现
对于信号量并不总是非常好用,而且在于判断和创建中应该十分小心,因为是凭空创建的
程序的进出不一定是配对的,有可能导致死锁
多线程问题:死锁
例如:每一个线程需要两个条件才能触发,每一个都已经达到了自己的第一个条件,但是没有达到第二个条件,所有线程都处于等待的状态,导致程序无法进行 ——死锁(哲学家吃饭问题)
1 | mutex_lock(&mutex); // 先锁上,在查看是否两个条件都满足 |
- 条件变量:
broadcast性能低,但是不使用broadcast容易出错 - 信号量:在管理多种资源就不好用了
高性能计算
主要挑战是
- 计算需要容易并行化
- 机器-线程两级任务分解
- 生产者-消费者解决一切两级任务分解
- 线程间的通信
- 通信不仅发生在节点/线程之间,还发生在任何共享的内存访问中
数据中心程序
特点
- 强调数据和存储,互联网
- 算法/系统对HPC和数据中心的意义,追求数据的快速,关注的中心是数据
挑战
在服务很多地理环境的前提下
- 数据要保持一致 consisty
- 服务时刻保持可用 avaliablity
- 容忍机器离线 partition tolerance
用好计算机的指标: QPS, tall latency
线程 threads
是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
线程是独立调度和分派的基本单位。线程可以为操作系统内核调度的内核线程,如Win32线程;由用户进程自行调度的用户线程,如Linux平台的POSIX Thread;或者由内核与用户进程,如Windows 7的线程,进行混合调度。
同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。
一个进程可以有很多线程,每条线程并行执行不同的任务。
在多核或多CPU,或支持Hyper-threading的CPU上使用多线程程序设计的好处是显而易见,即提高了程序的执行吞吐率。在单CPU单核的计算机上,使用多线程技术,也可以把进程中负责I/O处理、人机交互而常被阻塞的部分与密集计算的部分分开来执行,编写专门的workhorse线程执行密集计算,从而提高了程序的执行效率。
协程 coroutines
协程与子例程一样,协程(coroutine)也是一种程序组件。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛
协程不是进程或线程,其执行过程更类似于子例程,或者说不带返回值的函数调用。
一个程序可以包含多个协程,可以对比与一个进程包含多个线程,因而下面我们来比较协程和线程。我们知道多个线程相对独立,有自己的上下文,切换受系统控制;而协程也相对独立,有自己的上下文,但是其切换由自己控制,由当前协程切换到其他协程由当前协程来控制。
数据中心
- 同一时间会有很多请求达到服务器
- 计算部分
- 需要利用好多处理器
- 线程->
mandelbrot set - 协程->一人出力,他人摸鱼
- 线程->
- 需要利用好多处理器
- I/O 部分
- 在系统调用上block(例如请求另一个服务器或者磁盘
- 线程->一人干等,他人围观
- 协程->每个线程都占用可观的操作系统资源
- 在系统调用上block(例如请求另一个服务器或者磁盘
- Go & Goroutine 多处理器并行和轻量级开发都有协程,在Go 和 Goroutine 中,一个cpu调用一个线程
Go Worker,可以自由调度goroutine,每个线程中存在多个协程
对于Go语言,执行到blocking API时Go Worker 会改为non-blocking版本的- 成功-> 立即继续执行
- 失败-> 立即
yield到另一个需要CPU的goroutine
\r 退格
rust 语言 Go 语言
- 浏览器中的并发编程:Ajax(Asynchronous JavaScript + XML)
- HTML (DOM tree) + CSS
- 通过JavaScript 可以改变它
- 通过JavaScript 可以建立连接本地和服务器
人机交互程序
- 特点
- 没有太多的计算
- DOM Tree 不至于太大
- DOM Tree 有浏览器帮助
- 没有太多的 I/O
- 主要就是网络请求
- 没有太多的计算
单线程+事件模型
- 一个线程,全局的事件队列,按顺序执行
- 耗时的API调用会立即返回
- 条件满足时间队列里增加一个事件
异步事件模型 promise
- 好处
- 开发模型简单
- 函数执行是原子的(不能并行),减少了并发的bug的可能性
- API 依然可以打开
- 适合网页这种大部分时间在渲染和网络请求的场景中
- javaScript 代码只负责描述 DOM Tree
- 适合网页这种大部分时间在渲染和网络请求的场景中
- 开发模型简单
- 坏处
- Callback hell
- 代码嵌套太多,维护性差,promise: 描述 workflow 的嵌入式语言
- Callback hell
并发的bug和应对
防御性编程
在某一些特定的地方使用 assert 函数来判断是否正确 assert(cond)
堆栈溢出:当栈的内存不够时,栈会发生上溢出或者下溢出,这会导致指针的位置漂移,产生不好的结果
栈溢出检查
Canary 一种针对栈溢出攻击的防护手段
牺牲一些内存单元来预警 memory error 发生,在使用栈的时候不要全部占用完所有的内存,在栈的开头和结尾填入自定义的数值,再检查是否是上溢出还是下溢出
在函数退栈返回前,程序会比对栈上的 canary副本 和原始的 canary ,若二者不同,则说明发生了栈溢出,这时程序会直接崩溃
lockdep
lockdep规约
- 为每一个锁确定唯一的 “allocation.site”
- aassert 同一个allocation site 的锁存在全局唯一的上锁顺序
检查方法-printf
- aassert 同一个allocation site 的锁存在全局唯一的上锁顺序
- 记录所有观察到的上锁顺序
x->y,y->x,x->z
- 检查是否存在
x->y ^ y->x
threadsanitizer
运行时的数据竞争检查
- 为所有事件建立 happens-before 关系图
- 对于发生在不同线程并且至少有一个是写的 x, y 检查是否存在
x->y^y->x
AddressSanitizer 非法内存访问
- overflow
- underflow
- use-after-free
- use-after-return
MemorySanitizer 未初始化的读取
UBSanitizer 未定义的行为
- 偏离方向的指针
- 有符号的整数溢出
低配版 lockdep
- 统计当前spin count
- 如果超过某个明显不正常的数值就报告
- 配合调试器和线程backtrace诊断死锁
低配版 Sanitizer
内存分配要求:已分配内存 S = 总内存 - 未分配内存
kalloc(s)返回的内存必须位于未分配的内存thread-local-allocation+ 并发的 free 还是容易出错
分配时不能出现一点已经被分配的内存
释放时也不能出现一点已经被释放的内存
并发bug-死锁
线程之间互相等待,都在等待着对方持有的锁,上自旋锁的时候需要关闭中断,否则可能会出现错误
死锁产生的必要条件
- 互斥:一个资源每次只能被一个进程调用
- 请求与保持:一个进程请求阻塞时,不放开当前已有的资源
- 不剥夺:进程以获得的资源不能强行剥夺
- 循环等待:若干进程之间形成头尾相接的循环等待资源关系
AA-Deadlock
在操作系统中一个线程就可以发生死锁。也就是中断持有 CPU,但是拿不到锁,所以在等待。而进程持有锁但是得不到 CPU 所以也等待
1 | void os_run(){ |
ABBA-Deadlock – lock_ordering
- 任何时刻系统中的锁都是有限的
- 严格按照固定的顺序获得所有锁。其实就是当最快的线程获得了编号靠前的锁之后,对于其他线程来说,就已经被卡死在这里,当然要想走到这一步的线程在之前的锁的争取上是获得胜利的,所以整个线程进度图就像是一棵树,释放锁时也需要按照一定的顺序释放,从前往后或者从后往前,可以保证所有线程有序的进行。所以最好的锁是封装锁,外部的看不到,也能很好的避免死锁
并发bug-数据竞争
不同的线程同时访问统一段内存,并且其中至少有一个是写
对于两个同时读写,慢的一方会把快的一方存入的数据覆盖掉
使用互斥锁保护好共享数据,消灭数据竞争
出现bug的原因:
- 上错了锁
- 忘记上锁 原子性违反
其他的并发bug
- 互斥锁 ———— 原子性
- 条件变量 ———— 同步
- 忘记上锁 —— 违反原子性
- 忘记同步 —— 顺序违反
- 非法内存访问
- 未初始化的读取
- 数据竞争
操作系统的状态机模型
bare-metal 约定
实现操作系统的前提是软件与硬件之间存在某种约定
- CPU RESET之后,处理器处于某个特定的状态
- pc指针一般指向一段 memory-mapped ROM
- ROM 存储了厂商提供的固件
- pc reset 之后,应当指向一个特定的位置,可以不断的从中读取到指令,这就相当于把硬件和软件链接起来
- pc指针一般指向一段 memory-mapped ROM
- Fireware 固件,厂商提供代码
- 有用户数据加载到内存
- 例如存储介质上的第二级loader
- 或者直接加载操作系统
- 用户数据从内存读取
- 有用户数据加载到内存
CPU RESET
整个计算机都是一个状态机
- 从PC指针处读取指令,译码,执行
- 从 firmware 开始执行
- ffff0 通常是一条向firmware 跳转的jmp指令
firmware: BIOS vs UEFI
- 都是主板/主板上外插设备的软件抽象
- 支持系统管理内存运行
- legacy BIOS(基础的I/O系统)
- UEFI(未定义的可扩展硬件)
firmware作用
- 代码直接储存在硬件中
- CPU RESET 之后会执行
- 加载512个字节到内存中(Legacy BIOS)
- 放置一些绝对安全的代码
- BIOS中断(打印Hello world字符)
- ARM Trust Firmware
- BOOST LEVEL
- U-BOOST
- 有点像操作系统的系统调用,可以完成一些读取磁盘,写字符等基础操作,加载操作系统
firmware:Legacy BIOS 约定
Legacy BIOS把第一个可引导的设备的第一个扇区加载到物理内存的7c00位置
- 此时处理器处于16-bits位置上
- 启动磁盘的第一个512个字节叫做主引导扇区MBR,这个指引扇区由 firmware 搬运到特定的内存
- 其他没有任何约束
- windows 系统的AB磁盘都是软盘,从c开始才是磁盘
计算机操作系统的启动过程
BIOS并不会接受所有的磁盘,如果将非引导磁盘插入软驱的时候,BIOS 会报错
BIOS选择的标准是:检查软盘的第一个启动扇区(第一个可启动磁盘的前512个字节),如果是以55aa结束,那它就是一个引导扇区,BIOS会把这512个字节装载0:7c00(也可能是07c0:0) 处,然后将控制权彻底交给这段引导代码,到此为止,计算机不再由BIOS控制,而是被操作系统的一部分控制,之后这一部分代码就会加载后面部分的代码
- 按下开机键,cpu开始执行bios,bios是位于rom上的一段程序,并且在出厂的时候就被写死在rom里。
- bios的作用是检查计算机的硬件,即硬件自检,然后bios会调入磁盘0号扇区的内容,把0号扇区调入到内存,开始执行。
- 0号扇区内存储的内容是MBR,主引导扇区,大小只有512B,前446B是代码,后面的是硬盘分区表,这里存储的是硬盘里的分区信息,分区的起始地址
- 对于磁盘分区,其中对于windows有个C盘,与其他分区不同之处在于,这个分区的0号扇区内是存放着分区引导程序的,可以引导该分区的操作系统。所以进入MBR之后就可以选择进入的操作系统了,如果要执行windows就把windows的引导扇区调入内存开始执行,就会启动windows了,之后电脑就交由操作系统来管理了
firmware 病毒
不仅仅伤害软件,并且伤害硬件
- intel 430TX(Pentium)芯片组允许写入Flash ROM
- 只要向Flash BIOS写入特定的序列,Flash ROM就变为可写
- ROM 是用来写保护的
CIH 病毒程序会不断复制自己,会对软盘上的内容进行修改
这种病毒不会一上来就发病,每年的4月26号就会打开ROM的写系统,然后写入垃圾
这种病毒造成的损害没有办法通过重启来修复
- ROM 是用来写保护的
- 只要向Flash BIOS写入特定的序列,Flash ROM就变为可写
解决办法
- 更换一块ROM
- CPU更换为Risc-V的CPU,这个CPU上电之后还原ROM
firmware:UEFI
彻底解决了类似CIH的病毒
系统加载流程
- 盘必须按GPT(GUID Partition Table) 方式格式化
- 预留一个FAT32分区(fsblk/fdisk)可以看到
- firmware加载任意大小的PE可执行文件.efi
- 没有legacy bios 512字节限制
- EFI 应用可以返回firmware
- 优点
- 设备驱动框架
- 更多功能-只启动信任的操作系统
UEFI 加载器也不再仅仅加载是 512 字节的 MBR,而是能加载任意 GPT 分区表上的 FAT 分区中存储的应用。今天的计算机默认都通过 UEFI 引导。
模拟方案 QEMU
是一种模拟处理器软件,在GNU/LINUX上使用广泛,甚至能够达到电脑的速度
User mode
用户模式,能够启动那些为中央处理器编译的LINUX程序
System mode
系统模式,可以模拟一整台电脑系统,包括中央处理器和周边设备
真机方案 JTAG
一系列物理寄存器,可以实现gdb调试
操作系统-状态机
firmware 和 boot loader 加载工作
- 初始化全局变量和栈;分配堆区
- 为main函数传递参数
进入c代码之后,遵循C语言的形式语义,还有一些行为补充 AbstractMachine
C语言 volatlie
如果变量不声明为 volatile 的话,编译器不会想到它这个变量可能会被外部程序修改,所以在编译之后运行的时候,这个变量就会被保存在寄存器中,但是外部的中断程序不能更改寄存器内的变量,加上 volatile 是易变的,改变量就会被外部中断所改变
AbstractMachine
-
TRM+MPE
- 等同于多线程处理器
- IOE API 完全是普通的库函数
- 同一设备数据竞争 = undefined behavior
-
CET
- 允许创建多个执行流 + M2
yield主动切换,会被中断被动打断on_interrupt会拦截中断事件
-
VME
- 允许创建一个“经过地址翻译的执行模式”
- 通过CET API 管理
-
观察make编译程序的过程
1
2
3
4
5
6
7
8
9
10
11make -nB \\\\\\\\
| grep -ve '^\\\\\\\\(\\\\\\\\#\\\\\\\\|echo\\\\\\\\|mkdir\\\\\\\\|make\\\\\\\\)' \\\\\\\\
| sed "s#$AM_HOME#\\\\\\\\$AM_HOME#g" \\\\\\\\
| sed "s#$PWD#.#g" \\\\\\\\
| vim -
- make -nB (RTFM)
- grep 文本过滤,省略一些干扰项
- echo(提示信息), mkdir 建立目录, make(sub-goals)
- sed 输出更易读
- 将绝对路径替换为相对路径
- vim - 在vim 中查看
编译器和现代CPU
现在的CPU允许同一时间执行两条甚至是多条代码
一条指令周期执行一条代码
trace和调试器
程序执行 = 状态机执行
观察方式:strace / gdb
使用 strace -T 可以获得系统调用所花费的时间
每一条指令的 side-effect 有限,一般只能访问一次内存或者改变几个寄存器的数值
- 只记录初始状态和每条指令前后状态的 diff(指令之后状态的改变)
- 正向执行 Sn -> Sn+1
- 反向执行 Sn -> Sn-1
- 使用GDB回溯调试不适用于某些指令(syscall)
我们需要记住,从一个初始状态到执行结束期间,执行了多少条不确定的指令,还要记录对应指令结束之后的结果,还要记住例如random和syscall之后的结果
(指令数目+非确定指令的结果+非确定指令) * N
在CPU中执行的绝大多数指令都是确定的,只需要记录很少部份的不确定性的指令
如果要记录计算机的系统的执行,只需要记录所有的I/O指令(memory map/inport IO)+所有时候发生的中断
对于一个确定的程序,只需要记录一个初始状态,后面都可以 replay 复现所有的结果
record & replay
- 单线程 应用程序
syscall,rdrand,rdtsc
- 单处理器 操作系统
- 中断
对于record可以只记录不确定的部分,确定的运行的部分可以不记录
- 中断
性能优化
状态机执行需要时间,对象需要空间
需要理解时间花在那里,什么对象占用空间
性能摘要
性能摘要需要对程序执行性能影响最小,往往不需要full trace
隔一段时间暂停程序观察运行情况
- 中断
- 记录record
- 执行语句
- 函数调用栈
- 服务请求
1 | asm volatile("cli"); |
perf list, perf stat, perf record, perf report(需要手动安装perf)
实际性能优化
大部分情况
- 80%时间消耗在集中的几处代码
- L1 小内存分配时的lock contention
SMT solver
model-checker 自动分析程序执行
虚拟化
操作系统的启动
CPU reset -> firmware -> boot loader -> (kernel _start()) OS -> .....
