前言
由于 xv6-kernel 的代码是在 qemu+riscv 中进行仿真的,所以首先我们需要安装 qemu 和 riscv 仿真工具链
riscv工具链
下载源码
源码地址为
也可以直接使用 git 指令下载
1 | git clone https://gitcode.com/riscv-collab/riscv-gnu-toolchain/overview |
这里直接下载默认分支
下载模块
打开下载的源码目录下,找到名为 .gitmodules 的文件,这里面就是每个子模块的路径和分支。如果没有梯子,就可以根据其对应的名字在 Gitee 上查找对应的模块,然后直接将其下载到 riscv-gnu-toolchain 这个文件夹下,但是对应的模块要下载到对应的文件夹里。不仅如此,还需要下载该模块对应的分支,分支一定不能错。可以使用如下指令
1 | git clone -b branch_name url module_name |
其中 branch_name 是分支名称, url 是下载链接,也就是 Gitee 上对应的模块的仓库地址, module_name 就是需要将这个模块放入的文件夹的名称,需要与 .gitmodules 文件中指定的模块的 path 一致
编译安装
安装之前需要先安装依赖
1 | sudo apt-get install autoconf automake autotools-dev curl python3 python3-pip libmpc-dev libmpfr-dev libgmp-dev gawk build-essential bison flex texinfo gperf libtool patchutils bc zlib1g-dev libexpat-dev ninja-build git cmake libglib2.0-dev |
然后在 /opt 下创建 riscv 目录,并且修改其权限为所有权限
1 | sudo mkdir /opt/riscv |
还需要安装 libncurses5-dev 库,这个库使得能够在使用 gdb 调试时使用 layout 指令,先安装再编译 riscv 才生效
编译
1 | cd riscv-gnu-toolchain |
执行完成没有报错的话,就可以查看 /opt/riscv 目录下,可以看到里面有 riscv 的工具
环境配置
需要编辑 ~/.bashrc 文件,在文件末尾添加如下两行
1 | export RISCV="/opt/riscv" |
然后使配置文件生效
1 | source ~/.bashrc |
测试
创建一个文件 hello.c
1 |
|
然后使用 riscv 的 gcc 编译器编译
1 | riscv64-unkonwn-linux-gnu-gcc hello.c -o hello |
如果编译没有报错就成功了,但是 Ubuntu 不是 riscv 架构的,所以不能运行这个可执行文件
qemu安装
安装依赖
1 | sudo apt update |
python版本
python版本必须是 ≥ 3.6 的,使用下列指令查看 python 版本
1 | python3 --version |
安装 ninja
1 | sudo apt update |
下载源码
由于官网下载较慢,所以可使用命令下载
1 | wget https://download.qemu.org/qemu-6.2.0.tar.xz |
在终端输入指令解压
1 | xz -d qemu-6.2.0.tar.xz |
编译安装
首先进入解压后的文件夹,新建安装目录,然后 configure 指令
1 | cd qemu-6.2.0 |
编译源码
1 | make -j8 |
安装
1 | sudo make install |
下载 xv6源代码
xv6源代码仓库地址为 github-xv6
使用指令下载该源代码
1 | git clone https://github.com/mit-pdos/xv6-riscv.git |
xv6
介绍
代码非常简洁,只有 6000 行代码,大部分是 C 语言和汇编语言,而且代码中没有依赖任何库函数,这也是内核程序员需要注意的
在 xv6 中所实现的用户操作有
- sh
- cat
- echo
- grep
- kill:用于杀死一个终端程序
- ln:创建一个文件的硬链接
- ls:内容目录
- mkdir:创建目录
- rm:删除文件
- wc:计算文件的单词数量
SMP
它是适用于多核的处理器的,并且所有进程共享内存,一共是 128MB
硬件设备
- UART:同步串口通信设备,多个内核公用
- DISK:磁盘,多个内核公用
- TIMER:定时器,一个内核有一个定时器
- PLIC:平台级中断处理器,这是一个单独的芯片或者电路处理来自于不同的设备的中断,会计算那个核心中断并且允许处理中断。模拟器将会模拟平台级中断处理
- CLINT:核心本地中断控制器,这也是模拟的一部分,每个核心都有一个核心本地中断控制器,所以操作系统也需要处理这些东西
内存管理
内存管理比较简单
- 物理内存分为页,页面大小是固定的 4KB
- 从空闲列表中为内核分配内存,空闲链表至少有一个未使用的页面。这是一个简单的链表,它从空闲列表中分配页面。当一个页面不再使用时,会将该页面返回到空闲链表的最先面
- 在操作系统中没有对象。在 xv6 中有几种不同的结构,当然它们是指着,但是使用面向对象的编程语言,可以分配可变大小的内存
- 没有
malloc,虚拟地址空间由页表处理 - 页表:分为三个等级。每个进程有一个页表,此外内核本身还有一个页表,用于映射所有内存空间。内核页表被所有进程共享。页表硬件可以将数据页标记为可读,可写和可执行。R / W / X / U / V
任务调度
- 基本上是一个循环调度
- 每个过程有一个时间片,并且是固定的时间片——1000000 cycles。每个被调度的程序都在任务队列上等待着被调用。
- 所有进程共享一个就绪队列。内核会搜索一个准备好运行的进程,从队列中取出,并且为它分配时间片,运行结束之后会把它放回到就绪队列中,继续寻找另一个可运行的进程,并且内核会不断遍历该就绪队列。在这个队列中,线程会被标记为可运行和不可运行两种状态
启动顺序
- 使用
qemu来启动内核几乎跳过了所有的引导项 - RISC-V 会模拟物理内存,把内核代码放在一个固定的位置。
- xv6 不支持引导加载项,主引导记录或者 BIOS 之类的东西
锁
xv6 使用了几种锁来进行锁定和并发控制
- Spin Locks 自旋锁,在内存中只有一个字来表示锁。如果锁是未持有的或者自由的,这个字为 0,否则为 1。有两个用户可调用的方法。
-
acquire 获取,就是等待自旋锁状态被释放,一旦获取锁就会将其置为 1
-
release 释放,就是简单的将自旋锁状态设置为 0
还有两个线程所调用的方法
-
sleep 执行之后,线程将会结束它的时间片,并且将以不可运行的状态放回到就绪队列中,直到被唤醒
-
release 如果一个睡眠中的进程被唤醒,那它将会从睡眠状态改为可运行状态,然后它就会得到时间片
-
- 选择性禁用中断,每个核心都有一个状态控制字,这个控制字可以被设置也可以被清除。它表示要么启用并且允许中断,要么禁用。通过禁用中断可防止一个线程被中断。但是这只能保证在当前内核中的线程不会被其它线程中断,不能保证其他内核的中断
一些固定的限制
- xv6 中有一些固定的限制,这些都是用磅符号定义声明的,例如进程数量只是一个固定的数字,最大可打开的文件数量也是固定的。
- 在内核中更加倾向于使用数组而不是链表,在一些情况下,使用线性搜索来遍历这些链表。例如杀死某个进程就是通过遍历进程表并且对比进程号进行线性搜索来杀死该进程
用户地址空间
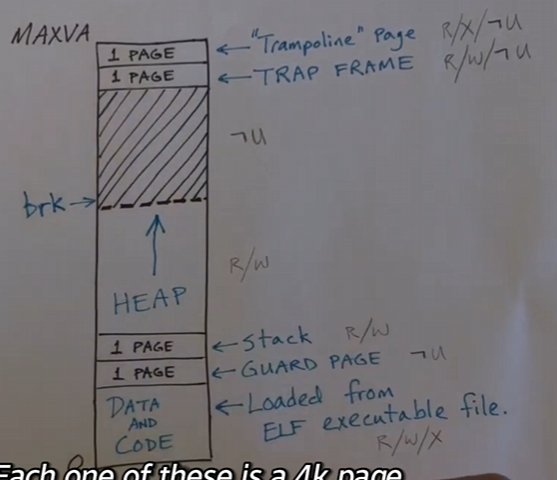
这就是用户地址空间,分配内存时以页为单位进行内存分配。
- 当使用
exec操作时,内核将进入文件系统并且找到可执行文件,它将分配几个整页面,会把数据读入到data and code区域,然后这些页面将会被标记为可读,可写,并且可由内核执行。 - 并且还为栈分配了一个页面,而且这个栈只有一个页面,这导致很多需要将堆栈超出 4KB 的程序不能在 xv6 中运行。如果一个程序的堆栈需要增长到 4KB 以上时,会被系统终止
- 在 linux 或者 unix 系统中,栈通常放在高内存中,并且向下增长,直到堆栈相互触碰
- 除此以外,xv6 还有一个安全页,不可读,不可写,在用户模式下无法访问,当用户想要获取这部分空间时,整个进程将会被终止
- 堆在栈之后开始,并且以页面为单位增长,会调用内存来分配一些空闲的时间给堆使用,这些页面将会标记为可读可写
- 用户可以在堆内存中任意的
malloc内存,分配内存
- 用户可以在堆内存中任意的
- 在虚拟内存空间最上面还有两个页面
trampaline page被标记为用户模式不可访问,包含代码,所以它是可执行的。当陷阱或者异常发生时,将在 trampaline page 中执行代码trap frame是可读可写的,寄存器将会被保存在这个位置- 当中断或者异常发生时,寄存器以及用户进程的整个状态都会被保存,并且将其按照
trampaline page中的代码保存在陷阱帧中。每个虚拟地址空间都有自己的陷阱框架页面,trampalline page被所有进程共享,所以它们都被映射到相同的地址空间,但是有着不同的物理记忆页面。
- 虚拟内存的大小正还是 256GB ,所以空闲内存会有很多,并且堆可能不会占用太多。而且内存中所存储的内容不可能超过实际的物理内存大小
- 在 C 语言程序运行时的入口
main函数可以传入argc表示参数数量,args表示传入参数,arge来传入系统环境变量,但是 xv6 不支持环境变量。内核中的代码设置虚拟地址空间,并且将为栈分配一个页面,会将参数推入栈中,并且将栈的指针指向栈底,然后将栈的指针存入寄存器中。所以在用户程序运行第一条指令时,它会在栈上找到参数 - 页表有三种方案,xv6 使用 SV39,所以虚拟地址的内存大小为 ,正好是 512GB 的大小,所以使用这种方案意味着可以访问 512GB 大小的内存。而 xv6 只使用 的内存,就是 256GB,所以最大内存地址为 0x4000000000
- SV32:是一个两级页表方案
- SV39:应用于 xv6,是一个三级页表方案
- SV48:是一个四级页表方案
内核代码
risc-v汇编指令码
ld例如ld t0, 0(t1)t0 = memory[t1 + 0]将t1的值加上 0,将这个值作为地址,取出这个地址所对应的内存中的值,将这个值赋值给t0lw例如lw t2, 20(t3)t2 = memory[20 + t3]lw与ld的区别就在于ld是从内存取出64位数值,而lw是取出32位数值。lh例如lh t4, 30(t5)t4 = memory[30 + t5]从内存中取出16位数值lb例如lb t4, 30(t5)t4 = memory[30 + t5]从内存中取出8位数值sd例如sd t0, 0(t1)memory[0+t1] = t0将t1的值加上0,将这个值作为地址,将t0的值存储到上述地址所对应的内存中去sw例如sw t0, 0(t1)memory[0+t1] = t0与sd的区别在于sw只会将t0的低32位数值存储到相应的内存。sd会将t0的64位都存入sh例如sh t0, 0(t1)memory[0+t1] = t0只将t0的低16位所对应的数值存入,也就是一个half word大小sb例如sb t0, 0(t1)memory[0+t1] = t0只存入8位,一个byte大小lwu例如lwu t2, 20(t3)t2 = memory[20 + t3]lw与lwu的区别在于,前者取出32位数值作符号扩展到64位,而后者做无符号扩展到64位lhu例如lhu t4, 30(t5)t4 = memory[30 + t5]lbu例如lbu t4, 30(t5)t4 = memory[30 + t5]
