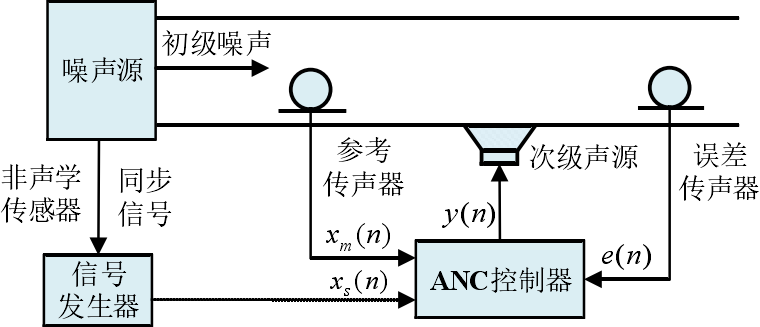
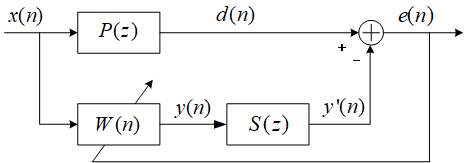
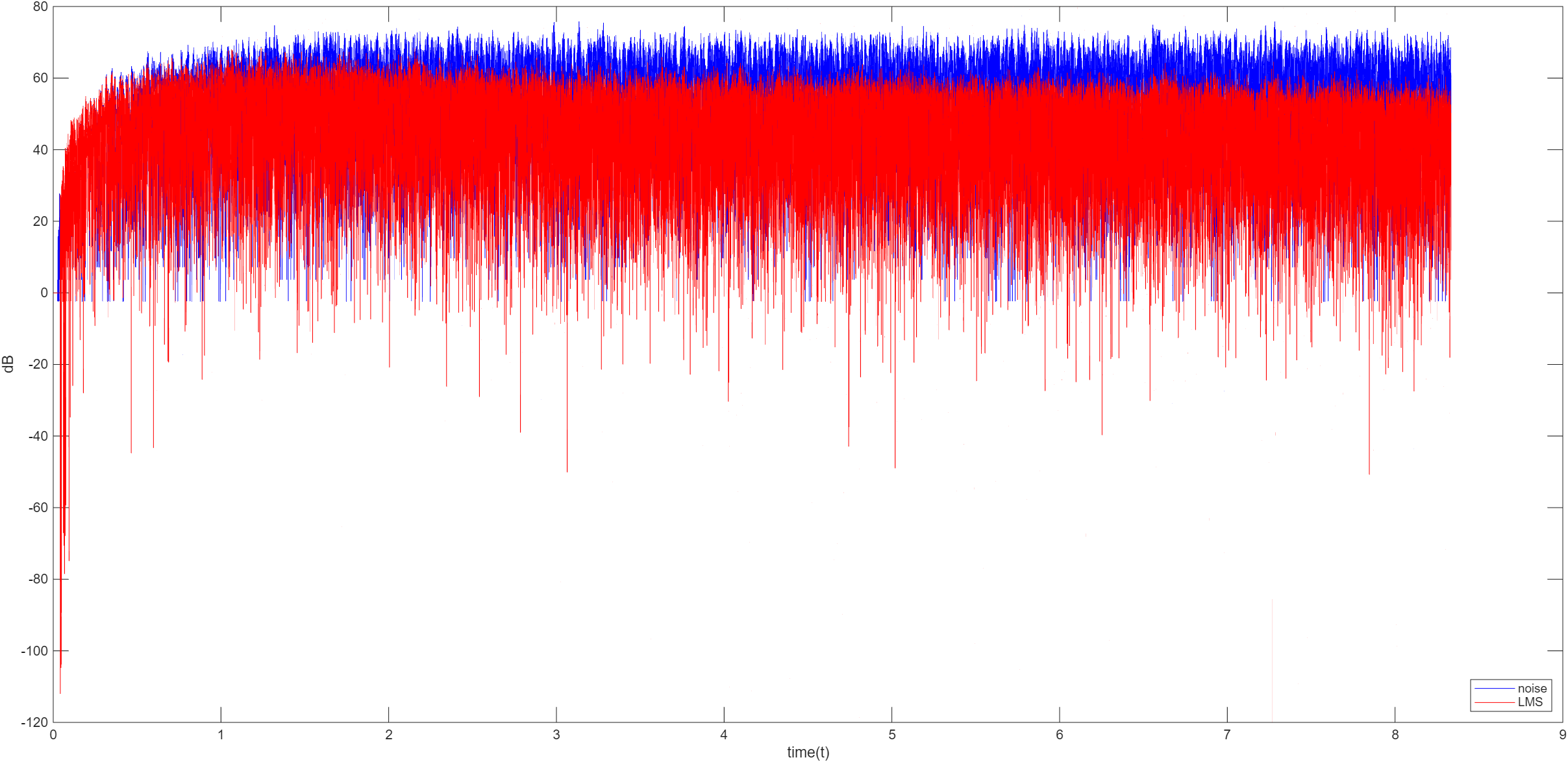
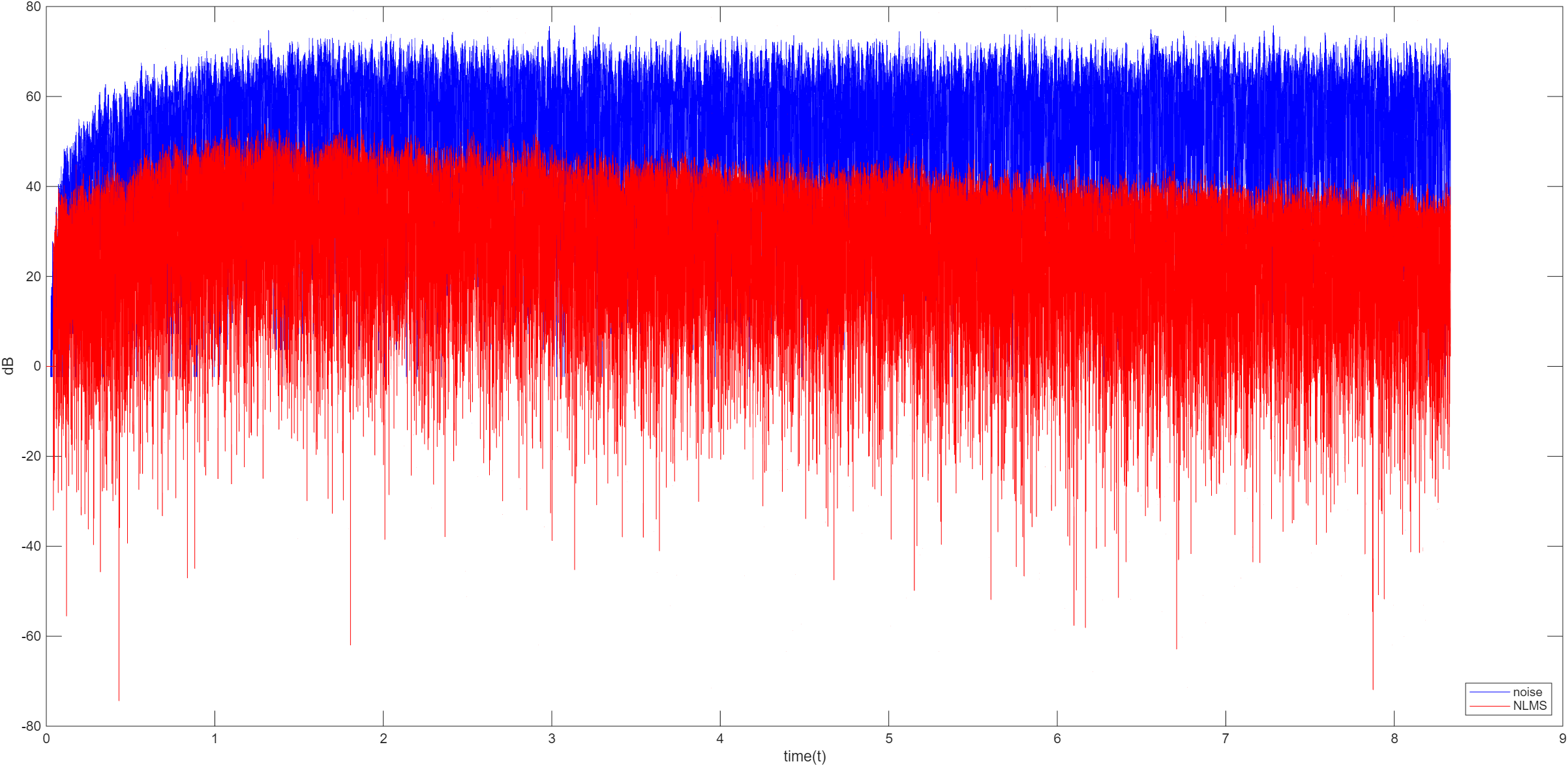
主动噪声控制,又称为有源噪声控制,是一种通过发出与外界噪声相位相反且振幅相同的声波来抵消噪音的技术。ANC 的原理是物理学中的声波相消理论。通过产生与原始噪声幅值相等、相位相反的次级声波(反噪声)来抵消不需要的噪声,是传统被动噪声控制的重要补充。
前言
声波相消理论
当两列声波同时在同一媒介中传播并且在某一处相遇时,任意点上的振动将是两者引起振动的叠加,该现象就是声波干涉。如果两列声波具有相同频率及固定相位差,当其传播到同一位置时,若出现同相振动则会产生相长干涉,若出现反相振动则会弧线相消干涉。
其中初级噪声是原始噪声信号,次级噪声是扬声器生成的噪声,用来抵消原始噪声。在系统正常工作的情况下,扬声器的输出信号与原始噪声信号在特定的空间内实现干涉,要想形成稳定的干涉时,两列波需要满足如下条件
它的数学表达式为
原始噪声 p 1 ( t ) = A sin ( ω t + ϕ 1 ) p_1(t)=A\sin(\omega t+\phi_1) p 1 ( t ) = A sin ( ω t + ϕ 1 )
反噪声 p 2 ( t ) = A sin ( ω t + ϕ 2 ) p_2(t)=A\sin(\omega t+\phi_2) p 2 ( t ) = A sin ( ω t + ϕ 2 ) ϕ 2 = ϕ 1 + 18 0 ∘ \phi_2=\phi_1+180^\circ ϕ 2 = ϕ 1 + 1 8 0 ∘
合成声音为 p ( t ) = p 1 ( t ) + p 2 ( t ) = 0 p(t)=p_1(t)+p_2(t)=0 p ( t ) = p 1 ( t ) + p 2 ( t ) = 0
数字滤波器
数字滤波器 | LuosBlog
数字傅里叶分析
傅里叶分析的本质是,任何满足狄利克雷条件的信号,都可以分解为一系列不同频率、不同幅度、不同相位的正弦或余弦信号的线性叠加
时域视角:信号随时间变化的波形,描述信号在什么时候是什么样
频域视角:信号由哪些频率成分组成,每个频率成分的强度和相位,描述信号由什么组成
一个方波可以分解为基波和无数奇次谐波的叠加,叠加的谐波越多,波形越接近方波。在进行傅里叶分析时,需要先将模拟信号转换为数字信号,再进行傅里叶分析
采样:以固定时间间隔对连续信号进行取值,得到离散时间信号。为了保证无失真地恢复原信号,采样频率必须大于信号最高频率地两倍,否则回发生混叠失真
量化:将连续幅值地采样值转换为有限精度地二进制数,这会引入量化噪声
截断:计算机只能处理有限长度的信号,因此需要将无限长的离散时间信号截断为有限长度的序列
傅里叶变换:傅里叶变换 | LuosBlog
相关和卷积
相关运算的本质为滑动匹配,即一个信号在另一个信号上滑动,每滑动一个位置,就计算两个信号重叠部分的点积。点积越大说明两个信号在该位置上越相似,点积为 0 说明两个信号正相关,点积为负数说明两个信号反相相似。另外还有圆周相关:即对两个周期性信号在一个周期内进行相关分析的运算,将信号尽心周期延拓,计算它们在一个周期内的相关性
互相关 x ⊗ h ( n ) = ∑ k = − ∞ ∞ x ( k ) h ( k + n ) x\otimes h(n)=\sum_{k=-\infty}^\infty x(k)h(k+n) x ⊗ h ( n ) = ∑ k = − ∞ ∞ x ( k ) h ( k + n )
自相关 x ⊗ x ( n ) = ∑ k = − ∞ ∞ x ( k ) x ( k + n ) x\otimes x(n)=\sum_{k=-\infty}^\infty x(k)x(k+n) x ⊗ x ( n ) = ∑ k = − ∞ ∞ x ( k ) x ( k + n )
卷积运算的本质就是让一个信号先前后翻转,然后在另一个信号上滑动,每滑动一个位置就计算重叠部分的卷积。另外循环卷积即将有限长的信号看作首尾相连的圆环,然后在圆环上进行加权滑动平均
卷积 x ∗ h ( n ) = ∑ k = − ∞ ∞ x ( k ) h ( n − k ) x*h(n)=\sum_{k=-\infty}^\infty x(k)h(n-k) x ∗ h ( n ) = ∑ k = − ∞ ∞ x ( k ) h ( n − k )
在频域与时域变换中,相关与卷积存在如下性质
时域卷积 ↔ \leftrightarrow ↔ F { x ∗ h } = F { x } F { h } F\{x*h\}=F\{x\}F\{h\} F { x ∗ h } = F { x } F { h }
时域互相关 ↔ \leftrightarrow ↔ F { x ⊗ h } = F { x } F { h } ⋆ F\{x\otimes h\}=F\{x\}F\{h\}^\star F { x ⊗ h } = F { x } F { h } ⋆
在使用中,当信号长度过大时,直接计算时域卷积或相关的复杂度比较高,可以利用频域性质,先做 FFT,相乘之后再做 IFFT,复杂度降低
另外循环卷积与线性卷积之间的关系如下
一般的,如果两个有限长序列的长度为 N 1 N_1 N 1 N 2 N_2 N 2 N 1 ≥ N 2 N_1\geq N_2 N 1 ≥ N 2 N 1 − N 2 + 1 N_1−N_2+1 N 1 − N 2 + 1
一般的,如果两个有限长序列的长度为 N 1 N_1 N 1 N 2 N_2 N 2 N 1 ≥ N 2 N_1\geq N_2 N 1 ≥ N 2 N 1 − N 2 + 1 N_1−N_2+1 N 1 − N 2 + 1
时域中的循环卷积对应于其离散傅里叶变换的乘积
时域中的循环相关对应于其离散傅里叶变换共轭谱的乘积
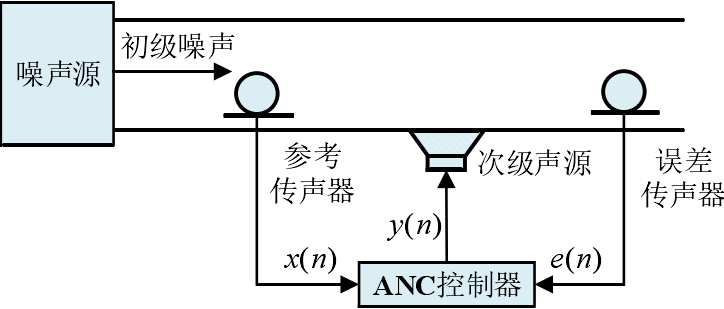
ANC 系统基本结构
控制结构分类如下
前馈控制:产生次级噪声之前就通过传感器测量初级噪声的频率以获取参考信号
反馈控制:不需要测得参考信号就产生次级噪声进行相消干涉
混合控制
前馈控制
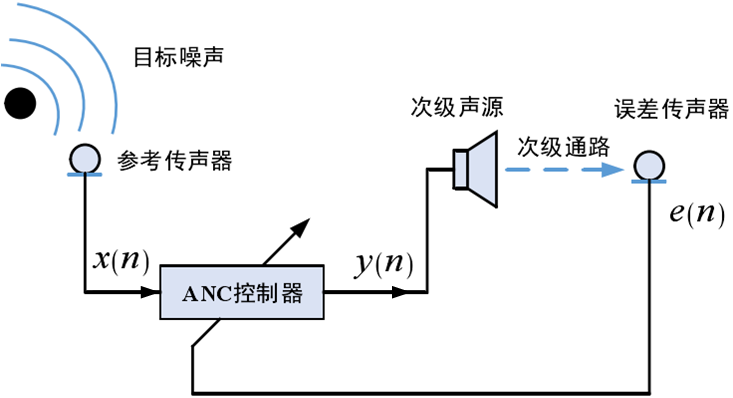
前馈 ANC 控制通过在目标噪声源处放置参考传声器或非声学传感器的方式来直接获取参考信号,误差传感器测得的残余噪声信号连同传感器获取的参考信号均作为控制器的输入,产生并调节次级声源信号,驱动次级扬声器发出次级噪声,与初级声源产生的噪声进行相消干涉,最终使得误差传感器处声压值最小。
前馈 ANC 控制有很强的鲁棒性,不仅适用于窄带噪声信号,也可用于处理宽带噪声信号。但是有些特定的场景可能不适合安装参考传声器。
参考传声器或参考麦克风采集噪声信号 x ( n ) x(n) x ( n )
ANC 控制器处理 x ( n ) x(n) x ( n ) y ( n ) y(n) y ( n )
次级声源播放 y ( n ) y(n) y ( n )
误差麦克风检测残余噪声 e ( n ) e(n) e ( n )
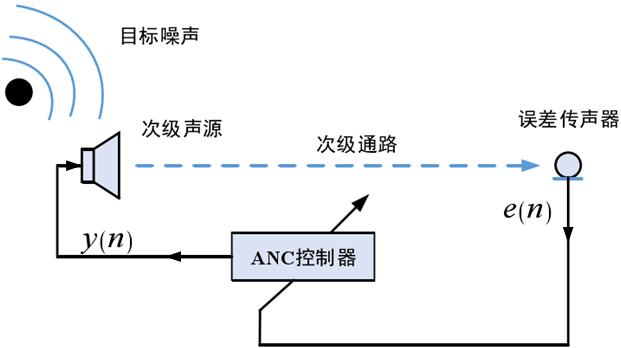
反馈控制
反馈型 ANC 系统中没有传感器来测得参考输入信号,仅通过误差传感器获取经相消干涉后的残余噪声并将其送入到反馈控制器,进而达到调节次级声源的目的,使其发出与初级噪声幅值相等相位相反的次级噪声。
反馈 ANC 系统的结构简单,不存在单反馈问题,因具有一定的主动阻尼而可以有效抑制系统的暂态信号,但是易受外界干扰而导致控制器发散,故系统稳定性不佳,此外,受限于参考信号的估计精度与硬件系统的时延,反馈 ANC 系统能实现的降噪频段相对较窄且降噪时易出现中高频段噪声不降反增的“水床效应”,对宽带噪声的处理能力较差。
误差麦克风同时采集原始噪声和系统输出的反相声波
控制器根据混合信号计算出反相输出
次级声源播放反相声波,形成负反馈回路
混合式 ANC
结合前馈与反馈 ANC 系统的有点,同时使用参考麦克风和误差麦克风。前馈 ANC 提供主要降噪效果,反馈 ANC 修正系统误差和环境变化,提升鲁棒性。
宽带与窄带 ANC 系统
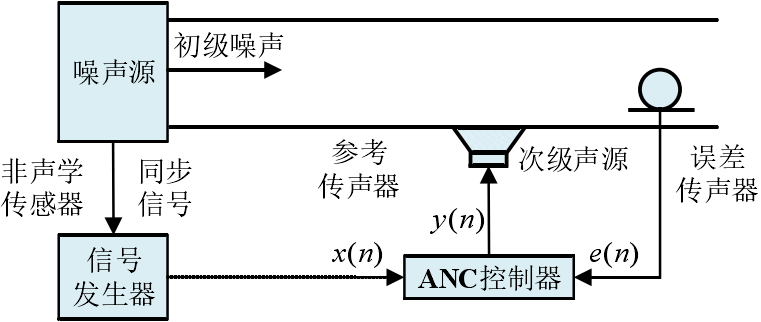
宽带 ANC 系统 通常采用参考传声器来构造参考噪声信号,进而实现消除较宽频段内的有效噪声,基本结构类似于前馈 ANC 系统。当参考传声器距离次级声源较近时,声反馈现象较为严重,因此在其中引入声反馈消除技术是十分必要
针对由发动机、压缩机、风扇等旋转机械部件运动而产生的周期性窄频带噪声,通过转速传感器、振动加速度传声器等非声学传感器的使用可辅助构造出较为精准的窄带参考信号,这类以非声学传感器来获取参考信号的 ANC 系统一般称之为窄带 ANC 系统 。由于非声学传感器的使用,窄带 ANC 系统不存在声反馈问题,同时也避免了参考传声器所存在的老化和非线性问题,此外,窄带阶次噪声通常具有较强的周期特性,由转速传感器等所构造的参考信号可有效满足系统对目标噪声的连续追踪需求,因此,窄带 ANC 系统通常具有较优良的窄带阶次分量降噪特性。
在实际生活中,大多数目标噪声均具有宽窄带混合的特性,采用由宽带 ANC 子系统和窄带 ANC 子系统所构成的宽窄带混合 ANC 系统往往能实现更为理想的控制效果。但是整体的结构会比较复杂,同时采用了声学传声器与非声学传感器来构造参考噪声信号,次级声源发出的抵消信号也是由宽、窄带 ANC 部分的输出信号求和得出
上述 ANC 类型,宽带与窄带的区别只是在于针对的噪声频率范围,宽带处理宽频率范围内的噪声,需要比较复杂的自适应算法,而窄带 ANC 针对特定频率的噪声,算法较为简单,计算量小。
LMS 算法
LMS 算法是自适应滤波领域中基础且广泛应用的算法,核心是通过最陡下降法随机近似,实时调整滤波器权重,使输出信号域期望信号的均方误差最小。LMS 的计算量小,实现简单,实时性强。
LMS 基于线性自适应滤波器,核心是用输入信号的线性组合逼近期望信号,LMS 中有如下定义
输入向量 X ( n ) = [ x ( n ) , x ( n − 1 ) , ⋯ , x ( n − L + 1 ) ] X(n)=[x(n),x(n-1),\cdots,x(n-L+1)] X ( n ) = [ x ( n ) , x ( n − 1 ) , ⋯ , x ( n − L + 1 ) ] L L L L L L
权重向量 w ( n ) = [ w 0 ( n ) , w 1 ( n ) , ⋯ , w L − 1 ( n ) ] w(n)=[w_0(n),w_1(n),\cdots,w_{L-1}(n)] w ( n ) = [ w 0 ( n ) , w 1 ( n ) , ⋯ , w L − 1 ( n ) ]
滤波器输出 y ( n ) = w T ( n ) X ( n ) = ∑ i L − 1 w i ( n ) x ( n − i ) y(n)=w^T(n)X(n)=\sum_i^{L-1}w_i(n)x(n-i) y ( n ) = w T ( n ) X ( n ) = ∑ i L − 1 w i ( n ) x ( n − i )
期望信号 d ( n ) d(n) d ( n )
误差信号 e ( n ) = d ( n ) + y ( n ) e(n)=d(n)+y(n) e ( n ) = d ( n ) + y ( n )
LMS 的优化目标是最小化均方误差,即
J ( n ) = E ( e 2 ( n ) ) = E [ ( d ( n ) + w T ( n ) X ( n ) ) 2 ] J(n)=E(e^2(n))=E\Big[(d(n)+w^T(n)X(n))^2\Big]
J ( n ) = E ( e 2 ( n ) ) = E [ ( d ( n ) + w T ( n ) X ( n ) ) 2 ]
利用最陡下降法通过沿误差梯度的反方向更新权值,使 J ( n ) J(n) J ( n )
w ( n + 1 ) = w ( n ) − μ ∇ J ( n ) w(n+1)=w(n)-\mu\nabla J(n)
w ( n + 1 ) = w ( n ) − μ ∇ J ( n )
其中
μ \mu μ μ \mu μ μ \mu μ 0 < μ < 2 λ max 0<\mu<\frac{2}{\lambda_{\max}} 0 < μ < λ m a x 2 λ max \lambda_{\max} λ m a x R = E [ x ( n ) x T ( n ) ] R=E[x(n)x^T(n)] R = E [ x ( n ) x T ( n ) ] 0 < μ < 1 t r ( R ) 0<\mu<\frac{1}{tr(R)} 0 < μ < t r ( R ) 1 ∇ J ( n ) \nabla J(n) ∇ J ( n ) ∇ J ( n ) = − 2 E [ e ( n ) x ( n ) ] \nabla J(n)=-2E[e(n)x(n)] ∇ J ( n ) = − 2 E [ e ( n ) x ( n ) ]
由于最陡下降法需要统计期望,无法实时计算,所以在 LMS 用瞬时梯度代替期望梯度,实现实时权值更新
∇ J ( n ) ^ = 2 e ( n ) x ( n ) \hat{\nabla J(n)}=2e(n)x(n)
∇ J ( n ) ^ = 2 e ( n ) x ( n )
带入最陡下降公式,得到 LMS 权值更新的核心公式
w ( n + 1 ) = w ( n ) − 2 μ e ( n ) x ( n ) w(n+1)=w(n)-2\mu e(n)x(n)
w ( n + 1 ) = w ( n ) − 2 μ e ( n ) x ( n )
通常将 2 μ 2\mu 2 μ μ ′ \mu^\prime μ ′ w ( n + 1 ) = w ( n ) − μ ′ e ( n ) x ( n ) w(n+1)=w(n)-\mu^\prime e(n)x(n) w ( n + 1 ) = w ( n ) − μ ′ e ( n ) x ( n )
LMS 的算法步骤如下
初始化:设定滤波器阶数 L L L μ \mu μ w ( 0 ) = 0 w(0)=0 w ( 0 ) = 0 X ( t ) X(t) X ( t )
在每个时刻 t t t
更新输入缓存:利用滑动窗口,将新样本加入,丢弃最旧的样本 X ( t ) = [ x ( t ) , x ( t − 1 ) , ⋯ , x ( t − L + 1 ) ] X(t)=[x(t),x(t-1),\cdots,x(t-L+1)] X ( t ) = [ x ( t ) , x ( t − 1 ) , ⋯ , x ( t − L + 1 ) ]
计算滤波器输出 y ( t ) = w T ( t ) X ( t ) y(t)=w^T(t)X(t) y ( t ) = w T ( t ) X ( t )
得到误差信号 e ( t ) = d ( t ) + y ( t ) e(t)=d(t)+y(t) e ( t ) = d ( t ) + y ( t )
更新权值向量 w ( t + 1 ) = w ( t ) − μ e ( t ) X ( t ) w(t+1)=w(t)-\mu e(t)X(t) w ( t + 1 ) = w ( t ) − μ e ( t ) X ( t )
迭代直到预设次数或者信号处理结束
NLMS 算法
NLMS 算法是 LMS 算法的归一化版本,在 LMS 算法中,步长是一个稳定的常数,在 NLMS 算法中,步长是一个随时间变化的量,定义为
μ ( n ) = α ∥ X ( n ) ∥ 2 + c \mu(n)=\frac{\alpha}{\Vert X(n)\Vert^2+c}
μ ( n ) = ∥ X ( n ) ∥ 2 + c α
其中定义 0 < α < 2 0<\alpha<2 0 < α < 2 c c c
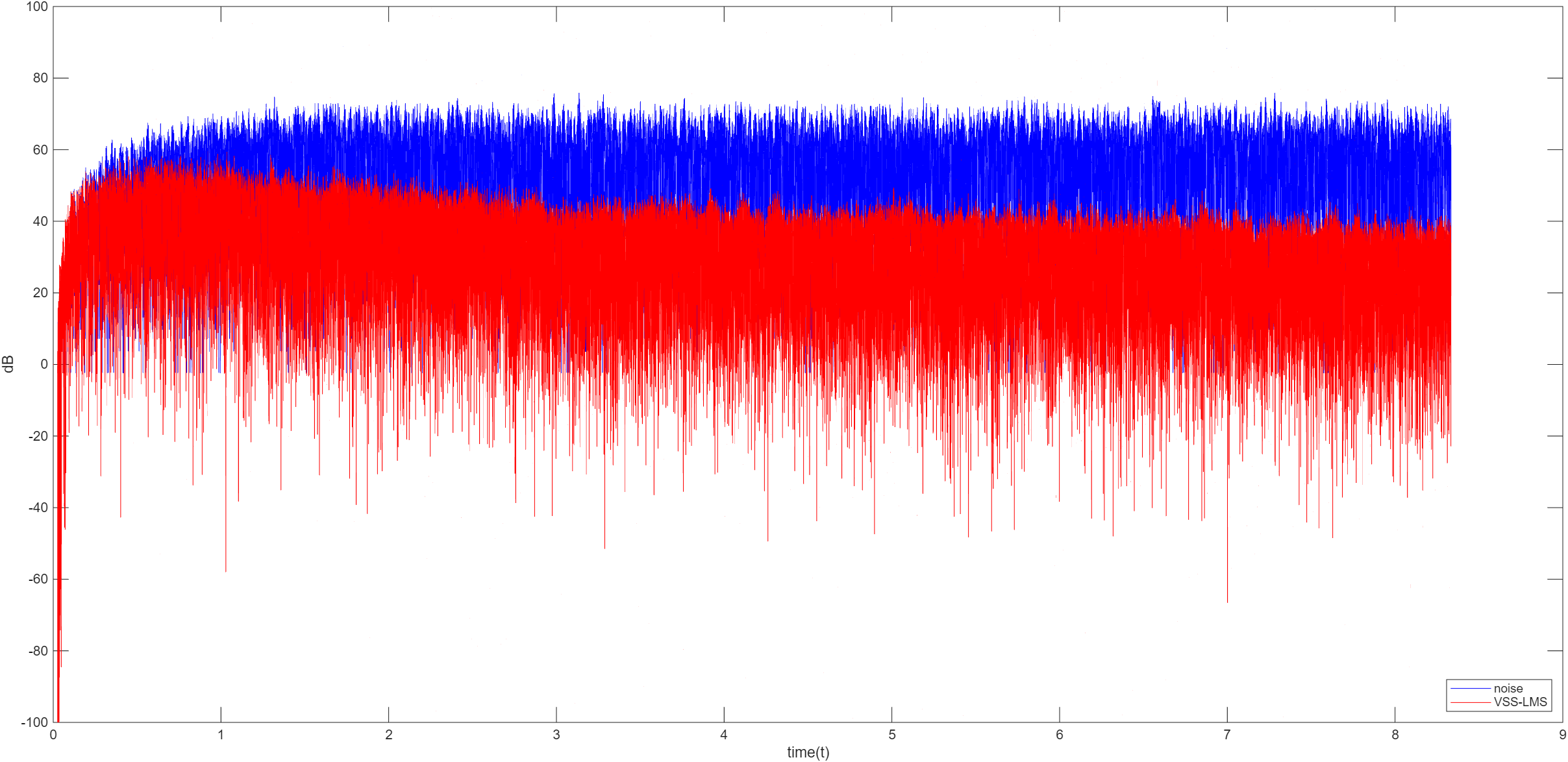
VSS-LMS 算法
VSS-LMS 算法即变步长最小均方算法,是解决了传统 LMS 算法中收敛速度和稳态误差之间难以调和的根本矛盾。VSS-LMS 算法使用一个能动态计算的时变参数 μ ( n ) \mu(n) μ ( n ) μ \mu μ μ ( n ) \mu(n) μ ( n )
Kwong-Johnston VSS-LMS
更新公式为 μ ( n ) = α μ ( n − 1 ) + γ e 2 ( n ) \mu(n)=\alpha \mu(n-1)+\gamma e^2(n) μ ( n ) = α μ ( n − 1 ) + γ e 2 ( n )
其中 0 < α < 1 0<\alpha<1 0 < α < 1 γ > 0 \gamma>0 γ > 0
通常取值 α ∈ [ 0.95 , 0.99 ] \alpha\in[0.95,0.99] α ∈ [ 0 . 9 5 , 0 . 9 9 ] γ ∈ [ 1 e − 6 , 1 e − 3 ] \gamma\in[1e^{-6},1e^{-3}] γ ∈ [ 1 e − 6 , 1 e − 3 ]
Aboulnasr-Mayyas VSS-LMS
更新公式为 p ( n ) = β p ( n − 1 ) + ( 1 − β ) e ( n ) e ( n − 1 ) p(n)=\beta p(n-1)+(1-\beta)e(n)e(n-1) p ( n ) = β p ( n − 1 ) + ( 1 − β ) e ( n ) e ( n − 1 ) μ ( n ) = α μ ( n − 1 ) + γ p 2 ( n − 1 ) \mu(n)=\alpha \mu(n-1)+\gamma p^2(n-1) μ ( n ) = α μ ( n − 1 ) + γ p 2 ( n − 1 )
通常取值 α ∈ [ 0.95 , 0.99 ] \alpha\in[0.95,0.99] α ∈ [ 0 . 9 5 , 0 . 9 9 ] γ ∈ [ 1 e − 6 , 1 e − 3 ] \gamma\in[1e^{-6},1e^{-3}] γ ∈ [ 1 e − 6 , 1 e − 3 ] 0 < β < 1 0<\beta<1 0 < β < 1 0.9 ∼ 0.95 0.9\sim0.95 0 . 9 ∼ 0 . 9 5
Sigmoid 型 VSS-LMS
更新公式为 μ ( n ) = μ m i n + μ m a x − μ m i n 1 + exp ( − β ( ∣ e ( n ) ∣ − δ ) ) \mu(n)=\mu_{min}+\frac{\mu_{max}-\mu_{min}}{1+\exp(-\beta(\vert e(n)\vert-\delta))} μ ( n ) = μ m i n + 1 + e x p ( − β ( ∣ e ( n ) ∣ − δ ) ) μ m a x − μ m i n
其中 β \beta β δ \delta δ ∣ e ( n ) ∣ > δ \vert e(n)\vert>\delta ∣ e ( n ) ∣ > δ μ m a x \mu_{max} μ m a x μ m i n \mu_{min} μ m i n
通常取值 β ∈ [ 1 , 20 ] \beta\in[1,20] β ∈ [ 1 , 2 0 ] δ ∈ [ 0.1 σ e , σ e ] \delta\in[0.1\sigma_e,\sigma_e] δ ∈ [ 0 . 1 σ e , σ e ] σ e \sigma_e σ e
基于误差-输入互相关的 VSS-LMS
更新公式为 μ ( n ) = μ m i n + ( μ m a x − μ m i n ) ( 1 − exp ( − β ∣ e ( n ) x ( n ) ∣ ) ) \mu(n)=\mu_{min}+(\mu_{max}-\mu_{min})(1-\exp(-\beta\vert e(n)x(n)\vert)) μ ( n ) = μ m i n + ( μ m a x − μ m i n ) ( 1 − exp ( − β ∣ e ( n ) x ( n ) ∣ ) )
其中控制系数通常取值 β ∈ [ 1 e − 3 , 1 e − 1 ] \beta\in[1e^{-3},1e^{-1}] β ∈ [ 1 e − 3 , 1 e − 1 ]
误差绝对值 VSS-LMS
步长更新公式为 μ ( n + 1 ) = α μ ( n ) + γ ∣ e ( n ) ∣ \mu(n+1)=\alpha\mu(n)+\gamma \vert e(n)\vert μ ( n + 1 ) = α μ ( n ) + γ ∣ e ( n ) ∣
通常取值 α ∈ [ 0.95 , 0.99 ] \alpha\in[0.95,0.99] α ∈ [ 0 . 9 5 , 0 . 9 9 ] γ ∈ [ 1 e − 6 , 1 e − 3 ] \gamma\in[1e^{-6},1e^{-3}] γ ∈ [ 1 e − 6 , 1 e − 3 ]
峰度控制 VSS-LMS
步长更新公式 μ ( n ) = μ m a x ( 1 − exp ( − α K u r t ( e ( n ) ) ) ) \mu(n)=\mu_{max}\Big(1-\exp\big(-\alpha\mathrm{Kurt}(e(n))\big)\Big) μ ( n ) = μ m a x ( 1 − exp ( − α K u r t ( e ( n ) ) ) )
其中 K u r t ( X ) = E [ ( X − μ σ ) 4 ] \mathrm{Kurt}(X)=E\Big[(\frac{X-\mu}{\sigma})^4\Big] K u r t ( X ) = E [ ( σ X − μ ) 4 ]