然后操作系统会加载第一个程序 RTFSC ,然后 linux kernel 会进入后台,成为中断/错误处理程序
从第一个开始依次执行访问,查找启动操作系统的文件
/sbin/init/etc/init/bin/init/bin/sh
操作系统执行之后,操作系统会执行一个程序,但是这个程序不会返回,并且操作系统的所有进程都会被 init 函数调用 fork 系统调用来启动
fork()
fork()进程是条系统调用:本来只有一个执行的进程,之后会变为两个产生分支,其实就是通过 fork() 来创建进程
fork() 作用就是将整个程序这个状态机完全的复制一份,执行完毕之后,系统中会出现完全一样的进程,内存的每一个字节都一样,寄存器也一样,除了 fork() 的返回值不一样,每个进程都有一个不一样的编号,每一个进程都无法访问其他的进程, fork() 返回的是创建出来的进程的进程编号,但是被创建出来的返回值是0,之后操作系统就进入了并发系统
执行fork的程序会将自身的整个状态机完全复制一份,除了返回值不同,父进程会返回子进程的oid,子进程返回0,其他部分都不变,连进程中的文件描述符也会复制一遍,但是那个文件对象只有那一个。
对于子进程要执行 execve 的指令时,会重置子进程的状态机,但是如果子进程中含有复制过来的文件描述符的话,并不会重置文件描述符,而是保留不变,是因为每个进程中都含有一个文件描述符表用于存储它的文件描述符,当一个进程执行 execve 状态机重置的时候,它的文件描述符应该被关掉而不是被子进程继承下去,防止出现父进程有权限而子进程无权限处理文件而发生安全问题的情况
- 操作系统就是状态机的管理者
- 虚拟化就是操作系统可以管理很多状态机,每次选择一个状态机执行一步
fork()函数甚至能把函数内部状态全部复制一份。使用不当导致fork bomb:无休止创建进程的程序- 不停的创建程序,系统还是会挂掉的
1 | :(){ :|:& };: |
fork 是完全复制状态机,完全复制一个进程,甚至连缓冲区内部数据都能复制
tty: line buffer 如果看到\n就会把缓冲区内的所有东西写出来,其实就是\n清除缓冲区,fflash(stdout)。清除缓冲区pipe:full buffer 如果看到写满 4096 字节之后,把这个页面整个丢给管道给另外的程序,或者打印出来。其实就是写入管道的话,缓冲区内的数据也会被写入管道,但是对于tty中打印的话,最终缓存区内部的数据没有被打印出来,两种缓冲模式不同。进程结束之后,C代码不会立即结束,会将缓冲区的所有内容清空
1 | for(int i = 0; i < 2; i++) |
fork搜索并行化
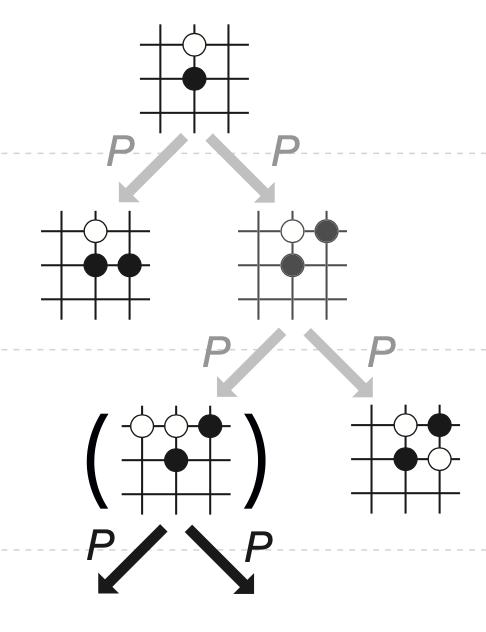
这个就体现出了一种回溯的新的算法,可以将运行的时间复杂度为 o(n) n是深度
每次搜索都fork一个新的进程,甚至连回溯的结果都不要了,直接只有对的进程能操作实现,并且最关键的是fork创建出来的子进程对原来的系统内存中并不会影响到
fork跳过初始化
只初始化一次,然后其他的所有进程都直接复制父进程,这样的子进程就不需要再次初始化了
例如 Android 是通过java代码开发的,是一个Java Virtual Machine,涉及到大量的类加载,所以可以只初始化一次然后全员使用,打开应用就相当于fork了一个进程,并且把相关的权限设置之后就可以开始运行
fork备份和容错
可以使用fork创建一个快照,也就是存档,当主进程crash了,就启动快照重新执行,并且在启动快照时再次复制一份进程
当运行并发程序时,可以在运行的时候经常fork新的进程,然后进程跑死之后,直接启动子进程,并且更改子进程的环境,启动的时候也要fork子进程
1 | int setjmp(jmp_buf env); |
fork——Unix时代的产物
fork + execve 只有内存和文件描述符,并且文件描述符指向的只有管道和终端
线程是属于进程的,如果一个进程中有两个线程,其中进程执行fork指令,当然肯定是进程中的某一个线程执行的fork指令,此时复制进程时并不会把所有的线程都复制,而是**只复制执行 fork 指令的线程,**如今的 linux 操作系统并不能很可靠的执行每一个线程的复制,线程的创建实际上是通过一个 clone 的系统调用来执行的,fork也只是某一种clone的变体,也可以把没有复制过来的进程给捞过来
execve()
指令在系统中创建各种各样的线程,每当创建一个线程之后都会进行判断。作用:重置状态机为某个函数初始状态,这个函数还可以传入参数 argc 和 argv[],还可以传入环境变量 envp[] 。
对于 main 函数,完整的 main 函数: int main(int argc, char* argc[], char* envp[]){} export 可以更改环境变量的值,也可以自己创建环境变量
1 | pid = fork(); |
通过使用 strace 查看程序的系统调用会发现:每一个程序开始所执行的第一个系统调用都是 execve()函数。实际上就是,对于 Linux 系统来说,每次运行一个程序都是调用的fork来创建新的线程,之后再通过 execve() 函数来初始化线程
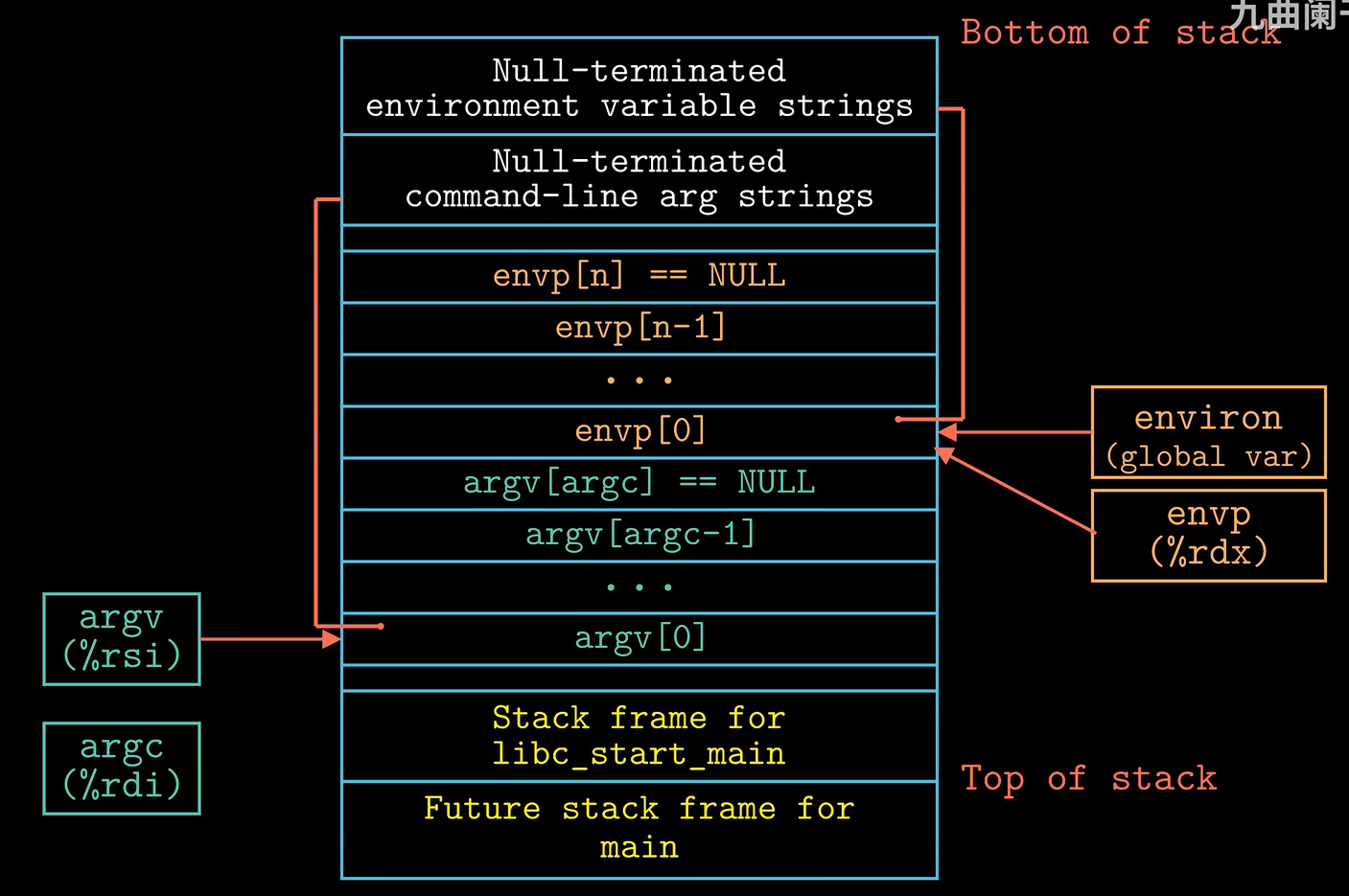
由于 main 函数是被 libc_start_main 函数调用的,所以 main 函数的栈帧在低地址处
exit()
当执行exit()时,整个系统中所有的东西都保持不变,只有执行exit()程序的线程被销毁
_exit(int statue)函数销毁当前状态机,并且允许有一个返回值- 子进程终止会通知父进程
- 对于多线程
- 删除一个线程
- 删除一个总线程之后,其他的线程也跟着结束
结束当前进程的四个方式
return, exit, _exit_, syscallreturn结束函数运行,会调用atexit()exit(0)是存在于libc的库函数- 执行的时候会调用
atexit,将缓冲区中的东西写出去 atexit(func)执行的时候会调用括号里的函数
- 执行的时候会调用
_exit(0)存在于glibc库里syscall wrapper- 相当于系统调用函数,直接终止整个进程所有线程,不会调用
atexit
- 相当于系统调用函数,直接终止整个进程所有线程,不会调用
syscall(SYS_exit,0)- 执行
exit系统调用函数终止当前线程 - 不会调用
atexit()
- 执行
1 | int main(int argc, char* argv[]){ |
waitpid(pid_t pid, int *statusp, int options);
当一个进程由于某种原因终止时,内核并不是立即把它从系统中清除,此时进程被保持在一种已终止的状态中,直到被它的父进程回收。把一个已经终止运行但是还没被回收的额进程称为僵死进程,虽然没有在运行,但是仍然在消耗系统的内存资源。
Linux 系统中父进程可以通过该函数来等待它的子进程终止或者停止
pid
- 如果
pid > 0那就是这个子进程的ID - 如果
pid = -1表示等待的是由父进程创建的所有的子进程组成的集合
statusp 指向status的指针
非空的,放入导致返回的子进程的状态信息
WIFEXITED(status)如果是exit或者return终止为trueWIFSIGNALED(status)如果是因为一个未捕获的信号终止trueWEXITSTATUS(status)可以提取程序返回值,前提是正常终止程序WIFEXITED(status)=1WTERMSIG(status)获取子进程因信号终止的信号,前提是WIFSIGNALED(status)=1信号终止WIFSTOPPED(status)当子进程接收到停止信号时trueWSTOPSIG(status)WIFSTOPPED为true时,获得导致子进程停止的信号类型WIFCONTINUED(status)子进程接收到SIGCONT信号继续执行时true
程序的地址空间
在c语言中, char* p 与 intptr_t 可以相互转换
- 可以指向任何地方,对于这些地方的权限行为,完全取决于pmap的结果
1 | int main(){ |
- 合法的地址(可读或者可写)
- 代码(main,%rip会从此处取出待执行的指令),只读
- 数据(static int x), 读写
- 堆栈(int y),读写
- 运行时分配的内存,读写
- 动态链接库
- 非法的地址
- NULL,一些乱七八糟的地址,导致 segmentation fault
查看进程地址空间 pmap report memory of a process 查看一个进程的地址空间
通过gdb来查看当前被调试的进程的进程号 info inferiors
之后可以使用 pmap + 进程号(或者 vim /proc/进程号/maps) 来查看进程的地址空间
输出的地址和后面会跟上读或写的权限
操作系统提供查看进程地址空间的机制RTFM: /proc/[pid]/maps(man 5 proc)
- 权限
- r 可读
- w 可写
- x 可执行
- p
- 进程地址空间的每一段
- 地址和权限
- 对应的文件:
offset,dev,inode,pathname
对于静态的链接的代码,地址一般都是 4000000 左右
但是对于动态链接的代码,地址一般都是 5555555 左右
当然这都是调试器所生成的地址,对于操作系统,每次运行程序都会有一个地址空间随机化,可以保证程序每次被加载到一个随机的地方,提升程序的安全性,但是调试器会把这个特性关掉( address space layout randomization )
- 这个可以通过
readelf -l a.out |& vim -来查看并且验证着一个部分,实际上对于elf文件中说明了在那个地址,分配多少内存,系统的执行权限 - 在这个里面,有几个没有文件的指令,但是分配了内存,这个就是用来对于为一些文件里为初始化的部分进行初始化 可以通过查看手册
man 5 proc来查看其他的含义
系统调用syscall
执行这条指令之后,系统会进入内核代码,这会带来权限开销或者额外的指令开销
- vdso 只读的系统调用也许可以不陷入内核中,这样运行会更快
- 示例 time
- 时间:内核维护 秒级时间
- gettimeofday()
- 示例 time
- vvar
- anon 已分配内存
- stack 程序堆栈
- mmap 虚拟内存映射 (mmap详细介绍)
mmap 的原理
1 | // 库函数 |
工作过程
memory map 内存映射文件的方法,就是将一个文件或者其他的对象映射到进程的地址空间,实现文件磁盘地质和进程虚拟地址空间中一段虚拟地址的的一一对应关系,实现这样的映射关系之后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页到对应的文件磁盘中,进程就实现了不需要对文件进行 read 或者 write 就完成了文件的读写,内核空间对这段区域的修改也反映用户空间,从而实现不同进程间的文件共享
可以把文件的某一段,当作内存一样来访问。将文件映射到物理内存,将进程虚拟空间映射到那块内存
特点
mmap 向应用程序提供的内存访问接口是内存地址连续的(虚拟内存),但是对应的磁盘文件的 block 可以不是地址连续的
mmap提供的内存空间是虚拟空间(虚拟内存),而不是物理空间(物理内存),因此完全可以分配远远大于物理内存大小的虚拟空间(例如 16G 内存主机分配 1000G 的mmap内存空间)mmap负责映射文件逻辑上一段连续的数据(物理上可以不连续存储)映射为连续内存,而这里的文件可以是磁盘文件、驱动假造出的文件(例如 DMA 技术)以及设备- mmap 由操作系统负责管理,对同一个文件地址的映射将被所有线程共享,操作系统确保线程安全以及线程可见性
- mmap 的设计很有启发性。基于磁盘的读写单位是 block(一般大小为 4KB),而基于内存的读写单位是地址(虽然内存的管理与分配单位是 4KB)
虚拟内存地址转换
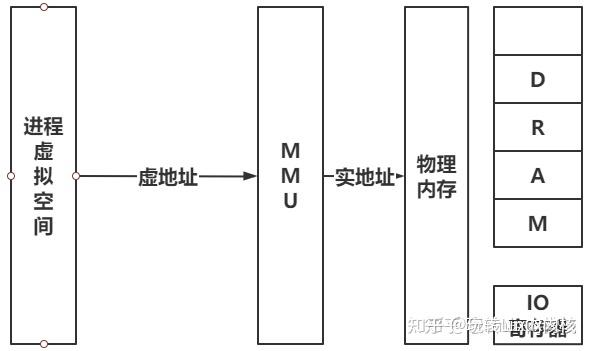
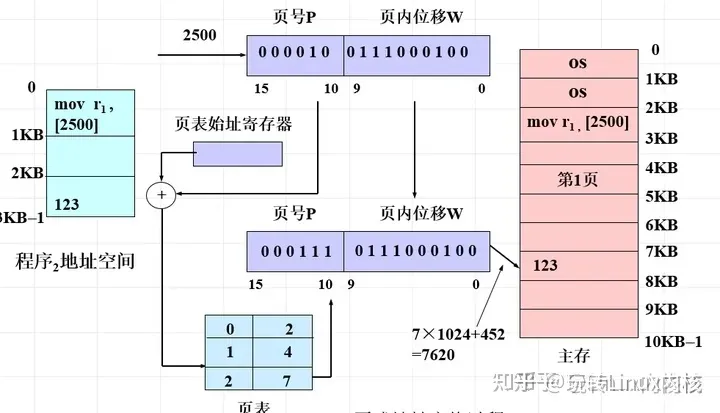
虚地址就是虚拟空间的地址,虚地址通过转换得到实地址,转换方式课程内也讲得很清楚,虚地址头部包含了页号(段地址和段大小,看存储模式:页存储、段存储,段页式),剩下部分是偏移量,经过MMU转换成实地址。
内存的存储方式
虚拟地址头部为页号,通过查询页表得到物理页号,页号*偏移量就能得到物理地址
虚拟地址头部为段号,段表中找到段基地址加上偏移量得到实地址
原理
mmap创建一个新的 vm_area_struct 结构,并且将其与文件/设备的物理地址相连
vm_area_struct
linux中使用 vm_area_struct 来表示一个独立的虚拟内存区域,一个进程可以使用多个vm_area_struct来表示不同类型的虚拟内存地址(堆,栈,代码段,MMAP区域等)
vm_area_struct结构中包含了区域起始地址。同时也包含了一个vm_opt指针,其内部可引出所有针对这个区域可以使用的系统调用函数。从而,进程可以通过vm_area_struct获取操作这段内存区域所需的任何信息。
进程通过vma操作内存,而vma与文件/设备的物理地址相连,系统自动回写脏页面到对应的文件磁盘上(或写入到设备地址空间),实现内存映射文件。
内存映射文件的原理
首先创建虚拟区间并完成地址映射,此时还没有将任何文件数据拷贝至主存。当进程发起读写操作时,会访问虚拟地址空间,通过查询页表,发现这段地址不在物理页上,因为只建立了地址映射,真正的数据还没有拷贝到内存,因此引发缺页异常。缺页异常经过一系列判断,确定无非法操作后,内核发起请求调页过程。
最终会调用nopage函数把所缺的页从文件在磁盘里的地址拷贝到物理内存。之后进程便可以对这片主存进行读写,如果写操作修改了内容,一定时间后系统会自动回写脏页面到对应的磁盘地址,完成了写入到文件的过程。另外,也可以调用msync()来强制同步,这样所写的内存就能立刻保存到文件中。
实现过程
-
进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
调用mmap→在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址→为此虚拟区域分配一个vm_area_struct,对这个结构进行初始化,将其插入到进程的虚拟地址区域链表或者树中
-
调用内核空间的系统调用函数mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
为映射分配了新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核“已打开文件集”中该文件的文件结构体(struct file),每个文件结构体维护着和这个已打开文件相关各项信息。通过该文件的文件结构体,链接到
file_operations模块,调用内核函数mmap不同于用户空间库函数。内核mmap函数通过虚拟文件系统inode模块定位到文件磁盘物理地址。通过remap_pfn_range函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。此时,这片虚拟地址并没有任何数据关联到主存中 -
进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
进程的读或写操作访问虚拟地址空间这一段映射地址,通过查询页表,发现这一段地址并不在物理页面上。因为目前只建立了地址映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。
缺页异常进行一系列判断,确定无非法操作后,内核发起请求调页过程。
调页过程先在交换缓存空间(swap cache)中寻找需要访问的内存页,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。
之后进程即可对这片主存进行读或者写的操作,如果写操作改变了其内容,一定时间后系统会自动回写脏页面到对应磁盘地址,也即完成了写入到文件的过程。前两个阶段仅在于创建虚拟区间并完成地址映射,但是并没有将任何文件数据的拷贝至主存。真正的文件读取是当进程发起读或写操作时
修改过的脏页面并不会立即更新回文件中,而是有一段时间的延迟,可以调用msync()来强制同步, 这样所写的内容就能立即保存到文件里了
Linux操作系统的shell
shell 功能的实现:
linux 系统下, 有一个系统级的打开文件表 (Open File Table).
而每个进程的 PCB (Process Control Block) 中都有一个文件描述符表 (File Descriptor Table), 进程就是通过文件描述符表中的文件描述符对文件进行操作的。每个文件描述符指向打开文件表中的一个文件,不同的文件描述符可以指向同一个文件。其中文件描述符是从0开始的整数
0:标准输入文件
1:标准输出文件
2:标准错误文件
对于 shell 就是首先把指令翻译为一棵树,然后从树的头节点开始执行指令。下面介绍一些指令
-
exec
其中execve是内核级别的系统调用,其他的
execl, execle, execlp, execv, execvp都是调用该系统调用1
2
3
4
5
6int execve(const char *filename, char *const argv[ ], char *const envp[ ]);
函数执行成功没有返回值,失败返回-1
参数
filename 表示文件路径 filename 其实也是可执行的指令,在linux中,echo,cat之类的指令都有存在对应的文件,但是cd是没有执行文件的
argv 是利用数组指针来传递给执行文件,也就是filename,以NULL结尾
最后表示传递给执行文件的新环境变量数组exec系列的系统调用是把当前程序替换成要执行的程序,并且使用fork来产生一个和当前进程一样的进程,通常会运行另一个程序同时保留原程序运行的方法是调用fork+exec
-
redir
重定向 > 的运行顺序是:先创建一个进程,然后将文件描述符重定向,然后执行execve指令
将信息输出到某一个文件中,如果文件存在需要使用!参数进行强制覆盖,可以使用>>追加到文件末尾,使用END停止重定向
1
2
3ls > {file}
ls! > {file}
ls >> {file}重定向的原理就是修改文件描述符的指向
1
2
3
4
5
6
7
8int dup(int oldfd) // 系统调用创建文件描述符oldfd的拷贝并且返回,使用尽可能小的未使用的文件描述符,成功返回之后,新旧描述符可以替换使用
ind dup2(int oldfd, int newfd) // 与上一个基本相同,可以指定返回的文件描述符为newld,如果newld已经打开就关闭它
// 代码实现重定向
int fd = open("filename",O_CREAT|O_TRUNC|O_WRONLY, 0666); // 打开文件,也生成一个文件描述符,oldfd
dup2(fd,newfd);
close(fd);
system("echo hello");
// 其中open的参数中,O_TRUNC 表示 >,如果改为 O_APPEND 可以实现 >> 的功能1
2
3sudo ./a.out > /etc/a.txt
// 会出现错误,因为根据重定向代码执行的顺序,是先创建进程,然后重定向文件描述符(打开文件),最后才执行execve指令
// 文件如果需要sudo权限的话,在打开文件时需要sudo权限,但是此时还未获得sudo权限,就会出错 -
list
一个列表,实现原理:调用fork生成一个进程,然后该进程递归处理list左侧的指令,等待左侧指令执行结束之后,再执行右侧的指令
-
pipe
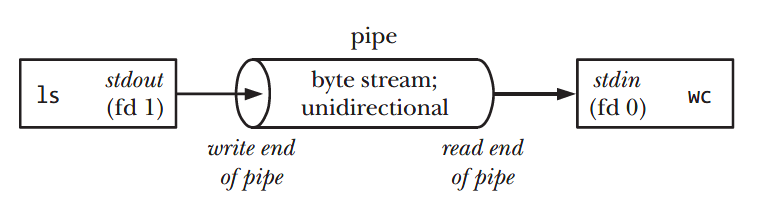
管道中是由两个端口组成的,一端是标准输入端,另一端是标准输出端,先执行左侧的指令,左侧指令的输出会进入到标准输入端,输入到右侧指令中,作为右侧指令的数据输入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21syscall(SYS_pipe, p);
系统中对于管道会创建两个文件描述符,一个管道的读口pipefd[0]管道的标准输出,一个是管道的写口pipefd[1]管道的标准输入
assert(syscall(SYS_pipe, p) >= 0);
if (syscall(SYS_fork) == 0) { // 创建一个和当前进程一样的进程,其中文件描述符也会复制一份
syscall(SYS_close, 1); // 关闭编号为1的文件描述符也就是标准输出
syscall(SYS_dup, p[1]); // 拷贝文件描述符 相当于是把关掉的文件描述符指向了管道的写口
syscall(SYS_close, p[0]); // 关闭文件描述符
syscall(SYS_close, p[1]); // 关闭文件描述符
runcmd(pcmd->left);// 执行左侧的指令
}
if (syscall(SYS_fork) == 0) { // 右侧指令的执行也创建一个进程
syscall(SYS_close, 0); // 关闭编号为0的文件描述符 标准输入端口
syscall(SYS_dup, p[0]); // 拷贝文件描述符
syscall(SYS_close, p[0]);
syscall(SYS_close, p[1]);
runcmd(pcmd->right); // 执行右侧的指令
}
syscall(SYS_close, p[0]); // 关闭文件描述符
syscall(SYS_close, p[1]);
syscall(SYS_wait4, -1, 0, 0, 0); // 等待左侧和右侧的指令执行结束之后再继续
syscall(SYS_wait4, -1, 0, 0, 0);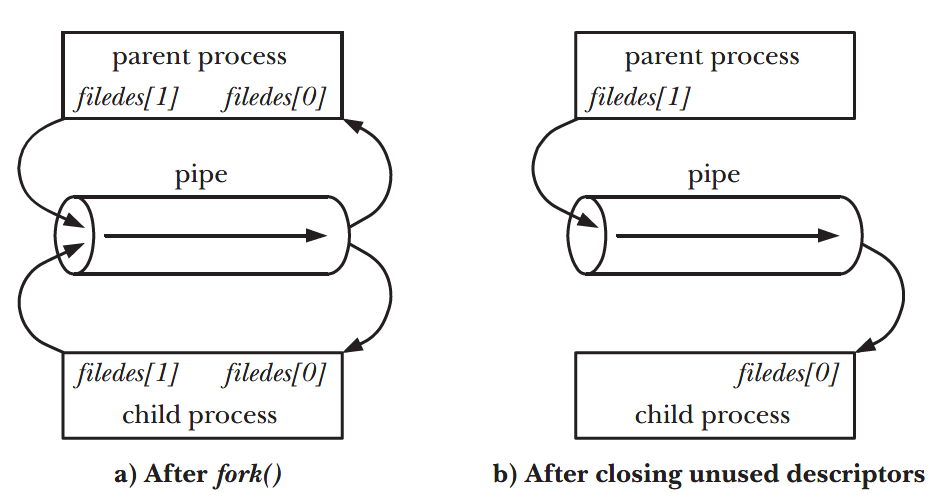
-
back
后台执行
1
if (syscall(SYS_fork) == 0) runcmd(bcmd->cmd); // 直接在后台执行,不等待程序执行结束
-
系统调用fork
fork就相当于是创建一个和自己一摸一样的进程出来,而exec是把当前的进程改变成目标进程
不同的 shell 对同样的指令处理优先级是不一样的
tmux 的实现是不同的终端,把用户的输入全部捕捉下来,然后再转发给对应的终端。执行 tty 可以看到当前的终端编号
对于有输出的指令,终端会判断输出的位置是否为终端,如果不是终端,就会输出到对应文件中
Ctrl-c的退出机制
是因为系统中的信号系统,当按下Ctrl-c时,终端会给前台程序发送一个信号,它收到信号之后会出现对应的操作,ctrl-c会发送一个SIGINT的信号,ctr±会发送一个SIGQUIT的信号,如果一个进程没有注册SIGINT信号的话,默认程序退出
1 | switch (signum) { |
如果在程序中使用 fork指令拷贝一个进程的话,这时候两个进程一模一样,甚至连signalhandler 信号中断都是一样的,在终端中执行ctrl-c的话,终端会发送一个 group 指令,杀死所有 fork 生成的子进程。
任何时刻都只能有一个前台的进程,也就是聚焦到某个进程上,这时候的 ctrl-c 只对前台进程有效,不会对后台进程有效,可以实现 handle ,当程序接收到 ctrl-c 的时候回到系统后台执行
当执行一个程序的时候,shell 会把前台交给这个程序,此时 shell 就不能读到终端的输入指令了,应该是在 wait,程序如果是&执行的话,还可以再读,shell 也相当于是一个进程组
libc 的实现
库分为静态 lib 和动态 lib
- 静态 lib 导出声明和实现都放在lib中。编译后所有代码都嵌入到宿主程序。
- 动态 lib 相当于一个h文件,是对实现部分(.dll文件)的导出部分的声明。编译后只是将导出声明部分编译到宿主程序中,运行时候需要相应的dll文件支持。
[手册](RTFM libc)(RTFSC Newlib)
操作系统内核就是一个C程序
不同位数的系统下,数据类型的长度是不一样的,所以就出现了 int32_t 之类的数据
标准库只对标准库内部数据的线程安全性负责
封装
-
系统调用
1
2
3
4
5
6
7
8
9
10
11
12execve的一个小demo
int main(){
extern char **environ;
char *argv[] = {"echo", "hello", "world", NULL,};
if(execve(argv[0], argv, environ) < 0){ // 系统调用
perror("exec");
}
// 同样的功能实现 libc的封装结果
// system("echo hello world");
// execlp("echo", "echo", "hello", "world", NULL);
} -
计算
1
2
3
4
5
6
7// 系统调用 排序和寻找
void qsort(void *base, size_t nmemb, size_t size,int (*compar)(const void *, const void *));
void *bsearch(const void *key, const void *base,size_t nmemb, size_t size,int (*compar)(const void *, const void *));
// libc/c++封装
sort(xs.begin(), xs.end(), [] (auto& a, auto& b) {...});
xs.sort(lambda key=...) -
文件描述符
1
2
3
4
5
6FILE* f;//其实也是一个文件描述符
// 使用了stdarg.h的参数列表
int vfprintf(FILE *stream, const char *format, va_list ap);
int vasprintf(char **ret, const char *format, va_list ap);
// 系统调用存在popen 和pclose 存在缺陷 -
操作系统状态,环境变量之类的
1
2
3
4extern char** environ; // 封装出来的环境变量,在程序运行过程中被赋值
err, error, perror,
warn("%s", filename); -
地址空间
1
2
3
4
5
6
7
8
9// libc 中实现了内存的分配和释放
malloc(s);
// 返回一段大小为s的区间
// 必要时会向操作系统申请额外的[L,R)空间
// 内存不足时拒绝请求
free(l,r);
// 给定l,删除[l, r)的内存
//! 多线程的不能保证正确性与安全性Scalability
wordLoad分析
O(n)大小的对象分配后至少有Ω(n)的读写操作,否则就是 performance bug (不应该分配那么多),设计优化时要保证所有线程都能够独立申请和分配内存(针对malloc, free)
- 越小的对象创建/分配越频繁
- 字符串,临时对象等,生存周期可长可短
- 较为频繁地分配中等大小的对象
- 较大的数组,复杂的对象,有更长的生存周期
- 低频率的大对象
- 巨大的容器,分配器,很长的生存周期
- 并行,并行,再并行
- 所有分配都会在所有处理器上发生
- 使用链表/区间树不一定是一个好想法
Fast and Slow
- fast Path
-
性能好,并行度极高,覆盖大部分情况
-
有小概率失败
设计:
-
不需要上锁/no contention
-
所有进程都事先分配一些内存,然后各自在自己已有的内存中不断分配小内存,如果自己的内存不够了,就从全局的内存中再分配一点(slow path),一般的话需要内存对齐为 个字节(不在意一点浪费)
-
把内存中的大小内存,按照递增的方式排列,然后每一个大小对应的内存中都指向了一个链表,这个链表里全都是该大小的元素,就这样串起来,以便于对内存的分配,分配速度几乎为O(1)
-
- slow Path
- 不在乎多快
- 但是能把困难的事情做好
实现小内存快速分配的小内存链表 Segregated List
分配:Segregated List (Slab)
- 每一个slab里的所有对象都一样大
- 每个线程都拥有每个对象大小的slab
- fast Path 立即在线程本地分配完成
- slow path pgalloc
- 实现
- 全局大链表
- per-page小链表
- 回收
- 直接归还到slab中
- 归还时的内存可能是另一个线程持有的slab 需要per-slab锁
实现大内存的快速分配
如果想要分配一个很大的内存空间,那就 first fit 或者 best fit
只需要一个数据结构来堆内存进行管理,例如:区间树,线段树….