内核代码文件
bio.c文件系统的磁盘块缓存console.c连接到用户的键盘和屏幕entry.S首次启动指令exec.cexec()系统调用file.c文件描述符支持fs.c文件系统kalloc.c物理页面分配器kernelvec.S处理来自内核的陷入指令以及计时器中断log.c文件系统日志记录以及崩溃修复main.c在启动过程中控制其他模块初始化pipe.c管道plic.cRISC-V中断控制器printf.c格式化输出到控制台proc.c进程和调度sleeplock.cLocks that yield the CPUspinlock.cLocks that don’t yield the CPU.start.c早期机器模式启动代码string.c字符串和字节数组库swtch.c线程切换syscall.cDispatch system calls to handling function.sysfile.c文件相关的系统调用sysproc.c进程相关的系统调用trampoline.S用于在用户和内核之间切换的汇编代码trap.c对陷入指令和中断进行处理并返回的C代码uart.c串口控制台设备驱动程序virtio_disk.c磁盘设备驱动程序vm.c管理页表和地址空间
系统开始
xv6 系统在多核的计算机上运行时,开始时每个核心都同时开始,并且它们享有共同的内存,所以他们会执行相同的代码,这个代码位于 entry.S 文件中
entry.S
代码很少,在这个文件中运行的是将一些环境设置好,以便可以执行 C 程序代码。初始化栈指针寄存器(SP寄存器)以及 线程指针(TP寄存器,会存储当前是第几个内核,整个过程中,寄存器将在核心上保持不变)。由于每个核心都是共享内存的,所以它们将访问同一组全局变量,但是每个内核都会需要自己的栈,并且不能重合,所以每个核心都有一个单独的空间。然后将控制权转交给 start.c 中一个名为 start 的 C 函数。
start.c
将控制权转交给 main.c ,也就是 main 函数。进入 start.c 函数之后,程序会进入机器模式,然后会做一些 bookkeeping 的事情,之后进入监督模式,也就是把系统交给用户管理。每个核心都会执行 start 函数和 main 函数
main
在函数中会判断内核号,0 号内核会进行一些初始化的操作,等待 0 号内核初始化完成之后,其它的内核会进行一些页面,内核陷阱列表和系统级中断等初始化。0 号内核的最后语句是初始化用户程序。当所有内核执行完成之后,每个内核都会调用一个调度器,就是寻找一个要执行的进程。
在 main 中有一段神奇的代码 __sync_synchronize ,这个函数将会告诉编译器,一定要完成这条代码之前的东西再执行这条代码之后的东西
spinlock
用一个单词表示自旋锁,如果内容是 0,那就表示锁是释放掉的,内容是 1,表示锁被占用
1 | // Mutual exclusion lock. |
还有两个参数
name可以给该自旋锁设置名字,它所指向的是一个字符串cpu指定某一个 CPU,每个核都有一个与之相关联的结构体cpu,这个字段包含一个指向cpu结构的指针,用于表示当前持有锁的内核
acquire
用于请求锁,代码格式类似于下列代码,也就是会并不断循环来请求锁
1 | if (locked == 0) |
这个自旋锁是有风险的,一旦两个线程同时请求锁,并且锁是释放的,这两个线程会同时将锁置 1,它们都会认为自己获得了锁,所以就会出现问题。在 risc-v 中提供了原子内存操作,它会不间断的检索该单词的前一个值,所以它不允许其它任何线程或者任何其它内核的指令来访问这段内存。
自旋锁具体实现就是,向内存中写入 1,并且读取内存的前一个值,如果前一个值为 0,那就大功告成,否则会一直循环请求,直到前一个值为 0
1 | // a5 = 1 |
这段代码将会被编译为上面的汇编指令,就是一段原子交换指令,这个函数的作用就是,传入一个想要修改的地址,并且传入新值,返回旧值。
整个请求的代码为
1 | void |
release
用于释放锁,释放锁只需要向锁的内存中写入 0 就可以,它不是一个原子操作,只是一个内存的读取与存储,
1 | void |
initlock
在第一次调用锁之前初始化锁
1 | void |
holding
用于输出哪个内核正在持有锁,用于检查 CPU 是否获得了锁,如果当前锁是 1,并且锁被当前 CPU 持有,则返回 1
1 | int |
push_off
在请求锁的函数的第一条语句就是禁用中断
1 | void |
pop_off
在释放锁的函数的最后一条语句就是使能中断
1 | void |
注意
自旋锁不应该被长期持有,如果一个线程想要获得锁,并且不断自旋,会浪费很多时间。当然 xv6 中还有其它锁定技术 sleep() 和 wakeup() 这些可以在需要拿着锁很长一段时间下使用
所以不会让一个线程获得锁时间太长,内核会集中处理拿到锁的线程的核心程序,尽可能快地释放锁
作用
锁是用来保护共享数据的,在 xv6 中会有如下精巧的操作
1 | acquire(); |
死锁
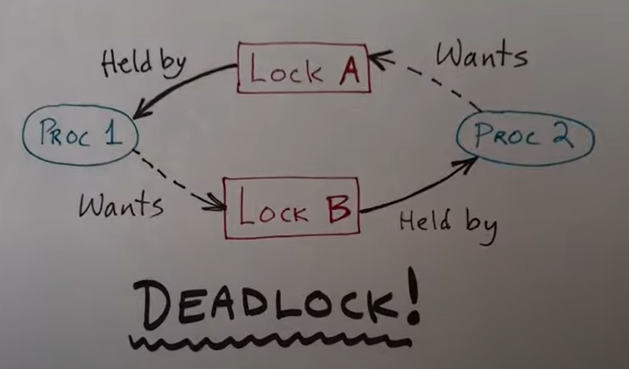
当一个线程获得了锁的时候,恰巧按下键盘,触发键盘中断,键盘中断调用中断处理程序,向某一个共享内存写入数据,需要获得锁。但是持有锁的线程被中断,这导致系统卡死。也就是拿着锁的线程不运行无法释放锁,中断请求锁但是拿不到,这就是死锁
所以解决死锁的方法就是在请求锁时禁用中断,在释放锁之后,打开中断,当然持有锁的时间一定需要很短
如果需要调用多个锁
例如需要调用 3 个锁,每个锁获取时都会禁用中断,但是在第一个释放锁就会启用中断,这个并不是我们想要的。希望可以使用多层嵌套调用 acquire 和 release 函数,所以可以使用一个计数器。例如每个内核都有一个 CPU 结构体,而每个结构体内部都有一个计数器,所以请求和释放函数可以如下实现
1 | acquire() { |
在中断使能函数 enableInterrupt 中,当 cnt==0 时,需要判断在第一次请求锁之前中断是否是使能状态,如果已经使能,那就会启用中断,所以在 CPU 结构体中,有一个专门用来存储第一次请求锁之前中断的使能状态。
空闲内存管理
在 xv6 中,所有的内存管理都是 4KB 为单位的,也就是以 page 为单位,它们被放在一个空闲列表中,内存管理有两个关键的函数
kalloc()只是从空闲列表中删除了一些东西kfree()将一个空闲页重新添加回空闲列表中
结构体
1 | struct run { |
其中
run是一个指向下一个空闲空间的指针kmem里面实现了自旋锁和空闲链表,用自旋锁对空闲链表进行分组,称为简单锁,用于将锁与空闲列表关联,每当操作空闲列表,需要获取锁或者设置锁,当访问完空闲列表之后,需要把锁释放掉
end
1 | extern char end[]; // first address after kernel. |
这是链接器在链接时生成的,里面存放的是内核之后的第一个地址,也就是第一个可用内存,这将会在初始化时被使用
kinit
1 | void |
这个函数中所做的就是初始化锁,并且释放掉范围之内的内存,这个范围就是第一个内存空间和顶端物理空间的内存,这是一个常数,正好是 128MB ,但是由于需要内存页面对齐,所以真实内存可能不到 128MB
kalloc
1 | // Allocate one 4096-byte page of physical memory. |
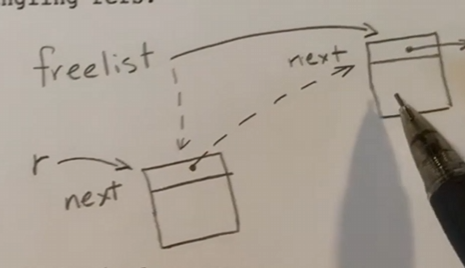
在 kalloc 中所进行的操作如上图所示
kfree
传递一个页面的指针
1 | void |
在函数中首先回进行错误检查,确保 pa 的物理地址在页边界上对齐,确保页面内存位于申请的首尾内存之间。之后会将页面写满 1,这样做目的就是防止内核其它代码出现任何bug,所以不想将页面返回空闲链表之后被使用,所以就将其中的每个字节都设置为某个值。然后请求锁,并将释放的内存链接到空闲内存链表中,与 kalloc() 正好相反
系统调用
用户模式如何进入系统调用
系统调用的所有函数原型(声明)位于 user.h 中,其中的系统调用代码的实现位于 usys.pl 脚本生成 usys.S 文件中
1 | #!/usr/bin/perl -w |
最后生成的对应的汇编代码为
1 | # generated by usys.pl - do not edit |
会生成很多系统调用的代码,每个系统调用码都对应着一个数字,位于 syscall.h 文件中。 ecall 在用户模式下被调用,进入到内核模式中,然后内核将执行对应的代码,然后返回用户模式 return
当调用该函数时,函数传入的参数会依次被放入 a0, a1... 寄存器中,而返回值将出现在 a0 中,内核会做到这一点,系统调用中的参数位于 a0, a1, ... 中,而且返回值会位于 a0 中。这些系统调用没有直接在寄存器中赋予参数,是因为调用之前就假定已经将参数写入到对应的寄存器中了,而调用结果将会在 a0 中被返回
initcode.S
是内核在用户模式下执行的第一个代码
1 | # Initial process that execs /init. |
代码量很少,在 start 中执行的代码就是 exec 系统调用,开始初始化的系统调用,加载两个参数,第一个参数就是 /init\0 ,第二个参数包含 init 的地址,一个 0 和一个对齐语句,加载完成之后,进行系统调用。在 exit 中执行的代码就是系统退出代码,调用 exit 系统调用退出,这个调用需要一个参数,就是退出码或者返回码。
寄存器
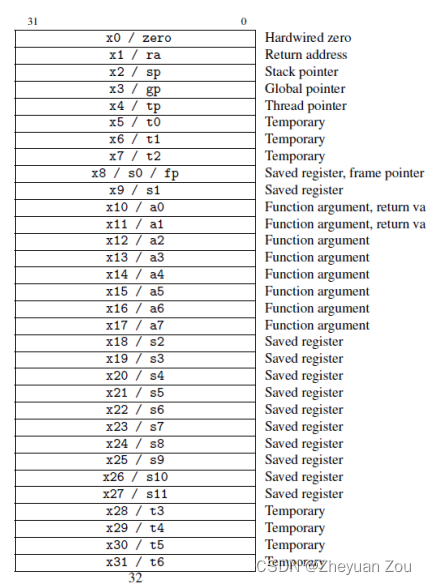
在 risc-v 架构中,有 32 个通用寄存器和一个程序计数器,每个都是 64 位寄存器
zero是以硬件线路作为寄存器的,在进程之间上下文切换中不需要保存ra返回地址寄存器,当在 risc-v 中进行函数调用时,函数返回地址位于ra寄存器,而不是推入栈中,返回地址只是简单的从ra中复制值,所以许多函数不需要访问主存sp栈指针,栈向下生长tp是 xv6 中所谓的线程指针,包括内核代码,实际上是不可改变的,在启动过程中mhartid寄存器的数据将会被 move 到这里gp是全局指针,被编译器使用,将被设置而不被更改,基本上只是用来使得访问全局和共享变量更快更有效a0,...,a7用于将参数传递给函数,a0用于存放函数返回值t0,...,t6这些寄存器可以在函数中自由使用,做函数任何想做的事情s0,...,s11有12个所谓的被调用方保存寄存器。调用方将假设它所调用的任何函数都不会修改这些寄存器。该函数必须在使用它们之前保存它们,通常将它们推入栈中。返回之前必须恢复这些寄存器pc是代码执行地址的寄存器,指向下一条该运行的代码