其中峰度控制系数 α ∈ [ 0.1 , 1.0 ] \alpha\in[0.1,1.0] α ∈ [ 0 . 1 , 1 . 0 ]
归一化 VSS-LMS
主要在于权重更新公式 w ( n + 1 ) = w ( n ) + μ ( n ) e ( n ) ∥ x ( n ) ∥ ϵ + ∥ x ∥ 2 w(n+1)=w(n)+\frac{\mu(n)e(n)\Vert x(n)\Vert}{\epsilon+\Vert x\Vert_2} w ( n + 1 ) = w ( n ) + ϵ + ∥ x ∥ 2 μ ( n ) e ( n ) ∥ x ( n ) ∥ ϵ \epsilon ϵ
更新步长的公式可以采用上述的方法来更新步长
无论采用哪种更新规律,在实际使用中都会加入饱和限制,即
μ ( n ) = min ( μ m a x , max ( μ m i n , μ ( n ) ) ) \mu(n)=\min(\mu_{max},\max(\mu_{min},\mu(n)))
μ ( n ) = min ( μ m a x , max ( μ m i n , μ ( n ) ) )
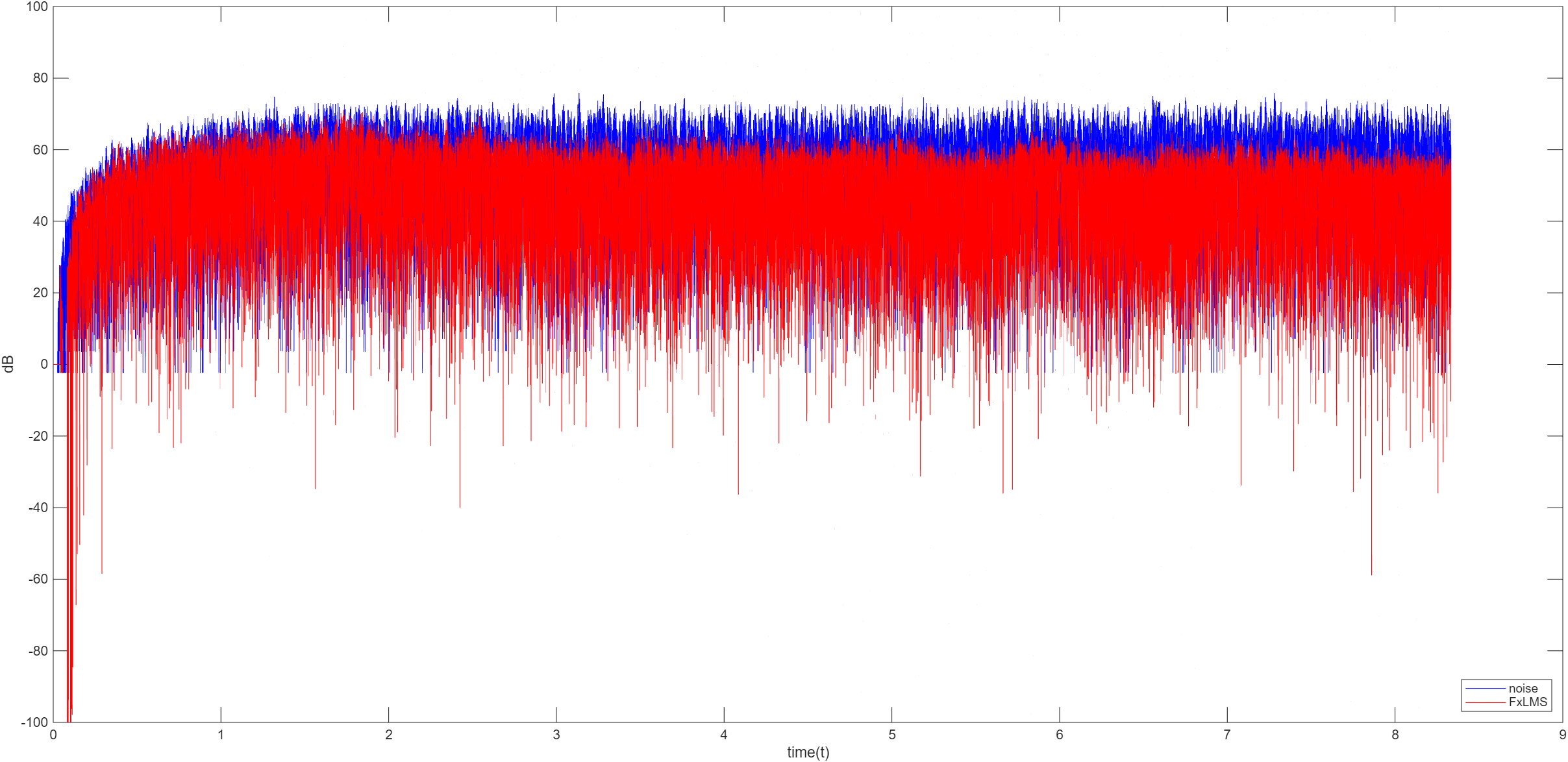
FxLMS
FxLMS 是 LMS 算法针对 ANC 系统中次级通道延迟与幅度衰减的专用改进版本,解决了基础的 LMS 因忽略从扬声器到误差麦克风声的传播路径导致的收敛慢、降噪效果差甚至是发散的问题,是工业上的标准算法。FxLMS 的核心逻辑就是先给参考信号预滤波,再用滤波后的信号更新权值,让自适应滤波器的输出能精准抵消经过次级通道传播后的噪声
基础 LMS 的误差信号为 e ( n ) = d ( n ) + y ( n ) e(n)=d(n)+y(n) e ( n ) = d ( n ) + y ( n ) e ( n ) = d ( n ) + s T ( n ) Y ( n ) e(n)=d(n)+s^T(n)Y(n) e ( n ) = d ( n ) + s T ( n ) Y ( n ) Y ( n ) = [ y ( n ) , y ( n − 1 ) , ⋯ ] Y(n)=[y(n),y(n-1),\cdots] Y ( n ) = [ y ( n ) , y ( n − 1 ) , ⋯ ] s ( n ) s(n) s ( n ) s ( n ) s(n) s ( n ) s ^ ( n ) \hat{s}(n) s ^ ( n ) d ( n ) d(n) d ( n ) s ( n ) s(n) s ( n )
参考麦克风信号 x ( n ) x(n) x ( n ) X ( n ) = [ x ( n ) , x ( n − 1 ) , ⋯ , x ( n − L + 1 ) ] X(n)=[x(n),x(n-1),\cdots,x(n-L+1)] X ( n ) = [ x ( n ) , x ( n − 1 ) , ⋯ , x ( n − L + 1 ) ] L L L
扬声器输出信号 y ( n ) = w T ( n ) X ( n ) y(n)=w^T(n)X(n) y ( n ) = w T ( n ) X ( n ) Y ( n ) = [ y ( n ) , y ( n − 1 ) , ⋯ , y ( n − L − 1 ) ] Y(n)=[y(n),y(n-1),\cdots,y(n-L-1)] Y ( n ) = [ y ( n ) , y ( n − 1 ) , ⋯ , y ( n − L − 1 ) ]
误差麦克风接收误差为 e ( n ) = s T ( n ) D ( n ) + s T ( n ) Y ( n ) e(n)=s^T(n)D(n)+s^T(n)Y(n) e ( n ) = s T ( n ) D ( n ) + s T ( n ) Y ( n ) D ( n ) D(n) D ( n )
利用当前次级路径模型生成滤波参考信号 x ′ ( n ) = s ^ T ( n ) X ( n ) x^\prime(n)=\hat{s}^T(n)X(n) x ′ ( n ) = s ^ T ( n ) X ( n ) X ′ ( n ) = [ x ′ ( n ) , x ′ ( n − 1 ) , ⋯ , x ′ ( n − L − 1 ) ] X^\prime(n)=[x^\prime(n),x^\prime(n-1),\cdots,x^\prime(n-L-1)] X ′ ( n ) = [ x ′ ( n ) , x ′ ( n − 1 ) , ⋯ , x ′ ( n − L − 1 ) ]
更新权重 w ( n + 1 ) = w ( n ) − μ e ( n ) X ′ ( n ) w(n+1)=w(n)-\mu e(n)X^\prime(n) w ( n + 1 ) = w ( n ) − μ e ( n ) X ′ ( n )
为了保证算法稳态收敛,应道限制 0 < μ < 2 λ max 0<\mu<\frac{2}{\lambda_{\max}} 0 < μ < λ m a x 2 λ max \lambda_{\max} λ m a x R = E [ x ′ ( n ) ( x ′ ) T ( n ) ] R=E[x^\prime(n)(x^{\prime})^T(n)] R = E [ x ′ ( n ) ( x ′ ) T ( n ) ] 0 < μ < 1 t r ( R ) 0<\mu<\frac{1}{tr(R)} 0 < μ < t r ( R ) 1
另外 FxLMS 的性能高度依赖次级通道估计 s ^ ( n ) \hat{s}(n) s ^ ( n ) s ^ ( n ) \hat{s}(n) s ^ ( n ) M M M s ^ ( n ) \hat{s}(n) s ^ ( n )
离线辨识:系统启动前,用白噪声激励扬声器,采集误差麦克风信号,通过系统辨识得到 s ^ ( n ) \hat{s}(n) s ^ ( n )
在线辨识:实时更新 s ^ ( n ) \hat{s}(n) s ^ ( n )
在工程中使用短长度 FIR 滤波器近似 s ^ ( n ) \hat{s}(n) s ^ ( n )
次级通道估计在线辨识
离线辨识有个致命缺陷,即环境变化时,会导致真实的 s ( n ) s(n) s ( n ) s ^ ( n ) \hat{s}(n) s ^ ( n ) s ^ ( n ) \hat{s}(n) s ^ ( n ) s ^ ( n ) \hat{s}(n) s ^ ( n )
无辅助噪声的在线辨识:由于部分场景不允许注入辅助噪声,可以利用主滤波器的输出 y ( n ) y(n) y ( n )
扬声器驱动信号为 u ( n ) = y ( n ) = w T ( n ) X ( n ) u(n)=y(n)=w^T(n)X(n) u ( n ) = y ( n ) = w T ( n ) X ( n )
误差麦克风信号为 e ( n ) = d ( n ) + s T Y ( n ) e(n)=d(n)+s^TY(n) e ( n ) = d ( n ) + s T Y ( n ) Y ( n ) = [ y ( n ) , y ( n − 1 ) , ⋯ , y ( n − L + 1 ) ] Y(n)=[y(n),y(n-1),\cdots,y(n-L+1)] Y ( n ) = [ y ( n ) , y ( n − 1 ) , ⋯ , y ( n − L + 1 ) ]
定义辨识误差 f ( n ) = e ( n ) − s ^ T Y ( n ) f(n)=e(n)-\hat{s}^TY(n) f ( n ) = e ( n ) − s ^ T Y ( n ) s ^ → s \hat{s}\rightarrow s s ^ → s f ( n ) → d ( n ) f(n)\rightarrow d(n) f ( n ) → d ( n )
构造辅助变量向量 Z ( n ) = [ y ( n − Δ ) , y ( n − Δ − 1 ) , ⋯ , y ( n − Δ − L + 1 ) ] Z(n)=[y(n-\Delta),y(n-\Delta-1),\cdots,y(n-\Delta-L+1)] Z ( n ) = [ y ( n − Δ ) , y ( n − Δ − 1 ) , ⋯ , y ( n − Δ − L + 1 ) ]
次级路径模型更新 s ^ ( n + 1 ) = s ^ ( n ) + μ s f ( n ) Z ( n ) \hat{s}(n+1)=\hat{s}(n)+\mu_s f(n)Z(n) s ^ ( n + 1 ) = s ^ ( n ) + μ s f ( n ) Z ( n )
利用当前次级路径模型生成滤波参考信号 x ′ ( n ) = s ^ T ( n ) X ( n ) x^\prime(n)=\hat{s}^T(n)X(n) x ′ ( n ) = s ^ T ( n ) X ( n ) X ′ ( n ) = [ x ′ ( n ) , x ′ ( n − 1 ) , ⋯ , x ′ ( n − L − 1 ) ] X^\prime(n)=[x^\prime(n),x^\prime(n-1),\cdots,x^\prime(n-L-1)] X ′ ( n ) = [ x ′ ( n ) , x ′ ( n − 1 ) , ⋯ , x ′ ( n − L − 1 ) ]
控制滤波器更新 w ( n + 1 ) = w ( n ) − μ w e ( n ) X ′ ( n ) w(n+1)=w(n)-\mu_we(n)X^\prime(n) w ( n + 1 ) = w ( n ) − μ w e ( n ) X ′ ( n )
有辅助噪声的在线辨识:扬声器的输出为主滤波器的输出 y ( n ) = w T ( n ) X ( n ) y(n)=w^T(n)X(n) y ( n ) = w T ( n ) X ( n ) v ( n ) v(n) v ( n )
误差麦克风信号为 e ( n ) = d ( n ) + s T Y ( n ) + s T V ( n ) e(n)=d(n)+s^TY(n)+s^TV(n) e ( n ) = d ( n ) + s T Y ( n ) + s T V ( n ) Y ( n ) = [ y ( n ) , y ( n − 1 ) , ⋯ , y ( n − L + 1 ) ] , V ( n ) = [ v ( n ) , v ( n − 1 ) , ⋯ , v ( n − L + 1 ) ] Y(n)=[y(n),y(n-1),\cdots,y(n-L+1)],V(n)=[v(n),v(n-1),\cdots,v(n-L+1)] Y ( n ) = [ y ( n ) , y ( n − 1 ) , ⋯ , y ( n − L + 1 ) ] , V ( n ) = [ v ( n ) , v ( n − 1 ) , ⋯ , v ( n − L + 1 ) ]
定义辨识误差 f ( n ) = e ( n ) − s ^ T Y ( n ) − s ^ T V ( n ) f(n)=e(n)-\hat{s}^TY(n)-\hat{s}^TV(n) f ( n ) = e ( n ) − s ^ T Y ( n ) − s ^ T V ( n ) s ^ → s \hat{s}\rightarrow s s ^ → s f ( n ) → d ( n ) f(n)\rightarrow d(n) f ( n ) → d ( n )
以辅助噪声向量 V ( n ) V(n) V ( n ) f ( n ) f(n) f ( n ) s ^ ( n + 1 ) = s ^ ( n ) + μ s f ( n ) V ( n ) \hat{s}(n+1)=\hat{s}(n)+\mu_s f(n)V(n) s ^ ( n + 1 ) = s ^ ( n ) + μ s f ( n ) V ( n )
由当前次级路径模型生成滤波参考信号 x ′ ( n ) = s ^ T ( n ) X ( n ) x^\prime(n)=\hat{s}^T(n)X(n) x ′ ( n ) = s ^ T ( n ) X ( n ) X ′ ( n ) = [ x ′ ( n ) , x ′ ( n − 1 ) , ⋯ , x ′ ( n − L + 1 ) ] X^\prime(n)=[x^\prime(n),x^\prime(n-1),\cdots,x^\prime(n-L+1)] X ′ ( n ) = [ x ′ ( n ) , x ′ ( n − 1 ) , ⋯ , x ′ ( n − L + 1 ) ]
控制滤波器系数更新 w ( n + 1 ) = w ( n ) − μ w e ( n ) X ′ ( n ) w(n+1)=w(n)-\mu_we(n)X^\prime(n) w ( n + 1 ) = w ( n ) − μ w e ( n ) X ′ ( n )
次级通道估计离线辨识
离线辨识是在系统启动前完成的辨识,适合环境固定的场景,它的精度高、计算简单。它的核心流程如下
准备激励信号:用已知的、宽带、能量均匀的信号激励扬声器,覆盖 ANC 的目标频段
同时同步采集扬声器输入激励 x ( n ) x(n) x ( n ) y ( n ) y(n) y ( n )
用算法从 { x ( n ) , y ( n ) } \{x(n),y(n)\} { x ( n ) , y ( n ) } s ^ ( n ) \hat{s}(n) s ^ ( n )
其中的激励信号直接决定辨识精度,在工程中常用的有 3 种
白噪声:频谱平坦,覆盖全频段,实现简单
线性扫频信号:能量集中,抗干扰性强,频率分辨率高
伪随机序列:确定性,抗干扰,可重复,频谱接近白噪声
在工程简化中,优先使用白噪声,代码容易实现且满足多数场合需求。
离线辨识有两种方法:即时域辨识和频域辨识
时域辨识:
麦克风输出激励信号 u ( n ) u(n) u ( n )
误差麦克风接收噪声误差 e ( n ) = s T V ( n ) e(n)=s^TV(n) e ( n ) = s T V ( n ) V ( n ) = [ v ( n ) , v ( n − 1 ) , ⋯ ] V(n)=[v(n),v(n-1),\cdots] V ( n ) = [ v ( n ) , v ( n − 1 ) , ⋯ ]
计算估计麦克风噪声误差 y ( n ) = s ^ T V ( n ) y(n)=\hat{s}^TV(n) y ( n ) = s ^ T V ( n )
计算误差 e o f f = e ( n ) − y ( n ) e_{off}=e(n)-y(n) e o f f = e ( n ) − y ( n )
更新 s ^ ( n + 1 ) = s ^ ( n ) + μ e ( n ) X ( n ) \hat{s}(n+1)=\hat{s}(n)+\mu e(n)X(n) s ^ ( n + 1 ) = s ^ ( n ) + μ e ( n ) X ( n ) s ^ ( n + 1 ) = s ^ ( n ) + μ ∥ X ( n ) ∥ 2 + δ e ( n ) X ( n ) \hat{s}(n+1)=\hat{s}(n)+\frac{\mu}{\Vert X(n)\Vert^2+\delta}e(n)X(n) s ^ ( n + 1 ) = s ^ ( n ) + ∥ X ( n ) ∥ 2 + δ μ e ( n ) X ( n )
频域辨识:
麦克风输出激励信号 u ( n ) u(n) u ( n ) e ( n ) = s ( n ) ∗ u ( n ) + v ( n ) e(n)=s(n)*u(n)+v(n) e ( n ) = s ( n ) ∗ u ( n ) + v ( n ) v ( n ) v(n) v ( n ) u ( n ) u(n) u ( n )
对上述采集信号做傅里叶变换,得到频域公式 Y ( f ) = S ( f ) U ( f ) + V ( f ) Y(f)=S(f)U(f)+V(f) Y ( f ) = S ( f ) U ( f ) + V ( f ) S ( f ) S(f) S ( f )
假设输入端 U ( f ) U(f) U ( f ) V ( f ) V(f) V ( f ) S ( f ) S(f) S ( f ) S ^ ( f ) = P U Y ( f ) P U U ( f ) = E [ U ( f ) U ∗ ( f ) ] E [ U ( f ) Y ∗ ( f ) ] \hat{S}(f)=\frac{P_{UY}(f)}{P_{UU}(f)}=\frac{E[U(f)U^*(f)]}{E[U(f)Y^*(f)]} S ^ ( f ) = P U U ( f ) P U Y ( f ) = E [ U ( f ) Y ∗ ( f ) ] E [ U ( f ) U ∗ ( f ) ]
利用 Welch 法进行谱估计:将长数据分为 M M M N N N w ( n ) w(n) w ( n )
第 i i i U i ( k ) = ∑ n = 0 N − 1 u i ( n ) w ( n ) e − j 2 π k n N U_i(k)=\sum_{n=0}^{N-1}u_i(n)w(n)e^{-j\frac{2\pi kn}{N}} U i ( k ) = ∑ n = 0 N − 1 u i ( n ) w ( n ) e − j N 2 π k n Y i ( k ) = ∑ n = 0 N − 1 y i ( n ) w ( n ) e − j 2 π k n N Y_i(k)=\sum_{n=0}^{N-1}y_i(n)w(n)e^{-j\frac{2\pi kn}{N}} Y i ( k ) = ∑ n = 0 N − 1 y i ( n ) w ( n ) e − j N 2 π k n
计算平均自谱和互谱 P ^ U U ( k ) = 1 M ∑ i = 1 M ∣ U i ( k ) ∣ 2 \hat{P}_{UU}(k)=\frac{1}{M}\sum_{i=1}^M\vert U_i(k)\vert^2 P ^ U U ( k ) = M 1 ∑ i = 1 M ∣ U i ( k ) ∣ 2 P ^ U Y ( k ) = 1 M ∑ i = 1 M U i ∗ ( k ) Y i ( k ) \hat{P}_{UY}(k)=\frac{1}{M}\sum_{i=1}^MU_i^*(k)Y_i(k) P ^ U Y ( k ) = M 1 ∑ i = 1 M U i ∗ ( k ) Y i ( k )
求比值得到频率响应估计 S ^ ( k ) = ∑ i = 1 M U i ∗ ( k ) Y i ( k ) ∑ i = 1 M ∣ U i ( k ) ∣ 2 \hat{S}(k)=\frac{\sum_{i=1}^MU_i^*(k)Y_i(k)}{\sum_{i=1}^M\vert U_i(k)\vert^2} S ^ ( k ) = ∑ i = 1 M ∣ U i ( k ) ∣ 2 ∑ i = 1 M U i ∗ ( k ) Y i ( k )
得到的频率响应估计进行逆傅里叶变换 s ^ r a w ( n ) = I F F T ( S ^ ( k ) ) \hat{s}_{raw}(n)=IFFT(\hat{S}(k)) s ^ r a w ( n ) = I F F T ( S ^ ( k ) ) s ^ ( n ) = R e ( s ^ r a w ( n ) ) \hat{s}(n)=Re(\hat{s}_{raw}(n)) s ^ ( n ) = R e ( s ^ r a w ( n ) )
此时得到的 s ^ ( n ) \hat{s}(n) s ^ ( n ) N N N L L L s ^ f = s ^ ( n ) w t ( n ) \hat{s}_f=\hat{s}(n)w_t(n) s ^ f = s ^ ( n ) w t ( n )
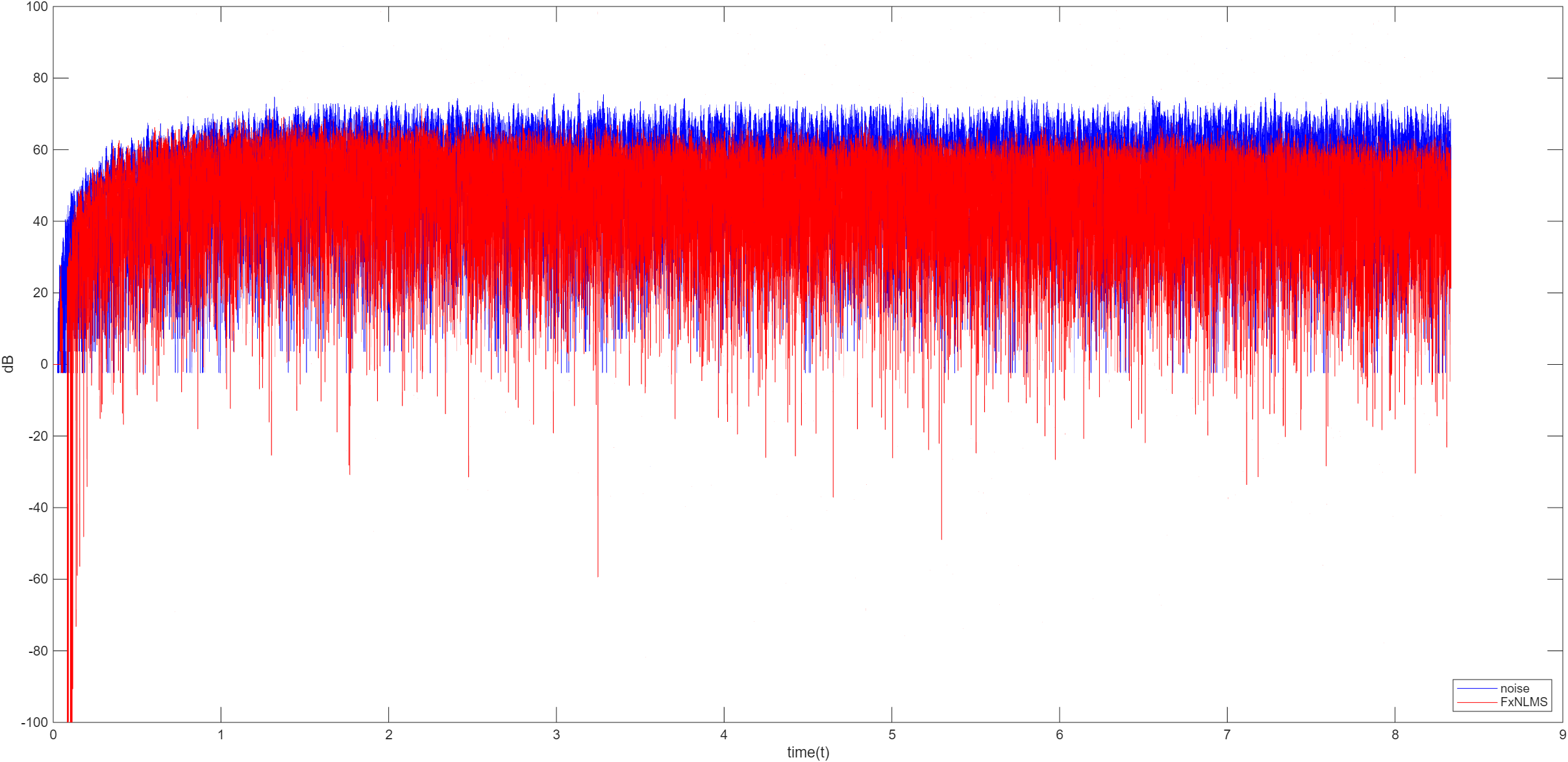
FxNLMS
FxNLMS 算法就是再 FxLMS 算法上添加步长归一化函数即可,即
μ ( n ) = α ∥ X ( n ) ∥ 2 + c \mu(n)=\frac{\alpha}{\Vert X(n)\Vert^2+c}
μ ( n ) = ∥ X ( n ) ∥ 2 + c α
与 NLMS 算法不同的是,这里需要用到的 X ( n ) X(n) X ( n ) X ′ ( n ) X^\prime(n) X ′ ( n )
μ ( n ) = α ∥ X ′ ( n ) ∥ 2 + c \mu(n)=\frac{\alpha}{\Vert X^\prime(n)\Vert^2+c}
μ ( n ) = ∥ X ′ ( n ) ∥ 2 + c α
其中定义 0 < α < 2 0<\alpha<2 0 < α < 2 c c c
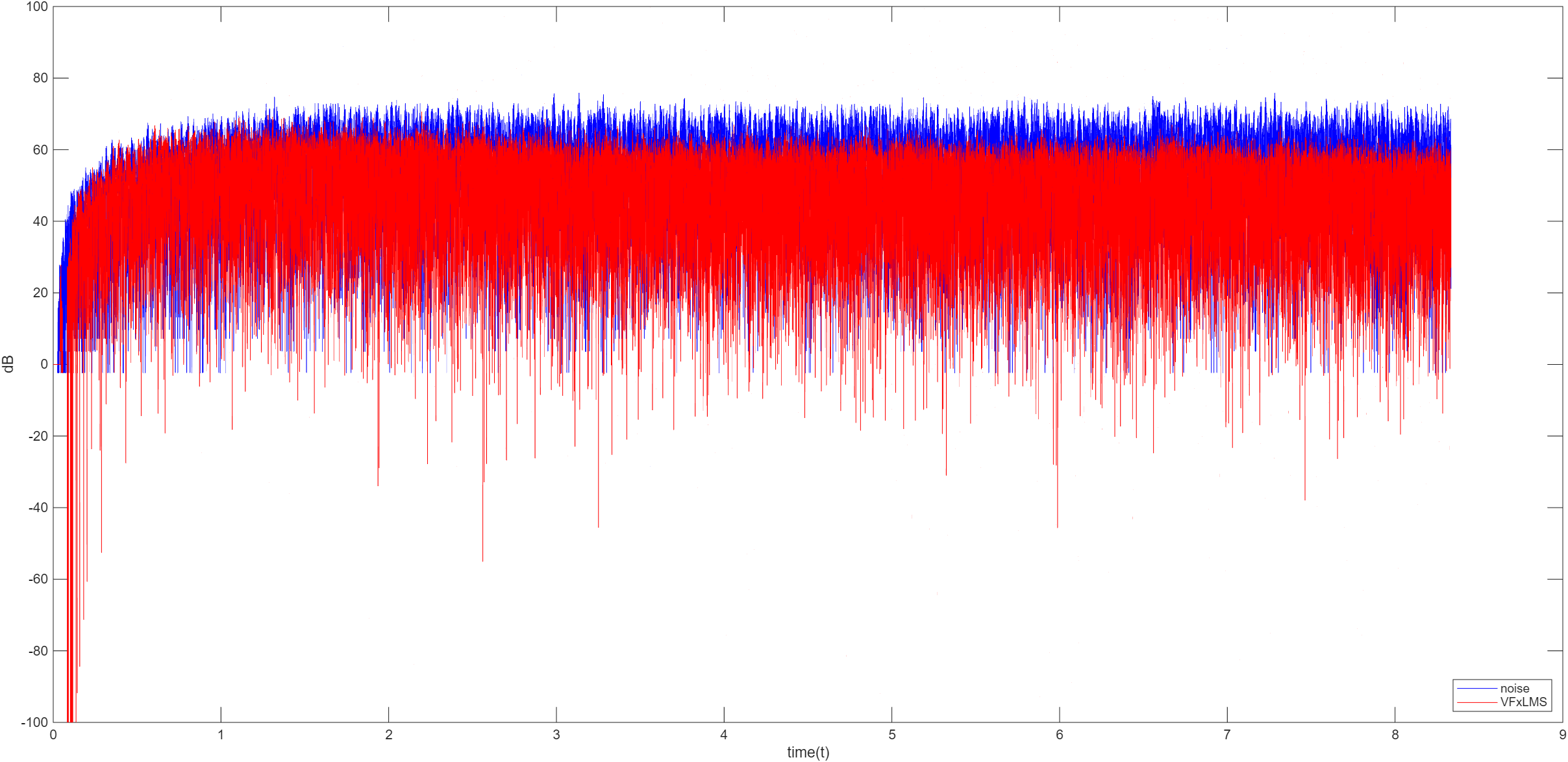
VFxLMS
VFxLMS 即变步长滤波的 FxLMS 算法,是 FxLMS 算法的核心改进,解决固定步长难以同时兼顾收敛速度与稳态误差的矛盾,在主动噪声控制中广泛应用。它的核心优势就是:初始阶段大步长快速收敛,接近最优解时使用小步长保证低残余噪声,适配动态环境。
在 FxLMS 中,固定步长的选择需要注意
大步长:收敛快,但稳态过量均方误差大,甚至可能导致系统不稳定
小步长:稳态 EMSE 小,但收敛慢,无法跟踪动态噪声变化
实际使用中,步长需与信号统计特性实时匹配,固定步长无法自适应调整
VFxLMS 在 FxLMS 的基础上,将固定的步长替换为时变步长 μ ( n ) \mu(n) μ ( n )
对于变步长的 μ ( n ) \mu(n) μ ( n )