malloc的实现
使用了 brk 系统调用和 mmap 系统调用来实现内存分配,前提是堆里面空闲空间不足,分配小内存时使用brk线性增长堆空间,分配大内存使用mmap添加一块内存区域映射
创建文件描述符
方法: int open(const char *pathname, int flags);
文件描述符相当于是指向操作系统内对象的指针
- 对象只能通过操作系统允许的方式访问
- 从0开始编号
- 可以通过
open获取,close释放,dup复制 - 对于数据文件,文件描述符会记住上次访问的文件位置
dup的两个文件描述符是共享offset的
copy on write
操作系统的内存安排虚拟化为很多页面,内存地址被映射成很多虚拟界面,在进程中申请的内存的页面都是属于操作系统的,在进程执行过程中,系统会给予这个进程对它所申请的页面一定的权限,当进行fork指令复制进程之后,系统会把子进程也指向父进程的页面,也就是父子进程共享页面,操作系统会对该页面的引用数量进行计数,这时操作系统会把两个进程写的权限抹掉,这时如果进程中对该页面有写的动作时,该操作会向系统发送一个 page fault 的错误,系统知道父子进程都是使用的同一个页面,所以会开始把这个页面拷贝一份,并且把读写的权限重新还给该进程,再重新写入,并且该页面的引用数量减少1。如果是调用指令 fork-execve 时,那就会把子进程直接重置,绝大多数页面是不需要拷贝的,这样做的话就能减少系统的开销,只会复制写入的那一页,其他的不写如的话不会复制,所以进程占用的内存的统计是一个伪命题
例如对于 libc 文件,操作系统中的所有进程调用的都是同一个libc,并且这些进程对于libc都是只读的权限(写的话会出大问题)
ptrace 进程调试
linux中提供的一个进程调试的工具,其实就是GDB的核心技术
提供了父进程可以观察和控制其子进程执行的能力,并且允许父进程检查和替换子进程的内核镜像包括寄存器的值
原理(调试已经运行的进程)
当使用了ptrace跟踪后,所有发送给被跟踪的子进程的信号(除了SIGKILL),都会被转发给父进程,而子进程则会被阻塞,这时子进程的状态就会被系统标注为TASK_TRACED。而父进程收到信号后,就可以对停止下来的子进程进行检查和修改,然后让子进程继续运行。
1 | long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data); |
ptrace 的使用
-
用
PTRACE_ATTACH或者PTRACE_TRACEME建立进程间的跟踪关系 -
PTRACE_PEEKTEXT,PTRACE_PEEKDATA,PTRACE_PEEKUSR等读取子进程内存/寄存器中保留的值 -
PTRACE_POKETEXT,PTRACE_POKEDATA,PTRACE_POKEUSR等把值写入到被跟踪进程的内存/寄存器中 -
用
PTRACE_CONT,PTRACE_SYSCALL,PTRACE_SINGLESTEP控制被跟踪进程以何种方式继续运行 -
PTRACE_DETACH,PTRACE_KILL脱离进程间的跟踪关系ptrace的一些tips:
- 进程状态
TASK_TRACED用以表示当前进程因为被父进程跟踪而被系统停止。 - 如在子进程结束前,父进程结束,则
trace关系解除。 - 利用
attach建立起来的跟踪关系,虽然ps看到双方为父子关系,但在"子进程“中调用getppid()仍会返回原来的父进程id。 - 不能attach到自己不能跟踪的进程,如
non-root进程跟踪root进程。 - 已经被
trace的进程,不能再次被attach。 - 即使是用
PTRACE_TRACEME建立起来的跟踪关系,也可以用DETACH的方式予以解除。 - 因为进入/退出系统调用都会触发一次
SIGTRAP,所以通常的做法是在第一次(进入)的时候读取系统调用的参数,在第二次(退出)的时候读取系统调用的返回值。但注意execve是个例外。 - 程序调试时的断点由
int 3设置完成,而单步跟踪则可由ptrace(PTRACE_SINGLESTEP)实现
通过ptrace实现单步调试的方式有两种
- 父进程执行fork创建一个子进程,通过ptrace设置子进程为PF_PTRACED 标记,然后执行execve加载被调试的程序,父进程可以对子进程进程调试
- 通过ptrace attach到指定的pid来完成对进程的调试
GDB的实现
GDB是GNU发布的一个强大的程序调试工具,用以调试C/C++程序,可以使程序员在程序运行的时候观察程序在内存/寄存器中的使用情况。这个是基于ptrace系统调用来实现的
原理
是利用ptrace系统调用,在被调试程序和gdb之间建立跟踪关系。然后所有发送给被调试程序的信号(除SIGKILL)都会被gdb截获,gdb根据截获的信号,查看被调试程序相应的内存地址,并控制被调试的程序继续运行。
实现
-
建立调试关系
-
gdb ./helloworld开始执行一个程序利用
fork+execve执行被测试的程序,子程序在execve之前调用ptrace(PTRACE_TRACEME)设置自己的调试模式是PTRACE_TRACEME,之后阻塞运行,而父进程(gdb)收到信号后,就可以对停止下来的子进程进行检查和修改,然后让子进程继续运行。 -
gdb pid调用
ptrace(OTRACE_ATTACH, pid, ...)使自己变成被调试程序的父进程,这种使用attach建立起来的跟踪关系可以调用ptrace(PTRACEE_DETACH, pid, ...)解除,并且要有对应的权限
-
-
断点
设置断点
break linenumber当运行到 linenumber 那一行时,被调试的程序就会停止原理
在指定位置插入断点指令,当被调试的程序运行到断点的时候,产生
SIGTRAP信号,该信号被 gdb 捕获并且进行断点命中判定,当gdb 判断出此次的SIGTRAP信号是断点命中之后就会转入等待用户进行下一步处理,否则继续。断点的设置原理
在程序中设置断点,就是先将该位置原来的指令保存,然后向该位置写入
int 3,当程序执行到int 3的时候,就会发生软中断,内核会给子进程发出SIGTRAP的信号,当然这个信号会被转发给父进程,然后用保存的指令替换掉它,等待恢复运行断点命中判定
gdb把所有断点位置都保存到一个链表中,命中判定就是把被调试程序当前停止位置和链表中的位置进行比较,看是否是断点产生的信号还是无关信号
-
单步跟踪
就是指在调试程序的时候,让程序运行一条指令/语句之后停下来
gdb 中常用的指令有 next, step, nexti, stepi
单步跟踪又常分为语句单步(step,next)和指令单步(nexti,stepi)。
在linux上,指令单步可以通过
ptrace来实现,调用ptrace(PTRACE_SINGLESTEP, pid, ...)指令可以使被调试的进程在每执行完一条指令之后就触发一个SIGTRAP信号,让 gdb 运行1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 一个小栗子
child = fork();
if(child == 0) {
execl("./HelloWorld", "HelloWorld", NULL);
}
else {
ptrace(PTRACE_ATTACH,child,NULL,NULL);
while(1){
wait(&val);
if(WIFEXITED(val))
break;
count++;
ptrace(PTRACE_SINGLESTEP,child,NULL,NULL);
}
printf("Total Instruction number= %d/n",count);
}gdb能让我们很容易的检测,修改被调试的进程,比如通过行号,函数名,变量名,实现:
- 需要在编译的时候提供足够的信息,如在
gcc时加入-g选项,这样gcc会把一些程序信息放到生成的ELF文件中,包括函数符号表,行号,变量信息,宏定义等,以便日后gdb调试,当然生成的文件也会大一些。 - 需要对ELF文件格式,进程的内存镜像以及程序的指令码十分熟悉
ptrace可以实时监测和修改另一个进程的运行 - 需要在编译的时候提供足够的信息,如在
-
gdb 为何知道执行到那里出错了
gdb 通过内存中的信息来打印出对应的错误的,根本原因是 运行的二进制文件中有一些能帮助debugger 分析程序运行的状态的信息
在编译的过程中就会生成 drawf 调试信息,允许对于任意一段内春定义一个 f ,这个f可以是turing complete,如果 PC 指针位于这段代码的内存之中的话,就可以生成一些对于变量的信息和程序运行到哪一步了,gcc 也会生成 debug info 便于在调试过程中可以把对应的指令反向编译为c语言以便查看(当然有时候也会生成一些错误的debug info)
gcc 编译过程中使用 -O2,选项 -g -S 可以查看嵌入汇编语言的debug info,可以使用
readelf -w来查看调试信息,错误信息是怎么产生的,可以看一下函数调用的栈。当进行函数调用的时候,系统会把当前的寄存器内的数据存入栈中
创建进程 POSIX Spawn
函数是在 fork 之后设计出来的,其背后使用的方法就是 clone
1 | int posix_spawn(pid_t *pid, char *path, |
fork in the road
- Fork不简单
- Fork 会连带着标准库一起都 fork,libc的buffer被复制了一份,但是很可能不是用户想要的行为,就会比较麻烦
- Fork 线程不安全
- Fork 不安全,fork的指针指向的内存地址是不变的 -打破了内存分配随机化
- Fork 很慢
- Fork doesn’t scale
- Fork 鼓励内存过度分配
可执行文件
-
可执行文件是最重要的操作系统对象,elf,是一个描述了状态机的初始状态+迁移的数据结构
这个数据结构的定义位于
/usr/include/elf.h -
寄存器 大部分由ABI规定,操作系统负责设置
-
地址空间 二进制文件+ABI共同决定
execve 在执行可执行文件的时候,会将系统进程状态机重置,这个可执行文件就是为了描述状态及重置之后的状态,状态就是寄存器和内存的地址空间,一般的寄存器的数值都为0,但是有一些状态 rip,就是进程的初始状态
操作系统上可执行的文件的满足的条件:
- 具有执行(x)权限
- 加载器能识别的可执行文件
execve 决定了一个文件能不能执行,对于一个文件可以通过 strace 来查看执行的结果,不能执行的文件 execve 会返回相应的报错 execve = -1
- 没有执行权限的 a.c: execve = -1, EACCESS
- 有执行权限的 a.c: execve = -1, ENOEXEC
She-bang
在一个文本的最前端加上一行 #! 开头的后面是一个可执行文件
把这个文本添加权限为可执行文件后,执行时系统会调用 execve 并且把第一个参数替换为 #! 后面的可执行文件,并且把这个文件作为第二个参数填入 execve 中,并且 #! 后面的可执行文件能且只能传一个参数
1 | // 对于任意一个文件,后缀不限制,可以把它变为可执行文件 |
(Binutils)
- objdump 把代码中的一部分disassemble 反汇编
- objcopy 把里面的代码数据等二进制的部分拷贝出来
- nm 把文件中的一些符号打印出来
- readelf 显示被执行文件的信息
- addr2line 显示文件
编译和链接
过程
编译器生成文本汇编代码→汇编器生成二进制指令序列
对于生成的汇编代码,如果有一行指令未知,那就会先填上0,但是最终生成的文件中这一部分是要填上的,使得assertion满足
1 | assert( |
这个重填的值为 S+A-P (P = main + 0x0b,这个就是预编译之后的main函数调用hello函数的地方所出现的) (在下面的地址无关代码有详细解释)
gcc 编译器相当于是把c语言指令编译为了指令+内存寄存器的状态机
预处理 cpp
c→预处理之后的文件
编译器 gcc
c→汇编
汇编器 as
汇编→状态机容器
- 一一对应翻译成二进制代码 section, symbol, debug info
- 不能决定的要留下之后怎么办的信息 relocation
链接器 ld
合并所有容器,得到一个完整的状态机
elf本身就是一个容器数据结构,包含了必要的信息
可执行文件的加载
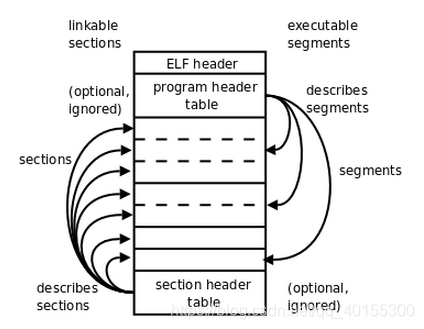
可执行文件就是一个描述了状态机初始状态的数据结构
不同于内存里的数据结构,指针都被偏移量代替
数据结构各个部分的定义位于 /usr/include/elf.h
ELF文件加载器
作用:解析数据结构+复制到内存中+跳转,创建进程运行时的初始状态,还需要设置一些运行时状态
符号重定位
c/c++程序的编译是以文件为单位进行的,因此每个 c/cpp 文件也叫作一个编译单元(translation unit), 源文件先是被编译成一个个目标文件, 再由链接器把这些目标文件组合成一个可执行文件或库,链接的过程,其核心工作是解决模块间各种符号(变量,函数)相互引用的问题,对符号的引用本质是对其在内存中具体地址的引用,因此确定符号地址是编译,链接,加载过程中一项不可缺少的工作,这就是所谓的符号重定位。本质上来说,符号重定位要解决的是当前编译单元如何访问「外部」符号这个问题。
程序在编译的时候,是以源文件为单位来进行的,编译器此时并没有全局的视野,因此对于一个编译单元内的符号是没有办法确定地址的,所以在编译的过程中,未知的符号就会先给0,而对于可执行文件,程序加载的地址是固定的或者是可以预期的,因此在链接的时候,会完成符号重定位,如果可执行文件引用了动态链接库的函数,该模块的起始地址无法确定,只能延迟重定位
静态链接
优点
在程序发布的时候就不需要依赖库,也就是不再需要带着库一块发布,程序可以独立执行。
缺点
- 浪费内存空间。在多进程的操作系统下,同一时间,内存中可能存在多个相同的公共库函数。
- 程序的开发与发布流程受模块制约。 只要有一个模块更新,那么就需要重新编译打包整个代码。
步骤
解析数据结构+复制到内存+跳转
要解决的问题就是将几个目标文件链接起来成为一个可执行文件,现在的链接器一般都采用两步链接
-
地址与空间分配,扫描所有输入的目标文件,合并它们的各个节,更新节表和全局符号表
链接器会为目标文件分配地址和空间,不仅仅是指在输出的可执行文件中的空间,也是在装载后的虚拟地址中的虚拟地址空间。但像.bss这样的节来说,分配空间的意义只限于虚拟地址空间。用
objdump -h可以看到链接前后的虚拟地址的分配情况,其中VMA表示虚拟地址(Virtual Memory Address),LMA表示加载地址(Load Memory Address),正常情况下这两个值是一样的。链接前,目标文件中的所有节的VMA都是0,此时虚拟空间还没有被分配。等到链接后,可执行文件中的各个节都被分配到了相应的虚拟地址。
输入文件中的各个节的虚拟地址确定以后,链接器开始计算各个符号的虚拟地址。因为各个符号在节内的相对位置是固定的,它们的地址也已经是确定的了,也就是节的虚拟首地址加上该符号在节内的偏移量。这样链接器就可以更新全局符号表了。
-
符号解析与重定位,利用上一步搜集到的信息,读取文件中节的数据,重定位信息,进行符号解析与重定位,调整代码中的地址等
ELF 文件中有一个重定位表的结构,专门用来保存与重定位相关的信息,它在ELF文件中往往是一个或者多个节。rel 就是表示存储的是重定位表。使用
objdump -r指令可以查看目标文件的重定位表,每个要被重定位的地方都有一个叫做重定位入口,重定位入口的偏移表示该入口在要被重定位的节点中的位置不同的机器寻址方式可能不同,这样导致重定位时的修正方式也是不同的。
- 绝对寻址
保存在被修改位置的值 + 符号的实际地址 - 相对寻址
保存在被修改位置的值 + 符号的实际地址 - 被修正的位置的地址
- 绝对寻址
-
强弱符号和强弱引用
当多个目标文件中含有相同名字的全局符号的定义时,这些目标文件在链接时将会出现符号重定义的错误。这种符号可以被称为强符号(Strong Symbol)。当然还有一些符号的定义可以被称为弱符号(Weak Symbol)。
对于C/C++来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。GCC的__attribute__((weak))可以用来定义任何一个强符号为弱符号。强符号和弱符号都是针对符号的定义来说的,而不是符号的引用。针对强弱符号的概念,链接器会按照如下规则处理:
- 不允许强符号被多次定义,否则会报重定义错误
- 如果一个符号在某个目标文件中为强符号,在其它文件中都为弱符号,那么选择强符号
- 如果一个符号在所有的目标文件中都是弱符号,那么选择其中占用空间最大的一个,可以使用 -fno-common 的编译选项来使编译器对于重定义的符号报错
在目标文件中对外部目标文件的符号引用在链接过程中也要被正确决议,如果没有找到该符号的定义,链接器就会报符号未定义错误,这种引用被称为强引用(Strong Reference),与之相应的还有一种弱引用(Week Reference)。在处理弱引用时,如果该符号未被定义,则链接器对该引用不报错,默认其为0或者某个特殊的值,以便于程序代码能够识别。在GCC中可以使用__attribute((weakref))__ 这个扩展关键字来声明一个引用为弱引用。
这种弱符号和弱引用对于库来说十分有用,比如库中定义的弱符号可以被用户定义的强符号所覆盖,从而使程序可以使用自定义版本的库函数;或者程序可以对某些扩展模功能模块的引用定义为弱引用,当我们的扩展模块与程序链接在一起时,功能模块就可以正常使用;如果我们去掉了某些功能模块,那么程序也可以正常链接,只是缺少了相应的功能,这使得程序更加容易剪裁和组合。
-
COMMON块
ELF文件的基本结构中,未初始化的全局变量和局部静态变量存储在.bss节中,其实现在的编译器生成的目标文件中,未初始化的全局变量往往并没有被放在.bss节中。