risc-v 模式
任何情况下 risc-v 都处于以下三种模式之一,每个内核都有自己的寄存器,每个内核在任何时候都以一种模式运行
- machine mode:机器模式是最高和最强大的模式,拥有最大的权限。在系统启动或者重启之后 xv6 内核会进入机器模式。这个模式使用不多。有些代码在启动时以机器模式运行,做一些初始化的工作
- startup——initialization
- time interrupt require:定时器中断要求处理程序在机器模式下运行。而在机器模式下运行的这段代码立即将中断转换为 supervisor mode 的代码中断,这个程序会很快返回
- supervisor mode:是所有动作发生的地方
- 所有内核代码都在此运行
- 有些中断是有权限的,无法在 user mode 下运行,只能在 supervisor mode 和 machine mode 下运行
- user mode
- 所有用户代码都在此运行
- 高权限的指令会产生一个陷阱,并且内核将会中止此进程
Control And Status Registers CSRs
事实上,系统能容纳 4096 个控制和状态寄存器。在 xv6 中,只有 19 个是重要的。
下面是三条具有高权限的指令,是对控制和状态寄存器的读写操作
csrr a0, sstatus将 s 状态寄存器读取到 a0 寄存器中csrw sstatus, a0将 a0 寄存器写入到 s 状态寄存器中csrrw a0 mscratch a0将 a0 寄存器与 mscratch 寄存器内容交换,这个交换是原子操作。这条指令的实际操作就是,将 mscratch 复制到 a0 寄存器中,同时将 a0 寄存器复制到 mscracth 中,这两个操作是同时进行的
下面是那 19 个比较重要的寄存器,其中 m 开头的只能在机器模式下使用和访问,而 s 开头的可以在机器模式和主管模式下访问
mhartid包含内核号。这个寄存器是硬件连线的,不能修改,可查询代码运行在哪个内核中,并且将内容移居到tp寄存器,tp寄存将永不改变。 函数cpuid()将会返回tp寄存器mstatussstatus状态寄存器mtvecstvec陷阱向量也就是陷阱发生时被调用的处理程序的地址mepcsepc当陷阱发生时,以前的程序计数器将会保存在该寄存器scause当陷阱发生时,陷阱发生的原因会被保存于此,如果有额外信息,stval寄存器也会更新stval保存出错的指令或者地址mscratchsscratch工作寄存器,可以被trap handler所使用satp包含指向页表的指针,是地址转换指针。注册地址转换指针,指向页表,而页表存储在主存中。任何时候都会有一个页表被使用,就是 satp 所指向的页表miesie可以在机器模式或者用户模式下有选择地使能中断sip可以找到任何一点,有哪些中断被挂起了medeleg异常可以从机器模式委托到主管模式mideleg中断可以从机器模式委托到主管模式pmp0cfgpmp0addrPMP控制寄存器和PMP地址寄存器,但是未在xv6中使用。物理内存保护,限制运行在用户模式或者主管模式的打码对物理内存的访问,具体可查看 RISC-V 物理内存保护(PMP)机制探究 - 泰晓科技 (tinylab.org)- 可以提供安全处理和故障隔离功能,对现代处理器来说是非常重要的。
- PMP 机制适用于所有特权模式为 S 或 U 的指令和数据访问,通过在 M 态下修改每个 hart 对应的控制寄存器,可以指定每个物理内存区域的读、写和执行等访问权限。
- PMP 机制也可用于 S 态中的页表访问。
- 违反 PMP 机制的访存将被处理器捕获并触发异常
trap
陷阱,分为两种
exceptions异常是同步的,是由某种指令引起的,分为两种- 系统调用指令,在 risc-v 系统中,系统调用指令为
ecall - 程序错误。一些非法的指令,对齐错误,内存访问错误会导致异常
- 系统调用指令,在 risc-v 系统中,系统调用指令为
interrupts中断是异步的,来自于当前代码以外的某个其它的地方- timer:处理程序必须在机器模式下运行,任何情况下都可能发生,但是恰好处理程序会在机器模式下运行。这个中断处理会通知内核,并且导致主管级别的软件中断
- device: uart,disk and so on:硬件设备的中断
- 软件中断:软件中断将由在机器模式下运行的代码引起。软件中断将由运行在监管模式下的代码来处理。也就是内核有软件中断处理程序,做一些需要为定时器中断所做的事
页表架构
虚拟地址转换
satp 包含指向页表的指针,是地址转换指针。注册地址转换指针,指向页表,而页表存储在主存中。任何时候都会有一个页表被使用,就是 satp 所指向的页表
虚拟地址转换在初始化之后总是打开的,一开始 satp 是 0,也就没有地址转换发生,但是在初始化阶段之后,该指针会指向第一个页表。也就是说,在机器模式下,虚拟地址转换还未打开,在用户模式和主管模式下就打开了
RISC-V 指令操作的是虚拟地址,RISC-V的页表硬件支持了虚拟地址到物理地址的转换
xv6运行在Sv39 RISC-V上, 这意味着只使用64位虚拟地址的低39位,而高25位不使用,高25位作为保留位
分页硬件通过利用39位中的高27位索引到页表中找到一个PTE来转换一个虚拟地址,并计算出一个56位的物理地址,该物理地址的前44位来自PTE中的PNN,而它的后12位则是从原来的虚拟地址中的低12位复制过来,如下图
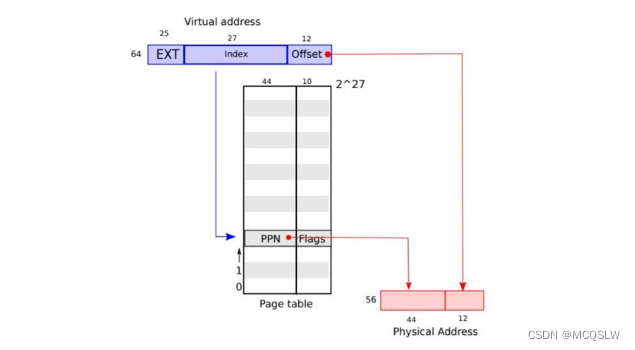
实际上 xv6 的地址转换时分三步运行的,页表是以三级页表的形式存储在物理内存中
第二级页表也就是根页表是一个 4KB 的页表,包含512个页表项。这些页表项包含树的下一级页表的物理地址首址。第一级页表也包含512个页表项,这些页表项包含第零级页表的物理首址。第一级页表的物理首址由页表寄存器 satp 提供,而 satp 寄存器由内核写入根页表的物理地址。最终的叶页表就是实际的物理页
虚拟地址的低39位的高27位用来定位页框号。这27位被分为3份,每份9位,分别定位对应的页表的页表项。具体过程如下图所示
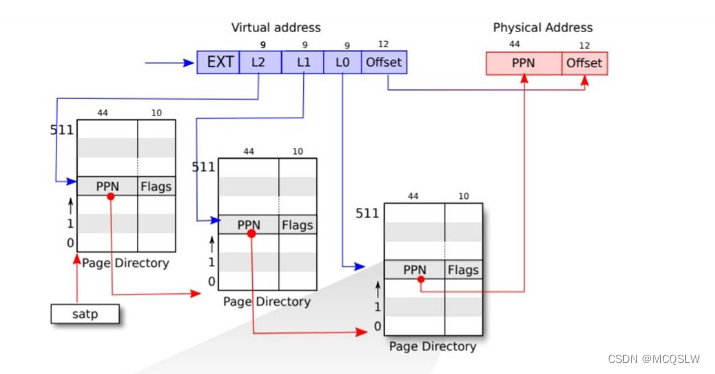
每个CPU都有自己的satp寄存器。因此,一个CPU将使用自己的satp寄存器所指向的页表来翻译后续指令产生的所有地址。这保证了不同CPU可以运行不同的进程,因为这使每个CPU的进程可以拥有不同的私有地址空间。
缺页异常:若转换一个地址所需的三个页表项中的任何一个不存在,分页硬件就会引发一个缺页异常(page-fault exception),内核会处理这个异常
页表项是一个 64 位的数字,各个位的分配如下图所示
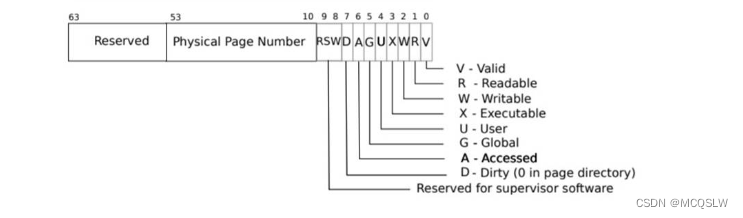
其中
- V :表示页表是否存在,没置位则不允许引用该页表对应的页
- R :是否允许指令读取
- W :是否允许指令写入
- X :是否可以将页表内容解释为指令并执行
- U :决定是否允许用户态下得到指令访问页面,没置位则只能在内核态下使用
内核页表
内核页表只有一个,所有内核共同使用。是一对一的映射,所有的页表内存都映射着物理内存,不需要进行地址运算。还有一些内存映射,是一个 IO 设备
用户进程页表
每一个用户进程都有一个页表,页表的实现有多个选项
- sv32 二级页表,例如RV32
- sv39 三级页表,xv6
- sv48 四级页表,例如RV64
内存访问
每一次内存的读取,存储都会遍历页表,遍历页表将涉及几次内存访问,这个效率是非常低的。
所以在实际的系统中是有地址转换的缓存的(Translation Lookaside Buffers,TLBs),用于减少这些低效率的操作。它会缓存最近的页表。当需要切换页表时,必须清空所有的 LTBs
实际上在 risc-v 架构提供了方法 sfence.vma ,而在内核中会有函数 sfence_vma 用于调用这个方法
虚拟地址
虚拟地址一共有 39 位

0-11位表示在页面上的偏移量12-20位表示页表项在第三级页表中的偏移地址21-29位表示第一级页表的页表项在第二级页表中的偏移量30-38位表示第零级页表的页表项在第一级页表中的偏移位置39-63位被忽略
具体过程表示i可以看看上面
页表项
其中
- V :表示页表是否存在,没置位则不允许引用该页表对应的页
- R :是否允许指令读取
- W :是否允许指令写入
- X :是否可以将页表内容解释为指令并执行
- U :决定是否允许用户态下得到指令访问页面,没置位则只能在内核态下使用
- 其它的 G, A, D 和 RSW 并没有在 xv6 中使用
其中 10-53 位是该页表对应的物理页的地址,一共 44 位,将其与虚拟地址的低 12 位组合得到最终的真实地址,一共占 56 位,所以最多可以支持 56 位的主物理内存
Trap Processing
分类
exceptionsyscall:ecallError: Illegal instruction, Aligment Error,…
interrupt- device interrupt:会在用户模式和主管模式下出现,而且处理程序是在主管模式下运行
stvec
是一个状态和控制寄存器,包含指向中断处理程序代码的指针。每个中断处理程序的第一条指令的地址,将处理发生的任何陷阱
中断处理
kernelvec:处理在主管模式下运行时发生的trapuservec:处理在用户模式下运行时所发生的trap
sstatus
一共是64个位,每一个位表示一个状态标志位
sie第 3 位,是否启用中断。如果是中断导致的trap,这个值必须是 1,否则不会处理- 在 xv6 的内核中可以改变启用中断的状态来防止核心部分代码受到打扰。
- 不同核之间不会相互干扰,但有可能会对同一块内存同时进行读写操作,这个是由锁来保护
spie第 7 位,当前中断使能状态,主要是用于保存多层嵌套的锁中最初的中断使能状态spp第 11 位,当前权限等级。主要是为了区分当前异常或者中断发生时,是在什么模式下的,中断处理不可能从机器模式到主管模式- 0:用户态
- 1:内核态
seie第 1 位,设备中断使能,初始化置为 1stie第 5 位,时钟定时器中断使能,初始化置 1ssie第 9 位,软件中断使能,也就是委托中断,初始化置 1sip用于中断挂起的标志位,保存了发生但是为处理的中断或者异常- 1:一个中断被挂起
- 0:没有中断
mstatus
是 64 位,每一个位表示一个状态标志位
mie第 3 位,是否启用中断spie第 7 位,表示最初中断使能状态mpp第 11 和 第 12 位,用于保存先前的模式- 00:用户模式
- 01:主管模式
- 11:机器模式
mtie第 8 位,用于使能定时器中断,在初始化阶段会被设为 1,这发生在start函数中,并且在机器模式下运行
trap处理
- 首先判断中断是否启用,如果未启用会将中断处理程序挂起,等到重新启用中断
- 但是如果是
expection,不管是否禁用中断都会立即处理
主管模式处理 trap
- 硬件将会做
- 将