基于误差信号的变步长:误差大时增大步长,误差小时减小步长,自适应误差调节步长
误差平方型 μ ( n ) = μ 0 ∣ e ( n ) ∣ p \mu(n)=\mu_0\vert e(n)\vert^p μ ( n ) = μ 0 ∣ e ( n ) ∣ p p = 1 , 2 p=1,2 p = 1 , 2 p = 2 p=2 p = 2
改进双曲线正切型 μ ( n ) = μ max tanh ( α ∣ e ( n ) ∣ 2 + β ) \mu(n)=\mu_{\max} \tanh(\alpha\vert e(n)\vert^2+\beta) μ ( n ) = μ m a x tanh ( α ∣ e ( n ) ∣ 2 + β ) α \alpha α β \beta β μ max \mu_{\max} μ m a x
归一化变步长:步长与滤波后的参考信号功率成反比,抵消信号功率波动对收敛的影响
μ ( n ) = μ 0 ∥ X ′ ( n ) ∥ 2 + δ \mu(n)=\frac{\mu_0}{\Vert X^\prime(n)\Vert^2+\delta} μ ( n ) = ∥ X ′ ( n ) ∥ 2 + δ μ 0 其中 δ \delta δ
误差与信号联合归一化:结合误差能量与参考信号功率,进一步提升鲁棒性
μ ( n ) = μ 0 ∣ e ( n ) ∣ ∥ X ′ ( n ) ∥ 2 + E [ e ( 2 ( n ) ] + δ \mu(n)=\frac{\mu_0\vert e(n)\vert}{\Vert X^\prime(n)\Vert^2+E[e(^2(n)]+\delta} μ ( n ) = ∥ X ′ ( n ) ∥ 2 + E [ e ( 2 ( n ) ] + δ μ 0 ∣ e ( n ) ∣ 其中 E [ e 2 ( n ) ] E[e^2(n)] E [ e 2 ( n ) ] E [ e 2 ( n ) ] = λ E [ e 2 ( n − 1 ) ] + ( 1 − λ ) e 2 ( n ) E[e^2(n)]=\lambda E[e^2(n-1)]+(1-\lambda)e^2(n) E [ e 2 ( n ) ] = λ E [ e 2 ( n − 1 ) ] + ( 1 − λ ) e 2 ( n ) λ \lambda λ 0.9 ∼ 0.99 0.9\sim0.99 0 . 9 ∼ 0 . 9 9
基于特征值约束的变步长:步长上限由滤波参考信号的自相关矩阵的最大特征值 λ max \lambda_{\max} λ m a x
0 < μ ( n ) < 2 λ max 0<\mu(n)<\frac{2}{\lambda_{\max}} 0 < μ ( n ) < λ m a x 2
需要注意的是,VFxLMS 的性能依赖于 s ^ ( n ) \hat{s}(n) s ^ ( n ) s ^ ( n ) \hat{s}(n) s ^ ( n )
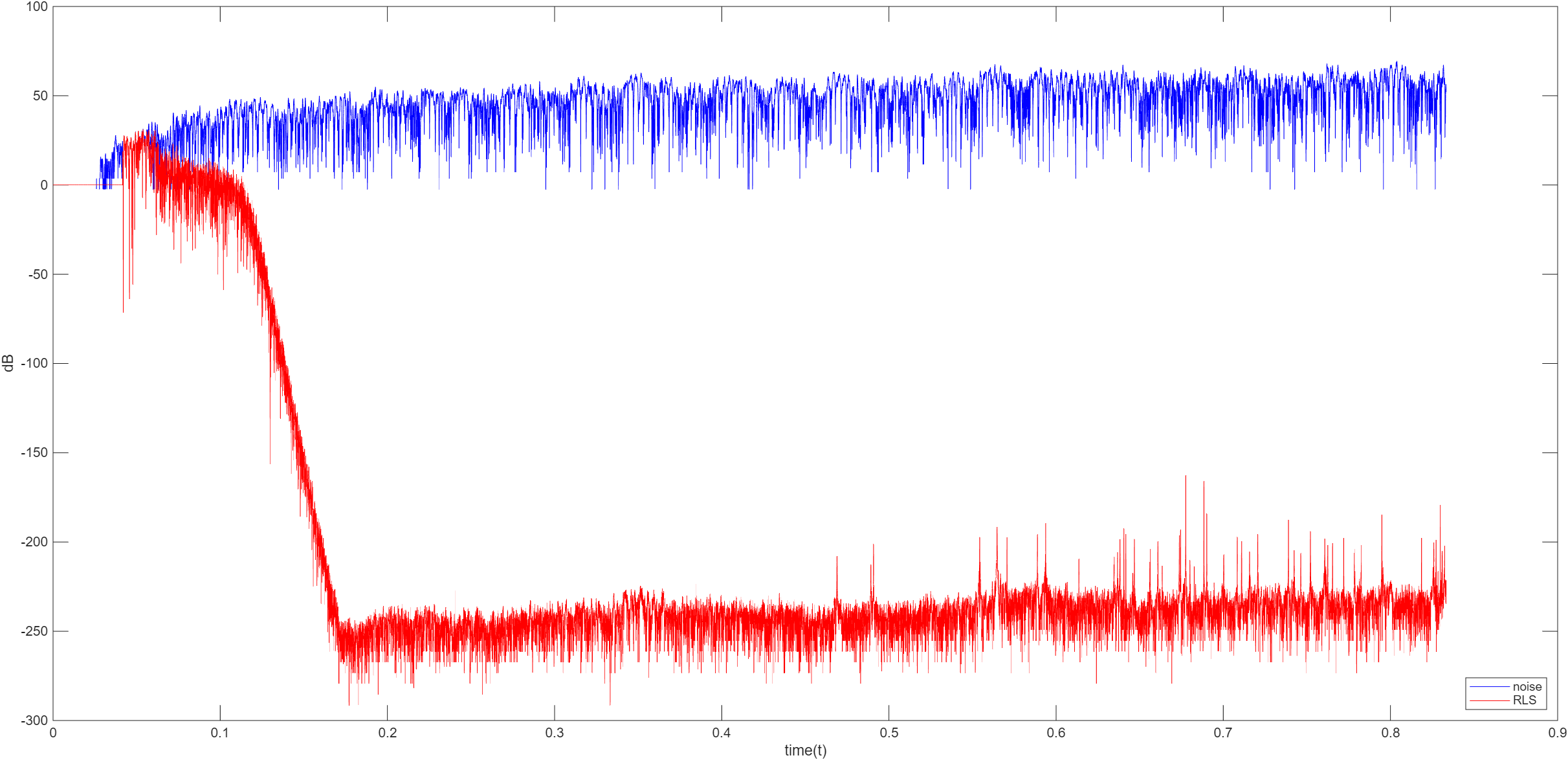
RLS
RLS 算法通过递归更新滤波器的系数 w ( n ) w(n) w ( n )
J ( n ) = ∑ i = 0 n λ n − i ∥ e ( i ) ∥ 2 J(n)=\sum_{i=0}^n\lambda^{n-i}\Vert e(i)\Vert_2
J ( n ) = i = 0 ∑ n λ n − i ∥ e ( i ) ∥ 2
其中的 0 < λ < 1 0<\lambda<1 0 < λ < 1 λ ∈ [ 0.95 , 0.999 ] \lambda\in[0.95,0.999] λ ∈ [ 0 . 9 5 , 0 . 9 9 9 ] 0.95 ∼ 0.98 0.95\sim0.98 0 . 9 5 ∼ 0 . 9 8 0.995 0.995 0 . 9 9 5 e ( n ) e(n) e ( n )
e ( n ) = d ( n ) + w T X ( n ) e(n)=d(n)+w^TX(n)
e ( n ) = d ( n ) + w T X ( n )
令代价函数对 w w w
∂ J ( n ) ∂ w ( n ) = 2 ∑ i = 0 n λ n − i X ( i ) e ( i ) = 2 ∑ i = 0 n λ n − i X ( i ) ( d ( i ) − w T X ( i ) ) = 0 \frac{\partial J(n)}{\partial w(n)}=2\sum_{i=0}^n\lambda^{n-i}X(i)e(i)=2\sum_{i=0}^n\lambda^{n-i}X(i)(d(i)-w^TX(i))=0
∂ w ( n ) ∂ J ( n ) = 2 i = 0 ∑ n λ n − i X ( i ) e ( i ) = 2 i = 0 ∑ n λ n − i X ( i ) ( d ( i ) − w T X ( i ) ) = 0
由于 w T X ( i ) w^TX(i) w T X ( i ) X ( i ) w T X ( i ) X(i)w^TX(i) X ( i ) w T X ( i ) X ( i ) X T ( i ) w X(i)X^T(i)w X ( i ) X T ( i ) w
∑ i = 0 n λ n − i X ( i ) d ( i ) = ∑ i = 0 n λ n − i X ( i ) X T ( i ) w ⇓ R ( n ) w = r ( n ) ⇓ w = R − 1 ( n ) r ( n ) \sum_{i=0}^n\lambda^{n-i}X(i)d(i)=\sum_{i=0}^n\lambda^{n-i}X(i)X^T(i)w\\\Downarrow\\R(n)w=r(n)\\\Downarrow\\w=R^{-1}(n)r(n)
i = 0 ∑ n λ n − i X ( i ) d ( i ) = i = 0 ∑ n λ n − i X ( i ) X T ( i ) w ⇓ R ( n ) w = r ( n ) ⇓ w = R − 1 ( n ) r ( n )
但是直接对 R ( n ) R(n) R ( n ) R ( n ) R(n) R ( n ) r ( n ) r(n) r ( n )
R ( n ) = λ R ( n − 1 ) + X ( n ) X T ( n ) r ( n ) = λ r ( n − 1 ) + X ( n ) d ( n ) R(n)=\lambda R(n-1)+X(n)X^T(n)\\r(n)=\lambda r(n-1)+X(n)d(n)
R ( n ) = λ R ( n − 1 ) + X ( n ) X T ( n ) r ( n ) = λ r ( n − 1 ) + X ( n ) d ( n )
对上述第一个公式左右两边求逆矩阵,利用 Woodbury 公式 ( A + B C D ) − 1 = A − 1 − A − 1 B ( C − 1 + D A − 1 B ) − 1 D A − 1 (A+BCD)^{-1}=A^{-1}-A^{-1}B(C^{-1}+DA^{-1}B)^{-1}DA^{-1} ( A + B C D ) − 1 = A − 1 − A − 1 B ( C − 1 + D A − 1 B ) − 1 D A − 1 A = λ R ( n − 1 ) , B = X ( n ) , C = 1 , D = X T ( n ) A=\lambda R(n-1),B=X(n),C=1,D=X^T(n) A = λ R ( n − 1 ) , B = X ( n ) , C = 1 , D = X T ( n ) P ( n ) = R − 1 ( n ) P(n)=R^{-1}(n) P ( n ) = R − 1 ( n )
P ( n ) = λ − 1 P ( n − 1 ) − λ − 2 P ( n − 1 ) X ( n ) X T ( n ) P ( n − 1 ) 1 + λ − 1 X T P ( n − 1 ) X ( n ) P(n)=\lambda^{-1}P(n-1)-\frac{\lambda^{-2}P(n-1)X(n)X^T(n)P(n-1)}{1+\lambda^{-1}X^TP(n-1)X(n)}
P ( n ) = λ − 1 P ( n − 1 ) − 1 + λ − 1 X T P ( n − 1 ) X ( n ) λ − 2 P ( n − 1 ) X ( n ) X T ( n ) P ( n − 1 )
得到 P ( n ) P(n) P ( n ) w ( n ) w(n) w ( n ) R ( n ) w ( n ) = r ( n ) R(n)w(n)=r(n) R ( n ) w ( n ) = r ( n ) w ( n − 1 ) w(n-1) w ( n − 1 ) R ( n − 1 ) w ( n − 1 ) = r ( n − 1 ) R(n-1)w(n-1)=r(n-1) R ( n − 1 ) w ( n − 1 ) = r ( n − 1 ) R R R r r r w ( n − 1 ) w(n-1) w ( n − 1 )
R ( n ) w ( n − 1 ) = λ R ( n − 1 ) w ( n − 1 ) + X ( n ) X T ( n ) w ( n − 1 ) R(n)w(n-1)=\lambda R(n-1)w(n-1)+X(n)X^T(n)w(n-1)
R ( n ) w ( n − 1 ) = λ R ( n − 1 ) w ( n − 1 ) + X ( n ) X T ( n ) w ( n − 1 )
由于 R ( n − 1 ) w ( n − 1 ) = r ( n − 1 ) R(n-1)w(n-1)=r(n-1) R ( n − 1 ) w ( n − 1 ) = r ( n − 1 )
R ( n ) w ( n − 1 ) = λ r ( n − 1 ) + X ( n ) X T ( n ) w ( n − 1 ) R(n)w(n-1)=\lambda r(n-1)+X(n)X^T(n)w(n-1)
R ( n ) w ( n − 1 ) = λ r ( n − 1 ) + X ( n ) X T ( n ) w ( n − 1 )
对比之前的 r ( n ) = λ r ( n ) + X ( n ) d ( n ) r(n)=\lambda r(n)+X(n)d(n) r ( n ) = λ r ( n ) + X ( n ) d ( n ) X ( n ) ( d ( n ) − X T ( n ) w ( n − 1 ) ) = X ( n ) e ( n ) X(n)(d(n)-X^T(n)w(n-1))=X(n)e(n) X ( n ) ( d ( n ) − X T ( n ) w ( n − 1 ) ) = X ( n ) e ( n )
R ( n ) w ( n − 1 ) = r ( n ) − X ( n ) e ( n ) R(n)w(n-1)=r(n)-X(n)e(n)
R ( n ) w ( n − 1 ) = r ( n ) − X ( n ) e ( n )
所以此时就希望能找到一个 Δ w \Delta w Δ w w ( n ) = w ( n − 1 ) + Δ w w(n)=w(n-1)+\Delta w w ( n ) = w ( n − 1 ) + Δ w R ( n ) w ( n ) = r ( n ) R(n)w(n)=r(n) R ( n ) w ( n ) = r ( n ) r ( n ) r(n) r ( n )
R ( n ) ( w ( n − 1 ) + Δ w ) = r ( n ) ⇓ R ( n ) Δ w = X ( n ) e ( n ) R(n)(w(n-1)+\Delta w)=r(n)\\\Downarrow\\R(n)\Delta w=X(n)e(n)
R ( n ) ( w ( n − 1 ) + Δ w ) = r ( n ) ⇓ R ( n ) Δ w = X ( n ) e ( n )
解出修正量
Δ w = R − 1 ( n ) X ( n ) e ( n ) = P ( n ) X ( n ) e ( n ) \Delta w=R^{-1}(n)X(n)e(n)=P(n)X(n)e(n)
Δ w = R − 1 ( n ) X ( n ) e ( n ) = P ( n ) X ( n ) e ( n )
此时引入一个增益向量来简化计算,带入上述的 P ( n ) P(n) P ( n )
K ( n ) = P ( n ) X ( n ) = P ( n − 1 ) X ( n ) λ + X T ( n ) P ( n − 1 ) X ( n ) K(n)=P(n)X(n)=\frac{P(n-1)X(n)}{\lambda+X^T(n)P(n-1)X(n)}
K ( n ) = P ( n ) X ( n ) = λ + X T ( n ) P ( n − 1 ) X ( n ) P ( n − 1 ) X ( n )
带入得到 P ( n ) P(n) P ( n )
P ( n ) = λ − 1 [ P ( n − 1 ) − K ( n ) X T ( n ) P ( n − 1 ) ] P(n)=\lambda^{-1}\Big[P(n-1)-K(n)X^T(n)P(n-1)\Big]
P ( n ) = λ − 1 [ P ( n − 1 ) − K ( n ) X T ( n ) P ( n − 1 ) ]
更新权向量
w ( n ) = w ( n − 1 ) − K ( n ) e ( n ) w(n)=w(n-1)-K(n)e(n)
w ( n ) = w ( n − 1 ) − K ( n ) e ( n )
初始时刻设置 w ( 0 ) = 0 w(0)=0 w ( 0 ) = 0 P ( 0 ) = δ − 1 I P(0)=\delta^{-1} I P ( 0 ) = δ − 1 I δ \delta δ δ \delta δ
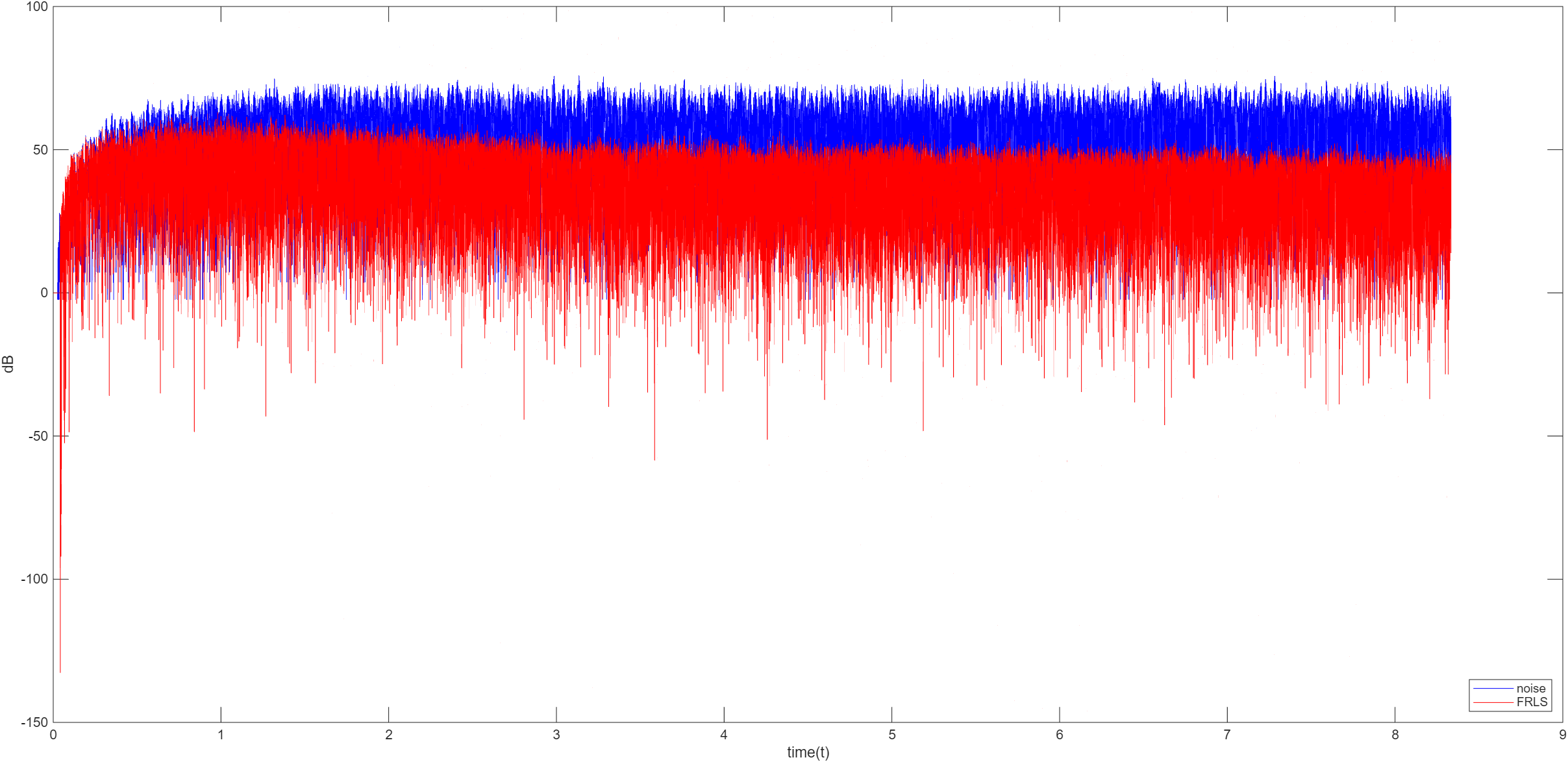
FRLS
FRLS 算法即快速递归最小二乘法,是标准 RLS 算法的一种高效实现。在标准 RLS 算法中,权向量更新公式如下
w ( n ) = w ( n − 1 ) − K ( n ) e ( n ) w(n)=w(n-1)-K(n)e(n)
w ( n ) = w ( n − 1 ) − K ( n ) e ( n )
其中的增益向量 K ( n ) = P ( n ) X ( n ) K(n)=P(n)X(n) K ( n ) = P ( n ) X ( n ) X ( n ) X(n) X ( n ) L × L L\times L L × L P ( n ) P(n) P ( n )
K ′ = P ( n − 1 ) X ( n ) K^\prime=P(n-1)X(n)
K ′ = P ( n − 1 ) X ( n )
这与标准 RLS 算法中的 Kalman 增益不同。定义转换因子
θ ( n ) = λ + X T K ′ ( n ) \theta(n)=\lambda+X^TK^\prime(n)
θ ( n ) = λ + X T K ′ ( n )
是一个标量,用于归一化 Kalman 增益。定义前向预测误差和后向预测误差
e f ( n ) = x ( n ) − a T ( n − 1 ) X ( n − 1 ) e b ( n ) = x ( n − L ) − b T ( n − 1 ) X ( n ) e_f(n)=x(n)-a^T(n-1)X(n-1)\\e_b(n)=x(n-L)-b^T(n-1)X(n)
e f ( n ) = x ( n ) − a T ( n − 1 ) X ( n − 1 ) e b ( n ) = x ( n − L ) − b T ( n − 1 ) X ( n )
其中 a ( n ) a(n) a ( n ) L L L x ( n ) x(n) x ( n ) b ( n ) b(n) b ( n ) L L L x ( n − L ) x(n-L) x ( n − L )
E f ( n ) = λ E f ( n − 1 ) + e f 2 ( n ) θ ( n − 1 ) E b ( n ) = λ E b ( n − 1 ) + e b 2 ( n ) θ ( n ) E_f(n)=\lambda E_f(n-1)+\frac{e_f^2(n)}{\theta(n-1)}\\E_b(n)=\lambda E_b(n-1)+\frac{e_b^2(n)}{\theta(n)}
E f ( n ) = λ E f ( n − 1 ) + θ ( n − 1 ) e f 2 ( n ) E b ( n ) = λ E b ( n − 1 ) + θ ( n ) e b 2 ( n )
FRLS 算法的核心是阶数更新和时间更新的结合,定义扩展 Kalman 增益向量 K L + 1 ( n ) K_{L+1}(n) K L + 1 ( n ) L + 1 L+1 L + 1 L L L
K L + 1 ( n ) = [ 0 K L ( n − 1 ) ] + [ 1 − a ( n − 1 ) ] e f ( n ) E f ( n − 1 ) K L + 1 ( n ) = [ K L ( n ) j ( n ) ] K_{L+1}(n)=\begin{bmatrix}0\\K_L(n-1)\end{bmatrix}+\begin{bmatrix}1\\-a(n-1)\end{bmatrix}\frac{e_f(n)}{E_f(n-1)}\\K_{L+1}(n)=\begin{bmatrix}K_L(n)\\j(n)\end{bmatrix}
K L + 1 ( n ) = [ 0 K L ( n − 1 ) ] + [ 1 − a ( n − 1 ) ] E f ( n − 1 ) e f ( n ) K L + 1 ( n ) = [ K L ( n ) j ( n ) ]
将 K L ( n ) K_L(n) K L ( n ) L L L j ( n ) j(n) j ( n )
前向预测器更新 a ( n ) = a ( n − 1 ) + K L ( n − 1 ) e f ( n ) θ ( n − 1 ) a(n)=a(n-1)+K_L(n-1)\frac{e_f(n)}{\theta(n-1)} a ( n ) = a ( n − 1 ) + K L ( n − 1 ) θ ( n − 1 ) e f ( n )
后向预测器更新 b ( n ) = b ( n − 1 ) + K L ( n ) e b ( n ) θ ( n ) b(n)=b(n-1)+K_L(n)\frac{e_b(n)}{\theta(n)} b ( n ) = b ( n − 1 ) + K L ( n ) θ ( n ) e b ( n )
上述的转换因子更新公式为 θ ( n ) = θ ( n − 1 ) + e f 2 ( n ) E f ( n − 1 ) − e b ( n ) j ( n ) \theta(n)=\theta(n-1)+\frac{e_f^2(n)}{E_f(n-1)}-e_b(n)j(n) θ ( n ) = θ ( n − 1 ) + E f ( n − 1 ) e f 2 ( n ) − e b ( n ) j ( n )
初始化
w ( n ) = 0 a ( 0 ) = 0 b ( 0 ) = 0 K ( 0 ) = 0 θ ( 0 ) = λ E f ( 0 ) = δ E b ( 0 ) = δ λ ∈ ( 0 , 1 ] w(n)=0\\a(0)=0\\b(0)=0\\K(0)=0\\\theta(0)=\lambda\\E_f(0)=\delta\\E_b(0)=\delta\\\lambda\in(0,1]
w ( n ) = 0 a ( 0 ) = 0 b ( 0 ) = 0 K ( 0 ) = 0 θ ( 0 ) = λ E f ( 0 ) = δ E b ( 0 ) = δ λ ∈ ( 0 , 1 ]
计算前向预测误差 e f ( n ) = x ( n ) − a T ( n − 1 ) X ( n − 1 ) e_f(n)=x(n)-a^T(n-1)X(n-1) e f ( n ) = x ( n ) − a T ( n − 1 ) X ( n − 1 )
更新前向预测误差能量 E f ( n ) = λ E f ( n − 1 ) + e f 2 ( n ) θ ( n − 1 ) E_f(n)=\lambda E_f(n-1)+\frac{e_f^2(n)}{\theta(n-1)} E f ( n ) = λ E f ( n − 1 ) + θ ( n − 1 ) e f 2 ( n )
前向预测器更新 a ( n ) = a ( n − 1 ) + K L ( n − 1 ) e f ( n ) θ ( n − 1 ) a(n)=a(n-1)+K_L(n-1)\frac{e_f(n)}{\theta(n-1)} a ( n ) = a ( n − 1 ) + K L ( n − 1 ) θ ( n − 1 ) e f ( n )
计算后向预测误差 e b ( n ) = x ( n − L ) − b T ( n − 1 ) X ( n ) e_b(n)=x(n-L)-b^T(n-1)X(n) e b ( n ) = x ( n − L ) − b T ( n − 1 ) X ( n )