现在的编译器和链接器都支持一种叫做COMMON块(Common Block)的机制,这种机制最早来源于Fortran,早期的Fortran没有动态分配空间的机制,程序员必须事先声明他所需要的临时使用空间的大小。Fortran把这种空间叫做COMMON块,当不同的目标文件需要的COMMON块空间大小不一致时,以最大的那一块为准。
现代的链接机制在处理弱符号的时候,采用的就是和COMMON块一样的机制。当有一强符号时,最终输出结果中的符号所占空间与强符号的相同,但若有弱符号的大小大于强符号,链接器会输出警告。导致需要COMMON块这种机制的根本原因是链接器不支持符号类型,也就无法判断各符号的类型是否一致。
当编译器将一个编译单元编译成目标文件时,如果该编译单元中包含了弱符号,那么该弱符号最终所占的空间大小此时是未知的,也就不能为它在.bss节分配空间,只有链接器在链接的时候才能确定该弱符号的大小,它可以在最终输出文件的.bss节为其分配空间。所以总体看来,未初始化的全局变量最终还是被放在.bss节中的。GCC的编译选项-fno-common和扩展关键字__attribute__((nocommon))允许我们将未初始化的全局变量不以COMMON块的形式处理,那么它就相当于一个强符号了。
静态链接库实际上是一组目标文件的集合,即很多目标文件压缩打包后形成的一个文件。gcc在执行静态链接时,会自动找到我们的目标文件所引用的目标文件所在的和所依赖的静态链接库,并把它们链接进来。为了减小空间的浪费,静态链接库中的每个目标文件往往只包含一个函数。
符号重定位既指在当前目标文件内进行重定位,也包括在不同目标文件,甚至不同模块间进行重定位。但是对于同一个文件中的,编译时就能知道相对地址,但是x86上的mov之类访问程序中数据段的指令要求操作数必须是绝对地址。而对于函数调用一般是相对地址调用,但是计算相对地址也只能在当前目标文件内进行,跨目标文件之间的调用编译器也做不到,只能等到链接时或者加载时才能进行相对地址的计算,因此重定位过程必不可少。但是对于动态链接即使是当前目标文件内,如果是全局非静态函数,那么它也是需要进行重定位的
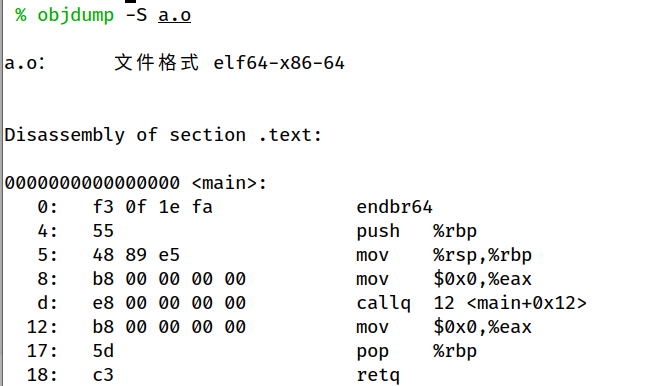
引用的hello函数的地址为12 <main+0x12>. 显然这个地址是错的,编译器当前并不知道 hello 这个函数最后会被分配到哪个地址上,因此在这儿只是随便用一个假的来代替,等着到接下来链接时,再把该处地址进行修正
编译器编译文件时时,会建立一系列表项,用来记录哪些地方需要在重定位时进行修正,这些表项叫作“重定位表”(relocatioin table)

如上最后一行,这条记录记录了在当前编译单元中,哪儿对 hello 进行了引用,其中 offset 用于指明需要修改的位置在该段中的偏移,TYPE 则指明要怎样去修改,因为 cpu 的寻址方式不是唯一的,寻址方式不同,地址的形式也有所不同,这个 type 用于指明怎么去修改, value 则是配合 type 来最后计算该符号地址的。
最后在可执行文件中,该地址就被链接成了对应的代码地址
动态链接
动态链接库的调用也是相当于是查表
共享库shared libraries
为了避免像静态库那种每次执行程序都需要把对应的库文件中的代码段复制到该进程的地址空间中,共享库应运而生
是一种特殊的可重定位目标文件,linux中通常用 .so 的后缀,windows中 dll 为后缀。
共享库在运行或者被加载时,可以被加载到任意的内存地址,还可以和在内存中的程序链接起来,这个过程就是动态链接
创建一个共享库需要用到 -shared 的编译选项表示生成共享库,并且需要用到 -fpic 来生成位置无关代码,这样共享库才能被加载到任意的内存
对共享库进行引用编译之后,生成的可执行目标文件中并没有包含共享库中的代码,只是复制了符号表和一些重定位信息,当可执行文件加载运行时,就会发现可执行程序中存在一个 interp 的 section,其中包含了动态链接器的路径名称。实际上这个动态链接器也是一个共享目标文件,接下来加载器会将这个动态链接器加载到内存中运行,然后由动态链接器执行重定位代码和数据的工作
具体流程
- 将libc.so 的代码和数据重定位到某个内存段
- 然后将重定位动态链接库中的代码和数据段到另一个内存段
- 重定位动态链接库中的定义的符号引用
- 操作完成之后,动态链接器将控制权给程序,从此刻开始共享库的位置就是固定的了
应用程序也可能在它运行的时候要求动态链接器加载和链接某个共享库,而无需在编译时链接
对于软件可以利用共享库的更新来实现软件的更新,运行的时候将加载新的共享库,是一种热更新。也可以实现高性能web服务器。并且对于修改和更新来说不需要停止现在的进程
优点
解决了静态链接的缺陷,更适应现代的大规模的软件开发,只编译一部分不用重新链接,动态库加载比较快,可以支持多个进程之间共享,对整个系统来说可以大大减少对内存的使用
缺点
-
结构复杂。
对于静态链接来说,系统只需要加载一个文件(可执行文件)到内存即可,但是在动态链接下,系统需要映射一个主程序和多个动态链接模块,因此,相比于静态链接,动态链接使得内存的空间分布更加复杂。
不同模块在内存中的装载位置一定要保证不一样。
-
由于是运行时加载,可能会影响程序的前期执行性能。
-
引入了安全问题,这也是我们能够进行PLT HOOK的基础。
动态链接就是在编译的时候,对于一些不知道的文件地址会先填入0,之后等加载的时候再对地址进行填入。动态链接相当于是查表
原理 (可以看看这篇文章)
动态链接就是对组成程序的目标文件等到程序运行的时候才进行链接,也就是把链接这个过程推迟到了运行时再进行,在动态链接下,一个程序被分成了若干个文件,有程序的主要部分,即可执行文件和程序所依赖的共享对象。很多时候我们也把这些部分称为模块,即动态链接下的可执行文件和共享对象都可以看做是程序的一个模块
其实就是加载时重定位,动态加载
对于加载时重定位,linux下的ELF文件主要支持两种方式:加载时符号重定位以及地址无关代码
-
加载时符号重定位
原理很简单,它与链接时重定位是一致的,只是把重定位的时机放到了动态库被加载到内存之后,由动态链接器来进行。
链接完成之后,一些地址仍然是假地址,这些地址在动态库加载完成之后会被动态链接器进行重定位,最终修改为正确的地址,这看起来跟静态链接很像,但是有几个关键的不同之处
- 因为不允许对可执行文件的代码段进行加载时符号重定位,因此如果可执行文件引用了动态库中的数据符号,则在该可执行文件内对符号的重定位必须在链接阶段完成,为做到这一点,链接器在构建可执行文件的时候,会在当前可执行文件的数据段里分配出相应的空间来作为该符号真正的内存地址,等到运行时加载动态库后,再在动态库中对该符号的引用进行重定位:把对该符号的引用指向可执行文件数据段里相应的区域。
- ELF 文件对调用动态库中的函数采用了所谓的"延迟绑定"(lazy binding)策略,只有当该函数在其第一次被调用发生时才最终被确认其真正的地址,因此我们不需要在调用动态库函数的地方直接填上假的地址,而是使用了一些跳转地址作为替换,这样一来连修改动态库和可执行程序中的相应代码都不需要进行了
加载时重定位实际上是一个重新修改动态库中数据符号地址的过程(函数符号的地址因为延迟绑定的存在不需要在代码段中重定位),但我们知道,不同的进程即使是对同一个动态库(stdout/errno/environ等)也很可能是加载到不同地址上,因此当以加载时重定位的方式来使用动态库时,该动态库就没法做到被各个进程所共享,而只能在每个进程中 copy 一份:因为符号重定位后,该动态库与在别的进程中就不同了,可见此时动态库节省内存的优势就不复存在了。
缺陷
- 它不能使动态库的指令代码被共享
- 程序启动加载动态库后,对动态库中的符号引用进行重定位会比较花时间,特别是动态库多且复杂的情况下
-
地址无关代码(PIC)
主要是为了克服一些加载时重定位的缺点,实现原理如下
-
模块内部符号的访问
在这里指的是:static类型的变量和函数,这种类型的符号比较简单,对于static函数来说,因为在动态库编译完成之后,它在模块内的相对地址就已经确定了,并且x86上函数调用只用到相对地址,此时连重定位都不需要进行,编译时就能确定地址,但是对于访问数据来说,需要用到绝对地址,但是动态库未被加载时,绝对地址是无法得知的
ELF 使用了一个小技巧,根据当前 IP 值来动态计算数据的绝对地址。当动态库编译好之后,库中的数据段,代码段的相对位置就已经固定了,此时对任意一条指令来说,该指令的地址与数据段的距离都是固定的,那么,只要程序在运行时获取到当前指令的地址,就可以直接加上该固定的位移,从而得到所想要访问的数据的绝对地址了
一般来说 x86 没有执行可以获取当前的 IP 值,因此会使用一个小技巧来通过函数调用来获取 IP 值(x86_64下不用这么麻烦),这个技巧原理在于进行函数调用的时候,将返回地址压到栈上,此时通过读出栈上的数值就能获得下一条指令的地址了,之后经过计算就可以得到地址
-
模块间符号的访问
模块间的符号访问比模块内的符号访问要麻烦很多,因为动态库运行时被加载到哪里是未知的,为了能使得代码段里对数据及函数的引用与具体地址无关,只能再作一层跳转,ELF 的做法是在动态库的数据段中加一个表项,叫作 GOT(global offset table), GOT 表格中放的是数据全局符号的地址,该表项在动态库被加载后由动态加载器进行初始化,动态库内所有对数据全局符号的访问都到该表中来取出相应的地址,即可做到与具体地址了,而该表作为动态库的一部分,访问起来与访问模块内的数据是一样的。
事实上,ELF 文件中还包含了一个重定位段,里面记录了哪些符号需要进行重定位,模块间的函数调用在实现原理上是一样的,也需要经过一个类似 GOT 的表格进行跳转,但在具体实现上,ELF 为了实现所谓延迟绑定而作了更精细的处理。其中PIC 也可在编译可执行文件时指定,此时可执行文件中的代码对外部符号的引用方式会改变,不再是直接(绝对地址或相对地址)引用该符号,而是也通过 GOT 来间接的引用。
-
延迟加载
动态库是在进程启动的时候加载进来的,加载后,动态链接器需要对其作一系列的初始化,如符号重定位(动态库内以及可执行文件内),这些工作是比较费时的,特别是对函数的重定位,很多时候,一个动态库里可能包含很多的全局函数,但是我们往往可能只用到了其中一小部分而已,而且在这用到的一小部分里,很可能其中有些还压根不会执行到,因此完全没必要把那些没用到的函数也过早进行重定位,具体来说,就是应该等到第一次发生对该函数的调用时才进行符号绑定 – 此谓之延迟绑定。
实现步骤
- 建立一个GOT.PLT 表,该表会存放全局函数的实际地址,但是在最开始的时候里面存放的不是真实的地址而是一个跳转
- 对于每一个全局函数,链接器生成一个与之相对应的影子函数 hello@plt
- 所有对于hello的调用,都是换成 hello@plt,每一个都时这样子的,就相当于是定义了一个函数来代替 call hello
1
2
3
4hello@plt:
jmp *(hello@got.plt)
push index
jmp _init其中第一条指令就是跳转,跳转到 got.plt 中所指向的真实地址,但是如果是函数的第一次调用,那么 got.plt 中存放的是 hello@plt 中的第二条指令,这就意味着第一次调用的时候第一条指令什么都没做,直接继续运行。第二条指令的作用是把当前要调用的函数在 got.plt 中的编号作为参数传给 _init(),而_init() 这个函数则用于把 hello 进行重定位,然后把结果写入到 got.plt 相应的地方,最后直接跳过去该函数。
-
ELF 文件格式

ELF为可执行可链接格式文件。ELF目标文件可以用于程序的链接,也可以用于程序的执行。可重定位目标文件对应连接视图,而可执行目标文件对应执行视图。
ELF 文件格式分为两种
- **可重定位目标文件a:**主要由不同的节组成,节是 ELF 文件中具有相同特征的最小可处理单位,必须具有节头表来链接程序,可重定位目标文件格式主要包含代码部分和数据部分,ELF(executable and linkable format)可重定位目标文件由由 ELF 头、节头表(用于描述各个节)和各个节组成
- **可执行目标文件b:**主要由不同的段组成,多个节合并后映射到一个段中,必须具有程序头表
ELF具体结构解析

节头表
包含文件中各节的说明信息,每个节在该表中都有一个与之对应的项,每一项都指定了节名和节大小等信息
程序头表
指示系统如何创建进程的存储器映像
ELF头
使用指令 readelf -h filename 来显示程序的ELF头信息
最开始的16个字节表示的数据

前4个字节表示ELF的魔数,与ASCII码中的DEL控制符,字符E,字符L以及字符F对应,加载的时候会确定魔数是否正确,不正确就拒绝加载。第7位表示ELF文件的版本号,通常都是1
其中的 Type 表示文件类型:
-
REL 可重定位文件
-
可执行文件
ELF文件头描述了文件的总体格式,其中有一项是程序的入口,就是程序运行时要执行的第一条指令的地址
-
分享文件
位于目标文件的起始位置,包含文件结构说明信息,32位系统对应的结构与64位对应的结构不一样
以下是32位系统对应的数据结构,占用52个字节,64位系统对应的数据结构占用64个字节

e_ident: 长度为 16 字节的序列,最开始 4 个字节为魔数,用来确定文件的类型或格式。在加载或读取文件可通过魔数确认文件类型是否正确。第一个字节为 0x7F, 随后 3 个字节分别为 ‘E’, ‘L’, ‘F’, 后 12 个字节包含一些标识信息,标示 32 位还是 64 位,大端还是小端等。e_type: 说明文件是可重定位文件,还是可执行文件,共享库文件等e_machine: 指定机器结构类型,如 IA-32、SPARC V9等e_version:占4字节,表示版本信息e_entry: 用于指定系统将控制权转移到的起始虚拟地址e_ensize: 为 ELF 头的大小e_phoff:指明程序头表在文件中的偏移e_shoff: 指出节头表在文件中的偏移量e_flags:关于处理器的一些标志,这里不做具体介绍e_ehsize:指明文件头大小e_phentsize:指明程序头表中每个条目的大小e_phnum: 指明程序头表中有多少条目,也就是多少个段e_shentsize: 表示节头表中一个表项的大小,所有表项大小相同e_shnum: 表示节头表中的项数。e_shstrndx:用来指明字符串表对应条目在节头表上的索引
因此 e_shentsize 和 e_shnum 共同指定了节头表的大小。在可重定位文件中只有 ELF 头在文件中固定在开始位置,其他部分位置由 ELF 头和节头表指出,顺序也不固定。
节
readelf -S filename 来查看节的内容
是ELF文件中的主体信息,包含了链接过程所用的代码信息,包括指令,数据,符号表和重定位信息。ELF文件主要包括以下几个节
-
.text 目标代码部分 紧跟在ELFheader之后,存放的是已经编译好的机器代码
-
.rodata 只读数据,例如printf中的格式串和switch语句中的跳转表都存于此
-
.data 已初始化的全局变量和静态变量的值
-
.bss 未初始化的全局变量和静态变量,但是被初始化为0的全局变量和静态变量也存放于此,未初始化的变量没有具体值,所以不占用实际的磁盘空间,只是一个占位符,在程序运行的过程中,会在内存中初始化变量
-
.symtab 符号表,程序中定义的函数名和全局静态变量名都属于符号,符号相关的信息保存在符号表中,链接时需要利用符号表中的信息来把目标文件都粘合到一起
readelf -s filename查看符号表内的符号其中Ndx表示存放的位置
局部变量的信息不会存储在符号表中,会在程序运行过程中存放在栈中
-
.rel.text .text节相关的可重定位信息
-
.rel.data .data节相关的可重定位信息
-
.strtab 字符串表,包括 .symtab 节中的符号以及节头表中的表名。字符串表就是以 null 结尾的字符串序列
-
.debug 调试信息
-
.line 原始C程序的行号和.text section 中机器指令之间的映射
-
.comment 存放的是编译器版本信息
利用 objdump -s -d filename 可以把这部分机器代码反汇编
对于可执行文件中的 .init 节定义了一个名为 _init 的函数,程序的初始化代码会调用这个函数进行初始化,其他部分基本与可重定位目标文件中的节是类似的,不过已经被重定位到最终的运行时内存地址上,所以可执行文件中不需要 .rel 的节。代码运行时,其中的代码段和数据段都会被加载到内存中执行,还有一部分内容(符号表,调试信息)不会被加载到内存中
对于任何一个段,链接器必须选择一个起始地址 vaddr,需要保证 vaddr mod align == off mod align ,这种对齐要求是优化的一种,使得程序在执行时,可执行文件中的段能高效地传送到内存中
链接器上下文中有3种不同的符号
- 由该模块定义,可以被其他模块定义的全局符号
- 由外部模块定义,被该模块引用的外部符号
- 只由该模块定义和引用的局部符号
区别局部变量和全局变量的是static
对于static 相当于是私有的函数和变量,是不能够被其他模块引用的,隐藏变量和函数声明,任何带有static属性的全局变量或者函数都是模块私有的
节头表
使用 readelf -S filename 对文件进行解析
节头表由若干表项组成,每个表项描述相应的一个节的名称、在文件中的偏移、大小、访问属性、对齐方式等,目标文件中每一个节都有一个表项与之对应。32 位可重定位文件对应的节头表数据结构如下图所示,每个表项占 40 字节,64 位每个占 64 位
程序头表
使用 readelf -l filename 命令显示可执行文件的程序头表信息
程序头表发挥了与节头表类似的功能,程序头表中的一个表项对应一个连续的存储段或节。程序头表表项大小和表项数分别由 ELF 头中的字段 e_phentsize 和 e_phnum 指定