pc保存在sepc - 将中断处理程序的第一条指令放入
pc中,也就是stvec->pc - 在
scause寄存器中保存陷阱处理程序的原因- 1:软件中断,与时钟中断有关
- 8:系统调用
- 9:外部设备
- 其它都是程序异常以及代码中的错误
- 可能会在
stval中保存额外的信息 - 硬件会立即保存之前的模式,会保存在
sstatus.SPP - 将
sstatus.sie写入sstatus.spie中,也就是保存多层嵌套的锁中最初的中断使能状态 - 禁用中断
sstatus.sie=0 - 模式改为主管模式
- 将
- 硬件处理做完之后将会开始执行第一条中断处理程序的代码
- 中断处理程序结束之后会返回到中断代码,然后从主管模式返回,这被称为
sretsstatus.spie写入到sstatus.sie中,还原启用中断的位sstatus.SPP写入到mode中,还原之前的模式sepc写入到pc中,还原到运行中断之前的代码
大部分内核都是在主管模式下完成的,只有少部分是在机器模式下完成的
机器模式处理 trap
- 大致与主管模式一致,但是有一个不同的寄存器
mstatus- 机器模式处理的唯一中断就是时间定时器中断。有一个委派机制来委派所有其他陷阱,所有其他中断和异常将会在主管模式下处理
- 中断总是在机器模式启用,每一个定时器中断都会处理,其它 trap 都会被委派到主管模式,而是否处理中断都由是否启用中断来决定
- 当一个定时器中断发生,处理的代码将会做:
- 强制创建一个软件中断到主管模式,并且中断主管模式代码
- 机器模式的运行依旧继续,并且使能中断
- 返回到中断的代码,哪个模式中断代码就返回哪个模式。如果在主管模式启用了中断,会在主管模式立即发生中断,否则会将中断保持挂起,直到启用中断
- 机器模式只处理时间中断,其他都是硬件级别上的委托,立即进入主管模式
- 在
mtvec保存了机器模式中断处理程序的地址,代码叫做timervec - 硬件处理
pc写入mepcmtvec写入到pc- 当前的模式写入到
mstatus.mpp中 mstatus.mie写入到mstatus.mpie中- 禁用中断
mstatus.mie=0 - 切换到机器模式
- 执行计时器
vec代码——timevec- 这将导致主管级别的中断,这个中断是软件中断,这个代码很短
- 在机器模式下执行
mret的指令,将会返回到机器模式中去- 恢复中断启用的标志位
mstatus.spie写入到mstatus.sie中,还原启用中断的位 mstatus.SPP写入到mode中,还原之前的模式mepc写入到pc中,还原到运行中断之前的代码
- 恢复中断启用的标志位
- 产生的软件中断会发生什么取决于是否在主管模式里启用中断
- 如果未启用,将软件中断挂起,直到启用中断之后再进行处理
- 如果启用,
trap会立即在主管模式下发生
定时器中断处理
是在机器模式下运行的,需要将 ssie 寄存器置为 1,迫使软件中断发生在主管模式的内核级别
Trap Delegation
所有的中断都需要进入机器模式来处理,但是也有可以绕过机器模式处理程序的委托,可以直接在主管模式处理中断。由两个寄存器用于委派异常或者中断
medeleg用于委派异常mideleg用于委派中断
这两个寄存器用于委派异常和中断,当有异常或者中断产生时,它将立即由内核代码在监管模式下处理。但是由于定时器中断不能委托,所以与其它中断不同,因为它做了软件中断
这两个寄存器在启动时初始化,发生在机器模式下的启动函数中。一旦初始化将不会改变
由于委派了这些中断或者异常而发生的陷阱,所以机器模式下什么都不会做,这将会立即成为主管级别的中断或者异常
medeleg
寄存器中所包含的委派 trap 类型
- 存储,加载和指令获取页面错误
- 三种模式下的系统调用
- 访问错误
- 未命中的错误
- 加载权限错误
- 加载未命中
- 断点
- 非法指令
- INST 权限错误
- INST 未命中
有一个专门的指令来初始化 medeleg 寄存器,就是
1 | csrw medeleg 0xffff |
虽然不是一个合法的指令,但是提供了一个想法可以用于将所有标志位置 1
mideleg
寄存器中委派的 trap 类型
- 在机器模式和主管模式下的设备中断
- 在机器模式和主管模式下的定时器中断
- 在机器模式和主管模式下的软件中断
初始化也很简单
1 | csrw mideleg 0xffff |
上下文切换
一个用户的线程,可通过 trap 进入内核态,中断处理结束之后调用 sret 返回到原来的程序中。
如果是发生的中断,那用户线程将不知道发生了此陷阱,会在线程返回之后继续运行代码。发生中断时,将会保存用户线程所有的寄存器,然后在系统返回时,这些寄存器将会被恢复或者重新加载,所以线程相当于是从它中断的时候继续开始。所以在用户态相当于是一系列的时间片。
如果发生的是定时器中断,那在这种情况下,内核进入处理时会在这个区域内关闭,然后调用其它的线程来处理。在之后,内核决定给用户线程另一个时间片,然后将返回到用户进程,最终还是返回到用户线程。其实这一段就是讲的线程调度。
对于多线程时间片分配处理,利用 sret 开始时间片,使用定时器中断来结束时间片
单核处理Trap流程
- 用户代码接受到 trap 之后,一般来说 trap 可以分为定时器中断,设备中断(外部信号导致,非同步,与用户代码无关),系统调用和错误(与用户代码有关)
- 中断失能
- 进入主管模式
spp=s mode - 保存用户
pc指针 - 读取
stvec更新pc,其中的指令应该是跳转到uservec - 更新中断原因
- 接受 trap 之后会进入内核态,然后根据中断类型信息从
uservec用户中断处理程序中找到中断处理程序的地址,然后进入中断处理,进入uservec- 保存用户寄存器和
pc寄存器到 trap frame 中 - 加载内核的
sp和tp寄存器 - 将内核页表的地址加载到
satp中(加载内核地址空间) - 然后跳转到
usertrap()函数
- 保存用户寄存器和
- 用户处理中断程序
usertrap()实际上这不是个真正的函数,可以说是一个代码块,永远不会返回到uservec。这里会将内核的 trap vector 加载到stvec寄存器中exception:退出exit(),打印错误报告device:设备中断处理,判断killed标志位,如果为true,就会exit()处理完回到原线程syscall:系统调用,判断killed标志位,如果为true,就会exit()处理完回到原线程。在处理系统调用时,会使能中断,也就是在处理系统调用时可能会去做其它的事情timer:定时器中断,判断killed标志位,如果为true,就会exit(),是时间片线程调度,下一步会执行yield,这将调用调度器和其它进程
usertrapret()C 语言代码- 禁用中断,防止在
syscall中启用 - 将
uservec保存到stvec中,以备下一次的 trap - 保存内核的
sp和tp寄存器 - 将被保存的用户的
pc写入到sepc
- 禁用中断,防止在
userret汇编语言代码,这个代码位于 trampoline page- 恢复寄存器
satp,也就是将用户页表地址加载进去,加载用户虚拟空间地址,将内核地址空间切换到用户地址空间 - 恢复用户寄存器
- 更新控制和状态寄存器
- 设置用户模式,
spp=u mode - 恢复中断
- 设置用户模式,
sret
- 恢复寄存器
- 返回到用户线程
sret
多核多线程的调度
有时候一个线程会受到多个内核的调度
所以当一个内核运行这个线程时,发生时间中断之后会将该线程的各种数据保存在一个共享的内存中,并且再次调度这个现成的内核有权限读取这段内存
每个线程都有用户部分和内核部分,从用户态转到内核态是需要上下文切换的,需要保存所有的通用寄存器
实际上调度线程的程序也是一个单独的线程,当线程进入内核态之后,会上下文切换到线程调度程序中,然后由该程序决定切换到哪个进程中
线程调度
在 xv6 中线程调度使用的函数是汇编函数 swtch()
1 | .globl swtch |
从上面代码可以看出,该函数内部的操作就是将一些常用寄存器给保存,然后初始化,也就是上下文切换
在 xv6 中,进入到内核态之后,如果需要线程调度,用到的代码就是 sched() ,这个代码与 scheduler 向关联
1 | void |
从代码中可以看到,当初始化时,CPU 的进程会先清空,然后进入调度,为了避免死锁会使能设备中断。
然后 CPU 会从任务列表中找一个进程来调用,调用该进程时会给该进程上锁,防止其它 CPU 调度。如果进程状态是准备好运行了,那就会进入调度,将进程状态切换为运行中,然后将其挂载到该 CPU 上,进行上下文切换,切换到该进程中。
当该进程运行的时间片结束时,会调用 sched 函数。进入该函数,首先会检查该进程的锁,检查 CPU 的 noff 标志,检查进程是否还在运行,检查中断是否使能,在线程调度时是不能使能。然后保存当前进程的 intena 标志,切换上下文。
函数 swtch 的作用就是保存当前进程的寄存器并且加载下一个进程的寄存器,是写在汇编代码里的
内存管理
用户的地址空间
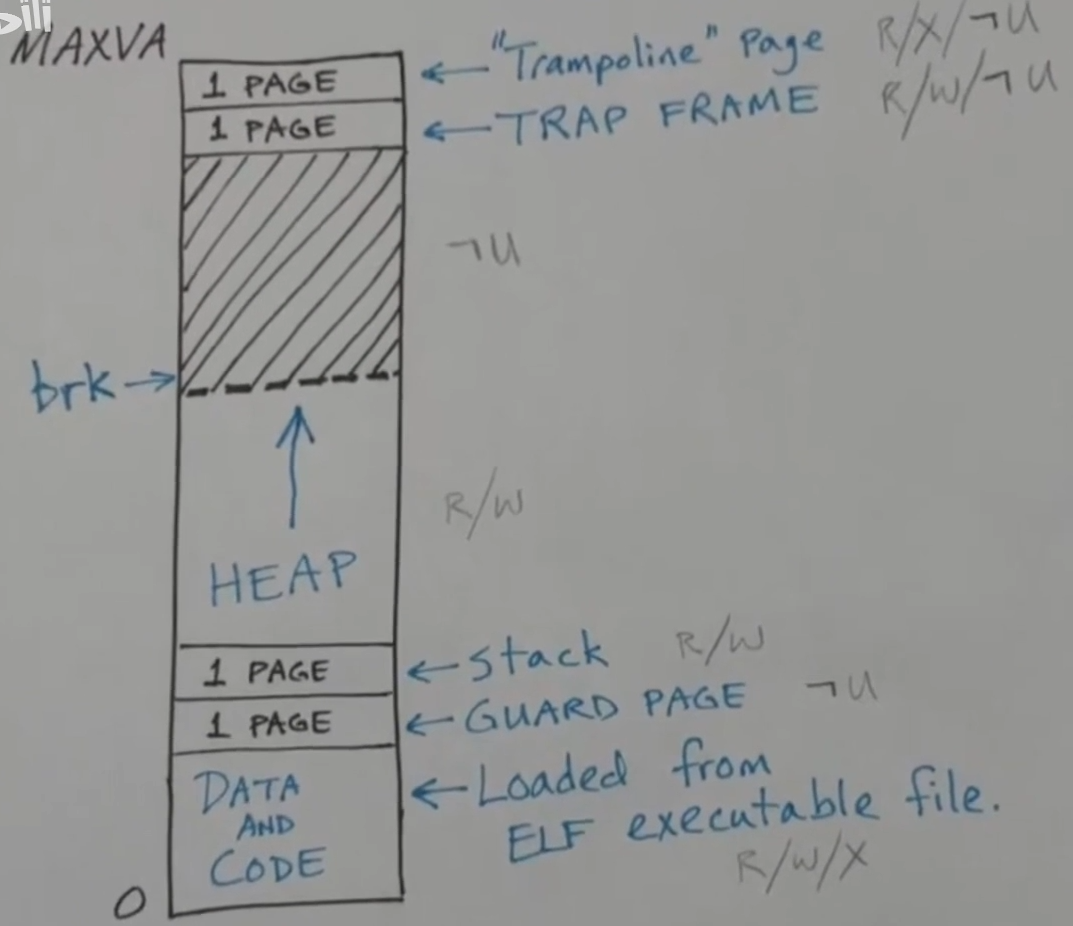
从下往上依次为
- 代码和数据段
- 安全页
- 栈
- 堆
- 空闲空间
- 陷阱框架页
- trampoline 页面
由于取决于用户程序,栈页面的位置会有不同,但是最上面的两个页面总是在同一个位置,这两个页面是可读可写的,但是在用户模式下不可访问,如果用户尝试访问会得到一个错误。
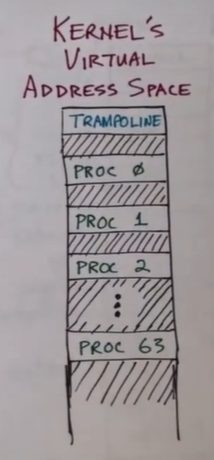
每一个用户进程都会有一段这样的空间,每一个都有一个 trap frame 和 trampoline 页面,但是内核进程只有一个虚拟地址空间,所有的内核都会共享这一个虚拟空间
在内核进程的虚拟地址空间中,最上层是 trampoline 页面,但是没有 trap frame 页面
trampoline page
- 包含代码,只包含了
uservec和userret函数,都是汇编代码 - 所有用户进程的 trampoline page 都在同一个位置,也就是虚拟地址空间和内核虚拟地址空间的最顶端
- 标记为可读可写,但是用户模式下不可访问
- 在实际中,所有的 trampoline page 都被映射到同一块物理地址空间,这个是共享的。这个是没问题的,因为这里的代码所有进程都是一样的并且不可改变
trap frame page
- 每一个用户进程都有自己的页面,每一个页面都是不一样的,每个虚拟地址空间都包含一个 trap frame,但是内核虚拟地址空间中是没有的
- 在页面中包含数据,它将包含将保存用户寄存器的数据
- 标记为可读可写,但是用户模式下无法访问
- 实际中,每一个 trapframe page 都被映射到不同的物理地址空间,不是共享的
物理地址与内核虚拟地址
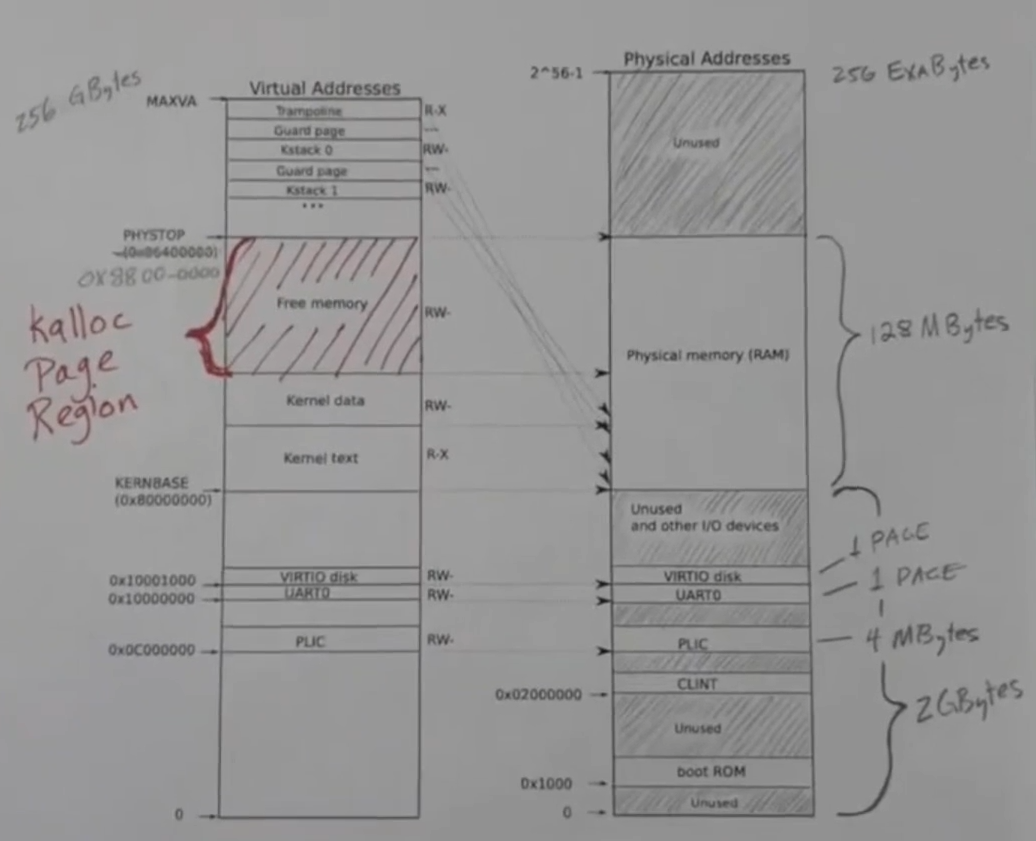
其中右边是真实物理空间,左边是内核虚拟地址空间。真实物理空间的内存分配如下
boot ROM启动项的只读内存- 核心本地中断控制器
- 平台级中断控制器
- 串行通信设备
- 虚拟磁盘
- 物理地址的 RAM
内核的虚拟地址空间分配如下
