前言
介绍
在无数深度学习的框架中,Keras 是为人类设计的 API,它提供一致且简单的 API,它将常见用例所需的用户操作数量降至最低,并且在用户错误时提供清晰和可操作的反馈
Keras 与底层深度学习语言(特别是 TensorFlow)集成在一起,所以它可以让用户实现任何可以用基础语言编写的东西
安装
首先是安装 Python,然后安装对应的包即可
1 | pip install tensorflow |
神经网络
神经元模型
神经元模型是组成神经网络的最基本单位,它起初来源于人体,模仿人体的神经元,功能也与人体的神经元一致,得到信号的输入,经过数据处理,然后给出一个结果作为输出或者作为下一个神经元的输入
神经元可以单方向的传输信号,一个神经元有多个树突,只有一个轴突,轴突尾端有多个轴突末梢给其他多个神经元传递信息
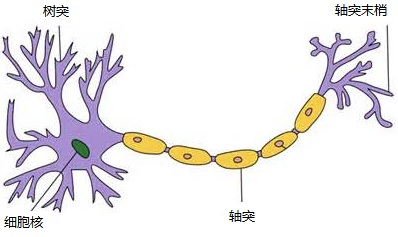
一个简化的神经元模型如下,是一个包含输入,输出与计算的模型。输入对应着神经元的树突,计算对应着细胞核,而输出对应着轴突。连接是神经元中最重要的东西,每一个连接上都有一个权重,一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好
1 | flowchart LR |
单层神经网络
单层神经网络是深度学习中最简单的神经网络模型之一,也被称为感知机(Perceptron)
基本结构
- 输入层:接收来自外部的输入数据
- 线性传输层:也称为加权和层(Weighted Sum Layer),对输入数据进行线性组合,即执行输入与权重的乘积之和的操作
- 输出层:对传输层的输出进行进一步处理,并产生最终的输出结果。单层神经网络没有隐藏层,因此它只能处理线性可分的问题
1 | flowchart LR |
工作原理
- 权重初始化:在神经网络训练之前,需要对连接输入层和输出层的权重进行初始化。通常情况下,可以随机选择一组初始权重,并根据损失函数的反馈进行调整
- 向前传递:在前向传播过程中,输入数据通过线性传输层进行加权组合,然后经过激活函数处理后得到最终的输出结果
激活函数
-
阈值函数(Threshold Function)
- 输出为二值(0 或 1),根据输入是否超过某个阈值来决定
-
Sigmoid 函数
- Sigmoid 函数将任意输入映射到 之间,常用于二分类问题
- Sigmoid 函数的平滑性使得它在梯度下降等优化算法中表现较好
-
Tanh 函数(双曲正切函数)
- Tanh 函数将输入映射到 之间
- Tanh 函数在某些情况下比 Sigmoid 表现更好,因为它关于原点对称。
-
ReLU 函数(Rectified Linear Unit)
- ReLU 函数是目前深度学习中最常用的激活函数之一
- ReLU 函数计算简单,梯度下降时收敛速度快,但在输入为负值时存在梯度消失问题
-
Leaky ReLU
- Leaky ReLU 是 ReLU 的改进版本,允许输入为负值时有小的梯度
- 其中 是一个很小的常数
-
Parametric ReLU(PReLU)
- PReLU 是 Leaky ReLU 的进一步扩展,其中的 是一个可学习的参数,数学表达式类似于 Leaky ReLU,但 在训练过程中可以调整
特点
单层神经网络只能做简单的线性分类任务
两层神经网络
结构
两层神经网络除了一个输入层和一个输出层之外,还增加了一个中间层即隐藏层,此时中间层和输出层都是计算层,结构如图
- 输入层:接收来自外部的输入数据
- 隐藏层:位于输入层和输出层之间,用于处理输入数据并提取更高级的特征表示。隐藏层中的每个神经元都通过权重与输入层相连,并通过激活函数引入非线性
- 输出层:生成最终的预测结果或分类标签,输出层中的每个神经元也通过权重与隐藏层相连,并可能通过激活函数进行输出处理
- 偏执单元:一个只含有存储功能,且存储值永远为 1 的单元,在神经网络的每个层次中,除了输出层以外,都会含有这样一个偏置单元
1 | flowchart LR |
工作原理
- 前向传播:输入数据通过输入层进入网络,经过隐藏层的加权和激活函数处理,最终到达输出层并生成预测结果。前向传播过程中的计算可以表示为矩阵乘法和激活函数的应用
- 反向传播:根据预测结果与实际标签之间的差异(即损失函数),网络通过反向传播算法更新权重和偏置,以减小损失并提高预测准确性。反向传播过程中使用链式法则计算梯度,并通过梯度下降法或其他优化算法更新权重和偏置
激活函数
-
Sigmoid 函数:将输入映射到 0 和 1 之间,常用于二分类问题的输出层
- 容易产生梯度消失问题
-
Tanh 函数:将输入映射到 -1 和 1 之间,解决了 Sigmoid 函数输出不是零中心的问题
- 存在梯度消失的问题
-
ReLU 函数:线性整流单元(ReLU)函数是当前最受欢迎的激活函数之一,除二分类问题外,大部分都会使用ReLU函数
- 解决了梯度消失的问题(至少在正区间内),并且计算速度非常快
- 存在死亡 ReLU 问题,在输入为负的情况下梯度为 0,可能导致神经元永远不会被激活