32位系统程序头表中每个表项具有以下数据结构。

p_type描述存储段的类型或特殊节的类型。p_offset指出本段首字节在文件中的偏移地址。p_vaddr指出本段首字节的虚拟地址。p_paddr指出本段首字节的物理地址。通常由操作系统动态确定,所以没啥用。p_filesz指出本段在文件中的字节数p_memsz指出本段在存储器中所占的字节数p_flags指出存储权限。p_align指出对齐方式,用一个模数表示,为 2 的正整数幂,例如页面大小为 4KB,则模数为
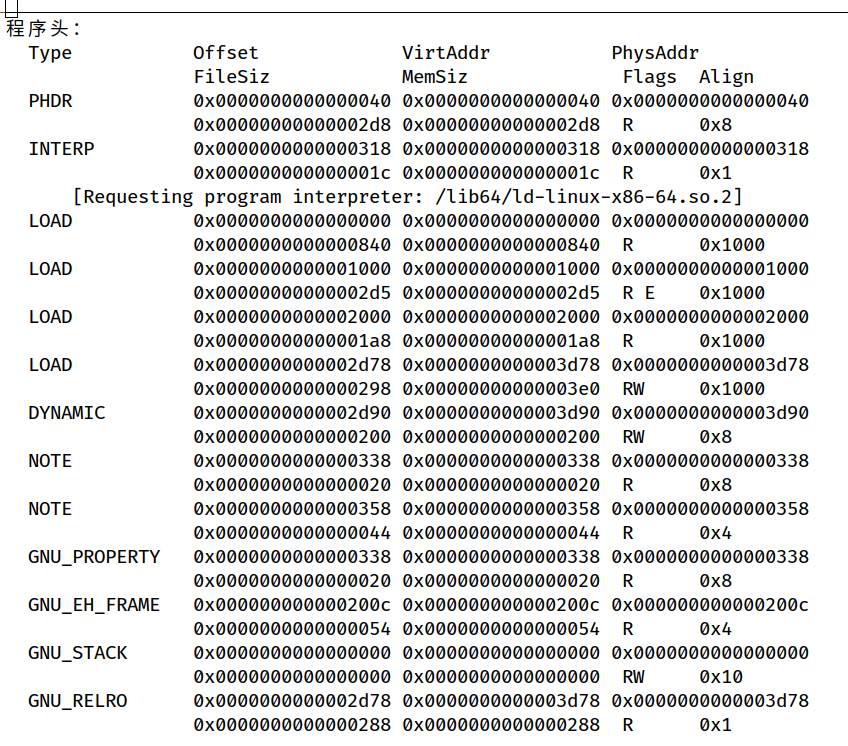
图中给出的程序头表,有4个可装入段(Type = LOAD)。第一个可装入段对应可执行文件中的0x0000000000000000~0x00000000000005c7 字节的内容,被映射到虚拟地址从 0x0000000000000000 开始长度为 0x00000000000005c8 的字节的区域,按 0x1000 = 212 = 4KB 对齐,有可读权限(Flags = R)第四个可装入段对应可执行文件中第 0x0000000000002df0~0x0000000000003010 字节的内容,被映射到的虚拟地址从 0x0000000000002df0 开始长度为 0x228 字节的区域,前 0x220 字节存储的是 .data 中的数据,后 0x8 字节对应 .bss 节,被初始化为 0。有可读写执行权限。从1,4 可装入段可以看出,.data 节在可执行目标文件中占用了相应的磁盘空间,在存储器中也分配了相应大小的空间;而.bss 节在文件中不占用磁盘空间,但在存储器中要分配相应大小的空间。
可执行文件的存储器映像
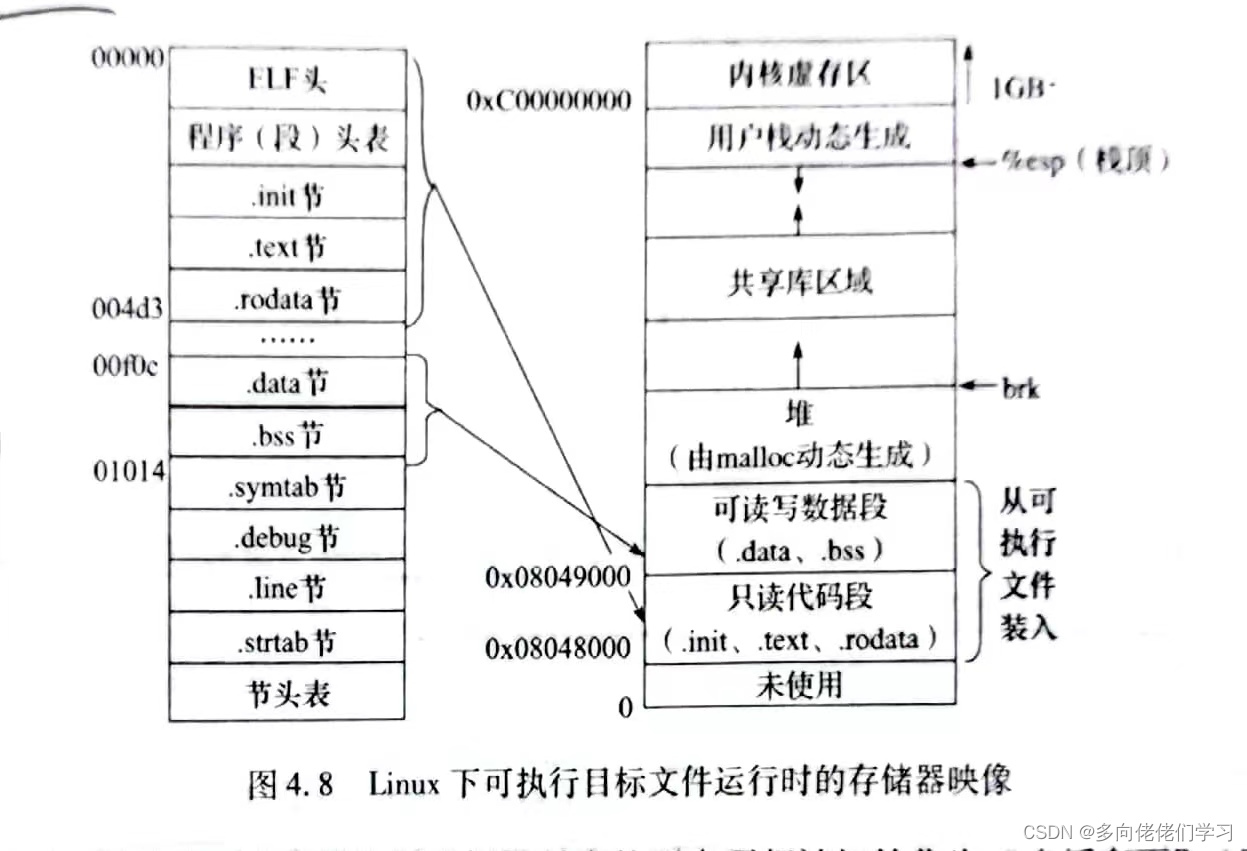
对于 IA-32 + Linux 系统,只读代码段总是映射到从虚拟地址为 0x8048000 开始的一段区域;可读可写数据段总是映射到只读代码段后面按照 4KB 对齐的高地址上;运行时堆则在可读可写数据段后 4KB 对齐的高地址处;栈则是从高地址到低地址增长。
处理器的虚拟化
计算机的CPU会把1s的时间切成很多小片,以此来虚拟化为很多的CPU,实际上只有一个CPU
为什么死循环不能使计算机彻底卡死
- 原理上
- cpu会利用mem[$pc]来取出pc地址里的指令然后执行
- 硬件会发生中断(类似于强行插入的ecall)
- 切换到操作系统代码执行
- 操作系统代码可以切换到另一个进程执行
- 实际上
- 操作系统每隔一段时间就会进入中断来保证操作系统的代码能被调用,以至于操作系统不能卡死,就是相当于对于运行的进程来说,可以每隔一段时间就能调用一个co_yeild()函数。
- 每隔一段时间都保存现场去执行其他的代码,操作系统具有选择下一条指令的权力
程序的加载
- 对于shell来说,收到指令之后就会在操作系统中使用
fork()指令创建一个新进程 - 在子进程中使用
execve()加载a.out。操作系统内核中的加载器识别出a.out是一个动态链接文件,做出必要的内存映射,从ld-linux-x86-64.so的代码开始执行,把动态链接库映射到进程的地址空间中,然后跳转到a.out的_start执行,初始化 C 语言运行环境,最终开始执行main。在linux中可以使用execve来把程序从磁盘中加载到内存中 - 程序运行过程中,如需进行输入/输出等操作 (如 libc 中的
putchar),则会使用特殊的指令 (例如 x86 系统上的int或syscall) 发出系统调用请求操作系统执行。典型的例子是printf会调用write系统调用,向编号为1的文件描述符写入数据。 - 加载器将可执行文件中的代码和数据复制到内存中,然后将CPU的控制权转移到程序开头,随后程序开始执行
每一个linux程序都有一个运行时内存镜像,如图所示,linux中代码段总是从 0x400000 处开始,然后是数据段,运行时 ‘堆’ 在数据段之后,运行时 ’堆‘ 的增长方向是从低地址到高地址,例如C语言中的malloc函数所申请的内存空间就属于堆内存中。堆后面的区域是为共享模块保留的,这个区域把堆和栈隔开了。用户栈的起始地址是 ,也是最大的合法用户地址,栈的增长方向是从高地址到低地址的。再向上从 开始,是为操作系统的代码和数据保留的,这个内存空间对用户代码是不可见的。实际上由于数据段由地址对齐的要求,所以代码段和数据段之间是有间隙的。同时为了防止程序受到攻击,在分配栈,共享库以及堆的运行时地址时,链接器还会用到地址空间随机化的策略,但是相对空间是不变的。
当加载器运行时,它为程序创造图中得到所示内存镜像,根据程序头表的内容,加载器将可执行文件的section复制到内存相应的位置,之后加载器跳转到程序的入口处,也就是_start函数的地址,这个函数在系统目标文件 ctrl.o 中定义,对于所有的C程序都是一样的,该文件属于是C运行时库中的内容。接下来就是 _libc_start_main() 函数,位于libc.so
中,作用是初始化执行环境,然后调用用户层的 main() 函数。 main() 函数返回值交由 _libc_start_main() 函数处理,并且在需要的时候把控制权交还给操作系统
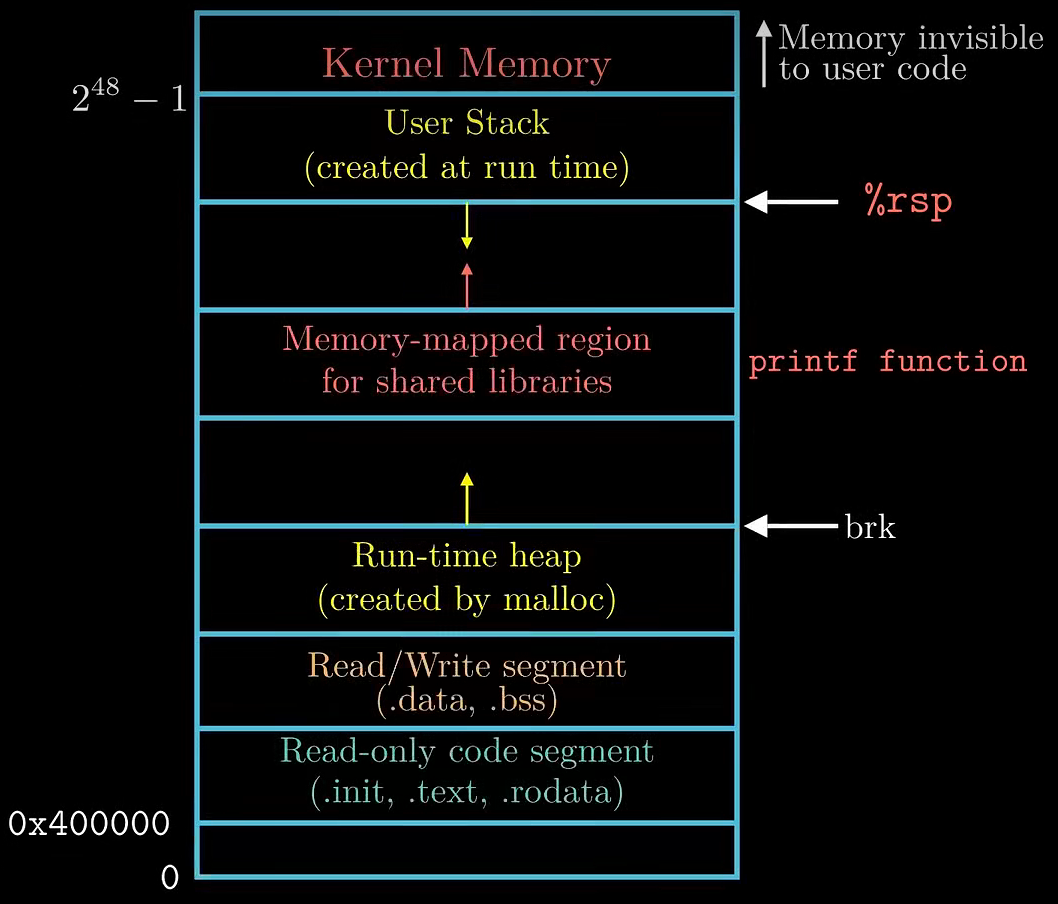
函数启动运行过程
_start() → _libc_start_main() → main() → _libc_start_main() → Linux Kernel
进程,线程,协程
进程
是正在运行的程序的实例,进程拥有代码和打开的文件资源、数据资源、独立的内存空间。
线程
是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一个进程可以有很多线程,每条线程并行执行不同的任务,他们共享进程所拥有的的资源,但线程拥有自己的栈空间。
对操作系统而言,线程是最小的执行单元,进程是最小的资源管理单元。无论是进程还是线程,都是被操作系统所管理的,当发生进程(或线程)的切换,操作系统需要执行”用户态–>内核态–>用户态“切换操作,将切换内容(上下文)保存到内存中(或内核栈)中。
协程
协程是一种比线程更加轻量级的存在,协程可以理解为一个特殊的函数,这个函数可以在某个地方挂起去执行别的函数,并且可以返回挂起处继续执行。一个线程内可以由多个协程来交互运行,但是多个协程的运行绝对是串行的,也就是说同一时刻只有一个协程能运行,其他协程必须被挂起
协程不是被操作系管理的,而是是在用户态执行,完全由程序所控制的,根据程序员所写的调度策略,通过协作(而不是抢占)来进行切换的。协程的本质思想就是控制函数运行时的主动让出(yield)和恢复(resume)。每个协程有自己的上下文,其切换由自己控制,当前协程切换到其它协程是由当前协程自己控制的。有自己独立的存储空间
对比
- 一个进程可以包含多个线程,一个线程可以包含多个协程
- 进程、线程都是由操作系统所管理的,存在用户态和内核态;而协程完全在用户态运行,自己实现调度
- 一个进程可以包含多个线程,一个线程可以包含多个协程
- 一个进程最少包含一个线程;但线程内可以不存在协程
- 当CPU存在多个内核时,一个进程的多个线程可以并行执行;但是一个线程中的多个协程一定是串行执行的
- 进程、线程、协程的切换都是上下文切换,区别如下
- 进程的切换上下文:切换虚拟地址空间,切换内核栈和硬件上下文,切换内容保存在内存中
- 线程的切换上下文:切换内核栈和硬件上下文,切换内容保存在内核栈中 (主要是线程处于同一个进程中,不需要切换虚拟地址空间)
- 协程的切换上下文:切换硬件上下文,切换内容保存在用户态的变量(用户栈或堆)中(协程是属于用户态的,不需要切换内核栈,而且数据也存储在用户态的变量里)
- 进程、线程、协程的调度开销程度: 进程 > 线程 >> 协程
- 协程更适合应用于单核CPU等IO密集但是计算并不密集的场景中,可以快速实现调度,尽可能提高CPU的利用率
协程函数与普通函数的区别
- 普通函数执行完后会退出,并释放栈帧。
- 协程函数可以在运行过程中保存上下文(栈帧),并主动切换到其它线程执行,还可以通过其它协程协作返回本函数继续执行。
特点
- 用户态 协程是在用户态实现调度
- 轻量级:协程不在内核调度,不需要内核态和用户态之间切换,使用开销比较小
- 非抢占:协程是由用户自己实现调度,并且同一时间只能有一个协程在执行,协程主动交出CPU资源
ucontext组件
1 | /* Userlevel context. */ |
uc_link指向后继上下文(即,当前协程运行结束后,接着要被恢复的下一个协程的上下文)uc_stack为该上下文中使用的栈uc_sigmask为该上下文中的阻塞信号集合(可通过man sigprocmask命令查看相关信息)uc_mcontext这个结构体依赖于机器且不透明,作用是保存硬件上下文,包括硬件寄存器的值
1 | /* Structure describing a signal stack. */ |
ss_sp指针 指向的是协程的栈空间的起始地址,可以是用户级的栈变量指针,也可以是堆变量指针ss_flagsflag,在协程使用中设置该值为0。具体作用参考man sigaltstackss_size表示栈空间的大小
1 | // getcontext, setcontext - get or set the user context |
getcontext()函数初始化ucp结构体,将当前上下文保存在ucp中setcontext()函数设置当前上下文为ucp所指向的上下文。ucp所指向的上下文应该是调用getcontext()或makecontext()获得的- 返回值:当调用成功后,
getcontext()返回0,setcontext()不会返回。当调用失败时,两个函数都返回-1并设置合适的errno
1 | // makecontext, swapcontext - manipulate user context |
makecontext() 函数修改 ucp 指向的上下文,该上下文是之前通过调用 getcontext() 获取的,也就是说在调用 makecontext()之前需要调用 getcontext()。且在调用 makecontext()之前,调用者必须分配一个新的栈空间为该上下文,并将栈空间地址设置到 ucp->uc_stack,还要设置 ucp->uc_link指向一个后继协程的上下文。如果func协程上下文中 uc_link值为 NULL,则执行完该协程后,线程会退出
makecontext() 函数将ucp 对应的上下文中的指令地址指向 func函数(协程)地址,argc表示func的入参个数,如果入参为空,该值设置为0。如果argc有值,入参为一系列 (int)整型的数据。
swapcontext() 保存当前协程的上下文到oucp,然后激活(切换到) ucp所指向的上下文对应的协程。返回值:当调用成功后,swapcontext() 不会返回;当调用失败后,返回-1并设置合适的 errno。swapcontext() 函数可以理解成为 getcontext() 和 setcontext() 函数的组合。
单个处理器的调度
系统中有多个进程/线程共享 CPU
- 包括系统调用 (进程/线程的一部分代码在 syscall 中执行)
- 偶尔会等待 I/O 返回,不使用 CPU (通常时间较长)
Round-Robin 策略
中断之后切换到下一个线程运行,如果下一个线程正在等待I/O返回,就继续尝试下一个,如果所有线程都不需要CPU,就调度idle线程执行
中断之间的线程被称为时间片

存在的问题
系统里有两个进程
- 交互式的进程
- 纯粹计算的进程
round-robin
- 交互式的进程使用很短的时间处理完数据之后等待用户输入
- 主动让出CPU
- 计算的进程要使交互式进程在有输入的时候可能被延时
- 必须等待计算一圈之后再执行
优先级策略
unix niceness
- 引入优先级 -20~19
- -20 极坏 优先级最高
- 19 极好 优先级最低
- linux中 nice相差10, CPU的资源获取率相差10倍
- 使用taskset指令设置进程的优先级
动态优先级策略
- 设置若干个 Round-Robin 队列
- 每一个队列对应一个优先级
- 动态优先级调整策略
- 优先调度高优先级队列
- 对CPU的占用率高的程序可以把优先级给低一点
- 对CPU占用率较低的程序可以把优先级高一点
CFS策略(complete fair scheduling)
-
为每一个进程记录精确的运行时间
-
中断/异常发生之后,切换到运行时间最少的进程执行
- 下次中断/异常之后,当前进程可能就不是最小的了
-
操作系统对物理时钟有着绝对的控制
复杂性
-
子进程继承父进程的 vruntime 已经运行的时间,就不会出现疯狂fork出现线程饥饿的情况了,并且父进程首先开始运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// 小栗子
int main(){
setbuf(stdout, NULL);
int pid = fork();
if(pid == 0){
for(const char *s = "Child\n"; *s; s++){
putchar(*s);
sleep(0.01);
}
}
else
for(const char *s = "Parent\n"; *s; s++){
putchar(*s);
sleep(0.01);
}
}
// 运行结果是两个输出混杂在一起,但是首先输出的永远是父进程的输出 -
I/O
例如程序sleep(1) 之后,它的vruntime 十分落后,如果要赶上其他进程的运行时间的话,就需要很多的CPU时间 所以现在的不会给这个程序额外的vruntime了 -
整数溢出
假设系统中最近,最远的时刻差不超过数轴的一半,可以只比较它们的相对大小CFS的数据结构
-
需要维护vruntime的集合
- 更新vruntime
- 取最小的 vruntime
- 进程创建/退出/睡眠/唤醒时插入/删除 t
-
MLFQ策略
- producer/consumer 获得最高优先级 Round-Robin
- while(1) 完全饥饿→需要定期把所有人优先级拉平
多处理器的调度
计算机系统是多核心,多线程的
困难所在
- 多用户多任务
- 既不能简单的分配线程到处理器:线程退出,处理器开始围观
- 也不能简单的把线程分配给有空的处理器:在处理器之间的迁移会导致 cache/TLB 全部白给
- 调度迁移可能过一会还得迁移回来,不迁移会造成处理器的浪费
- 能效比:功率无法支撑所有电路同时工作,总有一部分得停下来
- 能耗
- 软件可以配置CPU的工作模式
- 开关频率越低,能效越好
- 对于同一个进程的不同线程,如果分配到同一个CPU上的运行速度甚至比分配到多个CPU上的运行速度快
- 非统一内存访问:内存共享只是假象,位于同一个/不同module性能差距可能很大
- CPU Hot-plug:CPU的热插拔,对于进程运行的过程中,也许就会少一个CPU,有时会多一个CPU,代码太复杂…
操作系统设计
操作系统=一组对象+访问对象的API
实现=一个C程序实现上面的设计
- windows Subsystem for linux(WSL)
- WSL1 直接使用windows加载文件
- WSL2 虚拟机
- Linux Subsystem for Windows (Wine)
IPC-平台级中断处理器
**minix系统,缺点主要存在于IPC。**进程间通信是指在不同进程之间传播或者交换信息
-
管道
通常指无名管道,是 UNIX 上最古老的IPC形式
特点
- 是半双工的(数据只能一个方向流动),具有固定的读端和写端
- 只能用于具有亲缘关系的进程之间的通信
- 可以看作是一个特殊的文件,对于它的读写也可以使用普通的read、write 等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
-
FIFO
FIFO,也称为命名管道,它是一种文件类型。
特点
- FIFO可以在无关的进程之间交换数据,与无名管道不同。
- FIFO有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中。
-
消息队列
消息队列,是消息的链接表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。
特点
- 消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级。
- 消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除。
- 消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取。
-
信号量
信号量(semaphore)与已经介绍过的 IPC 结构不同,它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据
特点
- 信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
- 信号量基于操作系统的 PV 操作,程序对信号量的操作都是原子操作。
- 每次对信号量的 PV 操作不仅限于对信号量值加 1 或减 1,而且可以加减任意正整数。
- 支持信号量组。
-
共享内存
共享内存(Shared Memory),指两个或多个进程共享一个给定的存储区。
特点
- 共享内存是最快的一种 IPC,因为进程是直接对内存进行存取。
- 因为多个进程可以同时操作,所以需要进行同步。
- 信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问
实时操作系统——RTOS
实时操作系统又称为即时操作系统,会按照排序运行,管理系统资源,并为开发应用程序提供一致的基础
实时操作系统与一般的操作系统最大的特色就是‘实时性’,如果有一个任务需要执行,实时操作系统会立马执行该任务,不会有较长时间延时,这种特性保证了每个任务的及时执行