- 左侧的虚拟地址空间几乎都是真实映射的,也就是内核可以提供一个地址,不需要真正区分物理地址空间还是虚拟地址空间,相同的地址可以直接用于物理地址。
- 当需要访问虚拟磁盘,串口还是平台级中断控制器都是直接访问的
- 核心本地中断控制器只能在机器模式下运行,在机器模式下,所有的寻址都是使用物理地址的,而且没有虚拟寻址页,页表 not active,只使用物理地址,所以不需要映射到虚拟地址空间
- 虚拟地址的顶端有一个 trampoline 页面,然后就是安全页和栈页面的组合,者将会有 64 个,就是为每一个用户进程都分配一个。安全页没有映射真实的物理空间,因为它已经被标记为不可读不可写不可执行,任何试图访问它的进程都会出错,它用来捕获内核中任何堆栈的溢出
- 这里的栈的页面只是虚拟内存的映射,初始化时会在虚拟内存地址中分配栈的空间,然后映射到这里
- 在
KERNELBASE之后会有 Kernel text 区域,这个区域用于存储可读可执行的代码和只读的数据 - Kernel data 段保存内核的可读写数据,也就是内核中使用的变量
- 最后会有一段空闲的内存,这一段内存将会用于页面分配。这些区域一开始被分为几页,并且保存在空闲列表中
kalloc分配空间,会从空闲列表中分配一页空闲内存kfree释放空间,当kalloc分配的空间使用完之后,会归还到该空闲内存区域,也会回到空闲列表中- 用户进程的 trap frame page 将会在这段内存中分配空间
memlayout
在这个文件中,定义了一些设备的地址
UART0定义串口设备的地址,与上文中一致UART0_IRQ定义串口中断VIRTIO0定义虚拟磁盘设备地址VIRTIO0_IRQ定义虚拟磁盘设备中断CLINT定义核心本地中断地址CLINT_MTIMECMP就是一个函数,用于查找核心硬件寄存器的地址- 这个寄存器由内核加载,它会告诉你下一次打断的时间,所以内核会把打断的时间写到这个寄存器中,当时间到了该打断的时候,将会自动生成中断
CLINT_MTIME指向一个地址,该地址存储了从启动开始的 cycles 数PLIC平台级中断的地址PLIC_PRIORITY平台级中断优先级PLIC_PENDING平台级中断是否挂起PLIC_MENABLE平台级中断在机器模式下是否使能PLIC_SENABLE平台级中断在主管模式下是否使能PLIC_MPRIORITY平台级中断在机器模式下的优先级PLIC_SPRIORITY平台级中断在主管模式下的优先级PLIC_MCLAIM平台级中断在机器模式下的声明PLIC_SCLAIM平台级中断在主管模式下的声明KERNBASE内核加载位置PHYSTOP物理主存的顶部TRAMPOLINE定义了 trampoline 页面的地址,就是虚拟地址最顶端的一页KSTACK定义了栈的地址,每一个进程都有一个栈地址,传入进程号,根据进程号获得栈的地址TRAPFRAME定义 trap frame 页面的地址,也就是顶端的第二个页面的地址
目标文件链接
连接器作用
从目标文件中提取所有数据,并将其合并到可执行文件中
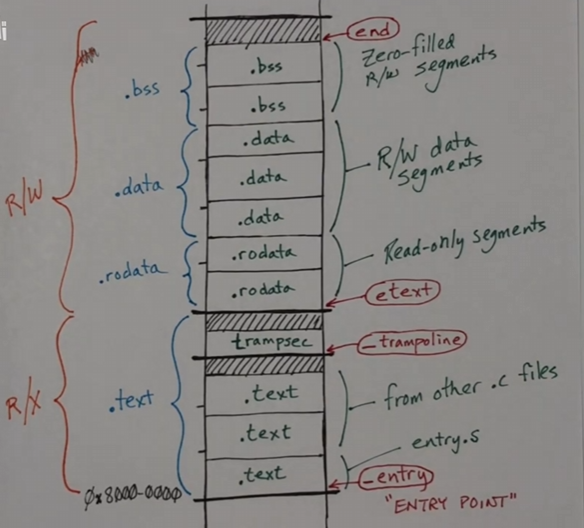
上面显示了来自于内核的各个部分的可执行文件中的内容,链接器将找到内存中放置所有这些材料的位置,然后会构建可执行文件,它包含了以后要加载到内存中的所有数据,当加载好内核并且开始运行内核时,模拟器(qemu)将读取可执行文件,并且把这些东西放到链接器所选择的地址中。
目标文件中会包含很多数据段,但是编译器和汇编器并不知道这些东西将会放在内存中的什么位置,这些数据段都是给定的名字。其中
.text包含可执行的代码.data包含程序的变量,是需要读写的值,有可能会有初值.rodata只读数据,这个数据会进行初始化,但是不会在运行中更新.bss包含未初始化的数据,而它被加载到内存中时会被 0 填充或者用 0 初始化,没有任何初始化数据,所以在目标文件和可执行文件中可能很小trampsectrampoline 段,这必须放在特殊的地方
链接器会从内存中找到这些数据,并且从 0x80000000 的边界开始,将这些代码和数据按照图中的方式将这些派那段放在一起,它们将会按顺序被放到这些位置。链接器的命令将列出此输入代码的目标文件。第一个 .text 中存储的是 entry.S 文件,而第一条指令的标签为 _entry ,会首先开始执行 .text 段,也就是代码段会先执行。这些代码存放的数据与命令行中链接的顺序有关, trampsec 这个文件放在代码段之后
链接器会找到所有东西的地址用于填充之前未填充的部分,例如有些变量在编译时并不知道在哪里,只有链接之后才知道变量的地址。链接器将代码中不确定的变量的地址改为确定的地址位置。而且编译器将确定几个重要的值,例如 etext 就是代码段的结尾和内核数据的开始,然后 end 是数据段的结尾, _entry 是代码段的开始, _trampoline 就是 trampoline 页面的位置。链接器一旦确定所有变量的位置,会将代码中所有关于此变量的引用都替换成该位置
链接器会构建一个页表来描述这块内存,例如 .text 段可读可执行,数据段可读可写。链接器会将所有数据和代码对齐
kernel.ld
1 | OUTPUT_ARCH( "riscv" ) |
内核启动过程
一些定义
1 | __attribute__ ((aligned (16))) char stack0[4096 * NCPU]; |
其中
-
stack0的大小为4096 * NCPU给每一个 CPU 都分配一个栈,为每个栈都分配一页的内存。由于是char类型的数组,所以可能不会对齐,所以前面声明强制对齐 -
timer_scratch每个 CPU 中有 5 个,是一个 64 字的数组,具体的构造如下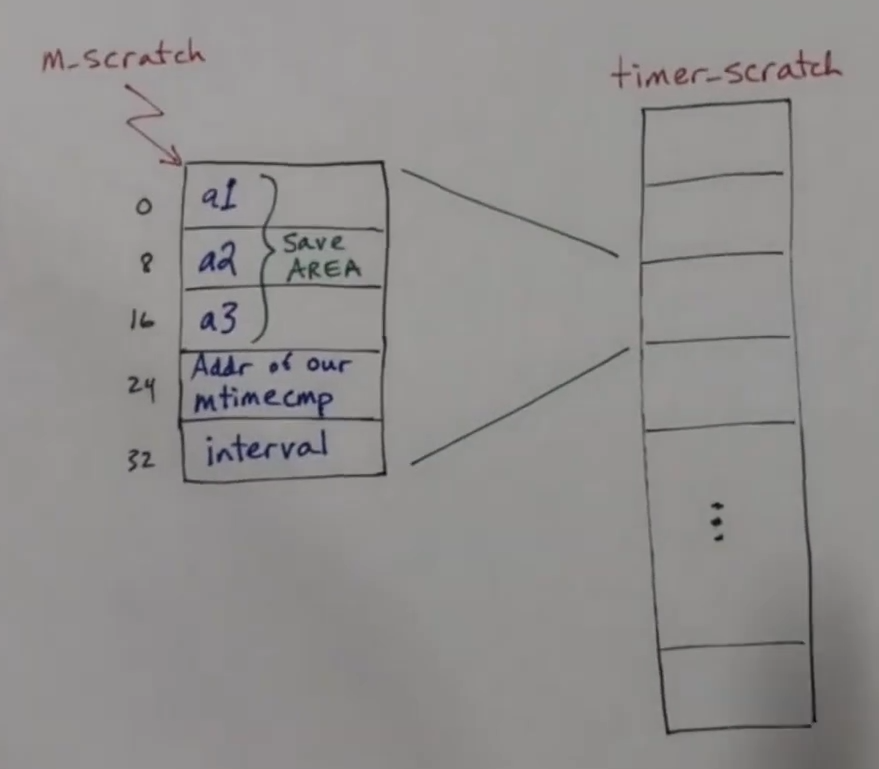
entry.S
1 | # qemu -kernel loads the kernel at 0x80000000 |
其中
.section .text是表示下面的代码将会被存放到.text段.global _entry声明该标签是全局的标签_entry这段代码的作用就是初始化栈指针寄存器,然后调用start函数,该函数不打算返回,但是如果返回了,将会执行下面的代码spin是本地的标签,这就是为了防止start函数返回,如果返回就死循环,锁定这个内核
start
1 | void |
注意
- 这段代码是在机器模式运行的
- 以
r_开头的函数表示对该寄存器的读取 - 以
w_开头的表示对寄存器的写入
流程
- 首先设置
mpp寄存器,设置先前的模式为主管模式 - 设置
mepc寄存器,也就是说明mret之后返回到哪里的代码,实际上在这之前并没有执行任何一条指令,通过设置各个寄存器来制造一个假象,使得 CPU 回到 main 函数中 - 机器模式没有页表,所以将
satp寄存器设置为 0 - 将
medeleg和mideleg寄存器全部置为 1,也就是会将所有中断和异常委托给主管模式,所以当异常或者是错误发生,不会在机器模式下处理 - 设置
sie,读取原先值,并且设置使能软件中断,定时器中断和设备中断 - 物理内存保护,实际上希望将这些内存中写入常数来判断这些物理内存是否都可访问
timerinit定时器初始化- 读取当前内核 id,并且写入
tp寄存器,用于之后确定代码运行在哪个内核上 mret这里将会回到main函数处执行
timerinit
1 | void |
流程
- 获得当前内核 id 号。核心本地中断寄存器上有几个寄存器,其中有
timecmp寄存器。CLINT_MTIMECMP会返回特定 id 的timecmp寄存器的地址,在这里会记下当前的时间加上 1000000 次循环作为定时器的下次中断 - 然后将当前内核的
timecmp寄存器的地址存储在time_scratch的第 4 个元素上,把中断间隔时间存储在time_scratch的第 5 个元素上,然后将time_scratch的地址存放到mscratch寄存器中。这个mscratch寄存器只在机器模式下才可访问。系统只在一开始时在机器模式,而在发生时间中断时也会位于机器模式 - 更新陷阱向量,也就是当陷阱出现时应该执行的处理函数的地址。在机器模式下就是定时器中断处理程序,也就是当定时器中断发生时会跳转到该函数中
- 启用机器模式中断
- 将定时器中断启用
timevec
定时器中断处理函数,将会在定时器中断发生时调用。这个函数在计时器初始化中调用
1 | .globl timervec |
- 首先前面所说的
time_scratch中保存了 5 个 8 字节的数据,其中前三个时用来存储在次数需要用到的三个数据 - 交换
mscratch和a0中的数据,然后再代码的末端会再交换回来。保存当前a1, a2, a3寄存器的值在mscratch中,并且在函数结束之前会把这些寄存器恢复 - 之后是相当于把当前的
timecmp加上了 1000000 次循环时间,也就是下一次定时器中断 - 然后会在这个处理中断结束之后,生成一个主管模式下的软件中断,当然这个中断的处理取决于主管模式下是否允许中断。通过将 2(b10) 写入寄存器
sip中。但是当前是机器模式,所以并不会立即处理这个软件中断,也就是会先挂起,当之后的mret回到主管模式时就会处理该中断。如果中断使能就会立即处理,否则就会挂起中断
陷阱处理
陷阱出现的原因
- 异步中断:设备中断,定时器中断
- 同步中断:系统调用,错误
内核中代码运行流程
- 用户代码接受到 trap 之后,一般来说 trap 可以分为定时器中断,设备中断(外部信号导致,非同步,与用户代码无关),系统调用和错误(与用户代码有关)
- 中断失能
- 进入主管模式
spp=s mode - 保存用户
pc指针 - 读取
stvec更新pc,其中的指令应该是跳转到uservec - 更新中断原因
- 接受 trap 之后会进入内核态,然后根据中断类型信息从
uservec用户中断处理程序中找到中断处理程序的地址,然后进入中断处理,进入uservec- 保存用户寄存器和
pc寄存器到 trap frame 中 - 加载内核的
sp和tp寄存器。每个进程都会为内核栈留出一个页面,这个就是加载到sp中的 - 将内核页表的地址加载到
satp中(加载内核地址空间) - 然后跳转到
usertrap()函数
- 保存用户寄存器和
- 用户处理中断程序
usertrap()实际上这不是个真正的函数,可以说是一个代码块,永远不会返回到uservec。这里会将内核的 trap vector 加载到stvec寄存器中exception:退出exit(),打印错误报告device:设备中断处理,判断killed标志位,如果为true,就会exit()处理完回到原线程syscall:系统调用,判断killed标志位,如果为true,就会exit()处理完回到原线程。在处理系统调用时,会使能中断,也就是在处理系统调用时可能会去做其它的事情timer:定时器中断,判断killed标志位,如果为true,就会exit(),是时间片线程调度,下一步会执行yield,这将调用调度器和其它进程,调度其他线程也会进行上下文切换,这里的上下文切换开关与其它的不同
usertrapret()C 语言代码- 禁用中断,防止在
syscall中启用 - 将
uservec保存到stvec中,以备下一次的 trap - 保存内核的