-
Leaky ReLU函数:为了解决ReLU的死亡问题,Leaky ReLU 函数被提出
- 在输入为负的情况下,Leaky ReLU 函数给予一个小的梯度,确保梯度不会完全消失
-
Softmax 函数:通常用在多分类神经网络的输出层,将多个类别的输出映射为概率分布
- 将输出规范化为概率分布,所有输出值加起来为 1
- 计算量较大,特别是在类别数较多的情况下
特点
双层神经网络可以无限逼近任意函数
多层神经网络
多层神经网络是一种由多个神经元层组成的神经网络模型
结构
- 输入层:接收外部输入的数据
- 隐藏层:位于输入层和输出层之间,对输入数据进行多次非线性变换和特征提取,隐藏层可以有多层,每一层都由若干个神经元结点构成,该层的任意一个结点都与上一层的每一个结点相连,由它们来提供输入,经过计算产生该结点的输出并作为下一层结点的输入
- 输出层:根据任务的不同,输出层可以是一个神经元(用于二分类问题)或多个神经元(用于多分类问题或回归问题)。输出层对隐藏层传递过来的数据进行最终处理,得到预测结果
优点
- 非线性建模能力强:通过隐藏层的非线性变换,多层神经网络可以建立复杂的输入与输出之间的映射关系
- 多层神经网络可以高度并行化,利用硬件加速计算
- 多层神经网络可以通过增加层数和神经元的数量,处理大规模的数据集,提高模型的泛化能力
缺点
- 多层神经网络的训练过程需要大量的数据和计算资源,并且可解释性较差
- 其收敛速度可能较慢,且存在不可预测的局部极小值问题
原理及公式
-
前向传播:前向传播涉及将输入数据通过网络的所有层,逐层进行计算,直至输出层生成预测结果。在前向传播过程中,每一层的神经元会接收来自前一层的输出,经过激活函数处理后,传递给下一层的神经元
- 是第 层的线性组合
- 是第 层到第 层的权重矩阵
- 是第 层的激活输出
- 是第 层的偏置向量
-
损失函数:前向传播结束后,会得到一个预测输出。将这个预测输出与真实的目标值进行比较,计算出损失函数的值。损失函数衡量了模型预测结果与真实结果之间的误差
-
均方误差
- 是真实标签
- 是预测值
-
交叉熵误差(用于分类问题)
-
-
反向传播:反向传播的核心思想是将损失函数相对于输出的梯度反向传播回网络的每一层,从而计算出损失函数对每一层参数的梯度。首先计算输出层的误差,即预测输出与真实目标值之间的差异。然后根据链式法则,将这个误差反向传播到前面的隐藏层。对于每一层,计算损失函数关于该层权重的梯度
-
计算误差的导数
- 表示逐元素相乘
- 表示损失函数对 的梯度
- 是激活函数的导数
-
计算梯度
- 是样本数量
-
-
参数更新:根据计算出的梯度,使用优化算法更新每一层的权重和偏置,一般使用梯度下降法或其他变种实现的
- 是学习率
1 | def forward_prop(a_in, w, b, sigma): |
激活函数的选择
- 隐藏层中
- 优先考虑 ReLU 修正线性单元激活函数
- 计算效率高,收敛快,不存在梯度消失问题
- ReLU 在输入小于 0 时输出为 0,导致某些神经元的权重无法更新
- 也可以选择 Leaky ReLU,PReLU 等变体来避免上述问题
- 考虑使用 Tanh 函数
- 输出值在 -1 和 1 之间,以 0 为中心,使得优化过程更加容易
- 也存在梯度消失问题,并且计算量较大
- 谨慎使用 Sigmoid 函数
- 输出值在 0 和 1 之间,不是以 0 为中心
- 会导致优化过程变得困难,存在梯度消失问题
- 在隐藏层中不推荐使用
- 优先考虑 ReLU 修正线性单元激活函数
- 输出层中
- 对于二分类问题
- 通常使用 Sigmoid 函数,该函数将输出映射到 0 和 1 之间,表示属于某个类别的概率
- 多分类问题
- 通常使用 Softmax 函数,该函数可以将输出映射到多个类别的概率分布上,计算每个类别的概率值,并且保证所有概率的总和为 1
- 回归问题
- 通常使用线性激活函数 identity 函数,该函数直接将输入映射到输出,不进行非线性变换
- 对于二分类问题
- 其他因素
- 复杂度:选择激活函数时,需要考虑其计算复杂度
- 性能:通过实验和验证来选择最合适特定任务的激活函数,可以使用交叉验证等方式来评估不同的激活函数对模型性能的影响
- 需求:根据任务需求来选择合适的激活函数
引入激活函数的原因
- 引入非线性:激活函数引入非线性能解决非线性问题
- 增强表达能力:激活函数使得神经网络能够学习和表示更复杂的函数关系,通过堆叠多层非线性激活函数可以逼近任意复杂的函数
- 缓解梯度消失与梯度爆炸问题:适当的激活函数可以帮助缓解梯度消失和梯度爆炸的问题
- 正则化效果:有些激活函数有正则化的效果,可以减少过拟合
- 特征选择和稀疏性:激活函数可以使得神经网络具有稀疏性,有助于特征选择,使得神经网络更加关注重要的输入特征
函数介绍
Sequential
keras.models.Sequential 顺序模型是多个网络层的线性堆叠,可以通过网络层实例的列表将参数传递给 Sequential 构造器,来创建一个对应的模型