实时性是RTOS的最大的优点
实时性
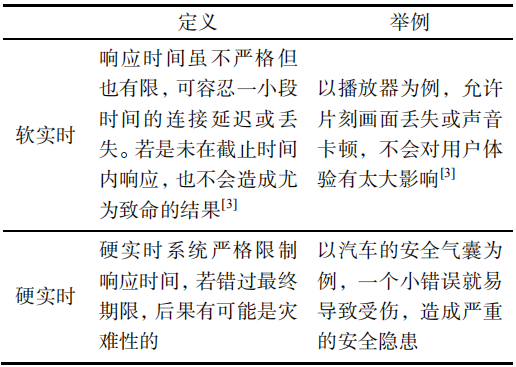
实时运算(Real-time computing)是计算机科学中对受到“实时约束”的计算机硬件和计算机软件系统的研究,实时约束像是从事件发生到系统回应之间的最长时间限制。实时程序必须保证在严格的时间限制内响应。
实时操作系统中都要包含一个实时任务调度器,这个任务调度器与其它操作系统的最大不同是强调:严格按照优先级来分配CPU时间,并且时间片轮转不是实时调度器的一个必选项。提出实时操作系统的概念,可以至少解决两个问题:一个是早期的CPU任务切换的开销太大,实时调度器可以避免任务频繁切换导致CPU时间的浪费; 另一个是在一些特殊的应用场景中,必须要保证重要的任务优先被执行。
国外嵌入式实时操作系统
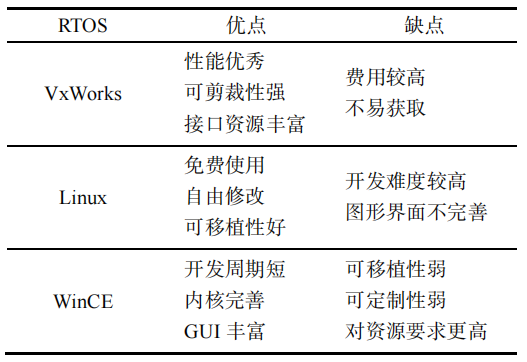
-
VxWorks
VxWorks 凭借良好的可靠性和实时性被广泛地应用在各种高精尖技术行业中,如卫星通讯、军事演习等。VxWorks 最大的缺点是价格昂贵,软件的开发和维护成本都非常高,一般只提供二进制代码,源代码是不提供的,支持的硬件数量有限。
-
Linux
Linux 开源操作系统使用免费、可自由修改,它的功能强大、设计完善,为运行不同计算机平台提供了准确有效的通信手段,在价格上极具竞争力,目前最为流行。Linux 的弊端在于提供实时性能需添加实时软件模块来实现调度策略、硬件中断异常和程序执行。因此,代码错误可能破坏操作系统从而影响整个系统的可靠性。
-
Windows CE
Windows CE(Wince)相对简易开发,周期短且内核完善,可灵活支持通信,GUI丰富且开发功能完善,能更大程度地控制调度机制。但 Wince的版权费用也不可避免存在价格不菲的缺点,没有考虑实时应用,很难支持多种硬件平台,无法做到可定制性,且对资源的要求更高,在网络功能方面应用很少
国内嵌入式实时操作系统
主要是 intewell RTOS
脏页
由于linux内核中存在pagecache,一般修改的文件数据并不会马上同步到磁盘,会缓存在内存的page cache中,我们把这种和磁盘数据不一致的页称为脏页,脏页会在合适的时机同步到磁盘。为了回写page cache中的脏页,需要标记页为脏(dirty)
脏页跟踪是指内核如何在合适的时机记录文件页为脏,以便内核在进行脏页回写时,知道将哪些页面回写到磁盘。匿名页不需要跟踪脏页,因为不需要同步到磁盘;私有文件页也不需要跟踪脏页,因为映射的时候,可写页会映射为只读,写访问会发生写时复制,转变为匿名页;所以只有共享的文件页需要跟踪脏页。跟踪有两个层面:一个是页表项记录,一个是页描述符记录。
访问文件页的两种方式
-
通过mmap映射文件
过程
- 通过mmap映射共享文件
- 第一次访问文件页时,发生缺页后读文件页到 page chche,如果是写访问则设置相应进程的页表项为脏,可写
- 脏页回写时,会通过反向映射机制,查找映射这个页的每一个vma, 设置相应进程的页表项为只读,清脏标记
- 假如第二次写访问这个文件页时,脏页的处理有两种情况
- page cache中的文件页还未回写到磁盘(3 之前), 此刻,这个文件页依然是脏页。因为相应进程的页表项为脏、可写,所以可以直接写这个页
- page cache中的文件页已经回写到磁盘(step3 之后), 此刻,这个文件页不再是脏页。因为页表项为只读,所以写访问会发生写时复制缺页异常,异常处理中将处理共享文件页映射,重新将相应进程的页表项为设置为脏、可写
- 对于mmap映射的共享文件页,因为这个文件页可能会被多个进程共享到多个vma中,所以通过页表项的脏标志位来跟踪脏页:第一次写访问发生缺页异常会读文件页到page cache中并设置进程的页表项的脏标志,回写之前(clear_page_dirty_for_io完成之前),页表项的脏标志是置位的,回写的时候(clear_page_dirty_for_io的调用)会通过反向映射机制将所有映射这个页的页表项的脏标志位清零并设置只读权限,回写之后(clear_page_dirty_for_io完成之后),再次的写访问会发生写时复制缺页异常,再次设置页表项的脏标志位,如此重复,从而跟踪了脏页
-
通过文件系统的write接口操作文件
- 通过write接口访问文件页时,会读取文件页到page cache,不会映射到任何进程地址空间,所有这种方式跟踪脏页是通过设置/清除页描述符脏标记来实现
- 第二次写访问文件页
- 脏页回写之前,页描述符脏标志位依然被置位,等待回写, 不需要设置页描述符脏标志位。
- 脏页回写之后,页描述符脏标志位是清零的,文件写页调用链会设置页描述符脏标志位。
- 对于直接通过write接口访问的文件页,因为这个文件页只会被读取到page cache中,并没有映射到任何进程地址空间,进程写访问是通过copy_from_user的方式,所以通过页描述符记录脏页。回写之前(clear_page_dirty_for_io完成之前),写文件的时候通过文件系统的写文件的调用链会设置页描述符脏标志位,回写的时候(clear_page_dirty_for_io的调用)会清除页描述符脏标志位,回写之后(clear_page_dirty_for_io完成之后),再次通过write接口写访问时,再次通过文件系统的写文件的调用链会再次设置页描述符脏标志位,如此重复,从而跟踪了脏页。
Linux在设计IO模块的时候,认为读写操作的紧迫性是不一样的,读操作的紧迫性要高于写操作。所以Linux的写默认是延迟的,因为这样不仅仅可以显著的提高效率
- 写操作合并:多次写操作才会真正的发起一次写物理磁盘,大幅提升IO性能
- IO栈中还有通用块层和IO调度层,在具体的文件系统层有文件在文件系统中的逻辑块映射,也就是文件的文件块在磁盘上对应的磁盘块的地址,这时候在通用块层会把这些信息封装成BIO对象,然后提交到gendisk->request_queue,在提交的过程中,如果BIO和已有的request中的BIO在物理地址上是连续的,那么这些BIO就会合并成一个request。在IO调度层,一次request就意味着一次IO,因为这时候磁盘需要重新寻址,所以这个合并其实是在io调度层入队列的时候完成的
- 可以通过iostat查看物理盘IO情况,看到对应的监控指标等
- 读操作比写操作更紧迫
- 通常延迟写物理磁盘不会导致进程挂起,写到page cache然后修改该页的PG_dirty标志即可返回(如果open的时候设置了sync标志或者调用了fsync、sync函数,那么会将写page cache的内容封装成一个IO request放到IO调度层的request_queue中,然后由调度层的调度算法来写到物理磁盘)
- 如果读操作读的时候page cache中没有缓存数据,读操作就需要去读物理磁盘,此时就需要一些时间
脏数据:事务对缓冲池中行记录的修改,并且还没有提交
脏读:指的是在不同事务下,当前事务可以读取到另外事务未提交的数据,简单来说就是可以读到脏数据。
VMA (virtual memory area)
在Linux中,每个segment用一个vm_area_struct(以下简称vma)结构体表示。vma是通过一个双向链表(早期的内核实现是单向链表)串起来的,现存的vma按起始地址以递增次序被归入链表中,每个vma是这个链表里的一个节点。
在用户空间可通过"/proc/PID/maps"接口来查看一个进程的所有vma在虚拟地址空间的分布情况,其内部实现靠的就是对这个链表的遍历
vma又通过红黑树(red black tree)组织起来,每个vma又是这个红黑树里的一个节点。为什么要同时使用两种数据结构呢?使用链表管理固然简单方便,但是通过查找链表找到与特定地址关联的vma,其时间复杂度是O(N),而现实应用中,在进程地址空间中查找vma又是非常频繁的操作(比如发生page fault的时候)
使用红黑树的话时间复杂度是O( ),尤其在vma数量很多的时候,可以显著减少查找所需的时间(数量翻倍,查找次数也仅多一次)。同时,红黑树是一种非平衡二叉树,可以简化重新平衡树的过程。
1 | struct vm_area_struct |
持久化
机器指令模型中只有两种状态
- 寄存器 (rax, rbx, ……, cr3)
- 物理内存
存储当前状态的需求:
- 可以寻址
- 根据编号读写数据
- 访问速度尽可能快
- 甚至不惜规定状态在掉电之后丢失
- memory hierarchy 存储器层次结构,内存阶层
持久化:对于需要保存的数据是以一串机械波 delay line memory ,并且相当于是在一根管道里不断循环,当检测到其中有1信号随时间损失,放大器就会补充能量,使之保存数据
memory hierarchy 存储器层次结构,内存阶层
在计算机体系结构中,内存阶层根据响应时间将计算机存储划分为一个层次结构。 由于响应时间,复杂性和容量是相关的,所以这些级别也可以通过它们的性能和控制技术来区分。 内存阶层影响计算机体系结构设计,算法预测以及涉及参考位置的较低级别编程结构的性能。
由于硬件技术的限制,我们可以制造出容量很小但很快的存储器,也可以制造出容量很大但很慢的存储器,但不可能两边的好处都占着,不可能制造出访问速度又快容量又大的存储器。因此,现代计算机都把存储器分成若干级,称为内存阶层(MemoryHierarchy),按照离CPU由近到远的顺序依次是CPU寄存器、Cache(缓存)、内存、硬盘,越靠近CPU的存储器容量越小但访问速度越快。大部分现今的中央处理器的速度都非常的快。大部分程式工作量需要内存存取。由于快取的效率和内存传输位于阶层中的不同等级,所以实际上会限制处理的速度,导致中央处理器花费大量的时间等待内存I/O完成工作。
大部分电脑的内存阶层都是如下
- 暂存器–可能是最快的存取,但仅仅只有几百个字节。
- 第一级(L1)快取–通常存取只需要几个周期,通常是几十个KB。
- 第二级(L2)快取–比L1约有2到10倍较高延迟性,通常是几百个KB或更多。
- 第三级(L3)快取–(不一定有)比L2更高的延迟性,通常有数MB之大。
- 主内存(DRAM)–存取需要几百个周期,但可以大到数个GB。
- 磁盘储存–需要成千上百个周期,但是容量非常的大.
1 | ------ |
对于进程,一旦crash之后,内存和寄存器中的所有状态都会丢失
磁芯内存magnetic core
磁芯存储器(英语:Magnetic Core Memory)是一种早期的计算机存储器。磁芯存储器是利用磁性材料制成之存储器,其原理为:将磁环(磁芯)带磁性或不带磁性之状态,用以代表1或0之比特,一长串1或0之组合就代表要存储之信息
磁芯存储器是一种随机存取存储器(Random Access Memory),在计算机中可担任主存的角色。比起真空管而言,磁芯存储器省电、也没有真空管的寿命问题。当计算机进入半导体时代后,仍然有一段相当的时间,磁芯存储器持续担任主存的角色。又由于磁芯存储器是非易失性存储器(Non-volatile Memory),它的一个特色是:即使死机或电源中断,只要没有发生错误的写入信号,则仍然可保有其内容。
存储介质
磁
读取:放大感应电流
写入:电磁铁磁化磁针
-
磁带
价格:非常低
容量:非常高
读写速度:
- 顺序读取:勉强-需要等待定位
- 随机读取:几乎完全不行
可靠性:
- 存在机械部件,保存环境苛刻
-
磁鼓
- 用旋转的二维平面存储数据
- 容量变小
- 读写延迟不会超过旋转周期
- 随机读写速度提升
- 用旋转的二维平面存储数据
-
磁盘
二维平面上可以放置很多磁带
- 价格低
- 容量高
- 顺序读写速度较高,随机读写速度勉强
- 可靠性 存在机械部件
调度方法
- 当今的磁盘上基本上都有cpu和Dram(dynamic random access memory),基本上是有一个 system on chip ,并且当系统调用的时候会发出请求来调用某一个block的内容,SOC就会对应的返回该block的数据
- [mq-deadline] none 读优先,写不至于饿死
硬盘分类
- SSD
用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单元(FLASH芯片、DRAM芯片)组成。固态硬盘在接口的规范和定义、功能及使用方法上与普通硬盘的完全相同,在产品外形和尺寸上也完全与普通硬盘一致。
优点:读写速度快;防震抗摔性;低功耗;无噪音;工作温度范围大;轻便
缺点:容量小;寿命有限;售价高
- HHD
是既包含传统硬盘又有闪存(flashmemory)模块的大容量存储设备。闪存处理存储中写入或恢复最频繁的数据。
优点:应用中的数据存储与恢复更快,系统启动时间减少,功耗降低,生成热量减少,硬盘寿命延长,笔记本和PAD的电池寿命延长,工作噪声级别降低
缺点:硬盘中数据的寻道时间更长,硬盘的自旋变化更频繁,闪存模块处理失败,不可能进行其中的数据恢复,系统的硬件总成本更高
- HDD
最基本的电脑存储器,我们电脑中常说的电脑硬盘
有磁头,马达,磁盘等一系列零件设备,搭载NAND flash芯片为存储设备,运行速度慢,功耗高,也不轻便
-
软盘
就是一个磁盘的盘片
- 价格低
- 容量低
- 读写速率低
- 可靠性低
坑-compact disk
通过激光扫过表面,就能够把光盘上的坑的信息读出来,但是只能读不能写
克服只读限制的方法
- 使用持久化数据结构,并且使用激光器烧出一个坑来
- 利用PCM来改变材料的反光特性
分析
- 价格低 (可以通过压盘复制)
- 容量高
- 顺序读写速度快,随机读取勉强,写入速度低
- 可靠性强
电
-
Solid State Drive
flash memory 闪存
利用 floating gate 的充放电来实现 1-bit 信息的存储
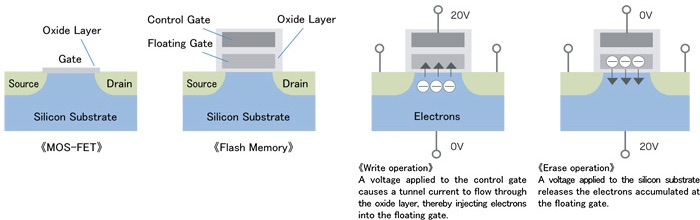
通过上面施加正向或者反向电压来改变存储内部是否有电子,进而来记录 1-bit 的信息
利用的是光刻,可以尽可能的小,借助的是01电路工艺,实际上就是一个大规模集成电路
- 价格低
- 容量高(3D空间上每一个(x,y,z)) 都是1-bit
- 读写速度高:直接通过电路读写,由于电路级并行,容量越大速度越快,快到淘汰了旧的SATA接口标准(NVMe)
- 可靠性高
-
USB Flash Disk U盘
缺点:
放电(erase)不可能做到100%放干净,经过数千/万次充放电之后,就再也无法擦除(dead cell: wear out)
解决:
软件定义磁盘,每一个SSD中都藏着一个完整的计算机
- FTL flash translation layer
U盘,SD卡,SSD区别
- U盘,SD卡,SSD都是NAND flash
- 但实际上软件/硬件系统的复杂程度不同,效率/寿命也不同
- 典型的SSD
- CPU-on chip RAM 缓存,store buffer,操作系统
- 寿命:~1 PiB 数据写入1000年寿命
- SD卡
- SDHC标准未规定jjj
- 良心商家依然有ARM芯片
- 典型的SSD
FTL性能,可靠性,安全性的难题
- 首先,(快速)格式化是没有用的
- 即使格式化后写入数据(不写满)
- 同一个 logic block 被覆盖,physical block 依旧存储了数据(copy on write)
- 需要文件加密系统
输入输出设备
I/O设备
一个能与CPU交互交换数据的接口/控制器。每一组线都有自己的地址,CPU可以直接使用指令(in/out/MMIO)和设备交换数据,并且CPU不管设备具体·是怎么处理的
总线:一个特殊的I/O设备
提供设备的注册和地址到设备的转发,把收到的地址(总线地址)和数据转发到相应的设备上,这样的话CPU只需要直接连接一根总线就可以了
中断控制器
CPU有一个中断引脚
收到某一个特定的电信号就会触发中断(引脚低电平),CPU会保存5个寄存器,跳转到中断向量表对应的位置执行
- 8259 PIC 可以设置中断屏蔽,中断触发等
- APIC
-
local APIC 中断向量表,IPI(处理器间的中断),时钟
-
IPI 处理器间中断
处理器间中断就是一个 CPU 向系统中的目标 CPU发送中断信号,以使目标CPU执行特定的操作。CPU将处理器间中断(IPI) 作为信号直接放在 APIC 总线上传输,并不通过 IRQ 中断线。Linux 在内核中使用了三种处理器间中断。CALL_FUNCTION_VECTOR:该中断被发往所有的 CPU,但不包括发送者。该中断促使目标 CPU 执行特定的操作,实际上就是运行一个随参数传递过来的函数。
-
-
I/O APIC
-
- 系统分发LRQ中断给CPU主要有两种方式
-
静态分发
所有本地 APIC 都会被静态写入中断重定向表的表项中,IRQ 中断请求信号会发送给这些表项的列出的本地 APIC。然后本地 APIC 再将中断发送给目标 CPU。
-
动态分发
在所有 CPU 正在执行的进程中,如果某个 CPU 正在执行的进程的优先级最低,IRQ 中断请求信号就传递给这个 CPU,这就是所谓的最低优先级模式。每个本地 APIC 内部都包含一个可编程任务优先级寄存器 TPR,该寄存器计算运行进程的优先级,以供中断分发参考使用。操作系统内核在进程切换时都会对这个寄存器进行修改。如果多个 CPU 有相同的最低优先级,这种情况是可能的,此时系统就利用仲裁技术来分配 CPU 的负荷。在本地APIC 中有一个仲裁优先级寄存器中,初始化时会为每个 CPU 都分配一个 0—l5 范围内的值。当某 CPU接收到一个中断时,其仲裁优先级的值就自动设置为 0,而其他 CPU 的仲裁优先级都增加一。当仲裁优先级寄存器的值大于15 时,就将获取中断的那个 CPU 的前一个仲裁优先级加 l,作为当前 CPU 的仲裁优先级。因此,中断在 CPU 之间以轮转方式进行分发,并且各个 CPU 任务优先级相同。多 APIC 系统还处理 CPU 之间产生的处理器间中断。某 CPU 为了要向目标CPU 发送中断,它先要将中断向量和目标 CPU 的本地 APIC 的 ID 存入中断指令寄存器 ICR 中,然后经过 APIC 总线向目标 CPU 发送核间中断,目标CPU 接收中断,然后进行中断处理。处理器间中断(IPI)是 SMP 体系结构非常重要的组成部分,利用它可以进行 CPU 间的通信,有效地提升系统的效率。