更新扩展 Kalman 增益向量 [ K L ( n ) j ( n ) ] = [ 0 K L ( n − 1 ) ] + [ 1 − a ( n − 1 ) ] e f ( n ) E f ( n − 1 ) \begin{bmatrix}K_L(n)\\j(n)\end{bmatrix}=\begin{bmatrix}0\\K_L(n-1)\end{bmatrix}+\begin{bmatrix}1\\-a(n-1)\end{bmatrix}\frac{e_f(n)}{E_f(n-1)} [ K L ( n ) j ( n ) ] = [ 0 K L ( n − 1 ) ] + [ 1 − a ( n − 1 ) ] E f ( n − 1 ) e f ( n )
更新转换因子 θ ( n ) = θ ( n − 1 ) + e f 2 ( n ) E f ( n − 1 ) − e b ( n ) j ( n ) \theta(n)=\theta(n-1)+\frac{e_f^2(n)}{E_f(n-1)}-e_b(n)j(n) θ ( n ) = θ ( n − 1 ) + E f ( n − 1 ) e f 2 ( n ) − e b ( n ) j ( n )
更新后向预测误差能量 E b ( n ) = λ E b ( n − 1 ) + e b 2 ( n ) θ ( n ) E_b(n)=\lambda E_b(n-1)+\frac{e_b^2(n)}{\theta(n)} E b ( n ) = λ E b ( n − 1 ) + θ ( n ) e b 2 ( n )
后向预测器更新 b ( n ) = b ( n − 1 ) + K L ( n ) e b ( n ) θ ( n ) b(n)=b(n-1)+K_L(n)\frac{e_b(n)}{\theta(n)} b ( n ) = b ( n − 1 ) + K L ( n ) θ ( n ) e b ( n )
得到误差信号 e ( n ) = d ( n ) − w T ( n − 1 ) X ( n ) e(n)=d(n)-w^T(n-1)X(n) e ( n ) = d ( n ) − w T ( n − 1 ) X ( n )
更新滤波器参数 w ( n ) = w ( n − 1 ) − K L ( n ) e ( n ) θ ( n ) w(n)=w(n-1)-K_L(n)\frac{e(n)}{\theta(n)} w ( n ) = w ( n − 1 ) − K L ( n ) θ ( n ) e ( n )
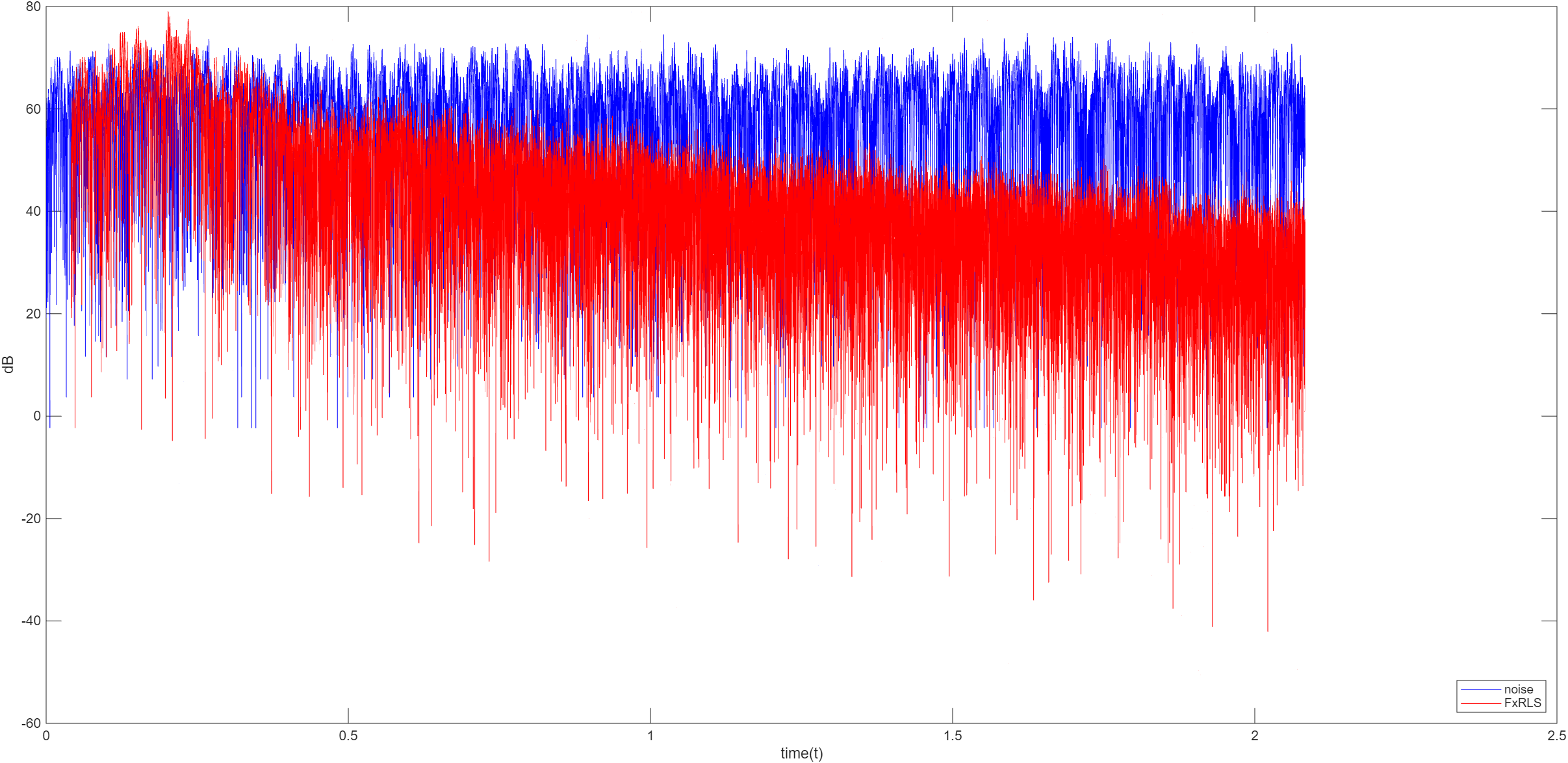
FxRLS
FxRLS 算法是递归最小二乘 RLS 算法上存在次级路径系统中的扩展,继承了 RLS 算法快速收敛、稳态误差小的优点,同时引入滤波操作解决了标准 RLS 在次级路径存在时的稳定性问题和收敛性能下降问题
FxRLS 相较于 RLS 的改进点在于:在进行权值更新前,先将原始参考信号 x ( n ) x(n) x ( n ) s ^ ( n ) \hat{s}(n) s ^ ( n ) x ′ ( n ) x^\prime(n) x ′ ( n ) x ′ ( n ) x^\prime(n) x ′ ( n ) x ( n ) x(n) x ( n )
初始化 w ( 0 ) = 0 w(0)=0 w ( 0 ) = 0 P ( 0 ) = δ − 1 I P(0)=\delta^{-1}I P ( 0 ) = δ − 1 I δ \delta δ
滤波后的参考信号 x ′ ( n ) = s ^ ( n ) X ( n ) x^\prime(n)=\hat{s}(n)X(n) x ′ ( n ) = s ^ ( n ) X ( n ) X ′ ( n ) X^\prime(n) X ′ ( n )
麦克风输出信号 y ( n ) = w T X ( n ) y(n)=w^TX(n) y ( n ) = w T X ( n ) Y ( n ) Y(n) Y ( n )
获得误差信号 e ( n ) = s T ( n ) D ( n ) + s T ( n ) Y ( n ) e(n)=s^T(n)D(n)+s^T(n)Y(n) e ( n ) = s T ( n ) D ( n ) + s T ( n ) Y ( n )
计算增益向量 K ( n ) = P ( n ) X ′ ( n ) = P ( n − 1 ) X ′ ( n ) λ + ( X ′ ) T ( n ) P ( n − 1 ) X ′ ( n ) K(n)=P(n)X^\prime(n)=\frac{P(n-1)X^\prime(n)}{\lambda+(X^\prime)^T(n)P(n-1)X^\prime(n)} K ( n ) = P ( n ) X ′ ( n ) = λ + ( X ′ ) T ( n ) P ( n − 1 ) X ′ ( n ) P ( n − 1 ) X ′ ( n )
计算协方差矩阵 P ( n ) = λ − 1 ( P ( n − 1 ) − K ( n ) ( X ′ ) T ( n ) P ( n − 1 ) ) P(n)=\lambda^{-1}(P(n-1)-K(n)(X^\prime)^T(n)P(n-1)) P ( n ) = λ − 1 ( P ( n − 1 ) − K ( n ) ( X ′ ) T ( n ) P ( n − 1 ) )
更新权值向量 w ( n ) = w ( n − 1 ) − K ( n ) e ( n ) w(n)=w(n-1)-K(n)e(n) w ( n ) = w ( n − 1 ) − K ( n ) e ( n )
次级通道模型辨识的方法与 FxLMS 中的辨识方法一致
FxKalman
FxKalman 算法建立在 Kalman 滤波的最优状态估计框架之上,核心是将自适应滤波器的系数向量 w w w X ′ ( n ) X^\prime(n) X ′ ( n )
参考麦克风采集的参考信号 x ( n ) x(n) x ( n ) X ( n ) X(n) X ( n )
计算扬声器输出信号 y ( n ) = w T ( n ) X ( n ) y(n)=w^T(n)X(n) y ( n ) = w T ( n ) X ( n ) Y ( n ) Y(n) Y ( n )
误差麦克风采集的残余信号 e ( n ) = s T ( n ) D ( n ) + s T ( n ) Y ( n ) e(n)=s^T(n)D(n)+s^T(n)Y(n) e ( n ) = s T ( n ) D ( n ) + s T ( n ) Y ( n )
计算次级路径估计滤波信号 x ′ ( n ) = s ^ T ( n ) X ( n ) x^\prime(n)=\hat{s}^T(n)X(n) x ′ ( n ) = s ^ T ( n ) X ( n ) X ′ ( n ) X^\prime(n) X ′ ( n )
更新预测 w ( n ∣ n − 1 ) = w ( n − 1 ∣ n − 1 ) w(n\vert n-1)=w(n-1\vert n-1) w ( n ∣ n − 1 ) = w ( n − 1 ∣ n − 1 ) P ( n ∣ n − 1 ) = P ( n − 1 ∣ n − 1 ) + Q P(n\vert n-1)=P(n-1\vert n-1)+Q P ( n ∣ n − 1 ) = P ( n − 1 ∣ n − 1 ) + Q
计算 Kalman 增益 K ( n ) = P ( n ∣ n − 1 ) X ′ ( n ) R + ( X ′ ) T ( n ) P ( n ∣ n − 1 ) X ′ ( n ) K(n)=\frac{P(n\vert n-1)X^\prime(n)}{R+(X^\prime)^T(n)P(n\vert n-1)X^\prime(n)} K ( n ) = R + ( X ′ ) T ( n ) P ( n ∣ n − 1 ) X ′ ( n ) P ( n ∣ n − 1 ) X ′ ( n )
测量更新 w ( n ∣ n ) = w ( n ∣ n − 1 ) + K ( n ) e ( n ) w(n\vert n)=w(n\vert n-1)+K(n)e(n) w ( n ∣ n ) = w ( n ∣ n − 1 ) + K ( n ) e ( n ) P ( n ∣ n ) = [ I − K ( n ) ( X ′ ) T ( n ) ] P ( n ∣ n − 1 ) P(n\vert n)=\Big[I-K(n)(X^\prime)^T(n)\Big]P(n\vert n-1) P ( n ∣ n ) = [ I − K ( n ) ( X ′ ) T ( n ) ] P ( n ∣ n − 1 )
其中 Q Q Q R R R P ( 0 ∣ 0 ) = δ − 1 I P(0\vert0)=\delta^{-1}I P ( 0 ∣ 0 ) = δ − 1 I δ \delta δ
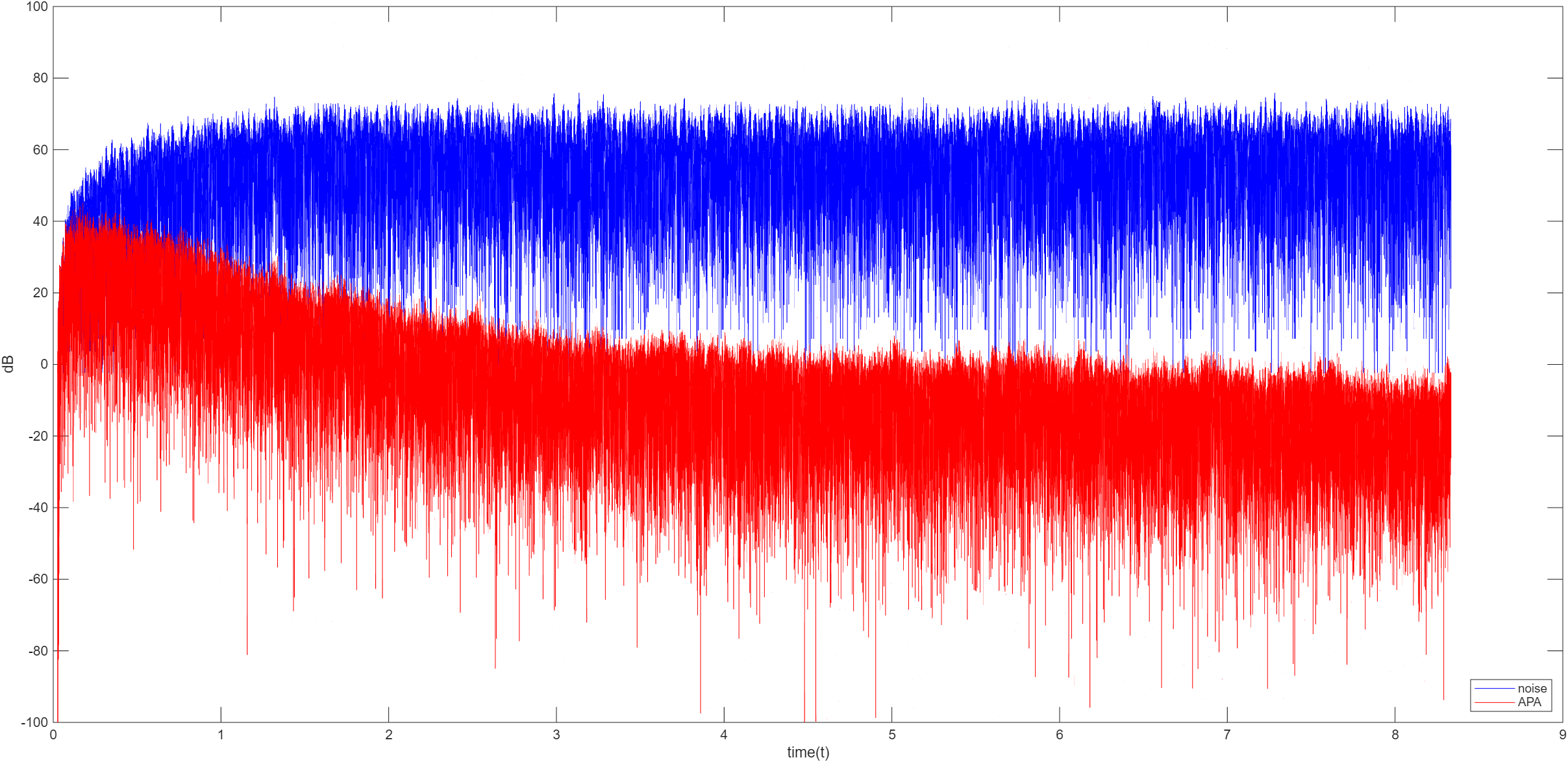
APA
APA(Affine Projection Algorithm,仿射投影算法) 是一种经典的自适应滤波算法,是为了解决 LMS 和 NLMS 算法在处理相关输入信号时收敛速度显著下降的问题的,它可以看作时 NLMS 算法的自然推广。NLMS 算法每次迭代时只使用 1 个当前输入向量进行权值更新,而 APA 算法每次迭代同时使用 K K K
从几何角度来看,K 阶仿射投影就是将当前权向量正交投影到由 K 个超平面相交形成的 K-L 维仿射子空间上。当 K = 1 K=1 K = 1
μ ( n ) = α ∥ X ( n ) ∥ 2 + c \mu(n)=\frac{\alpha}{\Vert X(n)\Vert^2+c}
μ ( n ) = ∥ X ( n ) ∥ 2 + c α
是当前权重向量在单个超平面上的正交投影,这个超平面由当前的参考信号向量定义,满足后验误差为 0 的约束。在 APA 算法中,同时施加 K K K
在 APA 算法中,定义了输入矩阵 M M M
M ( n ) = [ X ( n ) X ( n − 1 ) ⋯ X ( n − K + 1 ) ] X ( n ) = [ x ( n ) x ( n − 1 ) ⋯ x ( n − L + 1 ) ] T M(n)=\begin{bmatrix}X(n)&X(n-1)&\cdots&X(n-K+1)\end{bmatrix}\\X(n)=\begin{bmatrix}x(n)&x(n-1)&\cdots&x(n-L+1)\end{bmatrix}^T
M ( n ) = [ X ( n ) X ( n − 1 ) ⋯ X ( n − K + 1 ) ] X ( n ) = [ x ( n ) x ( n − 1 ) ⋯ x ( n − L + 1 ) ] T
定义期望信号向量
D ( n ) = [ d ( n ) ⋯ d ( n − K + 1 ) ] D(n)=\begin{bmatrix}d(n)&\cdots&d(n-K+1)\end{bmatrix}
D ( n ) = [ d ( n ) ⋯ d ( n − K + 1 ) ]
定义先验误差向量
e ( n ) = D ( n ) − M T ( n ) w ( n − 1 ) e(n)=D(n)-M^T(n)w(n-1)
e ( n ) = D ( n ) − M T ( n ) w ( n − 1 )
此时优化问题可以重写如下
min w ( n ) ∥ w ( n ) − w ( n − 1 ) ∥ 2 2 s . t . D ( n ) = M T ( n ) w ( n ) \min_{w(n)}\Vert w(n)-w(n-1)\Vert_2^2\\s.t.\quad D(n)=M^T(n)w(n)
w ( n ) min ∥ w ( n ) − w ( n − 1 ) ∥ 2 2 s . t . D ( n ) = M T ( n ) w ( n )
此时利用拉格朗日乘数法来求解,构造拉格朗日函数
L ( w ( n ) , λ ) = ∥ w ( n ) − w ( n − 1 ) ∥ 2 2 + λ T ( D ( n ) − M T ( n ) w ( n ) ) L(w(n),\lambda)=\Big\Vert w(n)-w(n-1)\Big\Vert_2^2+\lambda^T\Big(D(n)-M^T(n)w(n)\Big)
L ( w ( n ) , λ ) = ∥ ∥ ∥ ∥ w ( n ) − w ( n − 1 ) ∥ ∥ ∥ ∥ 2 2 + λ T ( D ( n ) − M T ( n ) w ( n ) )
对 w ( n ) w(n) w ( n )
∂ L ( w ( n ) , λ ) ∂ w ( n ) = 2 ( w ( n ) − w ( n − 1 ) ) − M ( n ) λ = 0 ⇓ w ( n ) = w ( n − 1 ) + 1 2 M ( n ) λ \frac{\partial L(w(n),\lambda)}{\partial w(n)}=2\Big(w(n)-w(n-1)\Big)-M(n)\lambda=0\\\Downarrow\\w(n)=w(n-1)+\frac{1}{2}M(n)\lambda
∂ w ( n ) ∂ L ( w ( n ) , λ ) = 2 ( w ( n ) − w ( n − 1 ) ) − M ( n ) λ = 0 ⇓ w ( n ) = w ( n − 1 ) + 2 1 M ( n ) λ
对 λ \lambda λ
∂ L ( w ( n ) , λ ) ∂ λ = D ( n ) − M T w ( n ) = 0 \frac{\partial L(w(n),\lambda)}{\partial \lambda}=D(n)-M^Tw(n)=0
∂ λ ∂ L ( w ( n ) , λ ) = D ( n ) − M T w ( n ) = 0
将 w ( n ) = w ( n − 1 ) + 1 2 M ( n ) λ w(n)=w(n-1)+\frac{1}{2}M(n)\lambda w ( n ) = w ( n − 1 ) + 2 1 M ( n ) λ
D ( n ) − M T ( w ( n − 1 ) + 1 2 M ( n ) λ ) = 0 ⇓ λ = 2 ( M T ( n ) M ( n ) ) − 1 e ( n ) D(n)-M^T\Big(w(n-1)+\frac{1}{2}M(n)\lambda\Big)=0\\\Downarrow\\\lambda=2\Big(M^T(n)M(n)\Big)^{-1}e(n)
D ( n ) − M T ( w ( n − 1 ) + 2 1 M ( n ) λ ) = 0 ⇓ λ = 2 ( M T ( n ) M ( n ) ) − 1 e ( n )
带入 w ( n ) = w ( n − 1 ) + 1 2 M ( n ) λ w(n)=w(n-1)+\frac{1}{2}M(n)\lambda w ( n ) = w ( n − 1 ) + 2 1 M ( n ) λ
w ( n ) = w ( n − 1 ) + M ( n ) ( M T ( n ) M ( n ) ) − 1 e ( n ) w(n)=w(n-1)+M(n)\Big(M^T(n)M(n)\Big)^{-1}e(n)
w ( n ) = w ( n − 1 ) + M ( n ) ( M T ( n ) M ( n ) ) − 1 e ( n )
实际中为了防止矩阵 M T ( n ) M ( n ) M^T(n)M(n) M T ( n ) M ( n ) δ \delta δ μ \mu μ
w ( n ) = w ( n − 1 ) + μ M ( n ) ( M T ( n ) M ( n ) + δ I ) − 1 e ( n ) w(n)=w(n-1)+\mu M(n)\Big(M^T(n)M(n)+\delta I\Big)^{-1}e(n)
w ( n ) = w ( n − 1 ) + μ M ( n ) ( M T ( n ) M ( n ) + δ I ) − 1 e ( n )
APA 算法的迭代过程如下
参考麦克风信号 x ( n ) x(n) x ( n ) X ( n ) X(n) X ( n )
更新输入矩阵 M ( n ) = [ X ( n ) , M ( : , 1 : K − 1 ) ] M(n)=\begin{bmatrix}X(n),M(:,1:K-1)\end{bmatrix} M ( n ) = [ X ( n ) , M ( : , 1 : K − 1 ) ]
计算先验误差向量 e ( n ) = D ( n ) − M T ( n ) w ( n − 1 ) e(n)=D(n)-M^T(n)w(n-1) e ( n ) = D ( n ) − M T ( n ) w ( n − 1 ) D ( n ) = [ d ( n ) ⋯ d ( n − K + 1 ) ] D(n)=\begin{bmatrix}d(n)&\cdots&d(n-K+1)\end{bmatrix} D ( n ) = [ d ( n ) ⋯ d ( n − K + 1 ) ]
计算矩阵逆 R ( n ) = M T ( n ) M ( n ) + δ I R(n)=M^T(n)M(n)+\delta I R ( n ) = M T ( n ) M ( n ) + δ I
更新权重向量 w ( n ) = w ( n − 1 ) + μ M ( n ) R − 1 ( n ) e ( n ) w(n)=w(n-1)+\mu M(n)R^{-1}(n)e(n) w ( n ) = w ( n − 1 ) + μ M ( n ) R − 1 ( n ) e ( n )
计算当前滤波器输出 y ( n ) = w T ( n ) X ( n ) y(n)=w^T(n)X(n) y ( n ) = w T ( n ) X ( n )
由于整体需要求逆计算,所以在运行中的计算量较大
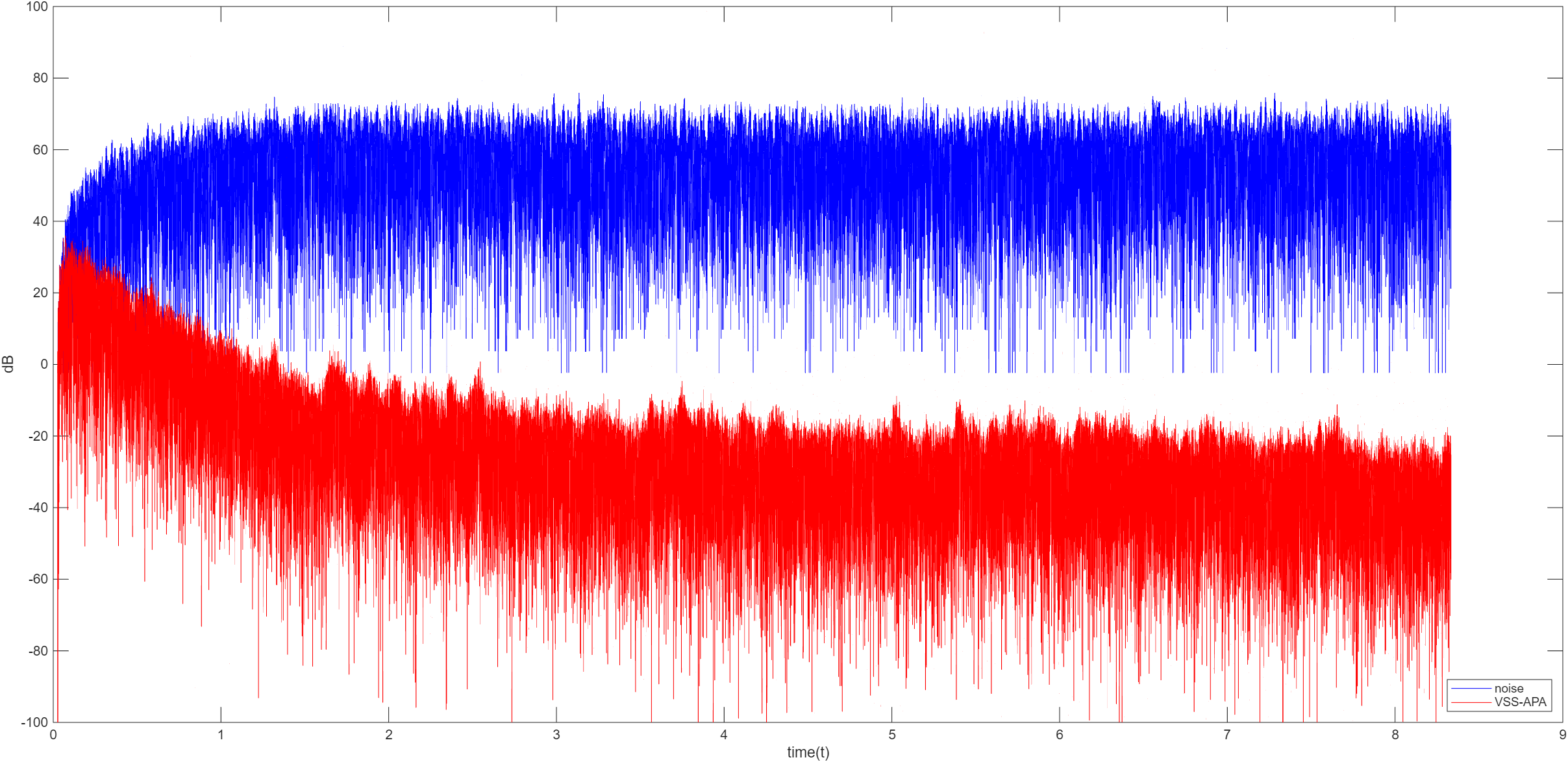
VSS-APA
对于固定步长 APA 算法,存在一个固有的矛盾,即大步长时收敛速度块,但稳态误差大,甚至可能导致算法发散,而小步长稳态误差小,但收敛速度慢,跟踪能力差
为了推导最优变步长,定义权误差向量
w ~ ( n ) = w 0 − w ^ ( n ) \tilde{w}(n)=w_0-\hat{w}(n)
w ~ ( n ) = w 0 − w ^ ( n )
其中 w 0 w_0 w 0
w ~ ( n + 1 ) = w ~ ( n ) − μ M ( n ) R − 1 ( n ) e ( n ) \tilde{w}(n+1)=\tilde{w}(n)-\mu M(n)R^{-1}(n)e(n)
w ~ ( n + 1 ) = w ~ ( n ) − μ M ( n ) R − 1 ( n ) e ( n )
对两边取平方欧几里得范数并求期望
E ( ∥ w ~ ( n + 1 ) ∥ 2 ) = E ( ∥ w ~ ( n ) ∥ 2 ) − 2 μ ( n ) E ( e T ( n ) R − 1 ( n ) M T ( n ) w ~ ( n ) ) + μ 2 ( n ) E ( ∥ M ( n ) R − 1 e ( n ) ∥ 2 ) E(\Vert\tilde{w}(n+1)\Vert^2)=E\Big(\Vert\tilde{w}(n)\Vert^2\Big)-2\mu(n)E\Big(e^T(n)R^{-1}(n)M^T(n)\tilde{w}(n)\Big)+\mu^2(n)E\Big(\Vert M(n)R^{-1}e(n)\Vert^2\Big)
E ( ∥ w ~ ( n + 1 ) ∥ 2 ) = E ( ∥ w ~ ( n ) ∥ 2 ) − 2 μ ( n ) E ( e T ( n ) R − 1 ( n ) M T ( n ) w ~ ( n ) ) + μ 2 ( n ) E ( ∥ M ( n ) R − 1 e ( n ) ∥ 2 )
为了使权误差向量的范数最小化,对 μ ( n ) \mu(n) μ ( n )
μ ( n ) = E ( e T ( n ) R − 1 ( n ) M T ( n ) w ~ ( n ) ) E ( ∥ M ( n ) R − 1 e ( n ) ∥ 2 ) \mu(n)=\frac{E\Big(e^T(n)R^{-1}(n)M^T(n)\tilde{w}(n)\Big)}{E\Big(\Vert M(n)R^{-1}e(n)\Vert^2\Big)}
μ ( n ) = E ( ∥ M ( n ) R − 1 e ( n ) ∥ 2 ) E ( e T ( n ) R − 1 ( n ) M T ( n ) w ~ ( n ) )
但是由于 w ^ ( n ) \hat{w}(n) w ^ ( n )
基于误差范数的变步长
步长更新公式 μ ( n ) = μ m a x exp ( − α ∥ e ( n ) ∥ 2 ) \mu(n)=\mu_{max}\exp(-\alpha\Vert e(n)\Vert^2) μ ( n ) = μ m a x exp ( − α ∥ e ( n ) ∥ 2 ) μ ( n ) = μ m a x 1 + β ∥ e ( n ) ∥ 2 \mu(n)=\frac{\mu_{max}}{1+\beta\Vert e(n)\Vert^2} μ ( n ) = 1 + β ∥ e ( n ) ∥ 2 μ m a x
其中 μ m a x \mu_{max} μ m a x α , β \alpha,\beta α , β
基于误差自相关的变步长,提高对噪声的鲁棒性
引入 p ( n ) = γ p ( n − 1 ) + ( 1 − γ ) e ( n ) e ( n − 1 ) p(n)=\gamma p(n-1)+(1-\gamma)e(n)e(n-1) p ( n ) = γ p ( n − 1 ) + ( 1 − γ ) e ( n ) e ( n − 1 )