1 | model = tf.keras.models.Sequential([ |
也可以使用 add 方法来添加层,利用该方法添加层时时顺序添加进模型的
1 | model = tf.keras.models.Sequential() |
上述两段代码实现了相同的功能
Dense
Dense 是核心网络层,就是全连接层
1 | keras.layers.Dense(units, |
其中
units输出的空间维度activation激活函数use_bias该层是否使用偏置向量kernel_initializer权重矩阵的初始化器bias_initializer偏置向量的初始化器activity_regularizer运用到该层的输出的正则化函数kernel_constraint运用到该层的权重矩阵的约束函数bias_constraint运用到偏置向量的约束函数
在该全连接层中所实现的计算为
作为模型的第一层,通常会指定输入尺寸,例如下
1 | keras.layers.Dense(32, input_shape = (10, )) |
输入尺寸和输出尺寸
- 输入尺寸为
(batch_size, ..., input_dim),其中batch_size就是批处理数据的数据量 - 输出尺寸为
(batch_size, ..., units)
activation
激活函数,可以通过设置单独的激活函数层来实现,也可以在构造层对象 Dense 时通过传递 activation 参数实现,也可以传递一个函数来作为激活函数
1 | model.add(Dense(64, activation = 'tanh') |
输入尺寸和输出尺寸
输入尺寸可以为任意尺寸,输出尺寸与输入尺寸一致
预定义激活函数
-
keras.activations.elu(x, alpha = 1.0)指数线性单元x输入张量alpha一个标量,表示负数部分的斜率
-
keras.activations.softmax(x, axis = -1)x输入张量axis代表 softmax 所作用的维度,整数
-
keras.activations.selu(x)可伸缩的指数线性单元x输入张量alpha标量,表示负数部分的斜率beta标量,表示指数线性激活函数的伸缩指数
-
keras.activations.softplus(x)x输入张量
-
keras.activations.softsign(x)x输入张量
-
keras.activations.relu(x, alpha = 0.0, max_value = None, threshold = 0.0)整流线性单元x输入张量alpha负数部分的斜率max_value输出的最大值threshold阈值
-
keras.activations.tanh(x)双曲正切激活函数x输入张量
-
sigmoid(x)x输入张量
-
hard_sigmoid(x)计算速度比sigmoid更快,实际上就是将sigmoid函数做了线性的近似x输入张量
-
keras.activations.exponential(x)自然数指数激活函数x输入张量
-
keras.activations.linear(x)线性激活函数x输入张量
-
keras.layers.LeakyReLU(alpha = 0.3) -
keras.layers.ELU(alpha=1.0)指数线性单元alpha负数因子的尺度
-
keras.layers.ThresholdedReLU(theta=1.0)带阈值的修正线性单元theta阈值
-
keras.layers.LeakyReLU(alpha = 0.3)当神经元未激活时,仍然允许赋予一个很小的梯度alpha负斜率系数
-
keras.layers.PReLU(alpha_initializer = 'zeros' , alpha_regularizer = None, alpha_constraint = None, shared_axes = None)参数化的 Relu- **
al**pha_initializer权重的初始化函数 alpha_regularizer权重的正则化方法alpha_constraint权重的约束shared_axes激活函数共享可学习参数的轴
- **
compile
1 | compile(optimizer, |
用于配置训练模型,是内置于 Sequential 的方法,其中
optimizer优化方法,传入参数为字符串或者优化器实例loss损失函数,传入参数为字符串函数名,损失函数或者loss实例metrics在训练和测试期间的模型评估标准,通常使用字符串列表传入参数,可使用的参数如下accuracy精确度binary_accuracy二分类准确度categorical_accuracy分类准确度sparse_categorical_accuracy稀疏分类准确度top_k_categorical_accuracy计算前 K 个元素的分类精确度sparse_top_k_categorical_accuracy计算前 K 个元素的稀疏分类准确度cosine_proximity计算余弦临近感应clone_metric克隆度量指标,若有状态,返回评估指标的克隆clone_metrics克隆给定的评估指标序列/字典