中断没能解决的问题
程序进行大量的中断读写,就会非常浪费时间
Direct Memory Access (DMA)
是一个专门执行memcpy程序的CPU
支持几种memcpy
- memory → memory
- memory → device
- deivce(register) → memory
- 实现:把DMA控制器链接在总线和内存上
DMA拷贝数据结束之后会发送一个中断信号来告诉CPU已经完成了
DMA
GPU 与 DMA 一样都是一个只做一件特别的事情的CPU,可以实现显示图形
一个完整的众核多处理器系统
-
注重大量并行相似任务
-
程序保存在内存(显存)中
nvcc(LLVM)分为两个部分
- main编译/链接成本地可执行的ELF
- kernel编译成GPU指令
-
数据也保存在内存(显存)中
- 也可以输出到视频接口
- 也可以通过DMA传回系统内存
设备驱动程序
I/O设备的抽象——设备抽象成字节流或者字节序列,I/O设备的主要功能:输入和输出。能够读写的字节序列,在数据未就绪或者无数据时就会等待
操作系统:设备 = 支持各类操作的对象(文件)
- read 从设备某个指定的位置读出数据
- write 向设备某个指定的位置写入数据
- ioctl 读取/设置设备状态
把系统调用(read/write/ioctl)翻译成与设备寄存器的交互,就是一段普通的代码。但是有可能会睡眠(未获得锁,等待其他操作唤醒)
缺点
- 设备不仅仅是数据,还有控制
- 设备的附加功能和配置
- 所有设备的额外功能都是依赖于 ioctl
更多文件操作
1 | struct file_operations { |
其中
unlocked_ioctl是BKL(big kernel lock 内核大锁)的产物- 单处理器时代只有ioctl
- 之后引入了BKL,ioctl执行时默认持有BKL
- 之后通过
unlocked_ioctl避免🔓,ioctl被移除
compact_ioctl机器字节的兼容性- 32-bit 程序在 64-bit 程序兼容
存储设备的抽象
磁盘的访问特性
- 以数据块为单位访问
- 传输有最小单元,不支持任意随机访问
- 最佳的传输模式与设备相关
- 大量吞吐
- 使用DMA传输数据
- 应用程序不直接访问,抽象成一个文件
- 访问者通常是文件系统
- 大量并发的访问,操作系统中的进程都要访问文件系统
文件系统API
为什么需要文件系统
- 设备在应用程序之间是共享的,需要保证写入操作i具有原子性,多个程序并行的时候可能会出现数据竞争
- 驱动设备,每一个驱动设备的调用的应用程序都是一系列对应的API的调用,全部由设备驱动负责调度和隔离
- 磁盘需要支持数据的持久化
文件系统:虚拟磁盘
设计目标:
- 提供合理的API使多个应用程序能共享数据
- 提供一定的间隔,隔离恶意/出错的程序
存储设备的虚拟化
- 磁盘 一个可以读写的字节序列
- 虚拟磁盘 一个可以读写的动态字节序列
- 命名管理,虚拟磁盘的名称,检索和便利
- 数据管理,std::vector
随机读写/resize
文件系统的根
文件系统可以虚拟为一棵文件树
有一个根节点
-
windows:每个设备(驱动器)都是一棵树
C盘开始,AB盘是软盘驱动器上的软盘
优盘会分配新的盘符
-
Unix/Linux
只有一个根目录
unix允许任意目录挂载(mount)一个设备代表的目录树,可以把设备挂载到任何想要的位置
1
2
3int mount(const char *source, const char *target,
const char *filesystemtype, unsigned long mountflags,
const void *data);
linux启动
最初的文件系统的根并不是在设备上的,而是一个 initramfs,这里面的文件非常少,只有 init, bin(busybox),这个文件系统存在于内存里面,之后执行启动的代码再把文件系统加载出来,再把文件挂载到指定位置
1 | export PATH=/bin |
pivot_root 可以实现根文件系统的切换
1 | pivot_root new_root put_old |
文件的挂载
- 文件 = 磁盘上的虚拟磁盘
- 挂载文件 = 在虚拟磁盘上虚拟出的虚拟磁盘
linux的处理方式:
- 创建一个loopback回环设备
- 设备驱动把设备的read/write翻译成文件的read/write
- lsblk 查看系统中的 block devices (strace)
- strace 观察挂载的流程,通过 ioctl 来挂载文件
ioctl(3, LOOP_CTL_GET_FREE)ioctl(4, LOOP_SET_FD, 3)
目录API
- mkdir 创建一个空目录,可以设置访问权限
- rmdir 删除一个空目录,没有递归删除的系统调用, rm -rf能遍历删除整个目录
- getdents 返回count个目录项(ls, find, tree的底层),以 . 开头的文件都会返回
硬(hard)链接
允许一个文件被多个目录引用
- 目录中仅存储指向文件数据的指针
- 不能链接目录
- 不能跨文件系统
对于UNIX文件系统,所有的文件都是硬链接,删除链接的系统调用就被称为 unlink
可以避免磁盘的拷贝,只是一个指向文件数据的指针,减少磁盘内存消耗
软(symbolic)链接
就是在文件里存储一个跳转提示 ln -s
- 软链接也是一个文件
- 当引用这个文件的时候就会去寻找另一个文件
- 另一个文件的绝对/相对路径以文本的形式存储在文件里
- 可以跨文件系统,可以链接目录
- 类似快捷方式
- 即使链接指向的地址不存在
其中使用了symlink的系统调用,但是对于这种软链接是有上限的,在内核代码中有声明
可以任意链接允许创建有向图
- 允许创建任意的有向图
- 允许多次间接链接
- 可以创建软链接的硬链接,软链接也是文件
- 允许成环
进程当前的工作目录:pwd 指令或者 $PWD 环境变量可以查看
chdir 系统调用可以修改 当前工作路径,对应shell中的cd,cd是shell的内部指令,也就是没有外部指令可以修改当前的工作目录
文件API
文件就是虚拟的磁盘,磁盘是一个字节序列,支持读写操作
文件描述符:
- 通过 open/pipe 获得
- 通过 close 释放
- 通过 dup/dup2 复制
- fork 时继承
mmap 磁盘映射
使用open打开一个文件之后
- 使用 MAP_SHARED 将文件映射到地址空间中
- 使用 MAP_PRIVATE 创建一个 copy-on-write 的副本
1 | void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); |
文件访问的游标
文件描述符不仅仅指向一个虚拟磁盘,而是指向了这个虚拟磁盘的一个具体的位置,这样的话,连续读写不需要指定文件读写的位置,如果一次写入太多,超过了虚拟磁盘的大小,虚拟磁盘就会自动扩容到写入的大小,并且写完之后,游标指向最后的位置
偏移量管理
操作系统的每一个API都可能和其他的API有交互
- open 获得一个独立的 offset
- dup 两个文件描述符共享 offset
- fork 父子进程共享 offset
- execve 文件描述符不变
- O_APPEND 方式打开的文件,偏移量始终在最后
1 |
|
1 | //------------------------------------------------------------------------ |
文件系统的API
- 目录
- mkdir, rmdir, link, unlink, open
- 文件
- read, write, mmap, stat, open
- 文件描述符
- lseek
文件系统
文件系统可以抽象为一个数据结构,以block为基本单位,可以抽象为blockarray,blockset等数据结构
利用balloc函数分配block内存,对于分配出来的内存可以使用一个链表连接起来
FAT文件系统File Allocation Table
1 | int balloc(); // 返回一个空闲可用的数据块 |
很小的文件系统
- 树状的目录结构
- 系统中以小文件为主
文件实现方式
- struct block * 的链表
使用链表存储数据有两种设计
-
在每一个数据块之后放置指针
- 优点:实现简单,无须单独开辟存储空间
- 缺点:数据的大小不是 ,单纯的lseek需要读取整块数据
-
将指针集中存放在文件系统的某个区域
- 优点:局部性好,lseek 更快
- 缺点:集中存放的数据损坏将导致数据丢失,对于这个区域,读写最频繁,所以最可能损坏
lseek需要遍历指针链表,解决:把存储的指针存储n份
FAT-12/16/32 即next指针的大小
FAT决定指针的类型大小
1 | if (CountofClusters < 4085) { |
对于flash,上层是可以完全看到flash的状态,一旦有损坏就是全盘都怀掉了,会自动屏蔽这些 cluster,对于以前的文件系统,如果有一块 cluster 怀掉了,系统就不分配值一块内存,系统可以容忍这些错误
对于系统文件,会有指针指向文件的下一块内存,当指针的内容是0xff 的话,就是文件结束了,否则就是文件的下一块block的地址
目录文件
以普通文件的方式存储目录这个数据结构,里面有很多叫做directory entry的数据结构

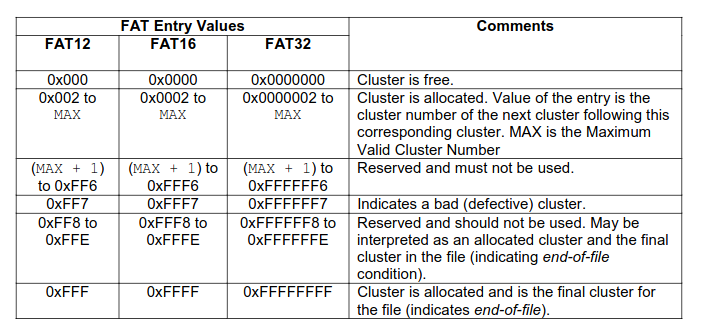
对于当时的FAT文件系统中,如果next中存放的数据是0,就说明内存是free状态,如果是2~MAX,说明内存已经被分配,如果是(MAX+1)~0xff6,文件系统处于一个不正确的状态,FF7就是文件系统出错了,FF8~FFE 保留并且不能被使用,也许是被解释为一个分配了的内存,并且是文件的末端的一块区域,0xFFF区域被分配并且是文件末端的区域
格式化 = FAT表丢失,所有的文件内容都在,只是对于数据结构看来都是free block,本质上是 cluster 的分类和建立可能的后继关系
FAT性能
- 小文件很合适
- 但是对于大文件的随机访问就很麻烦,4GB的文件跳到末尾(4kb cluster)需要多次操作,缓存可以解决,但是又引入了复杂的东西
- 在 FAT 时代,磁盘连续访问的性能更佳,但是时间久的磁盘会产生碎片,malloc也会产生碎片,但是对性能影响不大
FAT可靠性
- 维护若干个FAT副本,方式元数据损坏,但是每次写FAT都会把每个备份都给写一份
- 损坏的 cluster 在FAT中标记
ext2/UNIX 文件系统
| Summary | Findings |
|---|---|
| Most files are small | Roughly 2K is the most common size |
| Average file size is growing | Almost 200K is the average |
| Most bytes are stored in large files | A few big files use most of the space |
| File systems contains lots of files | Almost 100K on average |
| File systems are roughly half full | Even as disks grow, file systems remain ~50% full |
| Directories are typically small | Many have few entries; most have 20 or fewer |
按照对象方式集中存储文件/目录元数据
- 增强局部性(更容易缓存)
- 支持链接
为大小文件区分 fast/slow path
- 小的时候应该使用数组,不需要遍历,直接index访问
- 大的时候使用树 (tree) 快速随机访问
ext2磁盘镜像的格式
磁盘分组:
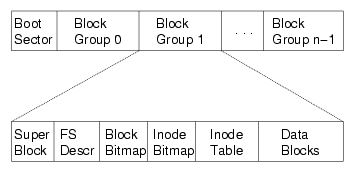
superblock:文件系统元数据
- 文件 (inode) 数量
- block group 信息
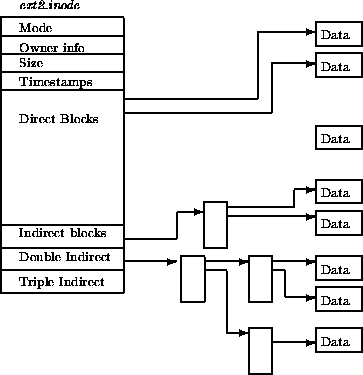
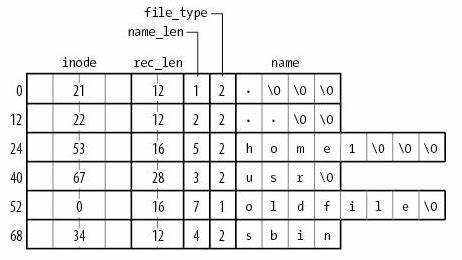
inode 统一存储,目录文件中存储文件名到inode编号的key-value mapping
ext2性能
大文件随机读写性能提升明显
- 支持链接
- inode 在磁盘上连续存储,便于缓存/预取
- 依然出现碎片
可靠性不好,存储inode的数据块一旦损坏是很严重的,文件系统会丢掉所有文件
FTL (falsh translation layer) 闪存转换层
FTL(Flash Translation Layer)译为闪存转换层,是Flash Memory(存储介质)与Device Controller(设备主控器)之间的连接关系
在整个储存体系中,FTL起着翻译官的作用,它将Host(电脑、手机等)发送至Device(eMMC、SSD)的逻辑地址转换为写入Flash的物理地址(地址映射管理)。在进行地址转换的同时,FTL还兼顾Flash的管理,不仅需要对Flash上的各个Block进行擦写次数控制(磨损均衡),还需要管理Flash上的无用数据(垃圾回收)
-
地址映射管理概念
不同于机械硬盘的磁头直接进行数据读写,SSD或者其它以Flash作为储存介质的硬盘无法直接进行数据读写操作。解决这个问题的办法,就是FTL层管理几张逻辑映射表做一个中间转换,Host给定一个逻辑地址,FTL根据这个逻辑地址在逻辑映射表上建立映射关系,连接到Flash上的物理地址。一般来说,FTL将逻辑地址处理后,建立的映射关系包含了Flash的Block编号、Page编号等,数据读取时便根据这些信息在Flash对应的位置上找到数据,传输至Host
-
磨损均衡概念
以Flash为储存介质,其可编程次数是必须考虑的重点。拿目前的固态举例,多以TLC Flash为储存介质,其编程次数在1000-1500次之间,若对TLC Flash上的某些block擦除次数超过了次数限制,那么将导致坏块产生,所以FTL须实现磨损均衡,协调整个Flash上的Block,将使用次数少的Block拿出来分担使用次数多的Block的压力。通俗的说,磨损均衡就是以相对最优的选择使Flash上每个Block的擦除次数尽可能相同,以避免有些Block擦除次数过多成为坏块致使用户可用容量变小的问题。
-
垃圾回收概念
因为储存原理的不同,删除SSD等以Flash为储存介质的硬盘上的数据时,只是删除了Host端的逻辑地址,而实际数据存在Flash的物理地址上,依旧霸占着空间(所以不要以为你的数据删除了就安全了,没进行垃圾回收时,他们依旧可以找回),后续数据写进来只能写到其他Block(Page)上,这就可能造成一个Block上的8M数据只有2M是有效数据,其他的都是被删除了逻辑地址的“假数据”,久而久之,就会导致空Block不够用了。解决这个问题呢,就靠垃圾回收(GC)了,它功能就是找一个空Block(目的Block),然后把那些“假数据”比较多的Block(源Block)上的有效数据搬移过来,再把源Block释放擦除,这样,一个目的Block可以容纳多个源Block的数据,达到强行一换多的目的,给用户腾出了更多的空间。
UNIX文件系统
Unix系统采用树形文件结构、内核与外核的结合、设备与文件一样的管理机制和使用方法等技术和措施,使得Unix文件系统成为当代非常优秀的系统
管理结构
通过磁盘索引i节点,目录项来进行管理的,在文件被打开或者被引用之后还需要“内存索引i节点”,“用户文件描述表”,”文件表“。文件系统磁盘结构如图

- 引导块:引导块占用第0号物理块,不属于文件系统管辖,如果系统中有多个文件系统,只有根文件系统才有引导程序放在引导块中,其余文件系统都不使用引导块
- 管理块:主要管理磁盘结构中各部分区域的大小及资源(i节点,磁盘块)的使用情况与管理方式
- i节点区:用于存放该文件系统全部磁盘i节点结构,磁盘索引节点包含文件的重要信息:文件所有者标识符;文件类型;文件存取许可权;文件联结数目;文件存取时间;文件长度;文件地址索引表。
- 数据区:存储文件数据
Unix 的每个目录只存放文件名和i节点号,一共16个字节,而文件中除名字以外的信息都存放在i节点中,优点是系统各级目录的规模大大减小。在Unix文件系统中,为了提高系统效率,减少内存空间的占用,当打开一个文件时,只是将与该文件相联系的目录项和磁盘i节点拷贝到主存中,为了对打开的文件进行管理,因此又设置了打开文件管理机构,它又由下列三部分组成:
- 活动i节点(内存i节点)反映文件当前活动情况,因此添加了一些项目:内存索引节点状态,设备号,索引节点号,内存索引节点的访问计数
- 打开文件表。i节点中只包含有文件的静态信息,但当一个文件被同一进程或不同进程、用同一或不同路径名、相同的或互异操作同时打开时,仅靠i节点就不能满足要求,因此,打开文件表记录了打开文件所需的一些附加信息:读写状态、引用计数、指向内存索引点的指针、读/写位置指针
- 用户文件描述符表。每个用户进程有一个用户文件描述符表,每一个表项就是一个指针,并指向打开文件表的一个表项,这个表的作用就是保证每个进程能够打开多个文件,或者对同一个文件以不同形式操作打开
物理结构
采用的是索引文件结构,在索引节点中建立有13个地址项

对于长度不超过10个物理块的小型文件,可直接找到该文件所在的盘块号;对于中、大型文件采用一次或两次间接寻址;对超大型文件采用三次间接寻址。索引节点的优点是:索引节点占用的空间小,对小文件的索引速度快,同时又允许组织大型和超大型文件。文件最多可占用的物理块数可达到10+ 256+256^2+ 256^3个,其实就是按块来分配内存,如果较大的文件,就可以在一块的末尾处添加一个指针来指向下一块内存的地址,用来寻址