sp和tp寄存器 - 将被保存的用户的
pc写入到sepc
- 禁用中断,防止在
userret汇编语言代码,这个代码位于 trampoline page- 恢复寄存器
satp,也就是将用户页表地址加载进去,加载用户虚拟空间地址,将内核地址空间切换到用户地址空间 - 恢复用户寄存器
- 更新控制和状态寄存器
- 设置用户模式,
spp=u mode - 恢复中断
- 设置用户模式,
sret
- 恢复寄存器
- 返回到用户线程
sret
trapframe
当在用户模式下,会有一个控制和状态寄存器 sscratch ,它将会指向这个 trap frame,其中 trap frame 的结构如下。它是一个页面,并且将以页面对齐
1 | struct trapframe { |
在处理 trap 的流程中,保存用户的寄存器到 trap frame 中,就是这个 trap frame ,每个进程都有一个 trap frame。由于一共有 32 个寄存器,但是其中一个寄存器是硬件连接到 0,所以只保存 31 个寄存器,也就是上面的 ra~t6 寄存器,剩下的
kernel_satp内核的页表kernel_sp进程的内核栈顶kernel_trap保存usertrap()的地址kernel_hartid保存tp寄存器中内容,就是当前内核 idepc保存用户的pc寄存器
CPU
1 | struct cpu { |
有个 CPU 的数组,也就是每一个 CPU 都有一个对应的结构体。
在 CPU 结构体中
proc就是进程指针,如果用户模式进程在该内核上运行,会有一个指向描述该进程的 proc 结构的指针。如果该 CPU 上没有运行进程或者正在程序调度进程,该字段将为 0 或者空noff记录失能中断层数的数据,也就是push_off层数intena记录最初是否启用中断。如果想要失能中断,就将noff++并且用intena记录下最初中断的使能状态,用于回到最初的状态。在最初的push_off之前是否启用中断context一个名为上下文的寄存器保存区域。这个寄存器保存区存在是为了在线程调度时保存寄存器,只需要保存ra和sp寄存器和s0-s11寄存器
proc
1 | struct proc { |
lock自旋锁state进程状态,可以为UNUSED未使用USED已使用SLEEPING挂起RUNNABLE可运行,等待一个时间片RUNNING正在运行ZOMBIE僵尸进程,也就是已经被杀死的进程,整个结构被回收和闲置之前。直到退出xstate就变成了未使用的
chan在睡眠状态时,等待什么信号,只有进程在SLEEPING时才有意义,用于存储SLEEPING信息,也可能在等待什么东西killed杀死进程的标志xstate进程的退出状态,用于传递给其它等待它的进程pid进程的 id 号parent指向进程的父,也就是会指向另一个进程的结构体,处理该字段必须持有wait_lockkstack内核栈的虚拟地址sz虚拟地址空间大小pagetable指向描述虚拟地址空间的页表的指针trapfram指向 trap frame page,每个进程在物理内存中都有一个唯一的页,位于每个进程虚拟地址空间的最顶端的第二页面,但是这里指向的是物理内存空间地址context这里是另一个上下文保存区域,所以在调度器调度进程和线程的时候可以使用这两个区域保存ofile[NOFILE]打开的文件的数组,指针指向对应的文件描述符,其中NOFILE是可以同时打开的文件数cwd当前地址name[16]进程名字
killed函数
用来检查进程的 killed 标志位,读取并且返回该标志位
1 | int killed(struct proc *p) { |
context
1 | // Saved registers for kernel context switches. |
是一个上下文内容的结构体,其中
ra返回地址寄存器,将会保存pc的内容sp栈指针s0-s11用于保存通用寄存器
trampoline
这个文件中有两段代码,被声明为 trampsec 段,所以会被链接器放置在 trampsec 区域中。
这里定义了标签 trampoline 这是此页面所在物理内存中的地址,并且这段代码将会以 4 字节对齐。但是实际上 .section trampsec 是页面的边界,已经对齐了,所以下面的对齐语句 align 4 是没有作用的。所以 trampoline 与 uservec 的地址是一样的,相当于是为同一个地址分配两个标签。这样的话, uservec 相对于页面边界 trampoline 计算偏移量为 0,而下面的 userret 计算的偏移量是大于 0 的
1 | .section trampsec |
uservec
这是汇编代码,这段代码和 userret 将会被链接器放置在 trampsec 区域中
1 | .globl uservec |
在这段代码里,首先是获取用户的寄存器的地址,保存到 a0 寄存器中,然后就能够通过 a0 寄存器实现对各个寄存器的保存了。
一般来说,会用 ra 寄存器保存返回值,但是 usertrap 没有返回值
userret
1 | .globl userret |
trap frame
usertrap
用户 trap 处理函数
1 | void |
usertrapret
这个函数 usertrapret 不仅使用在 usertrap 之后,而且对于 fork 进程也可以返回,所以这一段被单独拿出来作为一个函数
1 | void |
内核调度
cpuid
1 | int cpuid() { |
该函数简单的返回 tp 寄存器中的值,这个寄存器始终保存目前内核的 id 号,由于可能会被打断而导致返回时 return 的 id 过时,所以调用此函数之前需要禁用中断
mycpu
1 | struct cpu * |
根据当前 CPU 的 id 找到当前 CPU 对应的结构体,返回这个结构体,这个函数调用必须是在中断禁用的条件下的
myproc
1 | struct proc * |
获得当前的 CPU 中正在运行的进程,然会该进程的结构体,在这个过程中将会禁用中断,然后获取当前 CPU 的进程,最后重启中断返回进程结构体。在 CPU 结构体中,有一个指向当前进程的指针,一般来说 CPU 不是运行进程调度程序就是运行在某一个进程上,只有运行在某一个进程上时,这个指针才是有效的,指向对应的进程的结构体
yield
1 | void yield(void) { |
该函数中首先请求进程的锁,然后才能将进程状态设置为可执行(更改进程状态需要权限),然后进入调度函数 sched ,从调度函数中返回之后,释放锁
在 sched 函数中有 swtch 函数,这个函数会直接返回到内核进程调度程序中,也就是不会返回到原来的 sched 函数中,所以这将会导致可能需要一段时间才能从 sched 函数返回到当前这个 yield 函数中,才能继续释放锁进行之后的操作
这个函数会在 usertrap 和 kerneltrap 中被调用,到那时不会有任何锁,在 acquire 中会禁用中断,记录之前中断状态,然后计数,这时候 noff=1 。会将进程的运行状态设置为 RUNNABLE
sched
1 | void sched(void) { |
该函数需要正常运行的条件
- 拿到进程的锁
- CPU 的
noff计数为 1,也就是锁在这个进程中嵌套的层数为 1,也就是该 CPU 只在这个进程中被锁, - 需要当前的进程不是运行中,而是被设置为
RUNNABLE因为需要被放入进程队列中 - 在此过程中不能使能中断,否则出现死锁
然后保存当前 CPU 的最初的中断使能状态,进行上下文切换。等到这个进程再次被调度,就会恢复 CPU 中记录最初中断使能状态的标志。
swtch
1 | .globl swtch |
在这个函数中,就是调度器函数,只负责进行上下文切换,保存当前进程的寄存器,然后加载内核的寄存器, ret 之后会进入进程调度程序,选择一个进程开始运行
当从 p 进程 swtch 到线程调度进程中去时,会保存 P 进程的各种寄存器,保存到 p 进程的 context 中,并且加载 CPU 的上下文到寄存器中。如果是从线程调度寄存器 swtch 到 P 进程时,保存进程调度函数的寄存器到 CPU 的 context 中,并且加载 p 进程 的上下文到寄存器中
其中有一个 RISC-V 的特性,就是对于一个函数调用,该函数会做现场保护,如果被调用的函数不调用别的函数的话,就可以把当前的 pc 值保存在 ra 寄存器中,而不用推入栈中,所以当函数返回就会从 ra 寄存器中读到 pc 指针,进而恢复到原来的代码中。而在 swtch 中,是使用了这个特性,把之前的 ra 寄存器保存,然后将将要运行的代码保存在 ra 寄存器中,之后代码返回就会返回到新的代码地址中去
在 RISC-V 中,假设任何函数都可以更新,使用和修改,覆盖 a 寄存器和 t 寄存器,所以当调用 swtch 函数时,没有办法对 a 和 t 返回后的寄存器的值做任何假设,所以没有必要保存这些寄存器的数据,只需要保存 ra , sp 和 s 寄存器就可以了。在 xv6 中不使用 gp 寄存器,所以不予考虑。而 tp 寄存器保存的是当前内核的 id,所以是不会改变的,不予考虑
scheduler
1 | void scheduler(void) { |
在这个函数中有一个死循环,也就是 CPU 会不断循环执行这个调度程序,而这个死循环之前有初始化,将当前 CPU 的进程结构体初始化为 NULL,之后就进入死循环的调度任务
在调度任务中,需要使能中断防止死锁。然后遍历进程队列,找到一个可运行的进程,然后将其改为运行状态,切换上下文到该进程中运行,当 swtch 函数返回,就不再执行那个进程了,所以就会将 CPU 的进程改为 NULL
这个调度任务中有一个请求进程的锁,这里的话与上面的 yield 函数相对,也就是这里请求的锁会在调度回 yield 函数中释放,而在 yield 请求的锁会在这里被释放,所以就很奇妙的完成了只有进程在调度中时才会被锁上,其他时候都会被释放掉,也就不至于其它的内核在调度进程请求锁这里浪费太多时间
如果总是找不到一个可执行的进程,那么就会进入到外层的死循环中
调度流程
1 | sequenceDiagram |
中断状态
在 scheduler 函数中,如果进程调度循环结束一轮之后,会进入大的循环,在这里会把中断打开,以防止一直没有可运行的进程而导致内核锁死在这里。每次在进程队列中循环一遍之后,就会把中断打开,一段时间之后,会的得到中断并且会去处理 trap,这可能会唤醒一些进程,从而使得该内核可以运行
每当程序进入 usertrap 中之后都会禁用中断,而重新返回到该线程之后会将中断启用状态恢复到处理 trap 之前的状态。这也就是说,在这个进程调度的过程中,中断是被禁用的
进程挂起和唤醒
channel
- 保存在
proc结构体中的chan - 是一个
void *变量。这里面可以存储函数sleep的原因和唤醒该进程的条件 - 在唤醒函数
wakeup中作为匹配唤醒的条件
一个典型的语法
1 | while(condition is false) { |
对于一个正在 sleep 的进程,其它进程可能并不知道该进程在等待怎样的 wake up 条件。所以其它的进程有可能唤醒所有与该条件有关的进程,所以会发生下列情况之一