loss_weights可选的指定标量系数(浮点数)的列表或字典, 用以衡量损失函数对不同的模型输出的贡献sample_weight_mode如果需要执行按时间步采样权重(2D 权重),将其设置为temporal。 默认为None,为采样权重(1D)weighted_metrics在训练和测试期间,由sample_weight或class_weight评估和加权的度量标准列表target_tensors默认情况下,Keras 将为模型的目标创建一个占位符,在训练过程中将使用目标数据
optimizer
优化器是建立 Keras 模型所需要用到的参数之一
内置优化器实例
keras.optimizers.SGD(learning_rate = 0.01, momentum = 0.0, nesterov = False)随机梯度下降优化器learning_rate学习率momentum用于加速 SGD 在相关方向上前进,并抑制震荡nesterov是否使用 Nesterov 动量,即 Nestrov 动量(NAG)优化
keras.optimizers.RMSprop(learning_rate = 0.001, rho = 0.9)RMSProp 优化器learning_rate学习率rhoRMSProp 梯度平方的移动均值的衰减率
keras.optimizers.Adagrad(learning_rate = 0.01)Adagrad 优化器,是一种具有特定参数学习率的优化器,它根据参数在训练期间的更新频率进行自适应调整。参数接收的更新越多,更新越小learning_rate学习率
keras.optimizers.Adadelta(learning_rate = 1.0, rho = 0.95)Adadelta 优化器,是 Adagrad 的一个具有更强鲁棒性的的扩展版本,它不是累积所有过去的梯度,而是根据渐变更新的移动窗口调整学习速率learning_rate初始学习率rhoAdadelta 梯度平方移动均值的衰减率
keras.optimizers.Adam(learning_rate = 0.001, beta_1 = 0.9, beta_2 = 0.999, amsgrad = False)Adam 优化器learning_rate学习率beta_1位于 0 和 1 之间,通常比较接近 1beta_2位于 0 和 1 之间,通常比较接近 1amsgrad是否应用此算法的 AMSGrad 变种
keras.optimizers.Adamax(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)Adamax 优化器,是 Adam 算法基于无穷范数(infinity norm)的变种learning_rate学习率beta_1位于 0 和 1 之间,通常比较接近 1beta_2位于 0 和 1 之间,通常比较接近 1
keras.optimizers.Nadam(learning_rate = 0.002, beta_1 = 0.9, beta_2 = 0.999)一种结合了 Nesterov 动量和 Adam 的优化算法。与 Adam 相比,Nadam 添加了 Nesterov 动量的修正,可以更好地处理稀疏梯度问题learning_rate学习率beta_1位于 0 和 1 之间,通常比较接近 1beta_2位于 0 和 1 之间,通常比较接近 1
Loss
损失函数是编译模型时所需的两个参数之一,损失函数有两个参数 y_true 和 y_pred 分别是目标值和目标预测值,而且两者的 shape 是一致的
内置损失函数实例
-
keras.losses.mean_squared_error(y_true, y_pred)均方误差 -
keras.losses.mean_absolute_error(y_true, y_pred)平均绝对误差 -
keras.losses.mean_absolute_percentage_error(y_true, y_pred)平均绝对百分比误差 -
keras.losses.mean_squared_logarithmic_error(y_true, y_pred)均方根对数误差 -
keras.losses.squared_hinge(y_true, y_pred)Squared Hinge 损失函数的公式通常用于支持向量机(SVM)的上下文中,特别是在处理多分类问题时- 对于二分类问题来说
- 对于多分类问题
- 样本在第 个类别上的得分
- 样本在其真实类别上的得分
-
keras.losses.hinge(y_true, y_pred)铰链损失函数,专门用于二分类问题- 对于二分类问题
- 对于多酚类问题
-
keras.losses.categorical_hinge(y_true, y_pred)用于衡量模型预测值与真实标签之间的差距,并对错误分类或距离分类边界过近的样本点施加惩罚 -