步长更新 μ ( n ) = μ m a x ( 1 − exp ( − β ∣ p ( n ) ∣ 2 ) ) \mu(n)=\mu_{max}(1-\exp(-\beta\vert p(n)\vert^2)) μ ( n ) = μ m a x ( 1 − exp ( − β ∣ p ( n ) ∣ 2 ) )
其中的 γ \gamma γ 0.9 ∼ 0.99 0.9\sim0.99 0 . 9 ∼ 0 . 9 9
基于集员滤波的变步长:只有当误差超过某个预设的阈值时才更新权向量,这样可以大大降低计算复杂度
步长更新公式 μ ( n ) = max ( 0 , 1 − γ ∥ e ( n ) ∥ ) \mu(n)=\max(0,1-\frac{\gamma}{\Vert e(n)\Vert}) μ ( n ) = max ( 0 , 1 − ∥ e ( n ) ∥ γ )
其中 γ \gamma γ ∥ e ( n ) ≤ γ \Vert e(n)\leq\gamma ∥ e ( n ) ≤ γ μ ( n ) = 0 \mu(n)=0 μ ( n ) = 0
指数型变步长:直接将投影误差的范数通过指数函数映射得到步长
步长更新公式 μ ( n ) = μ m i n + ( μ m a x − μ m i n ) exp ( − α ∥ e ( n ) ∥ 2 ) \mu(n)=\mu_{min}+(\mu_{max}-\mu_{min})\exp(-\alpha\Vert e(n)\Vert^2) μ ( n ) = μ m i n + ( μ m a x − μ m i n ) exp ( − α ∥ e ( n ) ∥ 2 )
变步长公式需要在权向量更新时进行计算
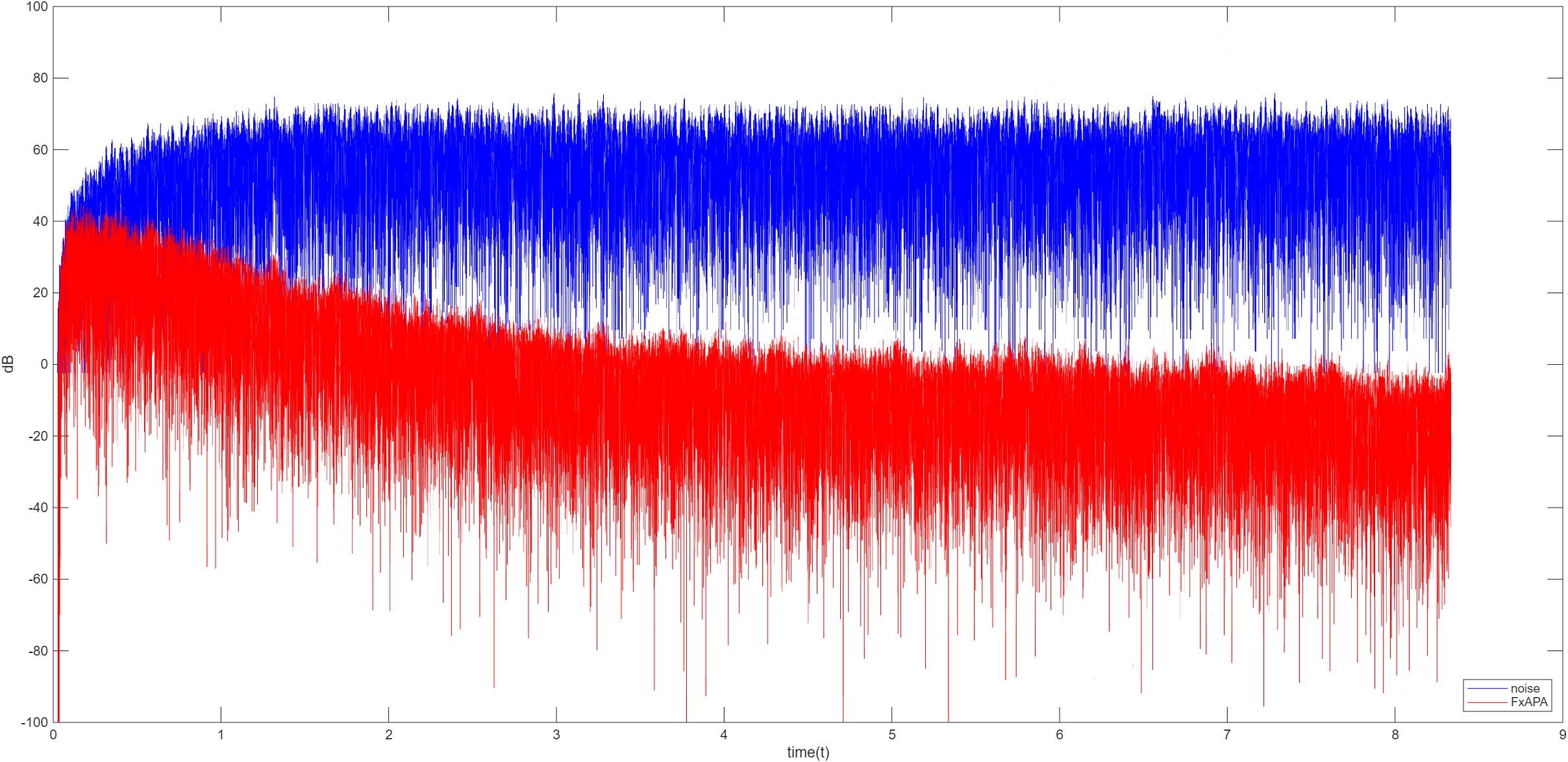
FxAPA
首先是将期望矩阵 D ( n ) D(n) D ( n ) D f ( n ) D_f(n) D f ( n ) M ( n ) M(n) M ( n ) M f ( n ) M_f(n) M f ( n )
D ( n ) = [ d ( n ) ⋯ d ( n − L + 1 ) ] d f ( n ) = s ^ T D ( n ) D f ( n ) = [ d f ( n ) ⋯ d f ( n − K + 1 ) ] x f ( n ) = s ^ T X ( n ) X f ( n ) = [ x f ( n ) ⋮ x f ( n − L + 1 ) ] M f = [ X f ( n ) ⋯ X f ( n − L + 1 ) ] D(n)=\begin{bmatrix}d(n)&\cdots&d(n-L+1)\end{bmatrix}\\d_f(n)=\hat{s}^TD(n)\\D_f(n)=\begin{bmatrix}d_f(n)&\cdots&d_f(n-K+1)\end{bmatrix}\\x_f(n)=\hat{s}^TX(n)\\X_f(n)=\begin{bmatrix}x_f(n)\\\vdots\\x_f(n-L+1)\end{bmatrix}\\M_f=\begin{bmatrix}X_f(n)&\cdots&X_f(n-L+1)\end{bmatrix}
D ( n ) = [ d ( n ) ⋯ d ( n − L + 1 ) ] d f ( n ) = s ^ T D ( n ) D f ( n ) = [ d f ( n ) ⋯ d f ( n − K + 1 ) ] x f ( n ) = s ^ T X ( n ) X f ( n ) = ⎣ ⎢ ⎢ ⎡ x f ( n ) ⋮ x f ( n − L + 1 ) ⎦ ⎥ ⎥ ⎤ M f = [ X f ( n ) ⋯ X f ( n − L + 1 ) ]
另外误差的公式为 e ( n ) = s T ( D f ( n ) − M T ( n ) w ( n − 1 ) ) e(n)=s^T\Big(D_f(n)-M^T(n)w(n-1)\Big) e ( n ) = s T ( D f ( n ) − M T ( n ) w ( n − 1 ) )
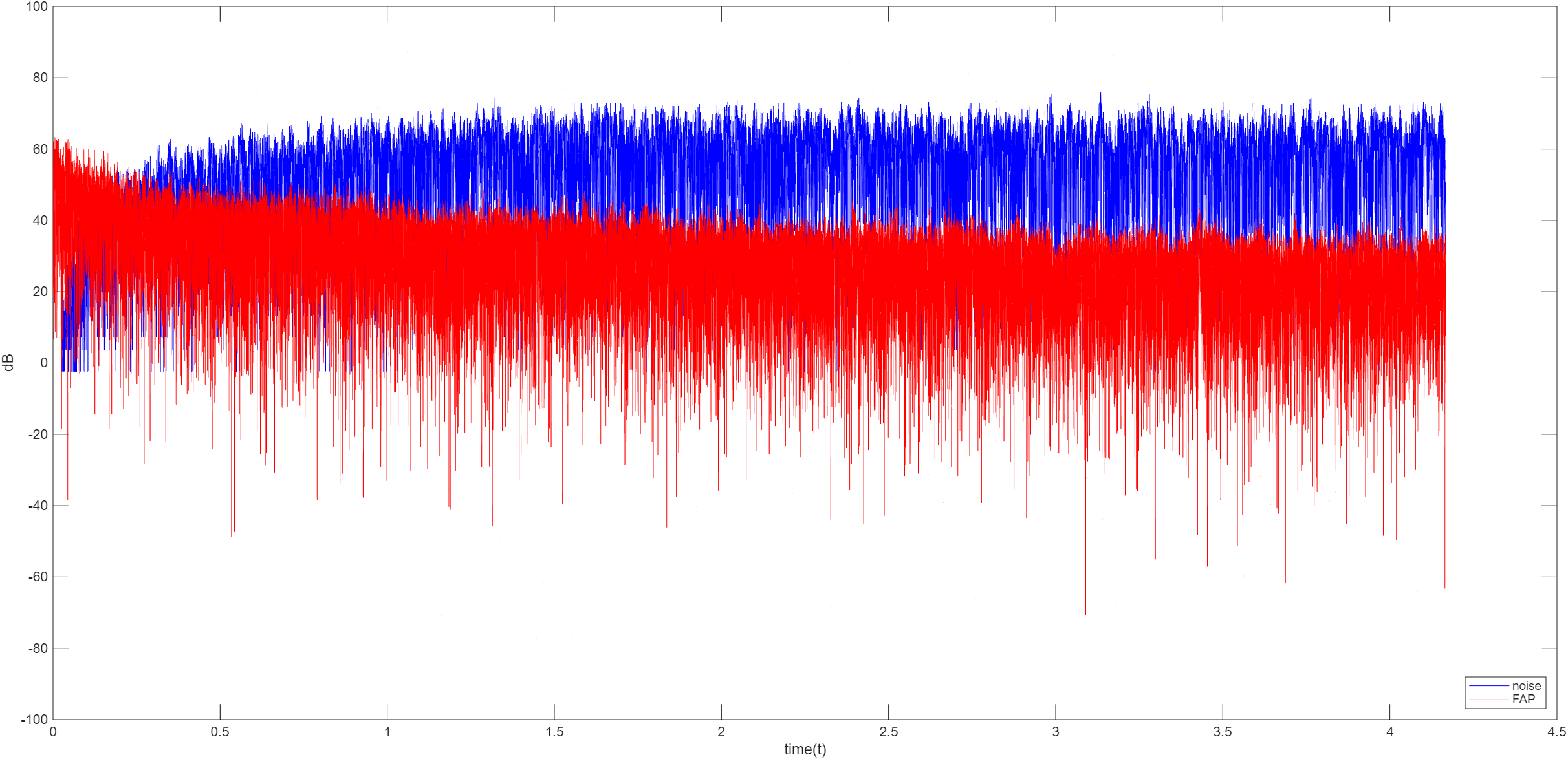
FAP
FAP(Fast Affine Projection Algorithm,快速仿射投影算法) 是标准 APA 算法的高效实现版本,解决了标准 APA 算法中 K × K K\times K K × K O ( L K 2 + K 3 ) O(LK^2+K^3) O ( L K 2 + K 3 ) O ( L + K ) O(L+K) O ( L + K )
残差向量的时间相关性近似
在计算误差向量 e ( n ) e(n) e ( n ) O ( L K ) O(LK) O ( L K ) O ( L + K ) O(L+K) O ( L + K ) e ( n ) e(n) e ( n ) K − 1 K-1 K − 1
e ( n ) = [ d ( n ) − X T ( n ) w ( n − 1 ) D ˉ ( n − 1 ) − M ˉ ( n − 1 ) w ( n − 1 ) ] ∈ R K × 1 e(n)=\begin{bmatrix}d(n)-X^T(n)w(n-1)\\\bar{D}(n-1)-\bar{M}(n-1)w(n-1)\end{bmatrix}\in\R^{K\times1}
e ( n ) = [ d ( n ) − X T ( n ) w ( n − 1 ) D ˉ ( n − 1 ) − M ˉ ( n − 1 ) w ( n − 1 ) ] ∈ R K × 1
其中 M ˉ ( n − 1 ) \bar{M}(n-1) M ˉ ( n − 1 ) M ( n − 1 ) M(n-1) M ( n − 1 ) n − 1 n-1 n − 1 D ˉ ( n − 1 ) \bar{D}(n-1) D ˉ ( n − 1 ) D ( n − 1 ) D(n-1) D ( n − 1 ) n − 1 n-1 n − 1 e 1 ( n − 1 ) e_1(n-1) e 1 ( n − 1 ) n − 1 n-1 n − 1 w ( n ) w(n) w ( n )
e 1 ( n ) = D ( n ) − M T ( n ) ( w ( n − 1 ) + μ M ( n ) R − 1 ( n ) e ( n ) ) = D ( n ) − M T ( n ) w ( n − 1 ) − μ M T ( n ) M ( n ) R − 1 e ( n ) = e ( n ) − μ M T ( n ) M ( n ) R − 1 ( n ) e ( n ) = ( I − μ M T ( n ) M ( n ) ( M T ( n ) M ( n ) + δ I ) − 1 ) e ( n ) e_1(n)=D(n)-M^T(n)\Big(w(n-1)+\mu M(n)R^{-1}(n)e(n)\Big)\\=D(n)-M^T(n)w(n-1)-\mu M^T(n)M(n)R^{-1}e(n)\\=e(n)-\mu M^T(n)M(n)R^{-1}(n)e(n)\\=\Big(I-\mu M^T(n)M(n)\big(M^T(n)M(n)+\delta I\big)^{-1}\Big)e(n)
e 1 ( n ) = D ( n ) − M T ( n ) ( w ( n − 1 ) + μ M ( n ) R − 1 ( n ) e ( n ) ) = D ( n ) − M T ( n ) w ( n − 1 ) − μ M T ( n ) M ( n ) R − 1 e ( n ) = e ( n ) − μ M T ( n ) M ( n ) R − 1 ( n ) e ( n ) = ( I − μ M T ( n ) M ( n ) ( M T ( n ) M ( n ) + δ I ) − 1 ) e ( n )
对自相关矩阵 M T ( n ) M ( n ) M^T(n)M(n) M T ( n ) M ( n )
M T ( n ) M ( n ) = V ( n ) Λ ( n ) V T ( n ) M^T(n)M(n)=V(n)\Lambda(n)V^T(n)
M T ( n ) M ( n ) = V ( n ) Λ ( n ) V T ( n )
其中 V ( n ) V(n) V ( n ) Λ ( n ) \Lambda(n) Λ ( n )
e ′ ( n ) = V T ( n ) e ( n ) e 1 ′ ( n ) = V T ( n ) e 1 ( n ) e^\prime(n)=V^T(n)e(n)\\e_1^\prime(n)=V^T(n)e_1(n)
e ′ ( n ) = V T ( n ) e ( n ) e 1 ′ ( n ) = V T ( n ) e 1 ( n )
将上述模态残差和特征值分解带入上述的后验残差公式中,矩阵运算转化为标量运算,得到每个模态的后验-先验残差关系
e r 1 , i , n − 1 = ( 1 − μ λ i , n − 1 δ + λ i , n − 1 ) e r i , n − 1 er_{1,i,n-1}=\Big(1-\frac{\mu\lambda_{i,n-1}}{\delta+\lambda_{i,n-1}}\Big)er_{i,n-1}
e r 1 , i , n − 1 = ( 1 − δ + λ i , n − 1 μ λ i , n − 1 ) e r i , n − 1
此时分为两种极端情况
当 λ i , n − 1 ≫ δ \lambda_{i,n-1}\gg\delta λ i , n − 1 ≫ δ ≈ 1 − μ \approx1-\mu ≈ 1 − μ
当 λ i , n − 1 ≪ δ \lambda_{i,n-1}\ll\delta λ i , n − 1 ≪ δ ≈ 1 \approx1 ≈ 1
一般来说, δ \delta δ 1 0 − 6 ∼ 1 0 − 3 10^{-6}\sim10^{-3} 1 0 − 6 ∼ 1 0 − 3 1 − μ 1-\mu 1 − μ
e 1 ( n ) ≈ ( 1 − μ ) e ( n ) e_1(n)\approx(1-\mu)e(n)
e 1 ( n ) ≈ ( 1 − μ ) e ( n )
将其带入分块展开式,得到
e ( n ) = [ d ( n ) − X T ( n ) w ( n − 1 ) e ˉ 1 ( n − 1 ) ] = [ e n ( 1 − μ ) e ˉ ( n − 1 ) ] e(n)=\begin{bmatrix}d(n)-X^T(n)w(n-1)\\\bar{e}_1(n-1)\end{bmatrix}=\begin{bmatrix}e_n\\(1-\mu)\bar{e}(n-1)\end{bmatrix}
e ( n ) = [ d ( n ) − X T ( n ) w ( n − 1 ) e ˉ 1 ( n − 1 ) ] = [ e n ( 1 − μ ) e ˉ ( n − 1 ) ]
其中的 e n = d ( n ) − X T ( n ) w ( n − 1 ) e_n=d(n)-X^T(n)w(n-1) e n = d ( n ) − X T ( n ) w ( n − 1 )
权值向量分解和递归
在原始 APA 算法中,权值更新公式 w ( n ) = w ( n − 1 ) + μ M ( n ) R − 1 ( n ) e ( n ) w(n)=w(n-1)+\mu M(n)R^{-1}(n)e(n) w ( n ) = w ( n − 1 ) + μ M ( n ) R − 1 ( n ) e ( n ) O ( L K ) O(LK) O ( L K ) ε ( n ) = R − 1 ( n ) e ( n ) \varepsilon(n)=R^{-1}(n)e(n) ε ( n ) = R − 1 ( n ) e ( n ) w ^ ( n ) \hat{w}(n) w ^ ( n ) E ( n ) E(n) E ( n )
w ( n ) = w ( 0 ) + μ ∑ i = 0 n − 1 M ( n − i ) ϵ ( n − i ) M ( n − i ) ϵ ( n − i ) = ∑ j = 0 K − 1 X ( n − i − j ) ϵ j ( n − i ) w ( n ) = w ( 0 ) + μ ∑ i = 0 n − 1 ∑ j = 0 K − 1 X ( n − i − j ) ϵ j ( n − i ) w(n)=w(0)+\mu\sum_{i=0}^{n-1}M(n-i)\epsilon(n-i)\\M(n-i)\epsilon(n-i)=\sum_{j=0}^{K-1}X(n-i-j)\epsilon_j(n-i)\\w(n)=w(0)+\mu\sum_{i=0}^{n-1}\sum_{j=0}^{K-1}X(n-i-j)\epsilon_j(n-i)
w ( n ) = w ( 0 ) + μ i = 0 ∑ n − 1 M ( n − i ) ϵ ( n − i ) M ( n − i ) ϵ ( n − i ) = j = 0 ∑ K − 1 X ( n − i − j ) ϵ j ( n − i ) w ( n ) = w ( 0 ) + μ i = 0 ∑ n − 1 j = 0 ∑ K − 1 X ( n − i − j ) ϵ j ( n − i )
其中 M ( n − i ) M(n-i) M ( n − i ) n − i n-i n − i ϵ ( n − i ) \epsilon(n-i) ϵ ( n − i ) n − i n-i n − i X ( n − i − j ) X(n-i-j) X ( n − i − j ) n − i − j n-i-j n − i − j ϵ j ( n − i ) \epsilon_j(n-i) ϵ j ( n − i ) n − i n-i n − i ϵ ( n − i ) \epsilon(n-i) ϵ ( n − i ) j j j X ( n − i − j ) ϵ j ( n − i ) X(n-i-j)\epsilon_j(n-i) X ( n − i − j ) ϵ j ( n − i )
w ( n ) = w ( 0 ) + μ ∑ k = 0 K − 1 X ( n − k ) ∑ j = 0 k ϵ j ( n − k + j ) + μ ∑ k = K n − 1 X ( n − K ) ∑ j = 0 K − 1 ϵ j ( n − k + j ) w(n )=w(0)+\mu\sum_{k=0}^{K-1}X(n-k)\sum_{j=0}^k\epsilon_j(n-k+j)+\mu\sum_{k=K}^{n-1}X(n-K)\sum_{j=0}^{K-1}\epsilon_j(n-k+j)
w ( n ) = w ( 0 ) + μ k = 0 ∑ K − 1 X ( n − k ) j = 0 ∑ k ϵ j ( n − k + j ) + μ k = K ∑ n − 1 X ( n − K ) j = 0 ∑ K − 1 ϵ j ( n − k + j )
定义辅助权值向量 w ^ ( n ) \hat{w}(n) w ^ ( n )
w ^ ( n − 1 ) = w ^ ( 0 ) + μ ∑ k = K n − 1 X ( n − K ) ∑ j = 0 K − 1 ϵ j ( n − k + j ) \hat{w}(n-1)=\hat{w}(0)+\mu\sum_{k=K}^{n-1}X(n-K)\sum_{j=0}^{K-1}\epsilon_j(n-k+j)
w ^ ( n − 1 ) = w ^ ( 0 ) + μ k = K ∑ n − 1 X ( n − K ) j = 0 ∑ K − 1 ϵ j ( n − k + j )
包含了所有早于 n − K n-K n − K E ( n ) E(n) E ( n )
E ( n ) = [ ϵ 0 ( n ) ϵ 1 ( n ) + ϵ 0 ( n − 1 ) ⋯ ϵ K − 1 ( n ) + ϵ K − 2 ( n − 1 ) + ⋯ + ϵ 0 ( n − ( K − 1 ) ) ] E(n)=\begin{bmatrix}\epsilon_0(n)\\\epsilon_1(n)+\epsilon_0(n-1)\\\cdots\\\epsilon_{K-1}(n)+\epsilon_{K-2}(n-1)+\cdots+\epsilon_0(n-(K-1))\end{bmatrix}
E ( n ) = ⎣ ⎢ ⎢ ⎢ ⎡ ϵ 0 ( n ) ϵ 1 ( n ) + ϵ 0 ( n − 1 ) ⋯ ϵ K − 1 ( n ) + ϵ K − 2 ( n − 1 ) + ⋯ + ϵ 0 ( n − ( K − 1 ) ) ⎦ ⎥ ⎥ ⎥ ⎤
它是最近 K K K μ M ( n ) E ( n ) \mu M(n)E(n) μ M ( n ) E ( n )
w ( n ) = w ^ ( n − 1 ) + μ M ( n ) E ( n ) w(n)=\hat{w}(n-1)+\mu M(n)E(n)
w ( n ) = w ^ ( n − 1 ) + μ M ( n ) E ( n )
此时权重向量的递归更新变为了辅助权重的递归更新 w ^ ( n ) \hat{w}(n) w ^ ( n )
w ^ ( n ) = w ^ ( n − 1 ) + μ X ( n − ( K − 1 ) ) ∑ j = 0 K − 1 ϵ j ( n − K + 1 + j ) = w ^ ( n − 1 ) + μ X ( n − K + 1 ) E K − 1 ( n ) \hat{w}(n)=\hat{w}(n-1)+\mu X(n-(K-1))\sum_{j=0}^{K-1}\epsilon_j(n-K+1+j)\\=\hat{w}(n-1)+\mu X(n-K+1)E_{K-1}(n)
w ^ ( n ) = w ^ ( n − 1 ) + μ X ( n − ( K − 1 ) ) j = 0 ∑ K − 1 ϵ j ( n − K + 1 + j ) = w ^ ( n − 1 ) + μ X ( n − K + 1 ) E K − 1 ( n )
其中 E K − 1 ( n ) E_{K-1}(n) E K − 1 ( n ) E ( n ) E(n) E ( n ) L L L
w ( n ) = w ^ ( n ) + μ M ˉ ( n ) E ˉ ( n ) w(n)=\hat{w}(n)+\mu \bar{M}(n)\bar{E}(n)
w ( n ) = w ^ ( n ) + μ M ˉ ( n ) E ˉ ( n )
其中 M ˉ ( n ) \bar{M}(n) M ˉ ( n ) M ( n ) M(n) M ( n ) K − 1 K-1 K − 1 E ˉ ( n ) \bar{E}(n) E ˉ ( n ) E ( n ) E(n) E ( n ) K − 1 K-1 K − 1 E ( n ) E(n) E ( n ) E ( n ) E(n) E ( n ) k k k ϵ k ( n ) \epsilon_{k}(n) ϵ k ( n ) E ( n − 1 ) E(n-1) E ( n − 1 ) k − 1 k-1 k − 1 ϵ 0 ( n ) \epsilon_0(n) ϵ 0 ( n )
E ( n ) = ϵ ( n ) + [ 0 E ˉ ( n − 1 ) ] E(n)=\epsilon(n)+\begin{bmatrix}0\\\bar{E}(n-1)\end{bmatrix}
E ( n ) = ϵ ( n ) + [ 0 E ˉ ( n − 1 ) ]
其中 E ˉ ( n − 1 ) \bar{E}(n-1) E ˉ ( n − 1 ) E ( n − 1 ) E(n-1) E ( n − 1 ) K − 1 K-1 K − 1 K K K w ( n ) = w ^ ( n − 1 ) + μ X ( n ) E ( n ) w(n)=\hat{w}(n-1)+\mu X(n)E(n) w ( n ) = w ^ ( n − 1 ) + μ X ( n ) E ( n ) e n = d ( n ) − X T ( n ) w ( n − 1 ) e_n=d(n)-X^T(n)w(n-1) e n = d ( n ) − X T ( n ) w ( n − 1 )
e n = d ( n ) − X T ( n ) ( w ^ ( n − 1 ) + μ M ˉ ( n − 1 ) E ˉ ( n − 1 ) ) = e ^ n − μ R x x ( n ) E ˉ ( n − 1 ) e_n=d(n)-X^T(n)\Big(\hat{w}(n-1)+\mu \bar{M}(n-1)\bar{E}(n-1)\Big)\\=\hat{e}_n-\mu R_{xx}(n)\bar{E}(n-1)
e n = d ( n ) − X T ( n ) ( w ^ ( n − 1 ) + μ M ˉ ( n − 1 ) E ˉ ( n − 1 ) ) = e ^ n − μ R x x ( n ) E ˉ ( n − 1 )