Unix 的统计数据表明,80%为小文件,20%为大文件(其中1%为超大文件),这组数据就更加说明了 Unix 文件系统设计的精妙和科学。为了提高磁盘空间的利用率,允许文件在磁盘上不连续存放,且其寻址方式最多可达到三次。它的缺点是造成访问文件的寻道时间延长和多次访问磁盘。在非实时场合是可行的,但在实时场合,它的这一缺点就很突出。
空闲磁盘块
unix 文件系统通过管理块来管理空闲块,数据结构如下
1 | struct filsys{ |
空闲块的管理方法是:将空闲块从后向前,若干个空闲块(如100个)分为一组(最后一组为99块),每组最后一块作为索引表,用来登记下一组100的物理块号和块数,最前的一组物理块号和块数存放在管理块的s_free[100]和s_nfree中。这种对空闲块先分组,再把组与组进行链接的管理方法称为组链接法。对空闲块的分配和释放类似于栈,使用后进先出算法。但其管理机构分为两级,一级常驻内存(管理块的s-nfree和s-free[]),另一级则驻在各组的第一个盘块上。其优点是常驻内存的只有一个组,而不是将所有组的空闲表都调入内存,这样就大大的节省了内存空间,同时软件开销也小。缺点是可能导致物理块的利用率不均匀。例如:假设当前的s-nfree= 80,此时某进程释放一个文件块,其占用的物理块号为300,系统回收它后,s-nfree= 81,s-free[81]= 300。接着某用户又申请物理空间,文件系统总是从索引表中取最后一项的值,即s-free[81]出栈,将300号物理块又立即分配使用。可以想象,300号块还会面临再释放,再分配的可能。300号块多次被使用,而其它空闲块却未被分配使用,即有些物理块可能长期被使用,而有些物理块可能长期得不到使用,因此对外存储器的使用寿命不利。
结构和共享
Unix的文件系统采取多级树型目录结构,其优点是有效的解决了文件重名问题,又可以很方便地实现文件共享。基本文件系统和子文件系统是可安装和可拆卸的,但在多用户环境下,多用户间共享数据同样感到不方便,绝对路径名是文件的唯一符号名,用户难以用另外符号名使用共享文件,因此Uinx文件又提供了如下两种链接机制
- 硬链接技术。如果想为文件 1.c 建立一个硬链接2.c,则只需将2.c的目录项指针指到文件1.c 的 inode,同时将i节点链接数加1即可。这样用户似乎是增加了一个物理拷贝,可实际却只有一个文件实体,当删除链接时,只要删除一个目录项和将链接数减1
- 符号链接技术。如果想为 usr/sxk/1.c 建立一个符合链接2.c,则 Unix 通过 read link 读出文件内容,即找到原文件路径名,再通过原文件路径名去打开文件。符号链接相当于给文件增加了一个别名。也可为目录建立符号链接,并且可以跨文件系统。Unix文件链接的优点是用很小的开销为多用户共享文件提供了有效方式,且能快速定位文件和目录;缺点是对多用户使用文件不能加以并发控制,易造成数据的不一致性。硬链接只适用于普通文件,而不适用于目录文件和不同文件系统
安全性
Unix是多用户操作系统,且它的各种外围设备都由相应的文件表示,因此安全性就很重要,它的安全主要通过磁盘i节点的权限设置来实现,每个Unix文件和Unix目录,都有3个允许的比特位设置,分别定义文件所有者、分组和其他人的使用权限,如:允许读、允许写、允许执行、允许SUID、允许SGID等,系统对文件保护的支持是比较充分的,只要正确设置文件和目录的权限,文件安全是有保障的。但需要注意的是,权限为SGID和SUID的可执行文件。SGID(SUID)中的S指set,程序在运行时,其进程的EUID(Effective UserID)或EGID(Effective Group ID)会被设成文件拥有者的UID、GID,从而进程也具有了Owner或OwnerGroup的权限。因此,如果使用不当,SGID和SUID程序会给系统安全性带来极大的危害。另外,在Unix系统中还应当留意设备文件,谨防它成为不安全的后门。例如,如果某个用户拥有/dev/lmem的读写权限,他就可以使用debugger(或其它程序)修改优先级或其它属性,也可以读取系统缓冲区的数据。Unix中的日志文件能够记录操作系统的使用状况,通过分析日志文件可以发现攻击迹象。
linux文件系统
结构
磁盘的特点:
- 可以原地重写
- 可以直接访问任意一块
需要提供高级快捷磁盘访问,以便轻松存储,定位,提取数据。
- 访问问题:如何让定义文件系统对用户的接口
- 存储问题:创建数据结构和算法,把逻辑文件系统映射到物理外存设备
文件系统本身通常由许多不同层组成。每层实际利用更低层功能,创建新的功能,以用于更高层的服务
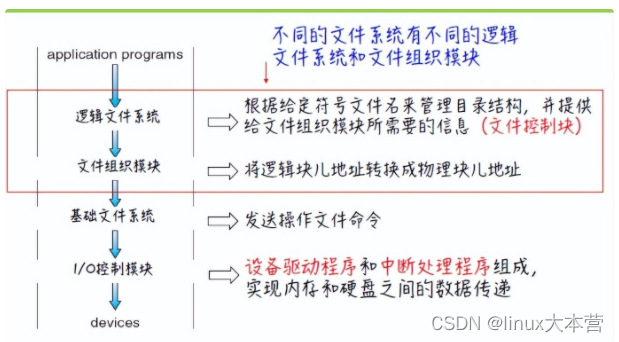
设备驱动程序可以作为翻译器,输入作为高级指令,输出由底层的硬件特定指令组成
基础文件系统只需要向适当设备驱动程序发送命令就可以
逻辑文件系统通过文件控制块维护文件结构
文件控制块(FCB)包含有关文件的信息,包括所有者,权限,文件内容的位置
大多数操作系统支持多种不同的文件系统
- CD-ROM ISO9660 文件格式
- Unix 文件系统(Unix File System)
- Windows文件系统:FAT(File Allocation Table),FAT32, FAT64,NTFS(Windows NT File System)
- Linux 文件系统:可扩展文件系统(Extended file system),分布式文件系统(Distributed File System)
实现
磁盘上,文件系统信息有
- 如何启动,存储地址
- 总的块数
- 空闲块的数目和位置
- 目录结构
- 各个具体文件的内容
结构上分为:
- 引导控制块(每个卷)可以包含从改卷引导操作系统所需要的信息,如果磁盘中没有操作系统,那么这块内容为空。UFS被称为引导块,NFS被称为分区引导扇区
- 卷控制块 包括卷的详细信息(分区的块数,块的大小,空闲块的数量和指针,空闲FCB的数量和指针。UFS被称为超级块,NTFS主控文件表
- 每个文件的FCB包含该文件的许多详细信息,有一个唯一的标识号,以便与目录条目相关联
- 每个文件系统的目录结构用于组织文件
内存中的信息用于管理文件系统,并且通过缓存来提高性能,这些数据在安装文件系统时被加载,在文件系统操作期间被更新,在卸载时被卸载,这些结构包括:
- 每个进程的打开文件表:包括一个指向系统的打开文件表中合适条目的指针和其他信息
- 整个系统的打开文件表:包括每个打开文件的FCB副本和其他信息
创建一个新文件
- 应用程序调用逻辑文件系统。逻辑文件系统指导目录结构的格式,它会分配一个新的FCB
- 系统将相应的目录信息读入内存
- 更新目录结构和FCB
- 将结果写回磁盘
一旦文件被创建,就能用于I/O,不过,首先他要被打开。系统调用open()将文件名传到逻辑文件系统,系统调用open():
- 首先搜索整个系统的打开文件表,查看是否已经被打开,如果是,则在该进程的打开文件表创建一个条目,并指向现有整个系统的打开文件表。
- 否则,根据文件名搜索目录结构
- 找到后,它的FCB会复制到内存的整个系统的开放文件表中(该表还存放着打开该文件的进程数量),接下来,在该进程的打开文件表创建一个条目,并指向现有整个系统的打开文件表。
Open()返回值:文件描述符是一个非负整数。它是一进程打开文件表的索引值,指向系统范围内打开文件表相应条目
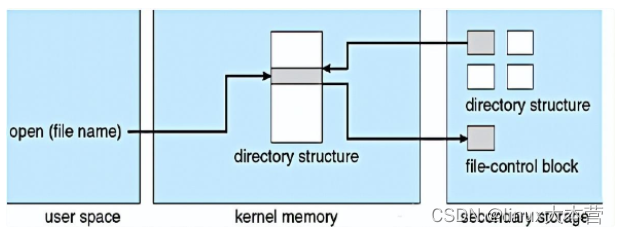
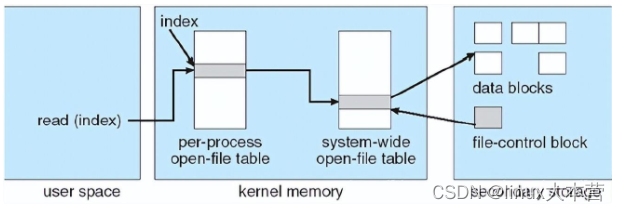
虚拟文件系统
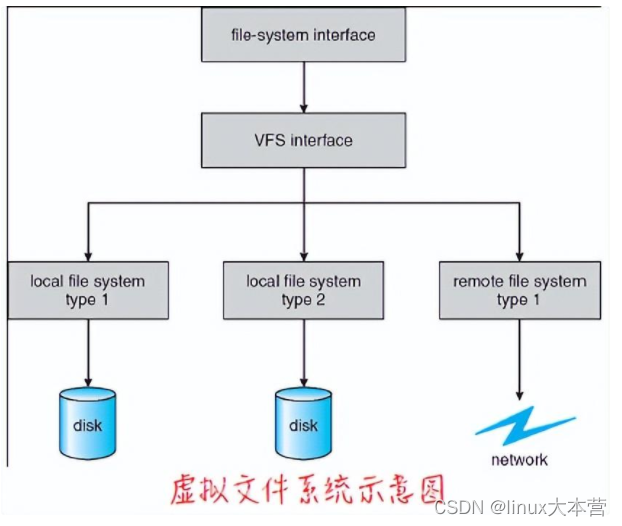
数据结构和程序用于隔离基本的操作系统调用的功能与实现细节。因此,文件系统的实现有三个主要层构成。
- 文件系统接口
- 虚拟文件系统 VFS,把文件操作与具体实现分开,虚拟文件系统提供了在唯一标识一个文件的机制。VFS基于vnode的文件表式结构,包含了一个数值表示符(文件描述符)来唯一表示网路上的一个文件
VFS能区分不同本地文件系统,能区分本地文件系统和远程文件系统
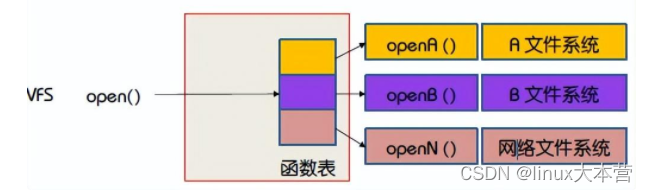
目录实现的方法
- 线性列表
- 哈希表
磁盘分配空间方式
-
连续分配
每个文件在磁盘上占有一组连续的块。 文件的连续分配可以用文件第一块的磁盘地址和连续块的数量(即长度)来定义
基于扩展的连续分配方案
- 开始地址
- 块数
- 指向下一个扩展块的指针
-
链接分配
每个文件时磁盘块的链表,磁盘块分布在磁盘的任何地方,文件有起始块和结束块的定义,每一块磁盘的末尾有指向下一块磁盘地址的指针
文件分配表:
每个卷的开始部分用于存储文件分配表(File Allocation Table),表中每个磁盘块都有一个FAT条目,并可通过块号索引。(未使用的块为0,使用的块包含下一个块儿号)
目录条目含有文件首块号码,通过这个块号索引的FAT条目包含文件下一块的号码,这个链会继续下去,直到最后一块,最后一块的表条目值为文件结束值。
-
索引分配
通过将所有指针放在一起,来做索引,文件用索引块来定义,每个文件都有索引块,索引块应尽可能小,也不能太小
-
链接方案:可以将多个文件索引块链接起来
-
多层次索引:用第一层索引块指向一组第二层的索引块,第二层索引块再指向文件块
-
组合方案:用于基于UNIX的文件系统,将索引块的前15个指针存储在文件的i-node中。其中,前12个指针指向直接块,剩下3个指针指向间接块
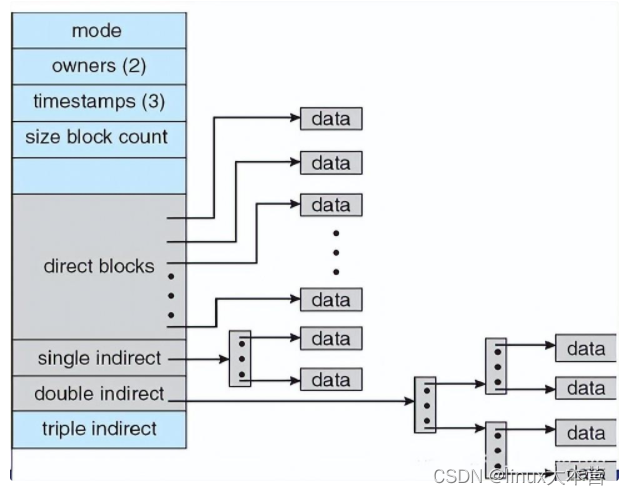
-
磁盘空闲空间管理
-
位向量
表现为位图,每一块用一位表示,1表示空闲,0表示已分配
-
链表
所有空闲块都用链表链接起来,并将指向第一个空闲快的指针保存在特殊位置,通知缓存在内存中,每个块有下一个块的指针
-
组
将n个空闲块的地址保存在第一个空闲块中,这些空闲块中的前n-1个位控,最后一块中包含另外n个空闲块的地址
-
计数
通常有多个连续块需要同时分配或释放,尤其是在使用连续分配时
- 记录第一块的地址和紧跟第一块的连续的空闲块的数量
- 空闲空间表的每个条目包括磁盘地址和数量
文件系统的性能和效率
磁盘空间的有效使用(效率),取决于
- 磁盘分配和目录管理算法
- 保留在文件目录条目中的数据类型
改善性能的方法:缓存
- 缓冲区缓存:一块独立内存,位于其中的块是马上需要使用的
- 页面缓存:将文件数据作为页而不是块来缓存。页面缓存使用虚拟内存技术,将文件数据作为页来缓存,比采用物理磁盘块来缓存更高效
- 板载高速缓存
系统调用read()和write()会通过缓冲区缓存,然而,内存映射调用需要使用两个缓存,即页面缓存和缓冲区缓存。内存映射先从文件系统中读入磁盘块,并放入缓冲区缓存,由于虚拟内存系统没有缓冲区缓存接口,缓冲缓存内的文件必须复制到页面缓存中
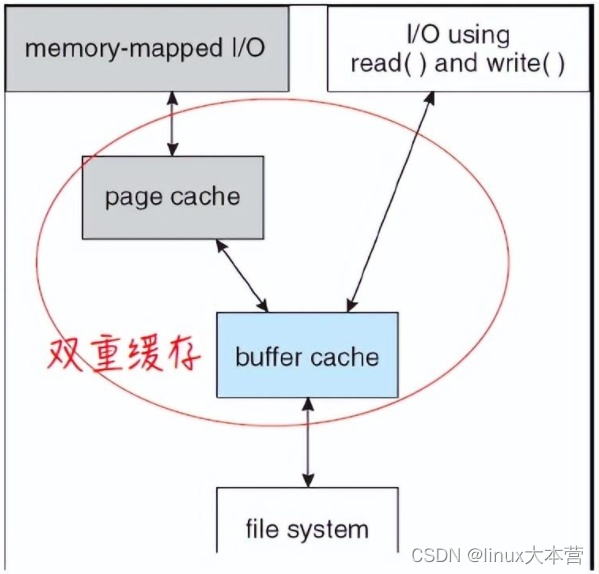
采用统一缓冲缓存:统一使用缓冲器缓存来缓存进程也和文件数据
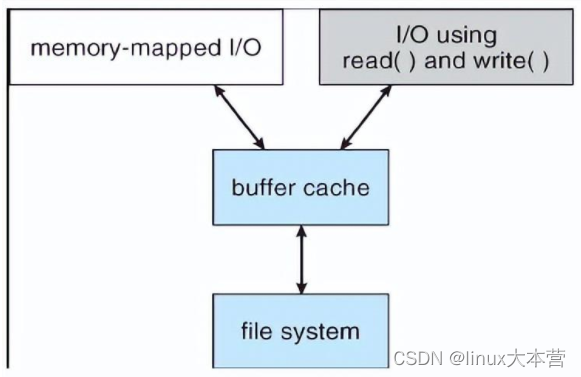
文件的读入或写出一般是按顺序进行。所以,不适合采用LRU算法(全面讲解LRU算法-CSDN博客),因为最近使用的页面最后才会用甚至根本不会再用
顺序访问可以通过马上释放和预先读取来加以优化:
- 马上释放:请求下一页时马上释放上一页
- 预先读取:请求页之后得到下一页也一起读取
文件系统得到恢复
目录信息一般事先保存在内存中以加快访问,有时会导致目录结构中的数据和磁盘块中的数据不一致。
解决:
- 一致性检查:比较目录结构中的数据和磁盘块中的数据,尝试着去修正不一致
- 备份&恢复:
- 备份(backup):利用系统程序来备份数据到其他的存储设备。软盘,磁带
- 恢复(recovery):通过从备份来恢复丢失的文件或磁盘
基于日志结构的文件系统:
- 文件创建涉及到目录结构修改,FCB分配,数据块分配等
- 所有元数据(meta data)的变化写入日志上,一旦这些修改写到日志,就认为已经提交了。
- 提交了的事务,并不一定马上完成操作
- 当整个提交的事务已经完成时,就从日志中删除事务条目
- 如果系统崩溃,日志文件可能还存在事务,它包含的任何事务虽然已经由操作系统提交了,但还没有完成到文件系统,必须重新执行。
持久数据的可靠性
RAID磁盘阵列
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,简称为「磁盘阵列」,其实就是用多个独立的磁盘组成在一起形成一个大的磁盘系统,从而实现比单块磁盘更好的存储性能和更高的可靠性。RAID实际上是实现了,使用一些不那么可靠的磁盘来合成一个又大又快又可靠的磁盘
使用多个磁盘来作为一块磁盘系统,其中可以有很多备份,在读取的时候,可以是从多个磁盘分别读取一块,然后组成想要读取的一整块。读取速度可以快好几倍,但是写入的速度是不变的。也可以对于磁盘以一定的顺序来组成虚拟磁盘,这样的读取顺序就可以多个磁盘循环读取,顺序读写都可以并行执行。
RAID是一个反向的虚拟化
- 进程:把一个CPU虚拟化为多个虚拟的CPU
- 虚拟内存:把一份内存通过MMU(Memory Management Unit 内存管理单元)虚拟为多个地址空间
- 文件:把一个存储设备虚拟化为多个磁盘
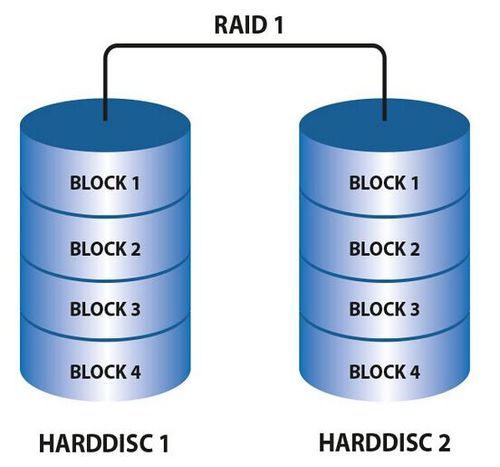
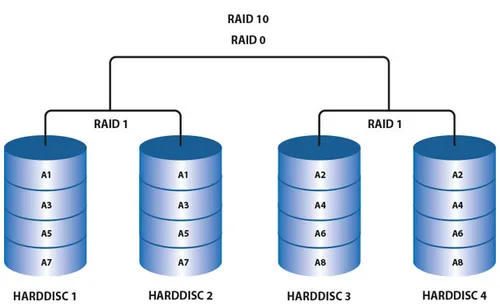
RAID4 专门留一块磁盘作为奇偶校验盘
例如:
,其中 作为一个RAID0 任意
专门留存D盘作为校验盘 (异或)做奇偶校验,如果V1修改,
任意一个磁盘数据损坏,都可以通过其他的磁盘信息来获得它的信息
但是随机读写变成了很困难的事情,每次读写都需要修改奇偶校验盘,最终的速率会受限于奇偶校验盘
RAID5 提供了一些升级,就是把奇偶校验位融入到存储块中,这样可以有效的加快磁盘随机读写的速度
系统崩溃
磁盘没有故障,操作系统内部可能出现crash,也可能断电
即便只是append一个字节都涉及到了多处磁盘的修改:FAT,目录文件和数据的修改
磁盘不提供多块读写 all or notion 的支持,甚至为了性能,没有顺序保证,bwrite可能被乱序,所以磁盘还是提供了bflush等待已经写入的数据落盘,就可以避免磁盘乱序
事实上,磁盘乱序就会导致任何一个子集的写入丢失都有可能出现,文件系统进入了不一致的状态,根本原因是存储设备无法提供多次写入的原子性
日志
两个视角:
- 存储实际的数据结构
- 文件系统的直观表示
- crash unsafe
- Append-only 记录所有历史操作
- 重做所有操作得到数据结构的当前状态
- 容易实现崩溃一致性
两者融合也就得到了日志
- 数据结构操作发生时,使用append-only 记录日志
- 日志落盘之后,更新数据结构,等待数据落盘之后删除日志
- 系统崩溃之后,检查日志中未完成的操作,重新执行一次 redo log
实现原子性的 append
- 定位到 journal 的末尾
- bwrite TXBegin 和所有数据结构操作
- bflush 等待数据落盘
- bwrite TXEnd 表示log落盘,之后就可以开始写入数据了
- bflush 等待数据落盘
- 将数据结构操作写入实际数据结构区域
- 数据落盘之后,删除日志
优化:
- 批处理
- 多次系统调用得到Tx合并成一个,减少log大小
- 定期 写回
- checksum
- 不使用TxBegin/TxEnd
- 直接标记Tx的长度和checksum
- Metadata journaling 元数据日志
- 数据占磁盘写入的绝大部分,只对 inode 和 bitmap 做优化可以提高性能
- 保证文件系统的目录结构是一致的,但是数据可能丢失
Andriod 操作系统
- linux + framework + JVM
- 实际上是在linux/java上做的二次开发
- 并不完全是,android定义了应用模型
- 支持java是一个非常高瞻远瞩的决定
- armv6 指令集
- 实际上是app的运行环境
四大组件
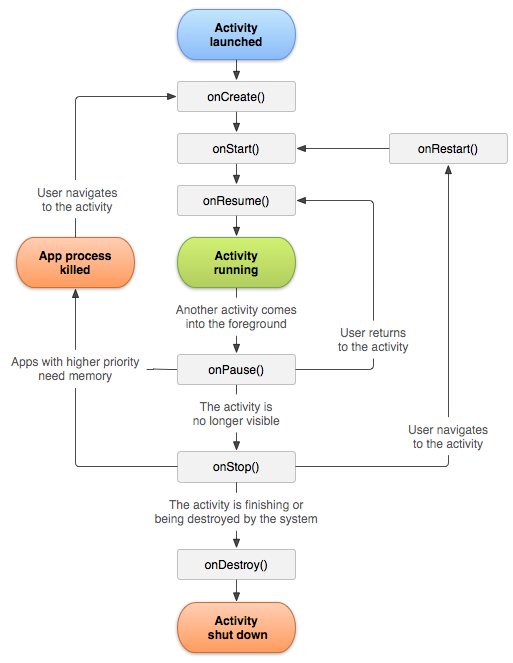
- activity
- 应用程序的UI界面
- 存在一个activity stack
- service
- 无界面的后台服务
- broadcast
- 接收系统消息,做出反应
- content provider
- 可以在应用间共享数据存储
PlatformAPI 之下:一个微内核
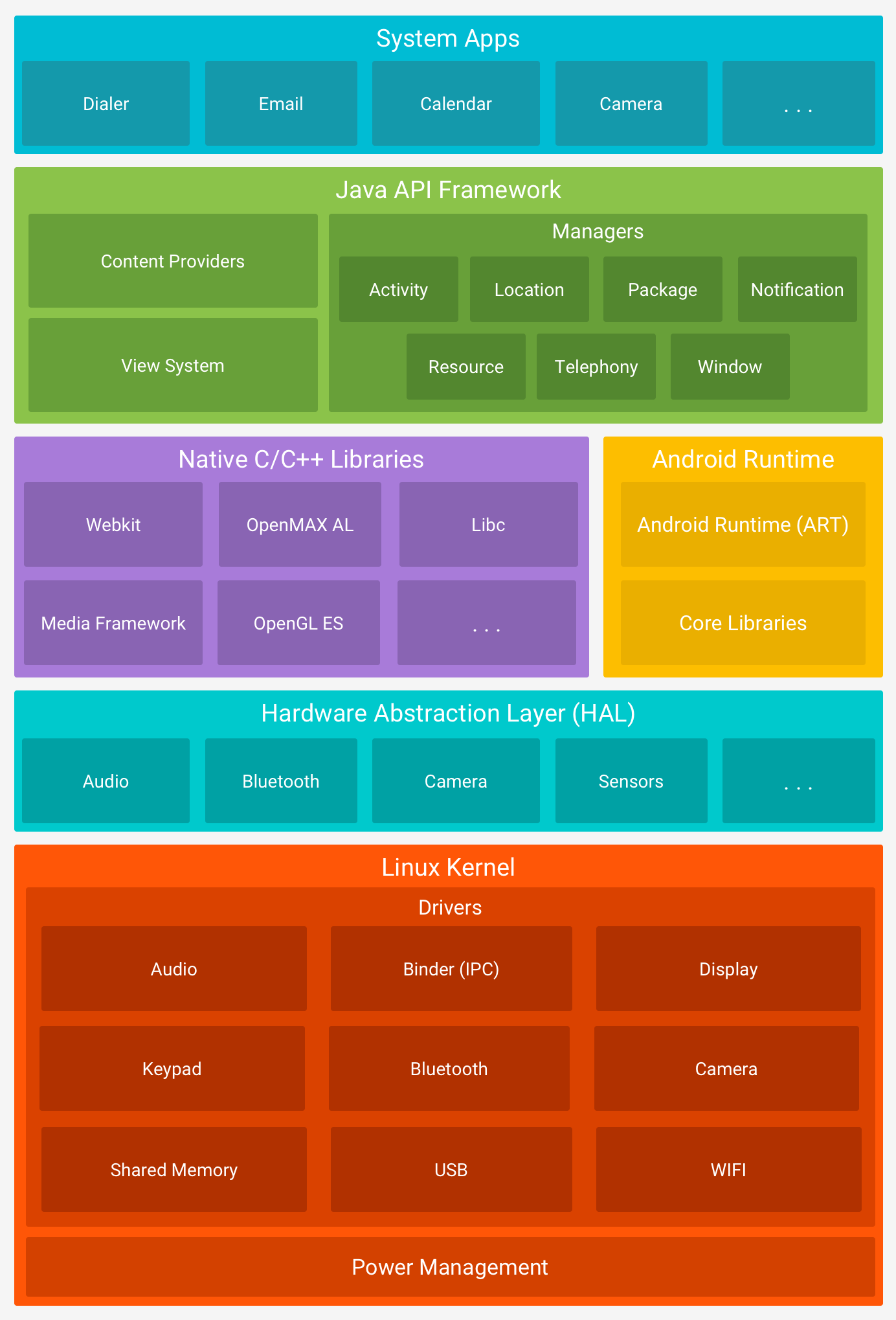
android内核的实现是在linux的基础上搭建出来的——一个微内核
- Remote Procedure Call (RPC)
- 注册机制
- 每个应用程序可以注册函数,然后整个操作系统可以调用该函数
- 基于内存共享实现
- 通过代码把参数序列化,保存到一个共享内存页面中,然后在其他应用程序调用的时候,在两个应用之间做一个映射
- 就像是在一个程序里调用函数,然后再另一个进程中执行,最后返回到原来的程序中
- 服务端线程池
手机上有多个service用于服务,但是会出现优先级反转,导致低优先级的程序占据着线程不释放,高优先级的任务也必须等待该任务结束,特别是安装软件的时候,向操作系统注册的时候会特别卡顿
杀死一个Android进程
- Android 每一个 app 都有一个独立的uid(进程号)
- 遍历进程表,杀死找到的对应的uid的进程,每5ms连续杀死40次,防止数据竞争
利用数据竞争保活
- 杀死孤儿进程从而不会立即收到 SIGKILL 信号
- 在被杀死之后立即唤醒另一个进程
- 进程托孤机制——强行终止都杀不掉
- 某一个进程fork一份进程,然后新的进程作为一个父进程创建一些子进程,然后释放掉父进程,就形成一些孤儿进程,孤儿进程之间会有死锁,一旦其中有一个进程被杀死了,另一个就会启动,重新fork一份上述的进程