keras.losses.logcosh(y_true, y_pred)Log-Cosh 是应用于回归任务中的另一种损失函数,比 L2 损失更平滑,Log-cosh 是预测误差的双曲余弦的对数 -
keras.losses.huber_loss(y_true, y_pred, delta = 1.0)综合了均方误差损失函数和平均绝对误差损失函数的优点,消除了两者的缺点 -
keras.losses.categorical_crossentropy(y_true, y_pred, from_logits = **False**, label_smoothing = 0)交叉熵损失函数 -
keras.losses.sparse_categorical_crossentropy(y_true, y_pred, from_logits = **False**, axis = -1)稀疏交叉熵损失函数,不需要把 转为 one_hot 编码,直接使用整数编码即可 -
keras.losses.binary_crossentropy(y_true, y_pred, from_logits = **False**, label_smoothing = 0) -
keras.losses.kullback_leibler_divergence(y_true, y_pred)KL 散度,用于度量两个概率分布相似度的指标- 对于离散的随机变量,存在两个概率分布 P 和 Q,定义散度为
- 对于连续的随机变量,定义散度为
- 定义对应的损失函数如下
-
keras.losses.poisson(y_true, y_pred)泊松分布- 泊松分布是一中离散分布,概率计算公式如下
- 对于未进行归一化和对数化处理的,对应的损失函数如下,最后一项可以省略或者用斯特林公式近似
- 对于进行过归一化和对数化处理的,对应的损失函数如下
-
keras.losses.cosine_proximity(y_true, y_pred, axis=-1)余弦相似度损失函数 -
keras.losses.is_categorical_crossentropy(loss)
fit
1 | fit(x=None, |
x输入数据,可以是numpy.array或者字典y目标数据,与x类似,需要保证x与y的第一个维度大小一致,也就是y.shape[0] = x.shape[0],同时y.shape[1]也需要与Dense定义时的输出维度一致batch_size每次梯度更新的样本数量,如果未指定默认为 32epochs模型训练迭代次数verbose日志显示模式- 0 安静模式,不会显示训练进度
- 1 进度条模式
- 2 每轮一行,不显示进度条
callbacks可以为keras.callbacks.Callback实例。可以在训练和验证过程中使用的回调函数validation_split用作验证集的训练数据的比例,位于 0~1 之间,模型将分出一部分不会被训练的验证数据,并将在每一轮结束时评估这些验证数据的误差和任何其他模型指标validation_data用于在每个轮次结束后评估损失和任意指标的数据,模型不会在这个数据上训练shuffle是否在每轮迭代之前混洗数据class_weight可选的字典,用来映射类索引(整数)到权重(浮点)值,用于在训练期间加权损失函数sample_weight训练样本的可选 Numpy 权重数组,用于在训练期间对损失函数进行加权initial_epoch开始训练的轮次。实际上训练次数有一个计数,从 0 开始直到epochs为止,这个参数指定的是开始的计数值steps_per_epoch在声明一个轮次完成并开始下一个轮次之前的总步数validation_steps在每个轮次结束时执行验证时,在停止之前要执行的步骤总数,只有在提供了validation_data时才有用validation_freq只有在提供了验证数据时才有用- 整数类型:指定在验证之前进行多少轮训练
- 元组或数组:指定在那一轮训练进行验证
max_queue_size生成器队列的最大尺寸,默认为 10workers当使用基于进程的多线程时的最大进程数use_multiprocessing是否使用基于进程的多线程,默认为False
evaluate
1 | evaluate(x=None, |
x输入数据y目标数据batch_size每次梯度更新的样本数,默认为 32verbose日志显示模式- 0 安静模式,不会显示训练进度
- 1 进度条模式
- 2 每轮一行,不显示进度条
sample_weight训练样本的可选 Numpy 权重数组,用于在训练期间对损失函数进行加权steps声明评估结束之前的总步数callbacks可以为keras.callbacks.Callback实例。可以在训练和验证过程中使用的回调函数max_queue_size生成器队列的最大尺寸,默认为 10workers当使用基于进程的多线程时的最大进程数use_multiprocessing是否使用基于进程的多线程,默认为False