其中 e ^ n = d ( n ) − X T ( n ) w ^ ( n − 1 ) \hat{e}_n=d(n)-X^T(n)\hat{w}(n-1) e ^ n = d ( n ) − X T ( n ) w ^ ( n − 1 ) R x x ( n ) = [ r x x , n ( 1 ) ⋯ r x x , n ( K − 1 ) ] T R_{xx}(n)=\begin{bmatrix}r_{xx,n}(1)&\cdots&r_{xx,n}(K-1)\end{bmatrix}^T R x x ( n ) = [ r x x , n ( 1 ) ⋯ r x x , n ( K − 1 ) ] T r x x , n ( k ) r_{xx,n}(k) r x x , n ( k ) k k k R x x ( n ) R_{xx}(n) R x x ( n )
R x x ( n ) = R x x ( n − 1 ) + x ( n ) α ( n ) − x ( n − L ) α ( n − L ) R_{xx}(n)=R_{xx}(n-1)+x(n)\alpha(n)-x(n-L)\alpha(n-L)
R x x ( n ) = R x x ( n − 1 ) + x ( n ) α ( n ) − x ( n − L ) α ( n − L )
其中的 α ( n ) = [ x ( n − 1 ) ⋯ x ( n − K + 1 ) ] T \alpha(n)=\begin{bmatrix}x(n-1)&\cdots&x(n-K+1)\end{bmatrix}^T α ( n ) = [ x ( n − 1 ) ⋯ x ( n − K + 1 ) ] T 2 N 2N 2 N
近似 Toeplitz 矩阵的快速求逆
另外上述公式中用到了 ϵ ( n ) = ( M T ( n ) M ( n ) + δ I ) − 1 e ( n ) \epsilon(n)=\Big(M^T(n)M(n)+\delta I\Big)^{-1}e(n) ϵ ( n ) = ( M T ( n ) M ( n ) + δ I ) − 1 e ( n ) O ( K 3 ) O(K^3) O ( K 3 ) R ( n ) = M T ( n ) M ( n ) + δ I R(n)=M^T(n)M(n)+\delta I R ( n ) = M T ( n ) M ( n ) + δ I K × K K\times K K × K a ( n ) a(n) a ( n ) R ( n ) R(n) R ( n ) b ( n ) b(n) b ( n ) E a ( n ) E_{a}(n) E a ( n ) E b ( n ) E_b(n) E b ( n ) R ( n ) R(n) R ( n ) R ˉ ( n ) \bar{R}(n) R ˉ ( n ) R ( n ) R(n) R ( n ) ( K − 1 ) × ( K − 1 ) (K-1)\times(K-1) ( K − 1 ) × ( K − 1 ) R ~ ( n ) \tilde{R}(n) R ~ ( n ) R ( n ) R(n) R ( n ) ( K − 1 ) × ( K − 1 ) (K-1)\times(K-1) ( K − 1 ) × ( K − 1 )
R − 1 ( n ) = [ R ˉ − 1 ( n ) 0 0 T 0 ] + 1 E b ( n ) b ( n ) b T ( n ) R − 1 ( n ) = [ 0 0 T 0 R ~ − 1 ( n ) ] + 1 E a ( n ) a ( n ) a T ( n ) R^{-1}(n)=\begin{bmatrix}\bar{R}^{-1}(n)&0\\0^T&0\end{bmatrix}+\frac{1}{E_{b}(n)}b(n)b^T(n)\\R^{-1}(n)=\begin{bmatrix}0&0^T\\0&\tilde{R}^{-1}(n)\end{bmatrix}+\frac{1}{E_{a}(n)}a(n)a^T(n)
R − 1 ( n ) = [ R ˉ − 1 ( n ) 0 T 0 0 ] + E b ( n ) 1 b ( n ) b T ( n ) R − 1 ( n ) = [ 0 0 0 T R ~ − 1 ( n ) ] + E a ( n ) 1 a ( n ) a T ( n )
可以得知 R − 1 ( n ) R^{-1}(n) R − 1 ( n ) ( K − 1 ) (K-1) ( K − 1 )
ϵ ~ ( n ) = R ~ − 1 ( n ) e ~ ( n ) ϵ ˉ ( n ) = R ˉ − 1 ( n ) e ˉ ( n ) \tilde{\epsilon}(n)=\tilde{R}^{-1}(n)\tilde{e}(n)\\\bar{\epsilon}(n)=\bar{R}^{-1}(n)\bar{e}(n)
ϵ ~ ( n ) = R ~ − 1 ( n ) e ~ ( n ) ϵ ˉ ( n ) = R ˉ − 1 ( n ) e ˉ ( n )
其中 e ~ ( n ) \tilde{e}(n) e ~ ( n ) e ( n ) e(n) e ( n ) K − 1 K-1 K − 1 e ˉ ( n ) \bar{e}(n) e ˉ ( n ) e ( n ) e(n) e ( n ) K − 1 K-1 K − 1 e ( n ) e(n) e ( n )
R − 1 ( n ) e ( n ) = [ ϵ ˉ ( n ) 0 ] + 1 E b ( n ) b ( n ) b T ( n ) e ( n ) R − 1 ( n ) e ( n ) = [ 0 ϵ ~ ( n ) ] + 1 E a ( n ) a ( n ) a T ( n ) e ( n ) R^{-1}(n)e(n)=\begin{bmatrix}\bar{\epsilon}(n)\\0\end{bmatrix}+\frac{1}{E_{b}(n)}b(n)b^T(n)e(n)\\R^{-1}(n)e(n)=\begin{bmatrix}0\\\tilde{\epsilon}(n)\end{bmatrix}+\frac{1}{E_{a}(n)}a(n)a^T(n)e(n)
R − 1 ( n ) e ( n ) = [ ϵ ˉ ( n ) 0 ] + E b ( n ) 1 b ( n ) b T ( n ) e ( n ) R − 1 ( n ) e ( n ) = [ 0 ϵ ~ ( n ) ] + E a ( n ) 1 a ( n ) a T ( n ) e ( n )
由于滑动窗口结构 R ~ ( n ) = R ˉ ( n − 1 ) \tilde{R}(n)=\bar{R}(n-1) R ~ ( n ) = R ˉ ( n − 1 ) e ~ ( n ) = ( 1 − μ ) e ˉ ( n − 1 ) \tilde{e}(n)=(1-\mu)\bar{e}(n-1) e ~ ( n ) = ( 1 − μ ) e ˉ ( n − 1 )
ϵ ~ ( n ) = R ~ − 1 ( n ) e ~ ( n ) = R ˉ − 1 ( n − 1 ) ( 1 − μ ) e ˉ ( n − 1 ) = ( 1 − μ ) ϵ ˉ ( n − 1 ) \tilde{\epsilon}(n)=\tilde{R}^{-1}(n)\tilde{e}(n)=\bar{R}^{-1}(n-1)(1-\mu)\bar{e}(n-1)\\=(1-\mu)\bar{\epsilon}(n-1)
ϵ ~ ( n ) = R ~ − 1 ( n ) e ~ ( n ) = R ˉ − 1 ( n − 1 ) ( 1 − μ ) e ˉ ( n − 1 ) = ( 1 − μ ) ϵ ˉ ( n − 1 )
这个公式让 ϵ ( n ) \epsilon(n) ϵ ( n )
整体流程
将上述所有公式整理一下,得到如下的 FAP 算法流程
初始化
初始化 E a ( 0 ) = E b ( 0 ) = δ E_{a}(0)=E_b(0)=\delta E a ( 0 ) = E b ( 0 ) = δ
初始化 a ( 0 ) = [ 1 0 ⃗ T ] ∈ R K × 1 a(0)=\begin{bmatrix}1&\vec{0}^T\end{bmatrix}\in\R^{K\times1} a ( 0 ) = [ 1 0 T ] ∈ R K × 1
初始化 b ( 0 ) = [ 0 ⃗ T 1 ] ∈ R K × 1 b(0)=\begin{bmatrix}\vec{0}^T&1\end{bmatrix}\in\R^{K\times1} b ( 0 ) = [ 0 T 1 ] ∈ R K × 1
初始化 w ^ ( 0 ) = 0 ⃗ ∈ R L × 1 \hat{w}(0)=\vec{0}\in\R^{L\times1} w ^ ( 0 ) = 0 ∈ R L × 1
初始化 e ( 0 ) = 0 ⃗ ∈ R K × 1 e(0)=\vec{0}\in\R^{K\times1} e ( 0 ) = 0 ∈ R K × 1
初始化 ϵ ( 0 ) = 0 ⃗ ∈ R K × 1 \epsilon(0)=\vec{0}\in\R^{K\times1} ϵ ( 0 ) = 0 ∈ R K × 1
初始化 E ( 0 ) = 0 ⃗ ∈ R K × 1 E(0)=\vec{0}\in\R^{K\times1} E ( 0 ) = 0 ∈ R K × 1
初始化 R x x ( 0 ) = 0 ⃗ ∈ R ( K − 1 ) × 1 R_{xx}(0)=\vec{0}\in\R^{(K-1)\times1} R x x ( 0 ) = 0 ∈ R ( K − 1 ) × 1
利用
计算先验前向预测误差 e f ( n ) = x ( n ) + a T ( n − 1 ) X ~ ( n − 1 ) e_f(n)=x(n)+a^T(n-1)\tilde{X}(n-1) e f ( n ) = x ( n ) + a T ( n − 1 ) X ~ ( n − 1 ) X ~ = [ x ( n − 1 ) ⋯ x ( n − K ) ] \tilde{X}=\begin{bmatrix}x(n-1)&\cdots&x(n-K)\end{bmatrix} X ~ = [ x ( n − 1 ) ⋯ x ( n − K ) ]
更新前向预测器 a ( 1 ) ( n ) = [ 1 a ˉ ( n − 1 ) ] + e f ( n ) E b ( n − 1 ) [ 0 b ˉ ( n − 1 ) ] a^{(1)}(n)=\begin{bmatrix}1\\\bar{a}(n-1)\end{bmatrix}+\frac{e_f(n)}{E_b(n-1)}\begin{bmatrix}0\\\bar{b}(n-1)\end{bmatrix} a ( 1 ) ( n ) = [ 1 a ˉ ( n − 1 ) ] + E b ( n − 1 ) e f ( n ) [ 0 b ˉ ( n − 1 ) ] a ˉ ( n − 1 ) \bar{a}(n-1) a ˉ ( n − 1 ) b ˉ ( n − 1 ) \bar{b}(n-1) b ˉ ( n − 1 ) a ( n − 1 ) a(n-1) a ( n − 1 ) b ( n − 1 ) b(n-1) b ( n − 1 )
更新前向预测误差能量 E a ( 1 ) ( n ) = E a ( n − 1 ) + e f 2 E b ( n − 1 ) E_a^{(1)}(n)=E_a(n-1)+\frac{e_f^2}{E_{b}(n-1)} E a ( 1 ) ( n ) = E a ( n − 1 ) + E b ( n − 1 ) e f 2
计算先验后向预测误差 e b ( n ) = x ( n − K ) + b T ( n − 1 ) X ~ ( n ) e_b(n)=x(n-K)+b^T(n-1)\tilde{X}(n) e b ( n ) = x ( n − K ) + b T ( n − 1 ) X ~ ( n )
更新后向预测其 b ( 1 ) ( n ) = [ 0 b ˉ ( n − 1 ) ] + e b ( n ) E a ( 1 ) ( n ) [ 0 a ˉ ( n − 1 ) ] b^{(1)}(n)=\begin{bmatrix}0\\\bar{b}(n-1)\end{bmatrix}+\frac{e_b(n)}{E^{(1)}_a(n)}\begin{bmatrix}0\\\bar{a}(n-1)\end{bmatrix} b ( 1 ) ( n ) = [ 0 b ˉ ( n − 1 ) ] + E a ( 1 ) ( n ) e b ( n ) [ 0 a ˉ ( n − 1 ) ]
更新后向预测误差能量 E b ( 1 ) ( n ) = E b ( n − 1 ) + e b 2 E a ( 1 ) ( n ) E^{(1)}_b(n)=E_b(n-1)+\frac{e_b^2}{E^{(1)}_a(n)} E b ( 1 ) ( n ) = E b ( n − 1 ) + E a ( 1 ) ( n ) e b 2
剔除最旧样本 a ( n ) = a ( 1 ) ( n ) − a K ( 1 ) ( n ) E b ( 1 ) ( n ) b ( 1 ) ( n ) a(n)=a^{(1)}(n)-\frac{a_K^{(1)}(n)}{E_b^{(1)}(n)}b^{(1)}(n) a ( n ) = a ( 1 ) ( n ) − E b ( 1 ) ( n ) a K ( 1 ) ( n ) b ( 1 ) ( n ) a K ( 1 ) ( n ) a_K^{(1)}(n) a K ( 1 ) ( n ) a ( 1 ) ( n ) a^{(1)}(n) a ( 1 ) ( n ) K K K
剔除最旧样本 E a ( n ) = E a ( 1 ) ( n ) − ( a K ( 1 ) ( n ) ) 2 E b ( 1 ) ( n ) E_a(n)=E^{(1)}_a(n)-\frac{(a_K^{(1)}(n))^2}{E_b^{(1)}(n)} E a ( n ) = E a ( 1 ) ( n ) − E b ( 1 ) ( n ) ( a K ( 1 ) ( n ) ) 2
剔除最旧样本 b ( n ) = b ( 1 ) ( n ) − b 1 ( 1 ) ( n ) E a ( n ) a ( n ) b(n)=b^{(1)}(n)-\frac{b^{(1)}_1(n)}{E_a(n)}a(n) b ( n ) = b ( 1 ) ( n ) − E a ( n ) b 1 ( 1 ) ( n ) a ( n ) b 1 ( n ) b_1(n) b 1 ( n ) b ( n ) b(n) b ( n )
剔除最旧样本 E b ( n ) = E b ( 1 ) ( n ) − ( b 1 ( 1 ) ( n ) ) 2 E a ( n ) E_b(n)=E^{(1)}_b(n)-\frac{(b_1^{(1)}(n))^2}{E_a(n)} E b ( n ) = E b ( 1 ) ( n ) − E a ( n ) ( b 1 ( 1 ) ( n ) ) 2
更新输入相关向量 R x x ( n ) = R x x ( n − 1 ) + x ( n ) α ( n ) − x ( n − L ) α ( n − L ) R_{xx}(n)=R_{xx}(n-1)+x(n)\alpha(n)-x(n-L)\alpha(n-L) R x x ( n ) = R x x ( n − 1 ) + x ( n ) α ( n ) − x ( n − L ) α ( n − L ) α ( n ) = [ x ( n − 1 ) ⋯ x ( n − K + 1 ) ] \alpha(n)=\begin{bmatrix}x(n-1)&\cdots&x(n-K+1)\end{bmatrix} α ( n ) = [ x ( n − 1 ) ⋯ x ( n − K + 1 ) ]
计算辅助残差 e ^ n = d ( n ) − X T ( n ) w ^ ( n − 1 ) \hat{e}_n=d(n)-X^T(n)\hat{w}(n-1) e ^ n = d ( n ) − X T ( n ) w ^ ( n − 1 )
计算标量残差 e n = e ^ n − μ R x x T ( n ) E ˉ ( n − 1 ) e_n=\hat{e}_n-\mu R^T_{xx}(n)\bar{E}(n-1) e n = e ^ n − μ R x x T ( n ) E ˉ ( n − 1 )
更新残差向量 e ( n ) = [ e n ( 1 − μ ) e ˉ ( n − 1 ) ] e(n)=\begin{bmatrix}e_n\\(1-\mu)\bar{e}(n-1)\end{bmatrix} e ( n ) = [ e n ( 1 − μ ) e ˉ ( n − 1 ) ]
计算归一化残差 ϵ ( n ) = R − 1 ( n ) e ( n ) = [ 0 ϵ ~ ( n ) ] + 1 E a ( n ) a ( n ) a T ( n ) e ( n ) \epsilon(n)=R^{-1}(n)e(n)=\begin{bmatrix}0\\\tilde{\epsilon}(n)\end{bmatrix}+\frac{1}{E_{a}(n)}a(n)a^T(n)e(n) ϵ ( n ) = R − 1 ( n ) e ( n ) = [ 0 ϵ ~ ( n ) ] + E a ( n ) 1 a ( n ) a T ( n ) e ( n )
计算 [ ϵ ˉ ( n ) 0 ] = ϵ ( n ) − 1 E b ( n ) b ( n ) b T ( n ) e ( n ) \begin{bmatrix}\bar{\epsilon}(n)\\0\end{bmatrix}=\epsilon(n)-\frac{1}{E_b(n)}b(n)b^T(n)e(n) [ ϵ ˉ ( n ) 0 ] = ϵ ( n ) − E b ( n ) 1 b ( n ) b T ( n ) e ( n )
更新累积向量 E ( n ) = [ 0 E ˉ ( n − 1 ) ] + ϵ ( n ) E(n)=\begin{bmatrix}0\\\bar{E}(n-1)\end{bmatrix}+\epsilon(n) E ( n ) = [ 0 E ˉ ( n − 1 ) ] + ϵ ( n )
更新辅助权值 w ^ ( n ) = w ^ ( n − 1 ) + μ X ( n − K + 1 ) E K − 1 ( n ) \hat{w}(n)=\hat{w}(n-1)+\mu X(n-K+1)E_{K-1}(n) w ^ ( n ) = w ^ ( n − 1 ) + μ X ( n − K + 1 ) E K − 1 ( n )
递推下一时刻的 ϵ ~ ( n + 1 ) = ( 1 − μ ) ϵ ˉ ( n ) \tilde{\epsilon}(n+1)=(1-\mu)\bar{\epsilon}(n) ϵ ~ ( n + 1 ) = ( 1 − μ ) ϵ ˉ ( n )
精确递归
上述的方法就是近似 M T ( n ) M ( n ) ≈ T o e p l i t z M a t r i x M^T(n)M(n)\approx Toeplitz Matrix M T ( n ) M ( n ) ≈ T o e p l i t z M a t r i x
定义输入矩阵 M ( n ) = [ X ( n ) X ( n − 1 ) ⋯ X ( n − L + 1 ) ] M(n)=\begin{bmatrix}X(n)&X(n-1)&\cdots&X(n-L+1)\end{bmatrix} M ( n ) = [ X ( n ) X ( n − 1 ) ⋯ X ( n − L + 1 ) ] G ( n ) G(n) G ( n )
G ( n ) = M T ( n ) M ( n ) + δ I G ( n − 1 ) = M T ( n − 1 ) M ( n − 1 ) + δ I G(n)=M^T(n)M(n)+\delta I\\G(n-1)=M^T(n-1)M(n-1)+\delta I
G ( n ) = M T ( n ) M ( n ) + δ I G ( n − 1 ) = M T ( n − 1 ) M ( n − 1 ) + δ I
根据输入矩阵的滑动,可以得到 G ( n ) G(n) G ( n ) ( L − 1 ) × ( L − 1 ) (L-1)\times(L-1) ( L − 1 ) × ( L − 1 ) G ( n − 1 ) G(n-1) G ( n − 1 ) ( L − 1 ) × ( L − 1 ) (L-1)\times(L-1) ( L − 1 ) × ( L − 1 ) G ( n ) G(n) G ( n )
G ( n ) = [ a ( n ) b T ( n ) b ( n ) C ( n − 1 ) ] a ( n ) = X T ( n ) X ( n ) + δ b ( n ) = [ X T ( n ) X ( n − 1 ) X T ( n ) X ( n − 2 ) ⋮ X T ( n ) X ( n − L + 1 ) ] G ( n − 1 ) = [ C ( n − 1 ) h T ( n ) h ( n ) γ ( n ) ] G(n)=\begin{bmatrix}a(n)&b^T(n)\\b(n)&C(n-1)\end{bmatrix}\\a(n)=X^T(n)X(n)+\delta\\b(n)=\begin{bmatrix}X^T(n)X(n-1)\\X^T(n)X(n-2)\\\vdots\\X^T(n)X(n-L+1)\end{bmatrix}\\G(n-1)=\begin{bmatrix}C(n-1)&h^T(n)\\h(n)&\gamma(n)\end{bmatrix}