- 唤醒了太多的进程
- 唤醒几个正在等待在共享数据中做更改的进程
它们其中之一有可能会抓住该条件,然后检查这个条件,如果这个条件满足要求,就会唤醒,如果发现这个条件是假的然后继续 sleep,所以必须在唤醒时重新检查条件
这会有一个问题:如果这个条件变成了 true,但是进程并没有执行完 sleep,那它就会错过这个信号,从而陷入永久的 sleep
sys_sleep
1 | uint64 |
ticks是一个全局变量,受到ticklock的保护,必须获得ticklock之后才能访问ticks- 不能错过任何一个
wakeup,每当wakeup时都会重新检查一下是否满足wakeup的条件,然后进行下一步,打开锁,以此保证请求和释放锁都是配对的 - 当 sleeping 过程中不能 hold 锁,所以就是自旋锁必须迅速释放。所以可以看到在
sys_sleep函数中,调用sleep函数之前,实际上是持有tickslock的,所以sleep函数将tickslock传入,在函数内会把该锁给释放掉,而当wakeup之后就会重新请求锁,以此来保证sleep过程中不能持有锁,只有在检查条件时才会持有锁。需要保证请求和释放锁都是配对的
这是一个 sleep 的系统调用,就是会 sleep 固定 tick 数的一个函数。当睡眠时间不够,会在循环中持续 sleep ,直到用户退出杀死这个进程或者是 sleep 时间足够了,就会释放 ticklock 锁,然后退出
sleep
1 | void sleep(void *chan, struct spinlock *lk) { |
这个 sleep 与 yield 函数相似,两者都会停止该进程的运行,两者都会获取进程的锁以此来把该进程标记为一个非运行的状态。在该函数中,会获取进程的锁,然后设置进程唤醒的条件,将进程状态设置为 sleeping ,然后进入 sched 进程调度函数,进行程序调度,那该函数就会保持 sleep 直到被唤醒,然后将唤醒条件清除,释放进程锁,然后返回
可以看到,函数的参数中传入一个自旋锁 lk ,在函数中将其释放掉,以此来保证该锁不会被长期占用,然后 wakeup 之后再请求锁,返回到之前的函数中
通常在循环中使用 sleep 寻找某个条件,这个条件由某个共享的变量保证
需要注意的是,在这个函数中的请求锁的函数必须是原子的,进入睡眠之前也不会被中断打扰。由于进程的锁一次只能由一个进程获取,所以会有两种情况
wakeup比sleep先获得锁,那wakeup已经走过之后,sleep函数才会设置SLEEPING状态,所以wakeup看来该进程并没有进入SLEEPING的状态sleep比wakeup先获得锁,会设置好进程的chan变量并且将进程的状态设置为SLEEPING之后进入到sched函数才会释放该进程的锁。然后wakeup函数运行才能重新唤醒该进程
wakeup
1 | void wakeup(void *chan) { |
在函数中,参数就是唤醒进程的信号,用于确定哪些进程可以被唤醒。在函数中遍历所有的进程,把所有符合唤醒条件的进程都唤醒,改变其状态为 RUNNABLE ,改变其状态需要获得该进程的锁。该函数需要在没有任何进程的锁被 hold 的时候调用。在代码中会判断只有在 SLEEPING 状态下的进程符合条件才会被改变状态为 RUNABLE ,所以一开始的 p!=myproc 实际上是一个无效的判断,也许就是个历史产物,但是实质上不会有什么影响,除了多费点时间
实际上, wakeup 的调用一般都是在该进程获得锁之后才进行
UART
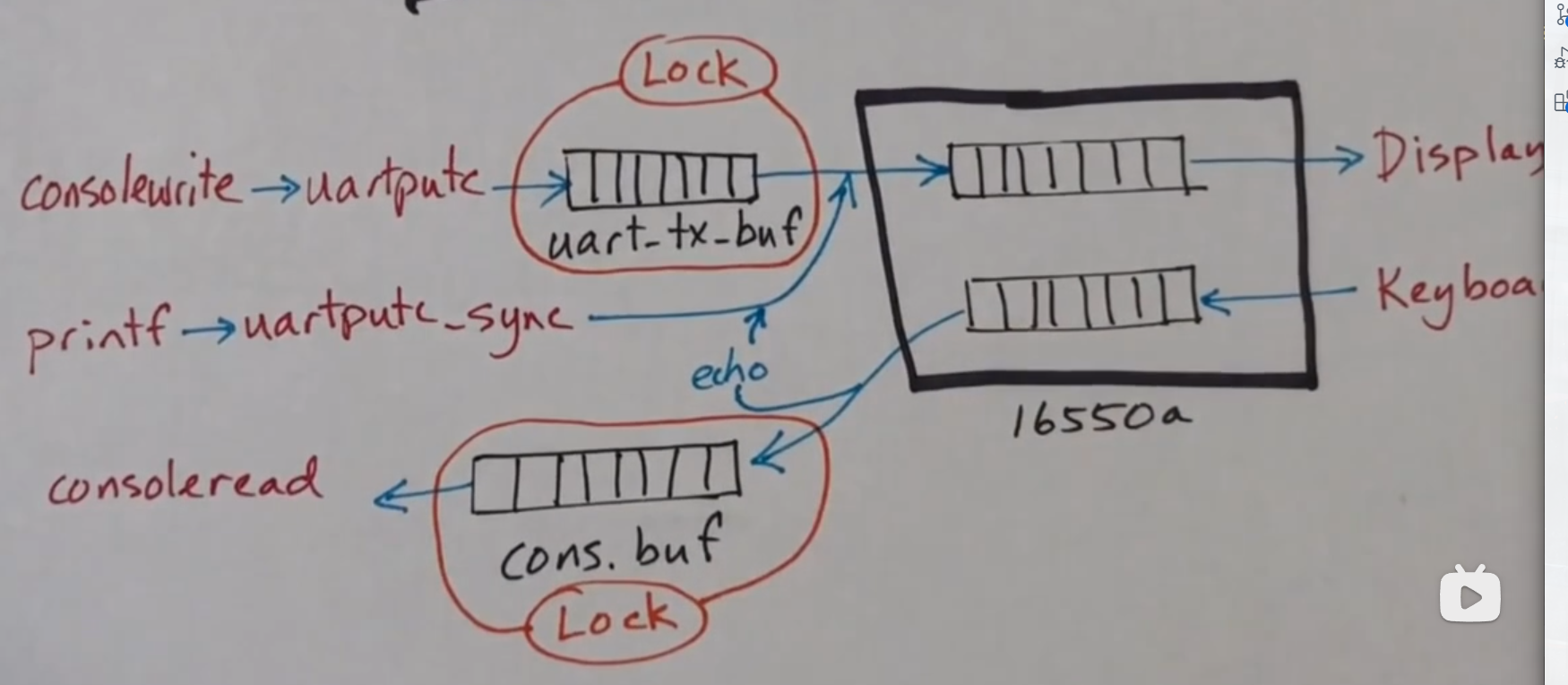
16650A 是一个早期的串口的通讯的芯片,它的协议至今还在使用,而 xv6 就是使用的该协议来做的。
内核将通过串口将数据输入到显示屏上,而键盘的数据也会通过串口输入到内核中,内核将从某个特定的字节读取。芯片 16650A 中可能没有 FIFO 队列,但是内部的 FIFO 队列可以被忽略
在内核中有 uart_tx_buf 来向显示屏发送串口数据,使用 cons_buf 来存储从键盘得到的数据,而且这两个数据都有自己的锁保护。所以在串口输出时,会调用 uartputc 来向 uart_tx_buf 中添加一个字节,并且使用 consoleread 来读取 cons_buf 缓冲区的字符。还有其它的方式,例如键盘中输入数据之后,可以使用 echo 来将其展示到显示屏上,这将会被内核自动响应并且立即显示,并且 echo 将会绕过输入缓冲区直接显示在设备上,如果缓冲区满了,将会拿到串口输出数据的锁来延迟 echo 。 printf 函数将会调用 uartputc_sync 函数同步的发送到显示设备上,这个是十分重要的,所以会绕过缓冲区
uart_tx_buf
这是串口输出缓冲区,尺寸有限,有 32 个字节,缓冲区中有两个索引, r 用于读取, w 用于写入
每写入一个都会把字符存到当前 w 的位置上,然后将 w 自增 1,读取时会将 r 所指的读取,然后 r 自增 1,但是它们两个索引只会在 32 个字节中循环追赶
1 | buf[w++ % sz] = ch; |
empty
如果是空的,那就是 r 追上 w 相互重合
full
如果是满的,就是 w 超过 r 正好是缓冲区的大小
lock
由于这个缓冲区可能会被多个进程访问,所以需要加上锁,这个锁是 uart_tx_lock
cons_buf
1 | struct { |
在这个 buffer 中,有三个索引值
r用于读取数据w用于写数据e是一个编辑的指针,在输入命令时,有时候会输入错误,这时候按下退格键将之前的命令字符删除,也就是说,在用户确认自己的输入之前,这些字符都是有可能被删除的。 所以在使用键盘键入字符时,console会先使用编辑指针e来记录用户输入的字符,如果用户此时按下Ctrl-D(EOF组合键)或者是换行\n时,这时候写指针就会确认之前编辑指针的输入,并且更新位置到编辑指针的位置
UART Hardware Regs

上述说到从串口读取数据是从某个位置读取的数据,那个位置就是内存映射位置,内存地址映射到物理地址空间中的某个地址,这个地址由常数 uart0 表示,这个地址恰好为 0x10...00 。在这个地址上有几个字节,这些字节被认为是 IO 寄存器
THR:发送保存寄存器,发送的数据存入这里IER:中断使能寄存器,如果想使能中断,需要在该寄存器中写入一些特殊的东西FCR:板上FIFO控制寄存器,如果想要使用芯片上的FIFOs,需要向该寄存器写入点东西LCR:线路控制寄存器,用于设置波特率

还有用于接收的地址
RHR:接收保存寄存器,从这里读取接收数据ISR:中断状态寄存器,显示中断的状态LSR:线路状态寄存器,有两位特别重要- 在
RHR中是否有输入,可以检查这个寄存器来读取数据 - 告诉发送保存寄存器,准备接收下一个输出字节。所以当写入
THR太快就会导致数据丢失
- 在
uartputc_sync
用于将字符尽快发送到硬件输出,被 printf 用来将错误消息尽可能快的打印在显示上,可以绕过输出队列。也可以使用 echo 方法将消息打印在显示设备上
1 | void |
uartputc
这将由控制台调用,将在输出队列中添加一个字符,要想做到这一点,需要获得这个队列的锁,还要测试缓冲器的情况,是否有一些额外的空间在其中,然后将字符串放入到队列中,之后就调用 uartstart
1 | void |
uartstart
将信息从串口缓冲队列发送到 16650A 芯片中,将下一个数据发送到硬件中,如果硬件接收端准备好接收这个字段的话就会发送,否则就先不发送退出函数
1 | void |
uartgetc
如果硬件设备准备好了,并且 RHR 中有输入,从硬件中读取一个字节,这个函数不会等待,如果没有数据或者硬件没准备好,直接返回 -1
1 | int |
uartintr
串口中断处理函数。只要有输入字符可以从硬件中读取,或者每当硬件准备好接收下一个输出字符时,硬件会产生中断,然后该中断会调用串口中断处理函数
它会读取串口硬件上的所有数据,然后每读到一个数据都会调用一次 consoleintr 函数
它也会调用串口开始发送的函数用于串口数据发送到硬件设备
1 | void |
uartinit
串口初始化
1 | void |
consputc
由上图可知, printf 调用 uartputc_sync 直接将数据输出到显示设备上,但是实际上,它不直接调用 uartputc_sync ,而是通过调用 consputc 来调用 uartputc_sync
1 | void |
consolewrite
用于调用 uartputc 函数来将数据写入缓冲区中,如果函数 uartputc 进入 sleep 状态,那这个函数也会罢工
1 | int |
该函数有三个形参,其中
user_src一个布尔值,传递表示src表示的缓冲区地址空间是虚拟地址空间还是真实的物理地址空间src源数据的地址n传递字节数
在该函数中,如果读取数据失败(地址非法)就会退出,否则就一直读到 n 个字节为止,最后该函数返回写入的字节数
consoleread
等待在 cons_buf 中有数据可以被检索,它将从缓冲区中复制字符串,并将其移动到用户空间的某个地方,直到得到 \n 或者时 EOF 字符
1 | int |
该函数有三个参数,其中
user_dst表示目的缓冲区地址dst的地址空间是虚拟地址空间还是真实的物理地址空间dst目标缓冲区地址n读取字节数
consoleintr
终端的中断处理函数,在 uartintr 中被调用
- 用于将一个字符添加到
cons_buf中 - 将字符回显到输出中
- 如果得到一个
\n或者是EOF文件结尾字符,都会将w=e然后唤醒任何等待输入的函数,例如consoleread函数来处理信息
1 | void |
该函数中传入一个字节,会将它传入输入缓冲区,会对字符进行判断,各种情况如下
ctrl+P打印进程列表,会调用procdump函数,这对于调试内核很有用ctrl+H,\x7f就是退格和delete,这将做的事情就是备份原先输入的数据,然后调用uartputc(BACKSPACE)ctrl+U就是删除当前的一整行,或者是将编辑索引删除到与写入索引一个位置,并且调用一个uartputc(BACKSPACE)default当字符是空的或者缓冲区中已经满了,就会忽略输入字符串- 如果字符串是返回字符
\r就将其转为新行\n字符,否则不变 - 然后将字符直接显示在显示器上并且输入到缓冲区中
- 如果写入了换行或者文件末尾或者是缓冲区满了,会将
w移动到e以便将所有字符读到,还会唤醒正处于SLEEPING的读取缓冲区的进程
- 如果字符串是返回字符
consoleinit
初始化函数,在其中会初始化锁,将串口初始化,并且链接函数指针
1 | void |
- 初始化缓冲区的锁
- 串口初始化
- 链接函数指针
虚拟内存
pagetable
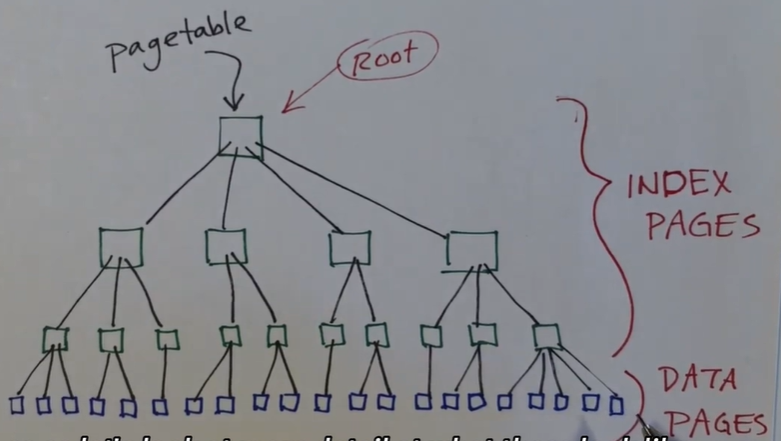
页表表现为树状,并且在 xv6 中为三级树
一些定义

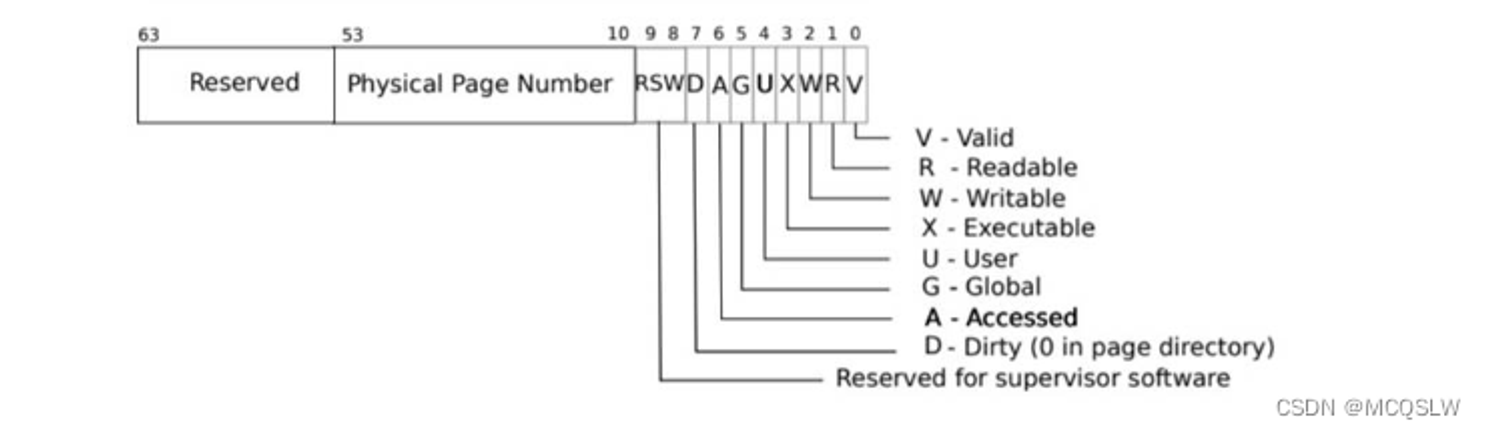