callback
回调函数是一个函数的合集,会在训练的阶段中所使用。可以使用回调函数来查看训练模型的内在状态和统计,也可以传递一个回调函数列表。在训练时,相应的回调函数的方法就会被在各自的阶段被调用
内置 callback 实例
keras.callbacks.callbacks.BaseLogger(stateful_metrics = None)会积累训练轮平均评估的回调函数,这个回调函数被自动应用到每一个 Keras 模型上面stateful_metrics可重复使用不应在一个epoch上平均的指标的字符串名称
keras.callbacks.callbacks.TerminateOnNaN()当遇到NaN损失会停止训练keras.callbacks.callbacks.ProgbarLogger(count_mode = 'samples', stateful_metrics = None)会把评估以标准输出打印的回调函数count_mode计数模式,进度条是否计数看见的样本或者步骤"steps""samples"
stateful_metrics可重复使用不应在一个epoch上平均的指标的字符串名称
keras.callbacks.callbacks.History()将所有事件都记录到History对象的回调函数keras.callbacks.callbacks.ModelCheckpoint(filepath, monitor = 'val_loss', verbose = 0, save_best_only = False, save_weights_only = False, mode = 'auto', period = 1)在每个训练期之后保存模型filepath保存模型的路径monitor被检测的数据verbose详细模型信息,0 或 1save_best_only是否仅保存最优的训练模型mode如果save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值minmaxauto
save_weights_only是否只保存权重period每个检查点之间的间隔,也就是训练的轮数
keras.callbacks.callbacks.EarlyStopping(monitor = 'val_loss', min_delta = 0, patience = 0, verbose = 0, mode = 'auto', baseline = None, restore_best_weights = False)当被监测的数量不再提升,则停止训练monitor被监测的数据min_delta被监测的数据中被认为是提升的最小变化patience在监测数据经过多少轮次没有明显变化时停止训练verbose详细信息模式modemin当监测的数据停止下降时,训练停止max当监测的数据停止上升时,训练停止auto方向会自动从被监测的数据的名字中判断出来
baseline要监控的数量的基准值,如果模型没有显示基准的改善,训练将停止restore_best_weights是否从具有监测数量的最佳值的时期恢复模型权重,如果为False则认为是训练最后一步获得权重
keras.callbacks.callbacks.RemoteMonitor(root = '[http://localhost:9000](http://localhost:9000/)', path = '/publish/epoch/end/', field = 'data', headers = None, send_as_json = False)将事件数据流到服务器的回调函数,需要使用到request库root目标服务器根地址path相对于目标服务器的地址field数据被保存的位置headers自定义http的头字段send_as_json请求是否以 json 形式发送
keras.callbacks.callbacks.LearningRateScheduler(schedule, verbose = 0)学习速率定时器schedule一个函数,接受轮索引数作为输入(整数,从 0 开始迭代) 然后返回一个学习速率作为输出verbose信息显示模式
keras.callbacks.callbacks.ReduceLROnPlateau(monitor = 'val_loss', factor = 0.1, patience = 10, verbose = 0, mode = 'auto', min_delta = 0.0001, cooldown = 0, min_lr = 0)当标准评估停止提升时,降低学习速率。当模型的学习进度停止了,适当的降低学习率会有效果。这个回调函数监测一个数据并且当这个数据在一定次数的训练轮之后还没有进步, 那么学习速率就会降低monitor被检测的数据factor更新学习速率的参数,新的学习率=旧学习率 *factorpatience在质量检测多少轮没有明显变化时停止verbose详细信息模式modemin当监测的数据停止下降时,训练停止max当监测的数据停止上升时,训练停止auto方向会自动从被监测的数据的名字中判断出来