G ( n ) = [ a ( n ) b ( n ) b T ( n ) C ( n − 1 ) ] a ( n ) = X T ( n ) X ( n ) + δ b ( n ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ X T ( n ) X ( n − 1 ) X T ( n ) X ( n − 2 ) ⋮ X T ( n ) X ( n − L + 1 ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ G ( n − 1 ) = [ C ( n − 1 ) h ( n ) h T ( n ) γ ( n ) ]
假设已有 R ( n − 1 ) = G − 1 ( n − 1 ) R(n-1)=G^{-1}(n-1) R ( n − 1 ) = G − 1 ( n − 1 )
R ( n − 1 ) = [ R 11 ( n − 1 ) R 12 ( n − 1 ) R 21 ( n − 1 ) R 22 ( n − 1 ) ] R(n-1)=\begin{bmatrix}R_{11}(n-1)&R_{12}(n-1)\\R_{21}(n-1)&R_{22}(n-1)\end{bmatrix}
R ( n − 1 ) = [ R 1 1 ( n − 1 ) R 2 1 ( n − 1 ) R 1 2 ( n − 1 ) R 2 2 ( n − 1 ) ]
其中 R 11 ( n ) ∈ R ( K − 1 ) × ( K − 1 ) R_{11}(n)\in \R^{(K-1)\times(K-1)} R 1 1 ( n ) ∈ R ( K − 1 ) × ( K − 1 )
C − 1 ( n − 1 ) = R 11 ( n − 1 ) − R 12 ( n − 1 ) R 22 − 1 ( n − 1 ) R 21 ( n − 1 ) C^{-1}(n-1)=R_{11}(n-1)-R_{12}(n-1)R_{22}^{-1}(n-1)R_{21}(n-1)
C − 1 ( n − 1 ) = R 1 1 ( n − 1 ) − R 1 2 ( n − 1 ) R 2 2 − 1 ( n − 1 ) R 2 1 ( n − 1 )
由于 G ( n − 1 ) G(n-1) G ( n − 1 ) R 21 ( n − 1 ) = R 12 T ( n − 1 ) R_{21}(n-1)=R_{12}^T(n-1) R 2 1 ( n − 1 ) = R 1 2 T ( n − 1 )
C − 1 ( n − 1 ) = R 11 ( n − 1 ) − R 12 ( n − 1 ) R 12 T ( n − 1 ) R 22 ( n − 1 ) C^{-1}(n-1)=R_{11}(n-1)-\frac{R_{12}(n-1)R_{12}^T(n-1)}{R_{22}(n-1)}
C − 1 ( n − 1 ) = R 1 1 ( n − 1 ) − R 2 2 ( n − 1 ) R 1 2 ( n − 1 ) R 1 2 T ( n − 1 )
然后构造 G − 1 ( n ) G^{-1}(n) G − 1 ( n ) C − 1 ( n − 1 ) C^{-1}(n-1) C − 1 ( n − 1 ) α = a − b T C − 1 b \alpha=a-b^TC^{-1}b α = a − b T C − 1 b
G − 1 ( n ) = [ 1 α − 1 α b T C − 1 − 1 α C − 1 b C − 1 + 1 α C − 1 b b T C − 1 ] G^{-1}(n)=\begin{bmatrix}\frac{1}{\alpha}&-\frac{1}{\alpha}b^TC^{-1}\\-\frac{1}{\alpha}C^{-1}b&C^{-1}+\frac{1}{\alpha}C^{-1}bb^TC^{-1}\end{bmatrix}
G − 1 ( n ) = [ α 1 − α 1 C − 1 b − α 1 b T C − 1 C − 1 + α 1 C − 1 b b T C − 1 ]
此时就不需要每次都重新求逆,而是利用上一时刻的逆矩阵递推得到下一时刻的逆矩阵。之后计算 b ( n ) b(n) b ( n ) b ( n ) b(n) b ( n )
X T ( n ) X ( n − i ) = ∑ m = 0 K − 1 x ( n + 1 − m ) x ( n − i − m ) X^T(n)X(n-i)=\sum_{m=0}^{K-1}x(n+1-m)x(n-i-m)
X T ( n ) X ( n − i ) = m = 0 ∑ K − 1 x ( n + 1 − m ) x ( n − i − m )
这些内积也可以利用滑动窗口递推,定义 ρ i ( n ) = X T ( n ) X ( n − i ) \rho_i(n)=X^T(n)X(n-i) ρ i ( n ) = X T ( n ) X ( n − i )
ρ i ( n ) = ρ i ( n − 1 ) + x ( n ) x ( n − i ) − x ( n − K ) x ( n − i − K ) \rho_i(n)=\rho_i(n-1)+x(n)x(n-i)-x(n-K)x(n-i-K)
ρ i ( n ) = ρ i ( n − 1 ) + x ( n ) x ( n − i ) − x ( n − K ) x ( n − i − K )
因此有
b ( n ) = [ ρ 1 ( n ) ρ 2 ( n ) ⋯ ρ K − 1 ( n ) ] a ( n ) = ρ 0 ( n ) + δ b(n)=\begin{bmatrix}\rho_1(n)&\rho_2(n)&\cdots&\rho_{K-1}(n)\end{bmatrix}\\a(n)=\rho_0(n)+\delta
b ( n ) = [ ρ 1 ( n ) ρ 2 ( n ) ⋯ ρ K − 1 ( n ) ] a ( n ) = ρ 0 ( n ) + δ
则可计算出 R ( n ) R(n) R ( n ) ϵ ( n ) = R ( n ) e ( n ) \epsilon(n)=R(n)e(n) ϵ ( n ) = R ( n ) e ( n )
w ( n + 1 ) = w ( n ) + μ M ( n ) ϵ ( n ) w(n+1)=w(n)+\mu M(n)\epsilon(n)
w ( n + 1 ) = w ( n ) + μ M ( n ) ϵ ( n )
整体的计算复杂度约为 O ( K 2 + K ) O(K^2+K) O ( K 2 + K )
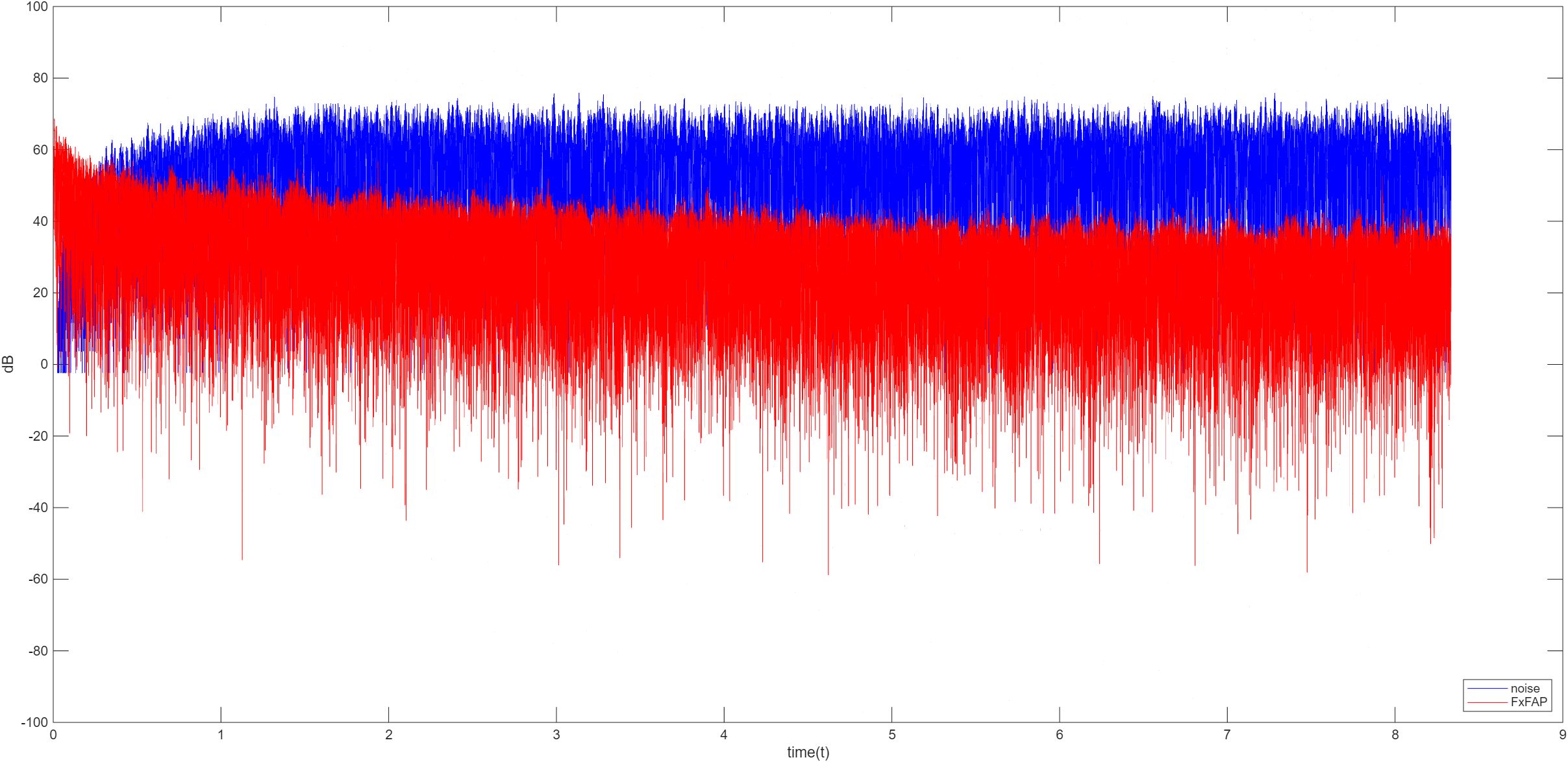
FxFAP
将 FAP 算法应用到 ANC 中,将参考信号 x ( n ) x(n) x ( n ) x f ( n ) x_f(n) x f ( n )
x f ( n ) = s ^ T X ( n ) X f ( n ) = [ x f ( n ) ⋮ x f ( n − L + 1 ) ] M = [ X f ( n ) X f ( n − 1 ) ⋯ X f ( n − K + 1 ) ] d f ( n ) = s T D ( n ) D f = [ d f ( n ) ⋮ d f ( n − L + 1 ) ] y ( n ) = X T ( n ) w ( n − 1 ) Y ( n ) = [ y ( n ) ⋮ y ( n − L + 1 ) ] x_f(n)=\hat{s}^TX(n)\\X_f(n)=\begin{bmatrix}x_f(n)\\\vdots\\x_f(n-L+1)\end{bmatrix}\\M=\begin{bmatrix}X_f(n)&X_f(n-1)&\cdots&X_f(n-K+1)\end{bmatrix}\\d_f(n)=s^TD(n)\\D_f=\begin{bmatrix}d_f(n)\\\vdots\\d_f(n-L+1)\end{bmatrix}\\y(n)=X^T(n)w(n-1)\\Y(n)=\begin{bmatrix}y(n)\\\vdots\\y(n-L+1)\end{bmatrix}
x f ( n ) = s ^ T X ( n ) X f ( n ) = ⎣ ⎢ ⎢ ⎡ x f ( n ) ⋮ x f ( n − L + 1 ) ⎦ ⎥ ⎥ ⎤ M = [ X f ( n ) X f ( n − 1 ) ⋯ X f ( n − K + 1 ) ] d f ( n ) = s T D ( n ) D f = ⎣ ⎢ ⎢ ⎡ d f ( n ) ⋮ d f ( n − L + 1 ) ⎦ ⎥ ⎥ ⎤ y ( n ) = X T ( n ) w ( n − 1 ) Y ( n ) = ⎣ ⎢ ⎢ ⎡ y ( n ) ⋮ y ( n − L + 1 ) ⎦ ⎥ ⎥ ⎤
另外误差的公式为 e ^ ( n ) = s T ( D f ( n ) − s T Y ) \hat{e}(n)=s^T\Big(D_f(n)-s^TY\Big) e ^ ( n ) = s T ( D f ( n ) − s T Y ) w ^ = w ^ + μ X f ( n − K + 1 ) E ( n − K + 1 ) \hat{w}=\hat{w}+\mu X_f(n-K+1)E(n-K+1) w ^ = w ^ + μ X f ( n − K + 1 ) E ( n − K + 1 )
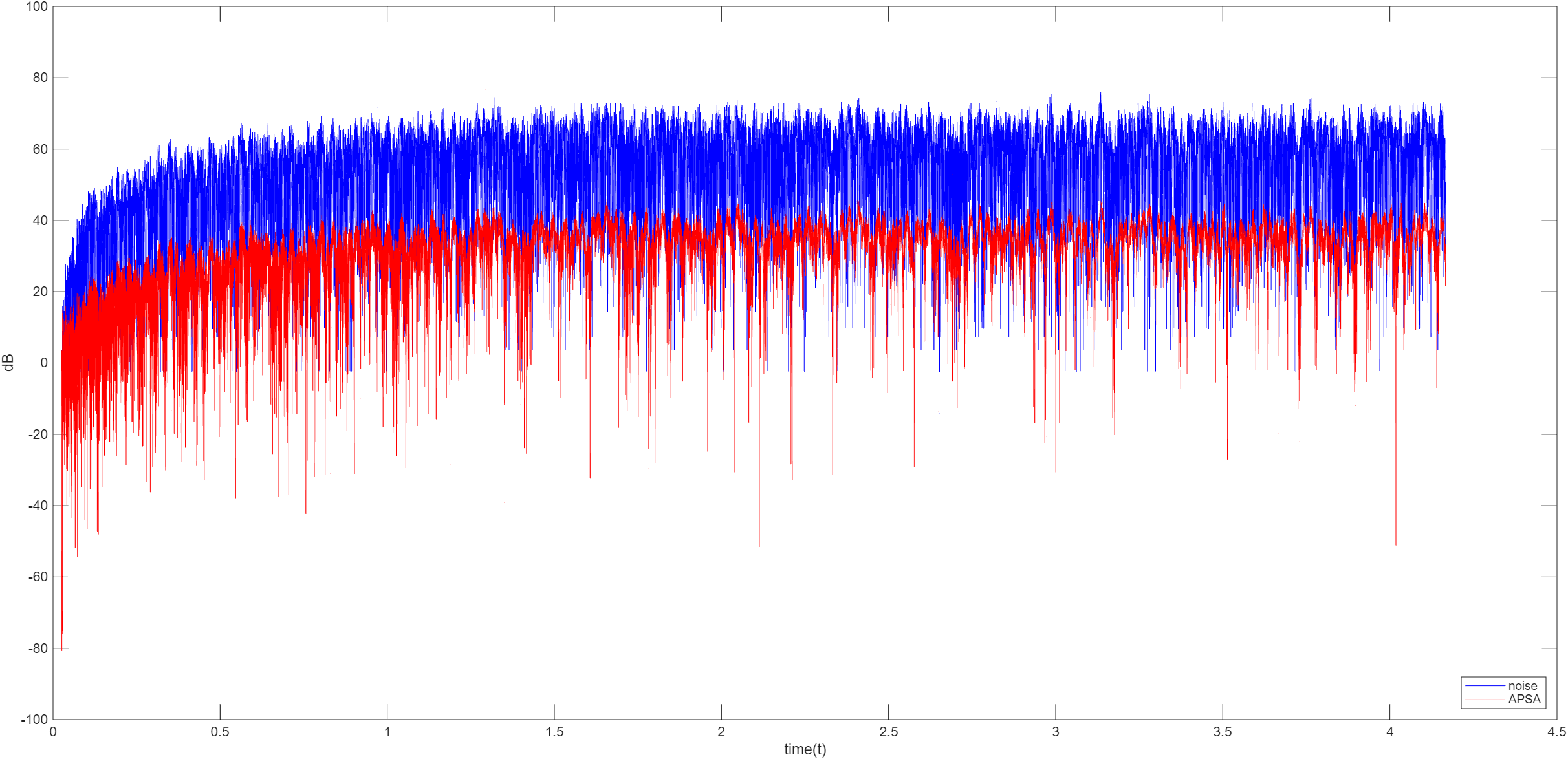
APSA
APSA (Affine Projection Sign Algorithm,仿射投影符号算法) 是一种广泛用于自适应滤波领域的算法,结合了仿射投影算法对有色输入信号的快速收敛特性和符号算法对脉冲噪声的鲁棒性,也避免了 APA 复杂的矩阵求逆运算,计算复杂度降低
APSA 基于 L1 范数优化准则,通过最小化后验误差向量的 L1 范数,同时满足权重向量变化量的 L2 范数约束来更新滤波器系数。定义先验误差向量和后验误差向量
e ( n ) = D ( n ) − M T ( n ) w ( n − 1 ) e p ( n ) = D ( n ) − M T w ( n ) e(n)=D(n)-M^T(n)w(n-1)\\e_p(n)=D(n)-M^Tw(n)
e ( n ) = D ( n ) − M T ( n ) w ( n − 1 ) e p ( n ) = D ( n ) − M T w ( n )
APSA 的设计基于一下约束优化问题
min w ( n ) ∥ e p ( n ) ∥ 1 s . t . ∥ w ( n ) − w ( n − 1 ) ∥ 2 2 ≤ μ 2 \min_{w(n)}\Vert e_p(n)\Vert_1\\s.t.\quad\Vert w(n)-w(n-1)\Vert_2^2\leq\mu^2
w ( n ) min ∥ e p ( n ) ∥ 1 s . t . ∥ w ( n ) − w ( n − 1 ) ∥ 2 2 ≤ μ 2
引入拉格朗日乘数 γ > 0 \gamma>0 γ > 0
J ( w ( n ) ) = ∥ e p ( n ) ∥ 1 + γ ( ∥ w ( n ) − w ( n − 1 ) ∥ 2 2 − μ 2 ) J(w(n))=\Vert e_p(n)\Vert_1+\gamma\Big(\Vert w(n)-w(n-1)\Vert_2^2-\mu^2\Big)
J ( w ( n ) ) = ∥ e p ( n ) ∥ 1 + γ ( ∥ w ( n ) − w ( n − 1 ) ∥ 2 2 − μ 2 )
对 w ( n ) w(n) w ( n )
∂ J ∂ w ( n ) = − M ( n ) s g n ( e p ( n ) ) + 2 γ ( w ( n ) − w ( n − 1 ) ) = 0 ⇓ w ( n ) = w ( n − 1 ) + 1 2 γ M ( n ) s g n ( e p ( n ) ) \frac{\partial J}{\partial w(n)}=-M(n)\mathrm{sgn}(e_p(n))+2\gamma(w(n)-w(n-1))=0\\\Downarrow\\w(n)=w(n-1)+\frac{1}{2\gamma}M(n)\mathrm{sgn}(e_p(n))
∂ w ( n ) ∂ J = − M ( n ) s g n ( e p ( n ) ) + 2 γ ( w ( n ) − w ( n − 1 ) ) = 0 ⇓ w ( n ) = w ( n − 1 ) + 2 γ 1 M ( n ) s g n ( e p ( n ) )
由于后验误差在实际中无法直接获得,通常使用先验误差近似代替。另外为其添加归一化和防止分母为 0,得到 APSA 的权重更新公式
w ( n ) = w ( n − 1 ) + μ M ( n ) s g n ( e ( n ) ) ∥ M ( n ) s g n ( e ( n ) ) ∥ 2 + δ w(n)=w(n-1)+\mu\frac{M(n)\mathrm{sgn}(e(n))}{\Vert M(n)\mathrm{sgn}(e(n))\Vert_2+\delta}
w ( n ) = w ( n − 1 ) + μ ∥ M ( n ) s g n ( e ( n ) ) ∥ 2 + δ M ( n ) s g n ( e ( n ) )
最终滤波器输出为
y ( n ) = X T ( n ) w ( n ) y(n)=X^T(n)w(n)
y ( n ) = X T ( n ) w ( n )
宽带 ANC 算法
SAF
SAF 即子带自适应滤波(Subband Adaptive Filtering),通过分析滤波器组将宽带输入信号分解为多个窄带子带信号,对每个子带独立进行自适应滤波处理,再通过综合滤波器组重构输出信号。
定义全带权向量 w ( n ) = [ w 0 ( n ) ⋯ w L − 1 ( n ) ] w(n)=\begin{bmatrix}w_0(n)&\cdots&w_{L-1}(n)\end{bmatrix} w ( n ) = [ w 0 ( n ) ⋯ w L − 1 ( n ) ] i i i X i ( n ) = [ x i ( n ) x i ( n − 1 ) ⋯ x i ( n − L + 1 ) ] X_i(n)=\begin{bmatrix}x_i(n)&x_i(n-1)&\cdots&x_i(n-L+1)\end{bmatrix} X i ( n ) = [ x i ( n ) x i ( n − 1 ) ⋯ x i ( n − L + 1 ) ] i i i y i ( n ) = w T ( n ) X i ( n ) y_i(n)=w^T(n)X_i(n) y i ( n ) = w T ( n ) X i ( n ) i i i d i ( n ) = d i ( n M ) d_i(n)=d_i(nM) d i ( n ) = d i ( n M ) i i i e i ( n ) = d i ( n ) − y i ( n ) e_i(n)=d_i(n)-y_i(n) e i ( n ) = d i ( n ) − y i ( n )
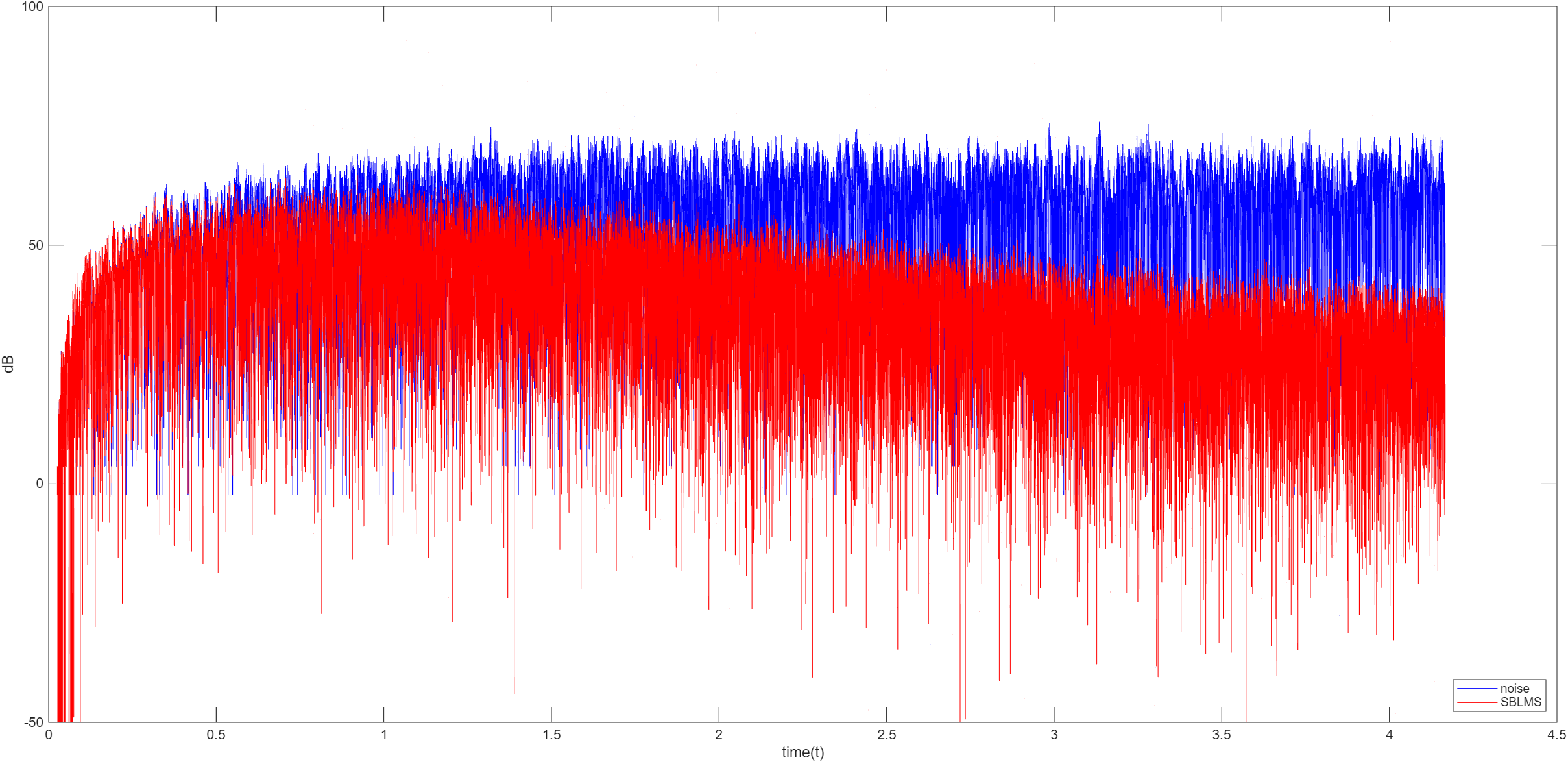
SBLMS
子带 LMS 基于最小扰动原理,权重更新公式为 w ( n + 1 ) = w ( n ) + μ ∑ i = 0 M − 1 X i ( n ) e i ( n ) w(n+1)=w(n)+\mu\sum_{i=0}^{M-1}X_i(n)e_i(n) w ( n + 1 ) = w ( n ) + μ ∑ i = 0 M − 1 X i ( n ) e i ( n )
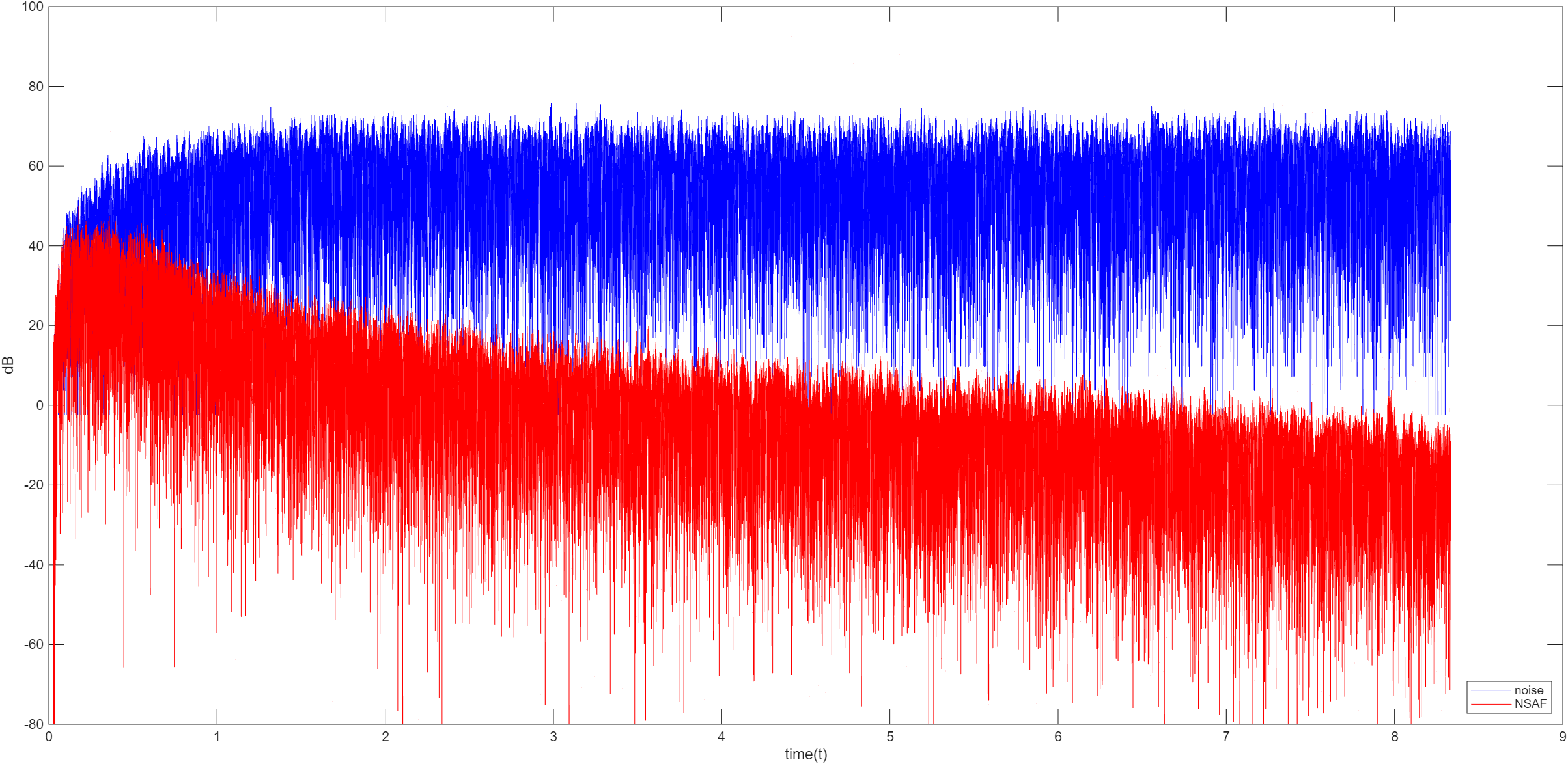
NSAF
NSAF 基于最小扰动原理,在满足子带误差约束的条件下,使权向量的更新量最小
定义优化问题 min w ( n + 1 ) ∥ w ( n + 1 ) − w ( n ) ∥ 2 \min_{w(n+1)}\Vert w(n+1)-w(n)\Vert^2 min w ( n + 1 ) ∥ w ( n + 1 ) − w ( n ) ∥ 2 d i ( n ) = X i T ( n ) w ( n + 1 ) d_i(n)=X_i^T(n)w(n+1) d i ( n ) = X i T ( n ) w ( n + 1 )
使用拉格朗日乘数法求解得到权值更新公式 w ( n + 1 ) = w ( n ) + μ ∑ i = 0 M − 1 X i ( n ) e i ( n ) X i T ( n ) X i ( n ) + ϵ w(n+1)=w(n)+\mu\sum_{i=0}^{M-1}\frac{X_i(n)e_i(n)}{X_i^T(n)X_i(n)+\epsilon} w ( n + 1 ) = w ( n ) + μ ∑ i = 0 M − 1 X i T ( n ) X i ( n ) + ϵ X i ( n ) e i ( n )
其中 μ \mu μ 0 < μ < 2 0<\mu<2 0 < μ < 2
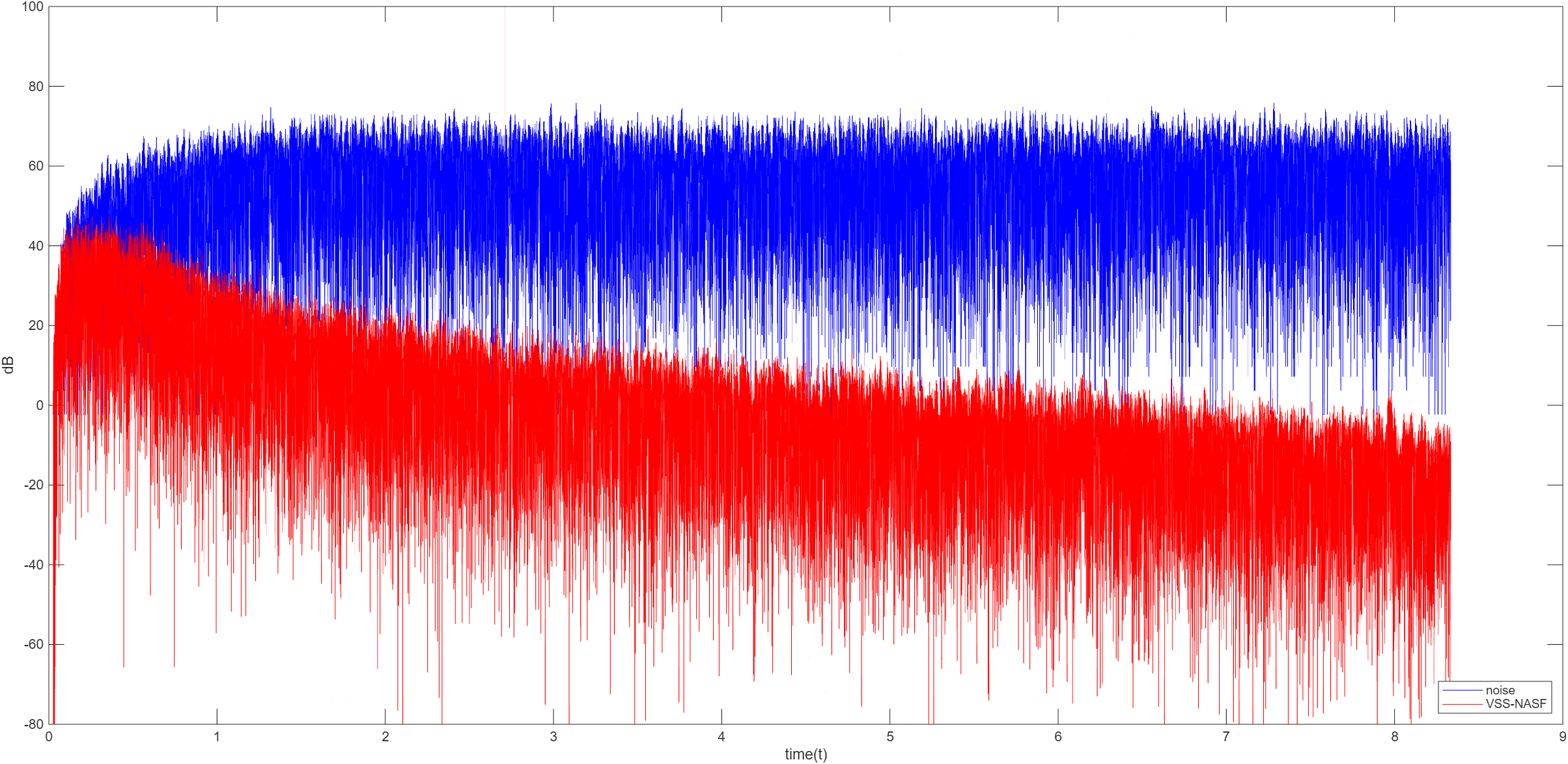
变步长 NSAF
变步 NSAF 解决固定步长 NSAF 收敛速度稳态失调的矛盾,变步长公式如下
基于误差平方的步长控制 μ ( n ) = μ m i n + ( μ m a x − μ m i n ) ( 1 − e − α e ˉ 2 ( n ) ) \mu(n)=\mu_{min}+(\mu_{max}-\mu_{min})(1-e^{-\alpha\bar{e}^2(n)}) μ ( n ) = μ m i n + ( μ m a x − μ m i n ) ( 1 − e − α e ˉ 2 ( n ) )
其中的 e ˉ 2 ( n ) = β e ˉ 2 ( n − 1 ) + ( 1 − β ) 1 M ∑ i = 0 M − 1 e i 2 ( n ) \bar{e}^2(n)=\beta\bar{e}^2(n-1)+(1-\beta)\frac{1}{M}\sum_{i=0}^{M-1}e_i^2(n) e ˉ 2 ( n ) = β e ˉ 2 ( n − 1 ) + ( 1 − β ) M 1 ∑ i = 0 M − 1 e i 2 ( n )
基于最小均方偏差 μ ( n ) = max ( μ m i n , min ( μ m a x , ∑ i = 0 M − 1 ϵ i 2 ( n ) ∥ X i ( n ) ∥ 2 ∑ i = 0 M − 1 e i 2 ( n ) ∥ X i ( n ) ∥ 2 ) ) \mu(n)=\max(\mu_{min},\min(\mu_{max},\frac{\sum_{i=0}^{M-1}\frac{\epsilon_i^2(n)}{\Vert X_i(n)\Vert^2}}{\sum_{i=0}^{M-1}\frac{e_i^2(n)}{\Vert X_i(n)\Vert^2}})) μ ( n ) = max ( μ m i n , min ( μ m a x , ∑ i = 0 M − 1 ∥ X i ( n ) ∥ 2 e i 2 ( n ) ∑ i = 0 M − 1 ∥ X i ( n ) ∥ 2 ϵ i 2 ( n ) ) )
其中的 e p s i l o n i 2 ( n ) = e i 2 ( n ) − σ i 2 ( n ) epsilon_i^2(n)=e_i^2(n)-\sigma_i^2(n) e p s i l o n i 2 ( n ) = e i 2 ( n ) − σ i 2 ( n )
其中 σ i ( n ) = min ( σ i ( n − 1 ) , γ σ i ( n − 1 ) + ( 1 − γ ) ∣ e i ( n ) ∣ ) \sigma_i(n)=\min(\sigma_i(n-1),\gamma\sigma_i(n-1)+(1-\gamma)\vert e_i(n)\vert) σ i ( n ) = min ( σ i ( n − 1 ) , γ σ i ( n − 1 ) + ( 1 − γ ) ∣ e i ( n ) ∣ )
基于噪声方差估计 μ i ( n ) = 1 − σ i ( n ) e i ( n ) \mu_i(n)=1-\frac{\sigma_i(n)}{e_i(n)} μ i ( n ) = 1 − e i ( n ) σ i ( n )
其中 σ i ( n ) = min ( σ i ( n − 1 ) , γ σ i ( n − 1 ) + ( 1 − γ ) ∣ e i ( n ) ∣ ) \sigma_i(n)=\min(\sigma_i(n-1),\gamma\sigma_i(n-1)+(1-\gamma)\vert e_i(n)\vert) σ i ( n ) = min ( σ i ( n − 1 ) , γ σ i ( n − 1 ) + ( 1 − γ ) ∣ e i ( n ) ∣ )
其中的 γ \gamma γ 0.99 ∼ 0.999 0.99\sim0.999 0 . 9 9 ∼ 0 . 9 9 9
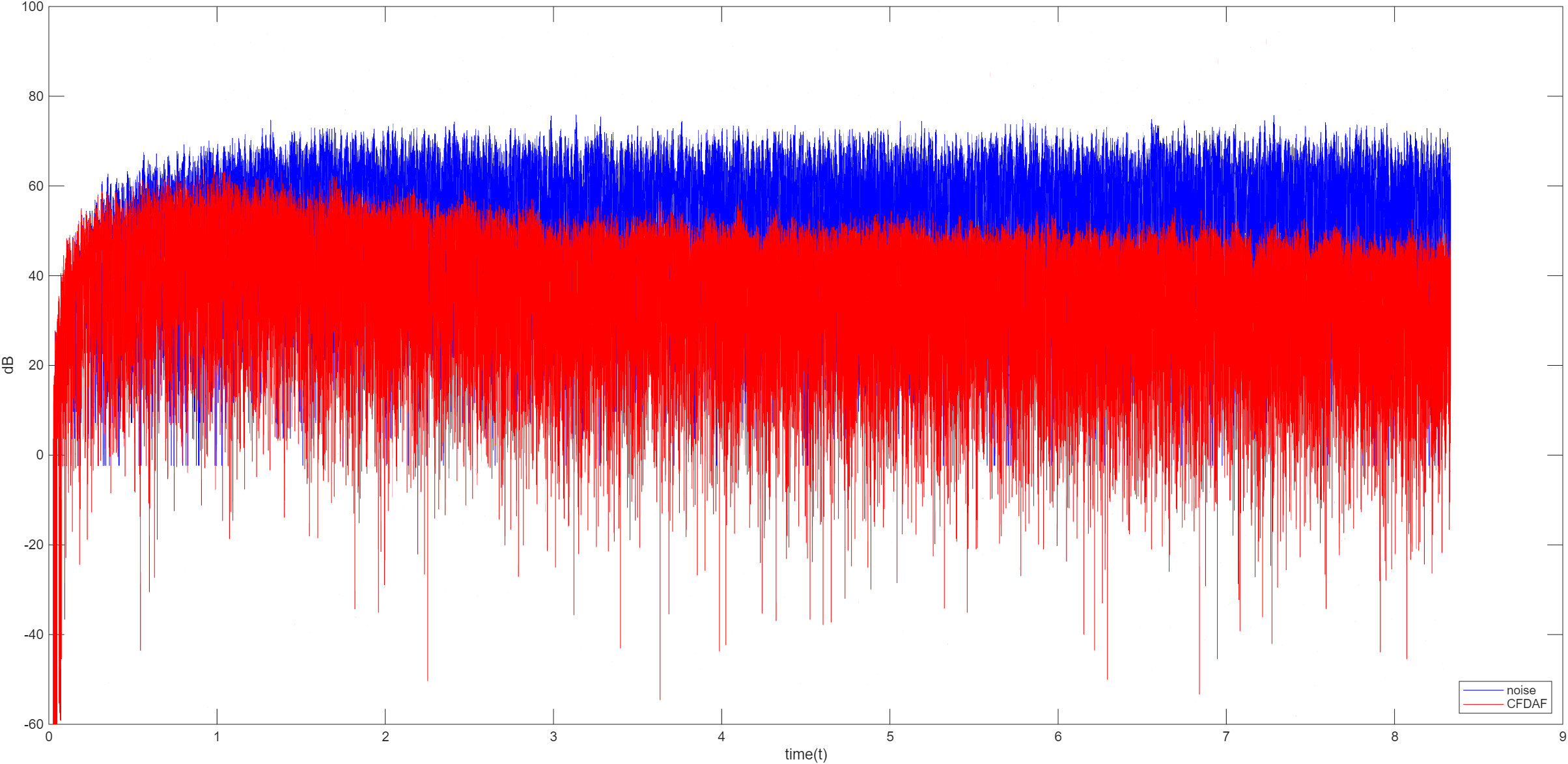
FDAF
FDAF 即频域自适应滤波器算法(Frequency-Domain Adaptive Filter),是基于块处理和快速傅里叶变换的自适应滤波算法。LMS 算法的计算复杂度为 O ( L 2 ) O(L^2) O ( L 2 ) O ( L log L ) O(L\log L) O ( L log L )
块处理:每积累 L L L