min_delta对于测量新的最优化的阀值,就是检测值被认为变化时的最小变化值cooldown在学习率降低之后,重新恢复正常之前等待的训练轮数min_lr学习率的下边界
keras.callbacks.callbacks.CSVLogger(filename, separator = ',', append = False)把训练结果数据流保存在 csv 文件中的回调函数filenamecsv 文件名separator用于隔离各个数据之间的字符串append如果文件存在是否以追加的方式保存数据流
keras.callbacks.callbacks.LambdaCallback(on_epoch_begin = None, on_epoch_end = None, on_batch_begin = None, on_batch_end = None, on_train_begin = None, on_train_end = None)在训练进行中创建简单,自定义的回调函数的回调函数,这个回调函数和匿名函数在合适的时间被创建on_epoch_begin在每轮开始时被调用on_epoch_end在每轮结束之后调用on_batch_begin在每批开始前调用on_batch_end在没批结束之后调用on_train_begin在模型训练前调用on_train_end在模型训练结束之后调用
keras.callbacks.tensorboard_v1.TensorBoard(log_dir = './logs', histogram_freq = 0, batch_size = 32, write_graph = True, write_grads = False, write_images = False, embeddings_freq = 0, embeddings_layer_names = None, embeddings_metadata = None, embeddings_data = None, update_freq = 'epoch')TensorBoard 分析可视化工具log_dir用于保存分析日志的文件名histogram_freq对于模型中各个层计算激活值和模型权重直方图的频率batch_size用以直方图计算的传入神经元网络输入数据的大小write_graph是否可视化图像write_grads是否可视化梯度值直方图write_images是否将模型权重以图片可视化embeddings_freq被选中的嵌入层会被保存的频率embeddings_layer_names被检测层名称列表embeddings_metadata字典,对应层的名字到保存有这个嵌入层元数据文件的名字embeddings_data要嵌入在embeddings_layer_names指定的层的数据update_freq更新频率,也就是写入 TensorBoard 的频率batch在每一批数据之后将损失和评估值写入 TensroBoard 中epoch在每一轮数据之后写入损失和评估值- 整数 在对应的样本数量之后写入损失和评估值
自定义回调函数
自定义回调函数时,只需要定义继承自 keras.callbacks.Callback 基类的类即可,也需要实现一些函数以及它们的调用时期如下
on_epoch_begin在每轮开始时被调用on_epoch_end在每轮结束之后调用on_batch_begin在每批开始前调用on_batch_end在没批结束之后调用on_train_begin在模型训练前调用on_train_end在模型训练结束之后调用
Utils
Utils 是 Keras 里的一个工具包
keras.utils.CustomObjectScope()提供更改为_GLOBAL_CUSTOM_OBJECTS无法转义的范围,即自定义对象作用域。提供定制类的作用域,在该作用域内全局定制类能够被更改,但在作用域结束后将回到初始状态。 以with声明开头的代码将能够通过名字访问定制类的实例,在with的作用范围,这些定制类的变动将一直持续,在with作用域结束后,全局定制类的实例将回归其在with作用域前的状态。keras.utils.HDF5Matrix(datapath, dataset, start = 0, end = None, normalizer = None)使用 HDF5 数据集代替numpy。array的方法。提供了start和end来数据集切片,还可以提供正则化函数,该函数会在每片数据检索时自动调用datapathHDF5 的文件路径dataset字符串,datapath中的 HDF5 数据集名称。所以数据集的全路径为datapath + datasetstart所需的指定数据集的切片开始的位置end所需的指定数据集的切片结束的位置normalizer早检索数据时调用的函数,可以将数据集标准化
keras.utils.Sequence()序列,用于拟合数据序列的基对象keras.utils.to_categorical(y, num_classes = None, dtype = 'float32')将类别向量转化为二进制类矩阵- 转化为
y需要转换成矩阵的类矢量num_classes总类别数dtype输入所期望转化成的数据类型
keras.utils.normalize(x, axis = -1, order = 2)便准化numpy.arrayx需要标准化的numpy.arrayaxis需要标准化的轴order规范化的方式- 1 就是 L1 归一化
- 2 就是 L2 归一化
keras.utils.get_file(fname, origin, untar=False, md5_hash=None, file_hash=None, cache_subdir='datasets', hash_algorithm='auto', extract=False, archive_format='auto', cache_dir=None)如果文件fname不存在缓存中时,从origin处下载文件。默认情况下origin处的文件将会被下载到缓存子目录下fnam文件名,如果设置了绝对路径,那么文件将会被下载到对应的位置origin文件原始的 urluntar是否需要解压文件md5_hash用于校验 md5 的哈希值file_hash下载后的文件的期望哈希字符串,支持sha256和md5两个哈希算法cache_subdir在keras缓存目录下的保存文件的子目录。如果给定了绝对路径,则文件将会被保存在对应的路径下hash_algorithm选择哈希算法来校验文件,可以选择的参数如下'md5''sha256''auto'将自动检测所使用的哈希算法
extract是否要尝试解压该文件archive_format尝试提取文件的存档格式'auto'默认为['tar'. 'zip']'tar'包含tartar.gztar.bz文件类型'zip'None
cache_dir存储缓存文件的位置,默认使用 keras 目录
keras.utils.print_summary(model, line_length=None, positions=None, print_fn=None)打印模型的概况modelkeras的模型实例line_length打印的每行的总长度,主要是为了适应不同大小的终端长度positions每行中日志元素的相对或绝对位置,默认为[.33, .55, .67, 1.]print_fn需要使用的打印函数,可以设置为自定义函数,默认为pintf
keras.utils.plot_model(model, to_file='model.png', show_shapes=False, show_layer_names=True, rankdir='TB', expand_nested=False, dpi=96)将 keras 的模型转为dot格式并且保存到文件中model模型实例to_file绘制图像的文件名show_shape是否显示尺寸信息show_layer_names是否显示层的名字rankdir传递给pyDot的rankdir参数,一个指定绘图格式的字符串'TB'创建一个垂直绘图'LR'创建一个水平绘图
expand_nested是否扩展嵌套模型为聚类dpi点 DPI- 但是需要注意的是,这个函数的使用需要安装
pydot和graphvizpip install pydotgraphviz需要在 官网 上下载并且安装,并且需要将安装路径下的bin文件夹添加到环境变量中
keras.utils.multi_gpu_model(model, gpus=None, cpu_merge=True, cpu_relocation=False)将模型复制到多个 GPU 上,该功能实现了单机多 GPU 数据并行- 运行原理
- 将模型输入分成多个子批次
- 在每个子批次上应用模型副本,每个模型的副本都在 GPU 上运行
- 在 CPU 上将结果连接成一个大批量
model模型实例,为了避免 OOM 错误,该模型可建立在 CPU 上gpus不小于 2 的整数或者整数列表,表示用于创建模型副本的 GPU 数量cpu_merge是否强制合并 CPU 范围内的模型权重cpu_relocation是否在 CPU 的范围内创建模型的权重
- 运行原理
保存加载模型
model.save("number_identify.keras")保存模型new_model = tf.keras.models.load_model('number_identify.keras')加载模型
需要注意的是,在使用 keras 时需要注意不能使用别的库里面的函数,否则会导致加载时标签错误而加载失败,例如
1 | model = tf.keras.models.Sequential() |
实例
多分类问题实例——手写数字识别
1 | import tensorflow as tf |
这里使用 keras 官方文档中的例子来做测试。测试结果如下,测试的精确度达到了 0.9685