更新公式为 w ( n + 1 ) = w ( n ) + μ ∑ l = 0 L − 1 X ( n L + l ) e ( n L + l ) w(n+1)=w(n)+\mu\sum_{l=0}^{L-1}X(nL+l)e(nL+l) w ( n + 1 ) = w ( n ) + μ ∑ l = 0 L − 1 X ( n L + l ) e ( n L + l )
其中 n n n L L L L L L 1 N \frac{1}{N} N 1
频域变换:利用 FFT 将时域卷积转换为频域逐点乘法,降低计算量
重叠保留法:解决频域循环卷积与线性卷积的差异问题,保证输出无混叠失真
直接使用 FFT 计算卷积会得到循环卷积结果,而非线性卷积
对长度为 L L L L L L 2 L 2L 2 L
每次处理长度为 2 L 2L 2 L L L L L L L
进行 2 L 2L 2 L
只保留输出块的后 N N N
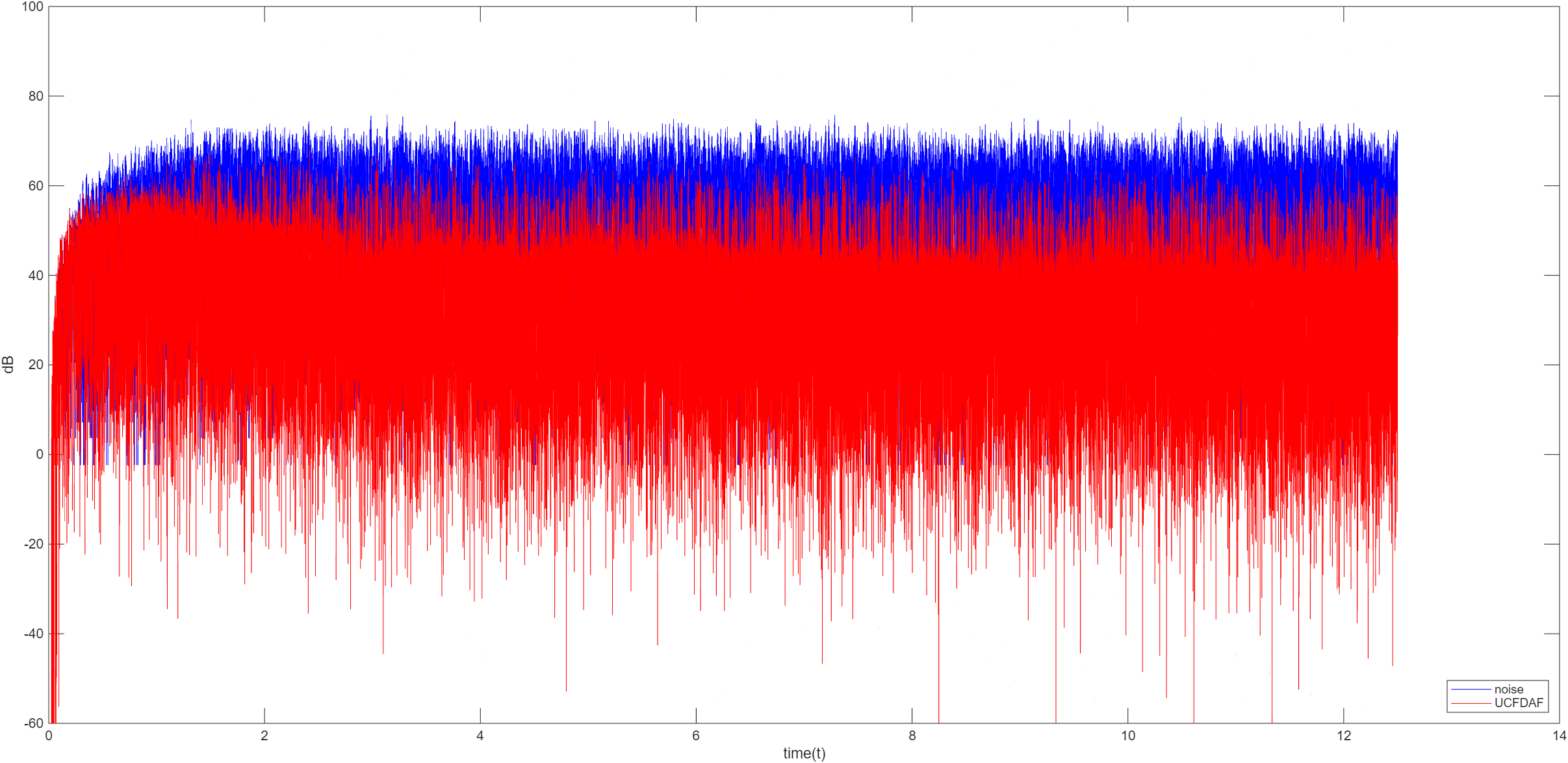
约束 FDAF
约束 FDAF 通过时域约束保证权向量的长度始终为 L L L
W ( n + 1 ) = W ( n ) + μ G X H ( n ) E ( n ) W(n+1)=W(n)+\mu GX^H(n)E(n)
W ( n + 1 ) = W ( n ) + μ G X H ( n ) E ( n )
其中的 G = F [ I L 0 L 0 L 0 L ] F − 1 G=F\begin{bmatrix}I_L&0_L\\0_L&0_L\end{bmatrix}F^{-1} G = F [ I L 0 L 0 L 0 L ] F − 1 L L L F F F 2 L 2L 2 L N N N
w ( n ) = I F F T ( W ( n ) ) w L : e n d ( n ) = 0 W ( n ) = F F T ( w ( n ) ) w(n)=IFFT(W(n))\\w_{L:end}(n)=0\\W(n)=FFT(w(n))
w ( n ) = I F F T ( W ( n ) ) w L : e n d ( n ) = 0 W ( n ) = F F T ( w ( n ) )
无约束 FDAF
无约束 FDAF 移除了时域约束,计算更简单,它的权值更新公式如下
W ( n + 1 ) = W ( n ) + μ X H ( n ) E ( n ) W(n+1)=W(n)+\mu X^H(n)E(n)
W ( n + 1 ) = W ( n ) + μ X H ( n ) E ( n )
与上述约束 FDAF 相比,去掉了约束矩阵 G G G
归一化 FDAF
归一化 FDAF 算法为每个频点分配独立的步长,与该频点的输入功率成反比,大幅提升了对相关输入信号的收敛速度
W ( n + 1 ) = W ( n ) + μ Λ − 1 ( n ) X H ( n ) E ( n ) W(n+1)=W(n)+\mu \Lambda^{-1}(n)X^H(n)E(n)
W ( n + 1 ) = W ( n ) + μ Λ − 1 ( n ) X H ( n ) E ( n )
其中 Λ ( n ) = d i a g { Φ x x , 0 ( n ) , Φ x x , 1 ( n ) , ⋯ , Φ x x , 2 L − 1 ( n ) } \Lambda(n)=\mathrm{diag}\{\Phi_{xx,0}(n),\Phi_{xx,1}(n),\cdots,\Phi_{xx,2L-1}(n)\} Λ ( n ) = d i a g { Φ x x , 0 ( n ) , Φ x x , 1 ( n ) , ⋯ , Φ x x , 2 L − 1 ( n ) } Φ x x , i ( n ) \Phi_{xx,i}(n) Φ x x , i ( n ) i i i
Φ x x , i ( n ) = λ Φ x x , i ( n ) + ( 1 − λ ) ∥ X i ( n ) ∥ 2 \Phi_{xx,i}(n)=\lambda\Phi_{xx,i}(n)+(1-\lambda)\Vert X_i(n)\Vert^2
Φ x x , i ( n ) = λ Φ x x , i ( n ) + ( 1 − λ ) ∥ X i ( n ) ∥ 2
其中 λ \lambda λ 0.9 ∼ 0.999 0.9\sim0.999 0 . 9 ∼ 0 . 9 9 9
非线性 ANC 算法
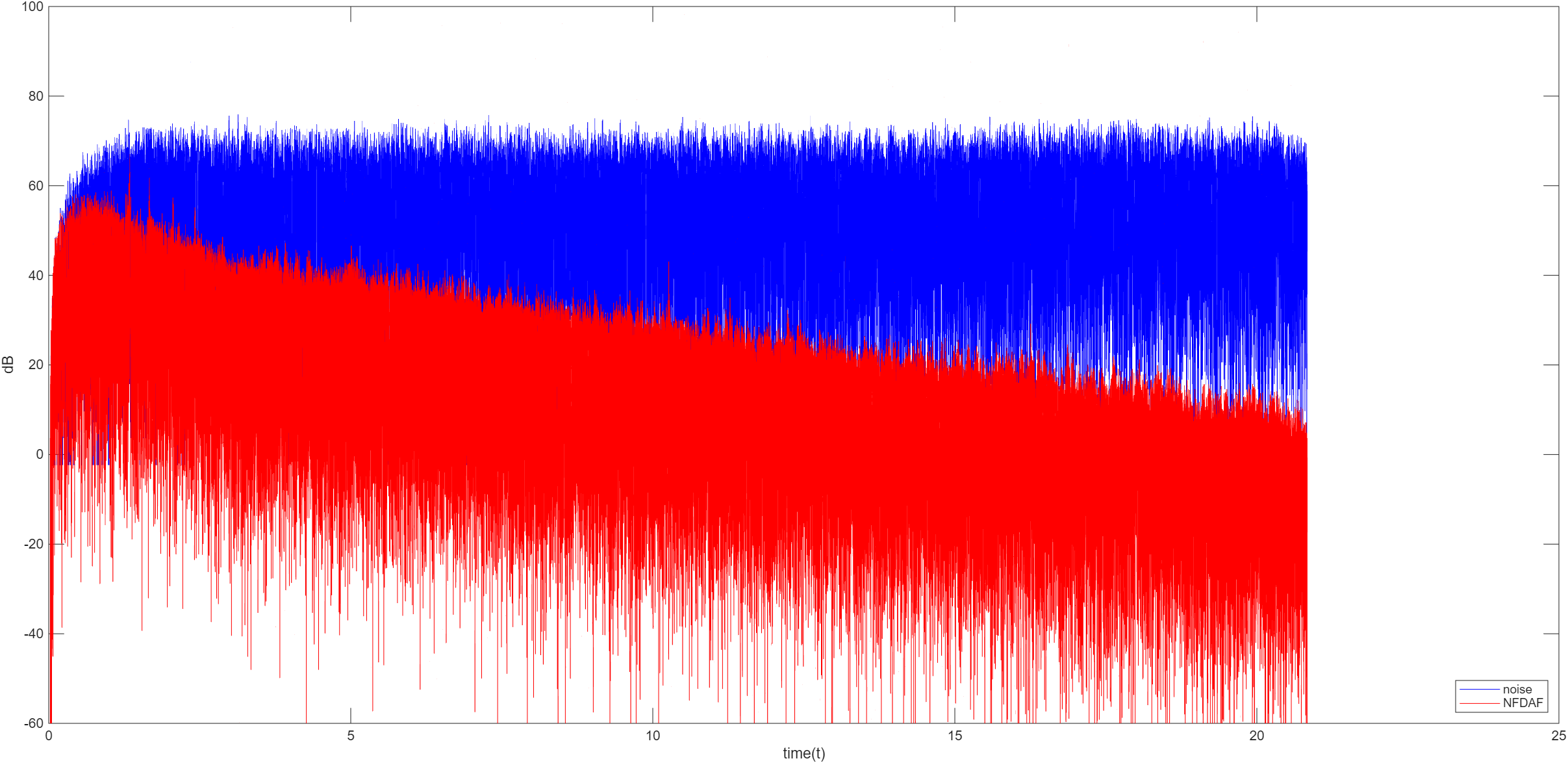
基于核方法的算法
传统线性 ANC 算法基于线性时不变系统假设,通过自适应线性滤波器生成反相声波抵消噪声,但是在实际使用中,系统普遍存在非线性失真。此时线性滤波器的容量不足,降噪效果就会急剧下降,核方法通过将低维输入空间的非线性问题映射到高维再生核希尔伯特空间,再高维空间中执行线性自适应滤波,等价于原空间的非线性运算,解决了线性 ANC 的非线性建模能力不足问题
再生核希尔伯特空间 RKHS 与核技巧:设输入空间 X ⊆ R M X\subseteq R^M X ⊆ R M ϕ : X → H \phi:X\rightarrow H ϕ : X → H ϕ \phi ϕ
k ( x , y ) = < ϕ ( x ) , ϕ ( y ) > H k(x,y)=<\phi(x),\phi(y)>_H
k ( x , y ) = < ϕ ( x ) , ϕ ( y ) > H
其中的核函数需要满足 Mercer 定理,即对于任意有限个输入 { x 1 , ⋯ , x n } \{x_1,\cdots,x_n\} { x 1 , ⋯ , x n } K ∈ R n × n K\in\R^{n\times n} K ∈ R n × n K i j = k ( x i , x j ) K_{ij}=k(x_i,x_j) K i j = k ( x i , x j )
高斯核函数 k ( x , y ) = exp ( − ∥ x − y ∥ 2 2 σ 2 ) k(x,y)=\exp(-\frac{\Vert x-y\Vert^2}{2\sigma^2}) k ( x , y ) = exp ( − 2 σ 2 ∥ x − y ∥ 2 )
多项式核函数 k ( x , y ) = ( x ⋅ y + c ) d k(x,y)=(x\cdot y+c)^d k ( x , y ) = ( x ⋅ y + c ) d
Sigmoid 核函数 k ( x , y ) = tanh ( a x ⋅ y + c ) k(x,y)=\tanh(ax\cdot y+c) k ( x , y ) = tanh ( a x ⋅ y + c )
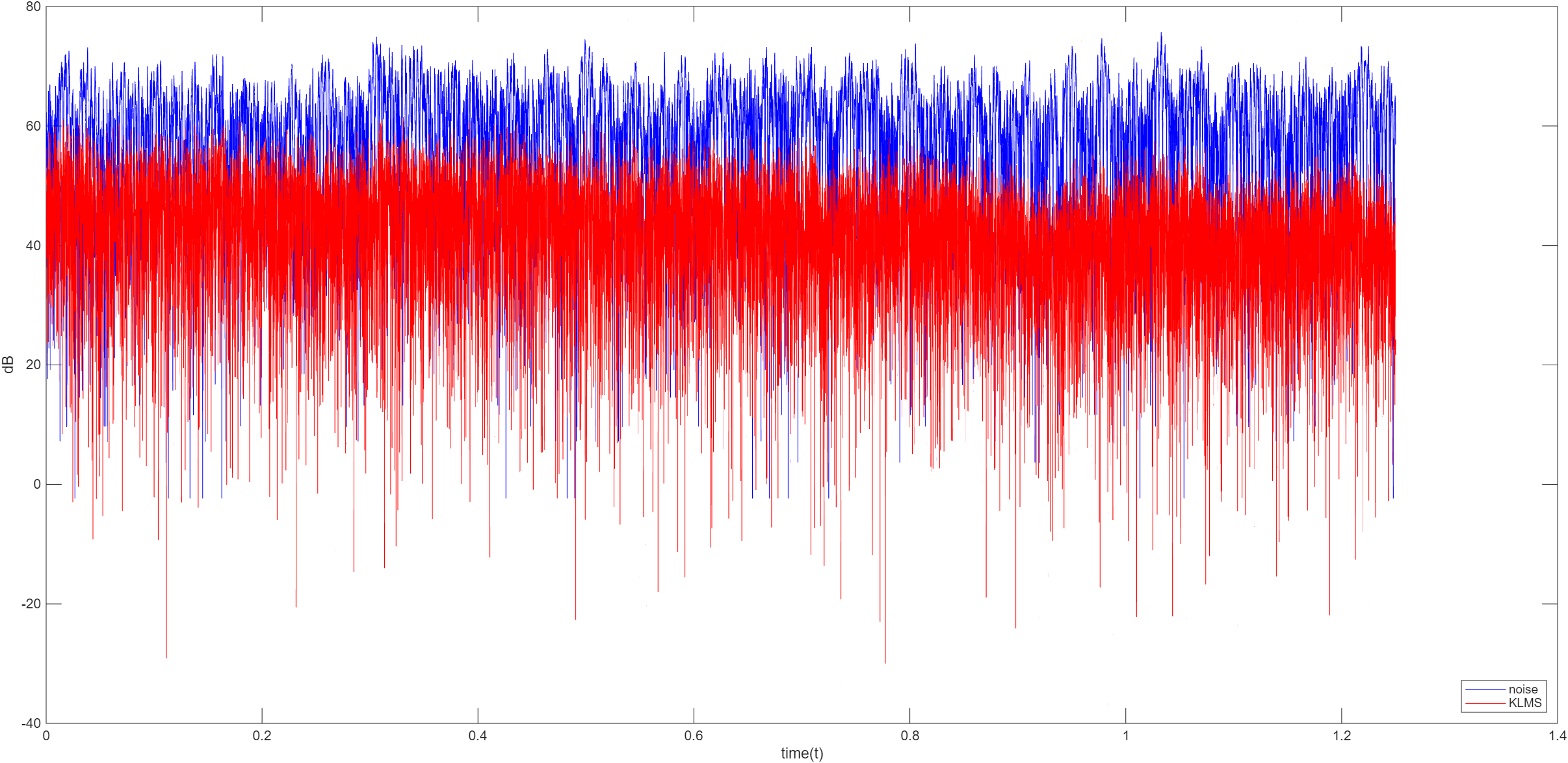
核 LMS 算法
设定在 n n n
X ( n ) = [ x ( n ) x ( n − 1 ) ⋯ x ( n − L + 1 ) ] X(n)=\begin{bmatrix}x(n)&x(n-1)&\cdots&x(n-L+1)\end{bmatrix}
X ( n ) = [ x ( n ) x ( n − 1 ) ⋯ x ( n − L + 1 ) ]
其中 L L L ϕ ( X ( n ) ) ∈ H \phi(X(n))\in H ϕ ( X ( n ) ) ∈ H w ( n ) w(n) w ( n )
y ( n ) = < w ( n − 1 ) , ϕ ( X ( n ) ) > H y(n)=<w(n-1),\phi(X(n))>_H
y ( n ) = < w ( n − 1 ) , ϕ ( X ( n ) ) > H
误差信号为
e ( n ) = d ( n ) − y ( n ) e(n)=d(n)-y(n)
e ( n ) = d ( n ) − y ( n )
采用随机梯度下降法最小化瞬时平方误差 ξ ( n ) = e 2 ( n ) \xi(n)=e^2(n) ξ ( n ) = e 2 ( n )
∇ ξ ( n ) = − 2 e ( n ) ϕ ( X ( n ) ) \nabla\xi(n)=-2e(n)\phi(X(n))
∇ ξ ( n ) = − 2 e ( n ) ϕ ( X ( n ) )
此时权重更新公式为
w ( n ) = w ( n − 1 ) + μ e ( n ) ϕ ( X ( n ) ) w(n)=w(n-1)+\mu e(n)\phi(X(n))
w ( n ) = w ( n − 1 ) + μ e ( n ) ϕ ( X ( n ) )
其中的 μ > 0 \mu>0 μ > 0
w ( n ) = ∑ i = 1 n α ( i ) ϕ ( X ( i ) ) w(n)=\sum_{i=1}^n\alpha(i)\phi(X(i))
w ( n ) = i = 1 ∑ n α ( i ) ϕ ( X ( i ) )
其中的 α ( i ) \alpha(i) α ( i )
y ( n ) = ∑ i = 1 n − 1 α ( i ) k ( X ( i ) , X ( n ) ) y(n)=\sum_{i=1}^{n-1}\alpha(i)k\Big(X(i),X(n)\Big)
y ( n ) = i = 1 ∑ n − 1 α ( i ) k ( X ( i ) , X ( n ) )
权值更新转化为系数更新,即
α ( n ) = μ e ( n ) \alpha(n)=\mu e(n)
α ( n ) = μ e ( n )
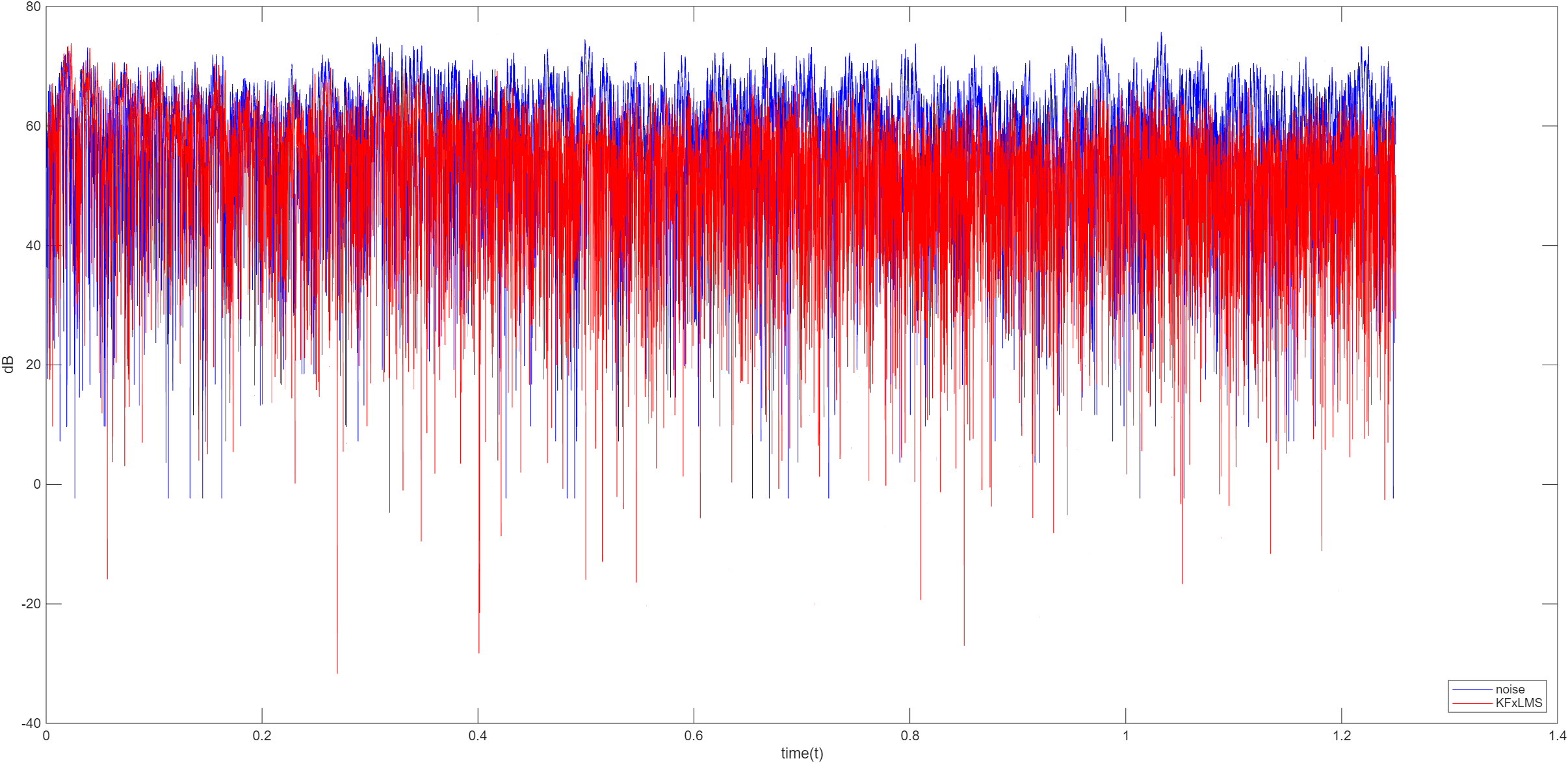
核 FxLMS 算法
在核 LMS 算法中,未考虑到 ANC 系统中次级路径的影响,无法直接应用于 ANC 算法中,而核 FxLMS 算法是 KLMS 算法的扩展,用于解决次级路径的补偿问题
对于参考信号 X ( n ) = [ x ( n ) x ( n − 1 ) ⋯ x ( n − L + 1 ) ] X(n)=\begin{bmatrix}x(n)&x(n-1)&\cdots&x(n-L+1)\end{bmatrix} X ( n ) = [ x ( n ) x ( n − 1 ) ⋯ x ( n − L + 1 ) ] y ( n ) y(n) y ( n ) y f ( n ) = s ( n ) ∗ y ( n ) y_f(n)=s(n)*y(n) y f ( n ) = s ( n ) ∗ y ( n ) s ( n ) s(n) s ( n ) e ( n ) = d ( n ) − y f ( n ) e(n)=d(n)-y_f(n) e ( n ) = d ( n ) − y f ( n )
代价函数为 ξ ( n ) = e 2 ( n ) \xi(n)=e^2(n) ξ ( n ) = e 2 ( n ) w ( n − 1 ) w(n-1) w ( n − 1 )
∇ ξ ( n ) = − 2 e ( n ) ( s ( n ) ∗ ∇ y ( n ) ) \nabla\xi(n)=-2e(n)\Big(s(n)*\nabla y(n)\Big)
∇ ξ ( n ) = − 2 e ( n ) ( s ( n ) ∗ ∇ y ( n ) )
由于 y ( n ) = < w ( n − 1 ) , ϕ ( X ( n ) ) > H y(n)=<w(n-1),\phi(X(n))>_H y ( n ) = < w ( n − 1 ) , ϕ ( X ( n ) ) > H ∇ y ( n ) = ϕ ( X ( n ) ) \nabla y(n)=\phi(X(n)) ∇ y ( n ) = ϕ ( X ( n ) )
∇ ξ ( n ) = − 2 e ( n ) ( s ( n ) ∗ ϕ ( X ( n ) ) ) \nabla\xi(n)=-2e(n)\Big(s(n)*\phi(X(n))\Big)
∇ ξ ( n ) = − 2 e ( n ) ( s ( n ) ∗ ϕ ( X ( n ) ) )
但是上述中直接对高维向量 ϕ ( X ( n ) ) \phi(X(n)) ϕ ( X ( n ) ) X ( n ) X(n) X ( n ) X f = s ^ ( n ) ∗ X ( n ) X_f=\hat{s}(n)*X(n) X f = s ^ ( n ) ∗ X ( n ) s ^ ( n ) \hat{s}(n) s ^ ( n ) X f ( n ) X_f(n) X f ( n ) ϕ ( X f ( n ) ) \phi(X_f(n)) ϕ ( X f ( n ) ) s ( n ) ∗ ϕ ( X ( n ) ) s(n)*\phi(X(n)) s ( n ) ∗ ϕ ( X ( n ) )
∇ ξ ( n ) = − 2 e ( n ) ( ϕ ( X f ( n ) ) ) w ( n ) = w ( n − 1 ) + μ e ( n ) ϕ ( X f ( n ) ) y ( n ) = ∑ i = 1 n − 1 α ( i ) k ( X f ( i ) , X ( n ) ) α ( n ) = μ e ( n ) \nabla\xi(n)=-2e(n)\Big(\phi(X_f(n))\Big)\\w(n)=w(n-1)+\mu e(n)\phi(X_f(n))\\y(n)=\sum_{i=1}^{n-1}\alpha(i)k\Big(X_f(i),X(n)\Big)\\\alpha(n)=\mu e(n)
∇ ξ ( n ) = − 2 e ( n ) ( ϕ ( X f ( n ) ) ) w ( n ) = w ( n − 1 ) + μ e ( n ) ϕ ( X f ( n ) ) y ( n ) = i = 1 ∑ n − 1 α ( i ) k ( X f ( i ) , X ( n ) ) α ( n ) = μ e ( n )
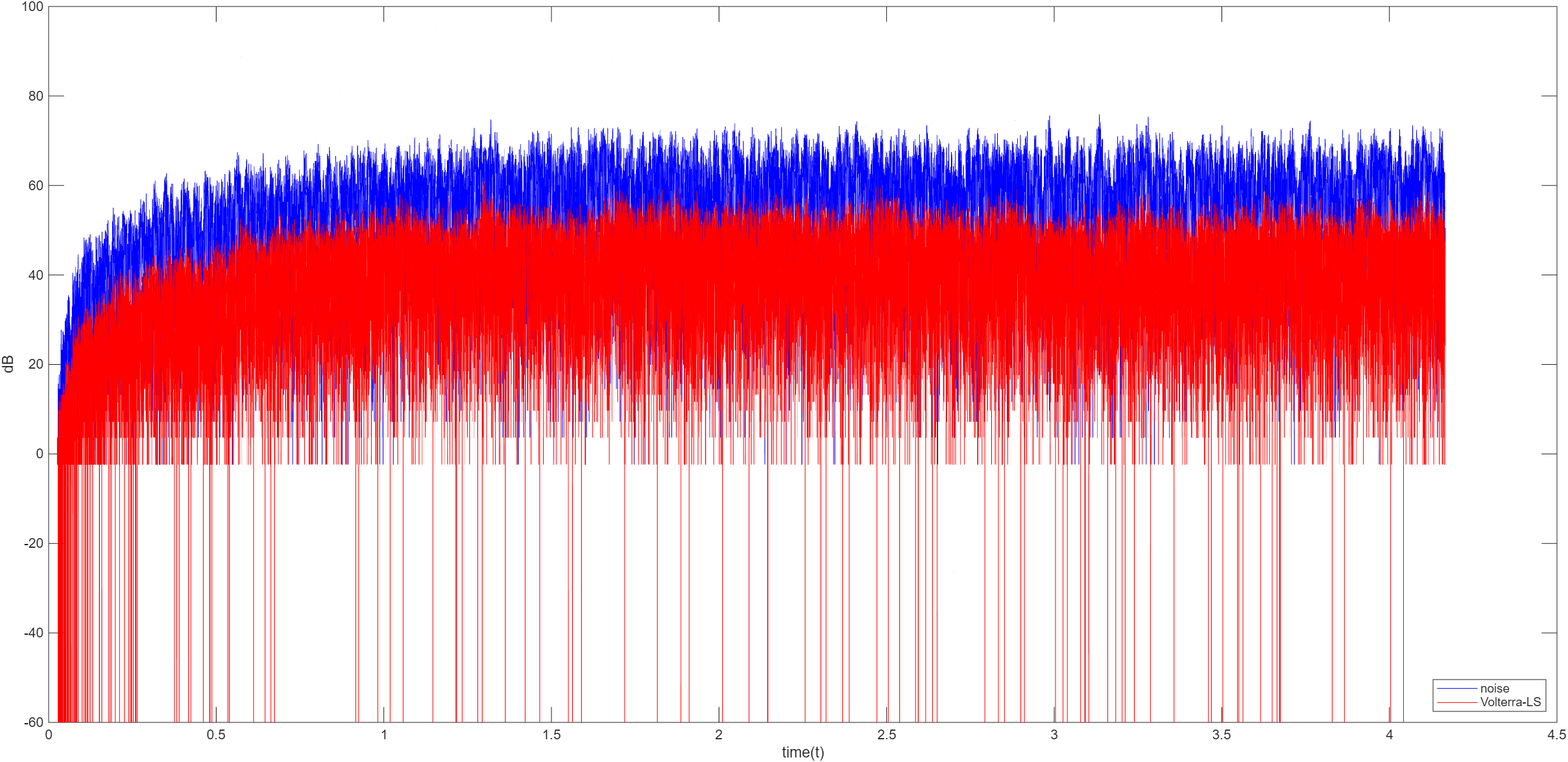
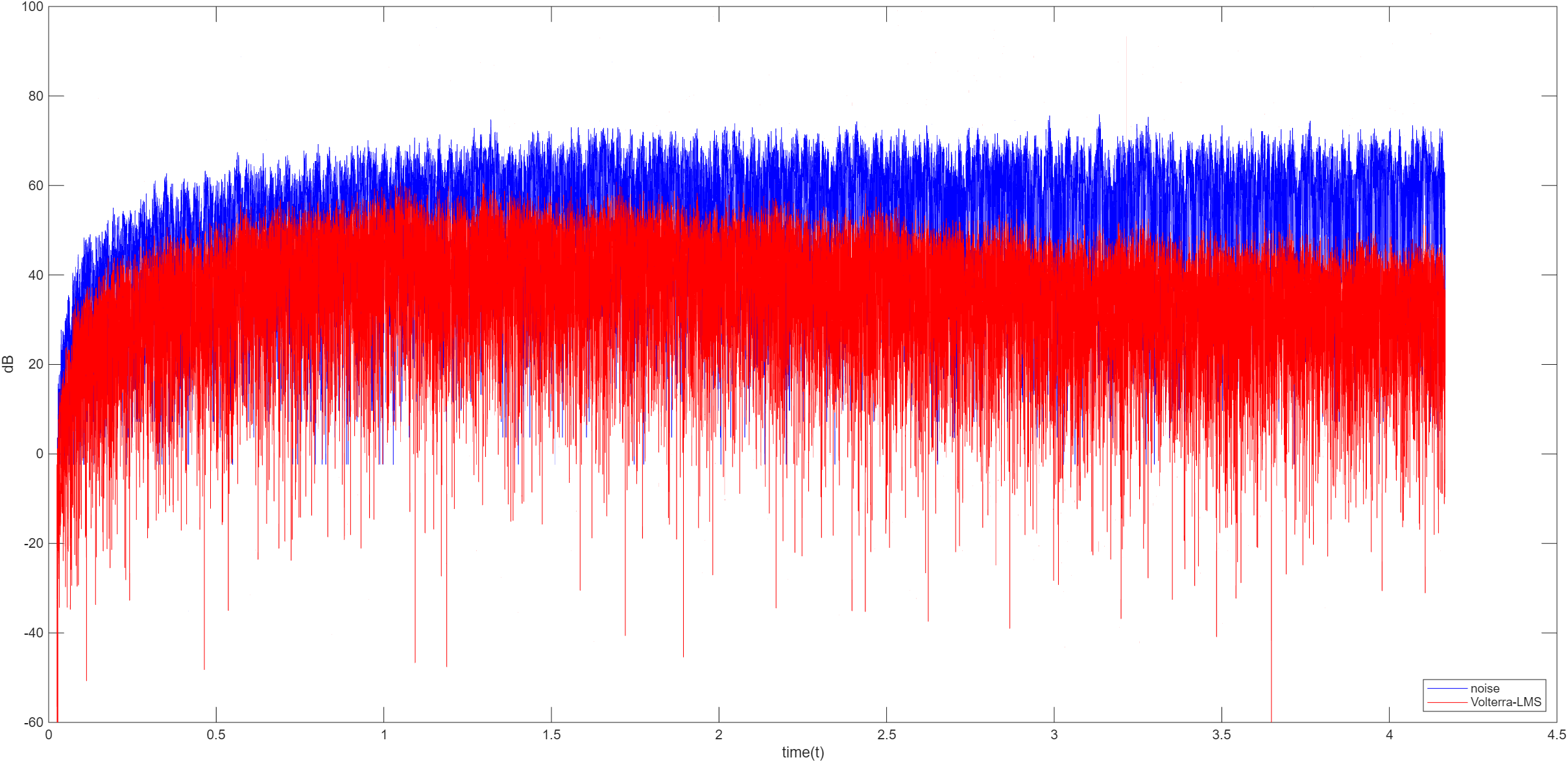
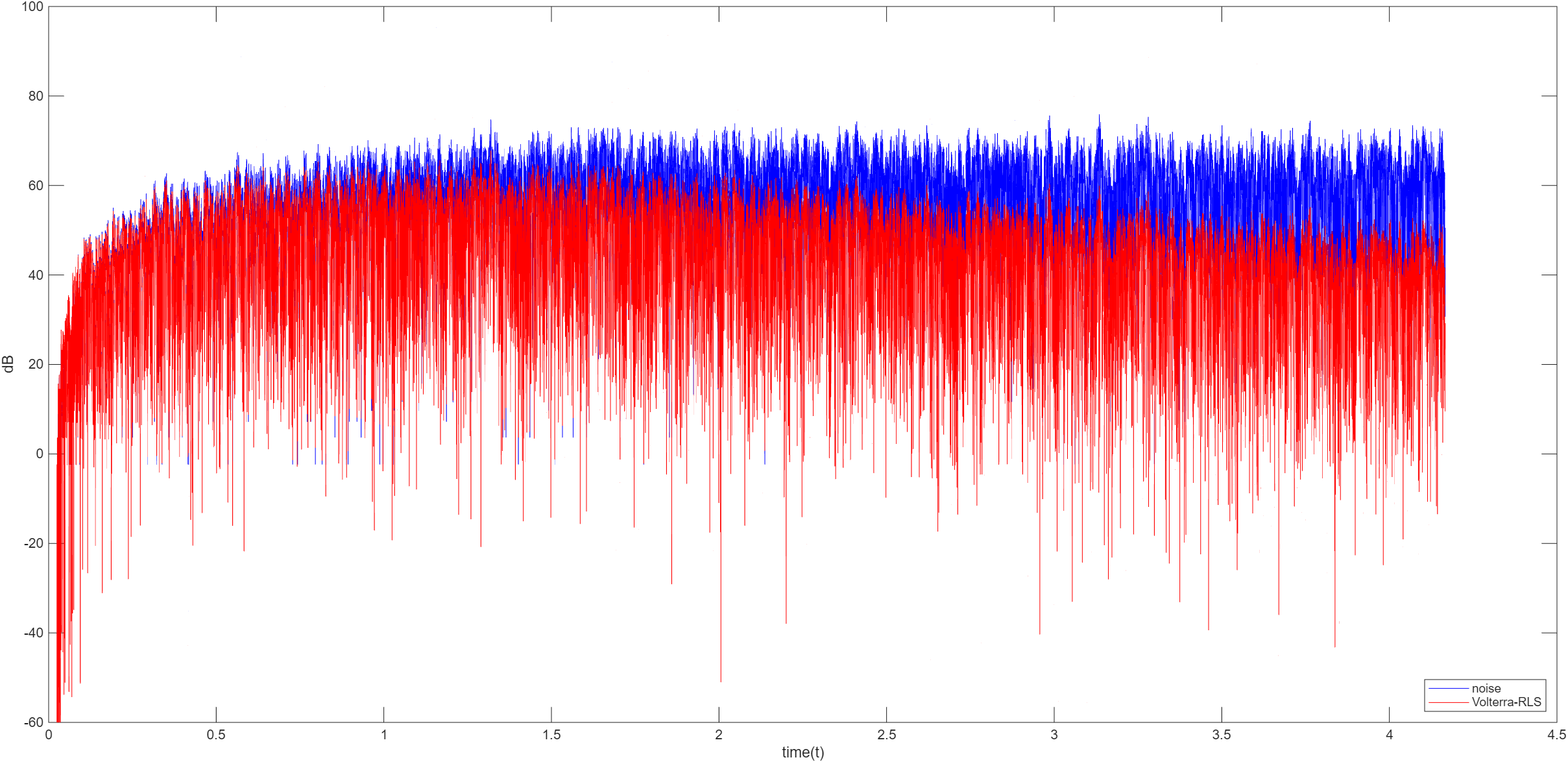
Volterra
Volterra 算法是基于 Volterra 级数的非线性系统建模与信号处理的方法,是泰勒级数在时域的推广,能同时描述系统的非线性特性和记忆效应。Volterra 级数公式如下
y ( t ) = w 0 + ∫ h 1 ( τ ) x ( t − τ ) d τ + ∬ h 2 ( τ 1 , τ 2 ) x ( t − τ 1 ) x ( t − τ 2 ) d τ 1 d τ 2 + ⋯ y(t)=w_0+\int h_1(\tau)x(t-\tau)d\tau+\iint h_2(\tau_1,\tau_2)x(t-\tau_1)x(t-\tau_2)d\tau_1d\tau_2+\cdots
y ( t ) = w 0 + ∫ h 1 ( τ ) x ( t − τ ) d τ + ∬ h 2 ( τ 1 , τ 2 ) x ( t − τ 1 ) x ( t − τ 2 ) d τ 1 d τ 2 + ⋯
其中的 h n ( τ 1 , ⋯ , τ n ) h_n(\tau_1,\cdots,\tau_n) h n ( τ 1 , ⋯ , τ n ) n n n
y ( n ) = h 0 + ∑ p = 1 P ∑ τ 1 = 0 M − 1 ⋯ ∑ τ p = 0 M − 1 h p ( τ 1 , ⋯ , τ p ) ∏ j = 1 p x ( n − τ j ) y(n)=h_0+\sum_{p=1}^P\sum_{\tau_1=0}^{M-1}\cdots\sum_{\tau_p=0}^{M-1}h_p(\tau_1,\cdots,\tau_p)\prod_{j=1}^px(n-\tau_j)
y ( n ) = h 0 + p = 1 ∑ P τ 1 = 0 ∑ M − 1 ⋯ τ p = 0 ∑ M − 1 h p ( τ 1 , ⋯ , τ p ) j = 1 ∏ p x ( n − τ j )
其中的 P P P M M M h p ( τ 1 , ⋯ , τ p ) h_p(\tau_1,\cdots,\tau_p) h p ( τ 1 , ⋯ , τ p ) p p p C ( M , 2 ) C(M,2) C ( M , 2 )
y ( t ) = w T X ( n ) y(t)=w^TX(n)
y ( t ) = w T X ( n )
其中的输入向量为
X ( n ) = [ 1 x ( n ) ⋮ x ( n − M + 1 ) x ( n ) x ( n ) ⋮ x ( n ) x ( n − M + 1 ) x ( n − 1 ) x ( n − 1 ) ⋮ x ( n − M + 1 ) x ( n − M + 1 ) ] w = [ h 0 h 1 ( 0 ) ⋮ h 1 ( M − 1 ) h 2 ( 0 , 0 ) ⋮ h 2 ( 0 , M − 1 ) h 2 ( 1 , 1 ) ⋮ h 2 ( M − 1 , M − 1 ) ] X(n)=\begin{bmatrix}1\\x(n)\\\vdots\\x(n-M+1)\\x(n)x(n)\\\vdots\\x(n)x(n-M+1)\\x(n-1)x(n-1)\\\vdots\\x(n-M+1)x(n-M+1)\end{bmatrix}\\w=\begin{bmatrix}h_0\\h_1(0)\\\vdots\\h_1(M-1)\\h_2(0,0)\\\vdots\\h_2(0,M-1)\\h_2(1,1)\\\vdots\\h_2(M-1,M-1)\end{bmatrix}
X ( n ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 1 x ( n ) ⋮ x ( n − M + 1 ) x ( n ) x ( n ) ⋮ x ( n ) x ( n − M + 1 ) x ( n − 1 ) x ( n − 1 ) ⋮ x ( n − M + 1 ) x ( n − M + 1 ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤ w = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ h 0 h 1 ( 0 ) ⋮ h 1 ( M − 1 ) h 2 ( 0 , 0 ) ⋮ h 2 ( 0 , M − 1 ) h 2 ( 1 , 1 ) ⋮ h 2 ( M − 1 , M − 1 ) ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
Volterra 算法的核心是估计核函数的系数,常用方法如下
最小二乘 LS
最小化误差的平方和 J ( w ) = ∑ n = 0 N − 1 e 2 ( n ) = ∑ n = 0 N − 1 ( d ( n ) + w T X ( n ) ) 2 J(w)=\sum_{n=0}^{N-1}e^2(n)=\sum_{n=0}^{N-1}\Big(d(n)+w^TX(n)\Big)^2 J ( w ) = ∑ n = 0 N − 1 e 2 ( n ) = ∑ n = 0 N − 1 ( d ( n ) + w T X ( n ) ) 2
得到最优解 w = − ( X T X ) − 1 X T d w=-(X^TX)^{-1}X^Td w = − ( X T X ) − 1 X T d X X X d d d
最小均方误差 LMS
最小化误差的平方和 J ( w ) = ∑ n = 0 N − 1 e 2 ( n ) = ∑ n = 0 N − 1 ( d ( n ) + w T X ( n ) ) 2 J(w)=\sum_{n=0}^{N-1}e^2(n)=\sum_{n=0}^{N-1}\Big(d(n)+w^TX(n)\Big)^2 J ( w ) = ∑ n = 0 N − 1 e 2 ( n ) = ∑ n = 0 N − 1 ( d ( n ) + w T X ( n ) ) 2
基于梯度下降法更新权向量 w = w − μ e ( n ) X ( n ) w=w-\mu e(n)X(n) w = w − μ e ( n ) X ( n )
递归最小二乘 RLS
最小化加权误差平方和 J ( w ) = ∑ n = 0 N − 1 λ N − n e 2 ( n ) J(w)=\sum_{n=0}^{N-1}\lambda^{N-n}e^2(n) J ( w ) = ∑ n = 0 N − 1 λ N − n e 2 ( n )
计算增益向量 K ( n ) = P ( n − 1 ) X ( n ) λ + X T ( n ) P ( n − 1 ) X ( n ) K(n)=\frac{P(n-1)X(n)}{\lambda+X^T(n)P(n-1)X(n)} K ( n ) = λ + X T ( n ) P ( n − 1 ) X ( n ) P ( n − 1 ) X ( n )
计算误差信号 e ( n ) = d ( n ) + w T ( n − 1 ) X ( n ) e(n)=d(n)+w^T(n-1)X(n) e ( n ) = d ( n ) + w T ( n − 1 ) X ( n )
更新权向量 w ( n ) = w ( n − 1 ) − K ( n ) e ( n ) w(n)=w(n-1)-K(n)e(n) w ( n ) = w ( n − 1 ) − K ( n ) e ( n )
更新逆相关矩阵 P ( n ) = λ − 1 ( P ( n − 1 ) − K ( n ) X T ( n ) P ( n − 1 ) ) P(n)=\lambda^{-1}\Big(P(n-1)-K(n)X^T(n)P(n-1)\Big) P ( n ) = λ − 1 ( P ( n − 1 ) − K ( n ) X T ( n ) P ( n − 1 ) )