PGSIZE页面最大尺寸PGSHIFT这个就是虚拟地址中,页表的地址的偏移PX(level, va)返回第level级页表中虚拟地址va的地址PXMASK返回页表地址的掩码,是 9 位,对应上图MAXVA虚拟地址的最大地址PA2PTE物理地址转为页表项虚拟地址PTE2PA页表项虚拟地址转为物理地址PTE_FLAGS页表项标志位的掩码PGROUNDUP(sz)该地址的上一页页表的地址(内存从下向上排)PGROUNDDOWN(a)该地址的下一页页表的地址(内存从下向上排)MAKE_SATP(pagetable)
walk
该函数会在页表树上查找,将返回指向数据页的页表项的地址,如果不能分配页面并且也不选择创建页面,会返回一个空指针,成功返回该页表的地址,返回的是虚拟地址
64 位的虚拟地址被拆分如下
39-63必须为 030-389 位的二级页表索引21-299 位的一级页表索引12-209 位的零级页表索引0-1112 位在页面的偏移量
该函数需要传入的参数
pagetable指向页表根节点和虚拟地址的指针va虚拟地址alloc是一个布尔量,当这个页表不存在的话,可以将alloc=1来创建页表,这个就是是否需要创建页表项
1 | pte_t * |
mappages
用于将页表项添加到页表中,也就是添加一个虚拟映射,创建一个虚拟地址开始于 va 的页表,虚拟地址空间映射的物理空间开始于 pa 。 va 和 size 没必要页面对齐,会使用最小的能包含所有大小的页面数。成功返回 0,如果 walk 不能分配一个需要的页表页面就返回 -1
参数如下
pagetable页表va虚拟地址空间,告诉页面将在虚拟地址空间中添加到哪里size添加页面的大小pa传递一个物理地址,指向很多页面,所以需要使用size来表示页面数perm该页面被赋予的权限R/W/X/U
如果函数运行出错将会返回 -1 ,否则返回 0
1 | int |
kvmmap
这个就是添加一个内核页表的映射,只在初始化时调用,不刷新 TLB 或启用页面
由于内核只有一个共享页表,所以当创建页表时,使用这个函数映射内核虚拟内存,实际上这个创建操作与 mappages 是类似的,除此以外,如果创建出错会直接报错,因为内核页表创建出错会导致无法正常运行
函数的形参:
kpgtbl内核的页表va映射的虚拟地址pa映射的实际物理地址sz内核页面大小perm页面的权限
1 | void |
kvmmake
这个函数将会调用 kvmmap 来创建和初始化内核的页表,为内核创建一个直接映射页面表
- 通过直接映射将所有物理内存添加到页表中
- 将所有设备直接映射到页表中
- 为 trampoline page 创建了一个映射,trampoline page 是位于某个物理地址中的,另外·还会有一个映射到虚拟地址的最高的页面的映射
- 调用
proc_mapstacks函数,在这个函数中- 调用
kalloc来为每一个进程的栈分配一个页面,这些页面将被映射到某些物理页面上 - 当进程以内核模式运行时,需要用到栈,所以在内核模式的页表中创建了 64 个对每个进程的内核栈的映射,这中间用到了
KSTACK宏定义函数,可以计算对应进程的栈的内存地址
- 调用
1 | pagetable_t |
kvminit
通过调用 kvmmake 来创建内核页表,并且将其地址保存在某个全局变量中 kernel_pagetable ,这个初始化函数将由 0 号内核调用来初始化内核页表
1 | void |
kvminithart
在初始化阶段,每个内核都会调用这个函数,每个内核的寄存器 satp 将保存内核的页表地址,这对于每个内核将会比较有效的打开这个页表
1 | void |
walkaddr
用于将虚拟地址并且将其转化为物理地址,如果没有映射的话返回 NULL ,只能在用户模式下使用
-
pagetable页表 -
va虚拟地址这个函数将使用页表映射,将虚拟地址转为物理地址。这个页表必须被标记为有效,并且必须有用户权限,如果中间出现错误,就会返回 0,由于任何虚拟地址的物理地址都不会对应为 0(从0x80…000开始),所以返回 0 是安全的
1 | uint64 |
uvmcreate
这将创建一个空的页表,它只是分配一个物理页面,并将其清除为 0,并且返回该页面的根索引,这个用于用户地址空间
1 | pagetable_t |
uvminit
在 xv6 代码中没找到这个函数,用于创建第一个用户虚拟地址空间,这个有点特别。这个函数将创建一个页面,并且将其映射到虚拟地址 0,并标记为可读可写可执行用户权限,并且会用一些代码填充,将会用 initcode 来填充这个页面,这个 initcode 是一个 52 个字节组成的数组。这个数组来自于 initcode.S 是系统执行的第一个用户模式的进程
initcode.S
在 initcode.S 代码中所做的是调用确切的系统调用,并且调用的进程名称为 /init ,还有 0 参数,这个 init 函数不应该返回,这个 init 函数应该存在,并且如果由于某种原因返回了,这将调用 exit 系统调用,然后循环退出。函数只能在用户模式下调用
这个汇编代码汇编好之后,从可执行文件中提取字节存放在 initcode 数组中
1 | .globl start |
uvmalloc
该函数将向现有虚拟地址空间添加页面,可以说是将虚拟地址空间给重新分配大小了。这个函数中调用 kalloc 来分配物理内存,并且使用 mappages 将内存映射到页表中。而且该函数申请的新的页表的新的大小不需要页表对齐,页表会在这段内存中尽可能地多分配页面。函数运行结束就返回 newsz 。如果运行中出现任何问题,就会调用 kfree 和 uvmdealloc 将页表大小重新恢复到原大小,并且将所有申请的页面退回到空闲内存中,并且返回 0 表示失败了。
在这个函数中,会给扩大的内存直接赋予可读权限和用户模式可访问权限,可写和可执行权限由外部指定
例如对于堆内存的扩展就可以使用 uvmalloc 函数来实现
其中参数为
pagetable页表地址oldsz虚拟空间原来的大小newsz新的大小xperm给新的页面添加的权限
1 | uint64 |
uvmunmap
删除从 va 开始的映射的 npage 个页表。 va 必须与页面对齐并且映射必须存在,可以选择释放物理内存。这个函数将遍历每个页面并且将其页表项设为 0。其中包括有效位,所以就是将这个页表设置为无效的页表
这个函数传入的参数为
pagetable指向页表的指针va虚拟地址npages从虚拟地址空间删除的页面数do_free是否释放数据页,如果为true还将调用kfree来释放数据页,会释放进空闲池
1 | void |
uvmdealloc
释放用户页面以将大小从 oldsz 调整为 newsz 。 oldsz 和 newsz 不需要页面对齐, newsz 如果大于 oldsz 那就不会取消分配的页面,直接返回。 oldsz 可以大于实际大小,返回新的大小
调用 uvmunmap 函数来从虚拟地址空间释放页面,用来缩小地址空间,并且会释放数据页,所以需要将 do_free=1 ,而且新的大小和旧的大小不需要页面对齐。需要保证新的大小不大于旧的大小,否则将会返回旧的大小,并且不做处理。
其中传入的参数为
pagetable页表地址oldsz旧的大小newsz新的大小
1 | uint64 |
freewalk
用于删除页表,释放页表中的所有索引页,但是不释放数据页,所以需要率先删除所有的叶映射来防止内存泄漏,这是一个递归调用。最后删除根索引页。如果使用递归函数需要注意不要递归的太深,主要是因为内核没有很大的栈,实际上树只有三层,所以不用担心
其中参数为
pagetable指向页表的指针,作用是调用该节点的子结点来删除子树
1 | void |
uvmfree
将会释放掉位于指定地址以下的虚拟地址空间的所有页面。先释放用户内存页,再释放页表索引
在用户的虚拟地址空间的顶部会有 trampoline 页面和 trap 页面,由于 trampoline 页面是由所有的虚拟地址空间共享的页面,所以不去释放,trap 页面也是预先分配的,所以也没有释放
其中传入的参数为
pagetable指向页表的指针sz要释放的虚拟地址空间的地址(实际上也是释放的大小)
1 | void |
uvmcopy
给定父进程的页表,将其内存复制到子进程的页表格中。复制页表和物理内存。成功时返回0,失败时返回-1。失败时释放所有分配的页面。
当使用 fork 指令复制进程时,需要复制整个进程的虚拟地址空间,需要为子进程创建第二个虚拟地址空间,会调用该函数
它会从旧的地址开始复制指定大小的页面到新的地址空间。新的地址空间的 trampoline 页面是映射于同一个位置的,新的虚拟地址空间会有新的 trap frame 页面,而且它将会为所有的虚拟地址空间的 data 页面创建映射到新的物理地址,而且这些新的页面会有相同的权限。如果失败会调用 kfree 和 uvmunmap 删除掉页表的条目并且释放掉所有申请的页面
参数为
old旧的页表地址,父进程页表地址new新的页表的地址,子进程页表地址sz复制的大小,父进程页表的大小
1 | int |
uvmclear
这个函数仅用于在用户模式下将保护页标记为不可访问,防止栈溢出,这就是它唯一用到的地方,通过清除页表条目中的 U 位来标记该页面
传入的参数
pagetable页表地址va虚拟地址
1 | void |
copyin and copyout
对于一个进程来说,需要时不时地将进程的数据移动到虚拟地址空间以内或者之外的地方
但是有时候一个字节块在虚拟地址空间中是连续的块,但是有可能横跨几个页面,而不同的页面存储的位置不一定连续,所以可以将其移动进缓冲区从而将物理地址中这些不连续的字节块连续起来。
copyin
从用户复制到内核,将 len 字节从给定页表中的虚拟地址 srcva 复制到 dst 。成功时返回 0,错误时返回 -1
这个函数将会从用户虚拟空间复制字节到目标内核区域,所以它会复制碎片的地址的数据,传入
传入的参数
pagetable传入的页表dst目标地址,这就像缓冲区一样,想要存储字节的地方,位于内核中srcva源数据地址,位于用户地址空间len传递数据大小
1 | int |
copyout
从内核复制到用户,将len字节从src复制到给定页表中的虚拟地址dstva。成功时返回0,错误时返回-1
用于将数据从这个缓冲区移回虚拟地址空间。或者说是将内核空间的数据复制到用户虚拟地址空间中
传入参数为
pagetable页表dstva目标地址,应该是虚拟地址空间地址,是用户地址空间src指向源数据的指针,内核地址空间len传入数据长度
1 | int |
这两个函数在出错时返回 -1,否则返回 0
copyinstr
将以 null 结尾的字符串从用户复制到内核,将字节从给定页表中的虚拟地址 srcva 复制到 dst ,直到 \0 或最大值。成功时返回 0,错误时返回 -1
函数与 copyin 相似,但是这个传递的是一个字符串,而不是特定的长度
传入的参数为
pagetable页表项dst目标地址/缓冲区地址srcva源虚拟地址max将会传递的最大大小,如果遇到字符串末尾的空终止字时就会停止,传递的字符数量不会超过这个大小,可能是缓冲区的大小。如果一直到最大长度都没有遇到终止字,就会返回 -1 以表示出现了某种错误
1 | int |
进程创建
一些定义
cpus[NCPU]实力化所有 CPU 结构体proc[NPROC]实例化所有进程的结构体initproc指向初始进程指针nextpid进程计数器,初始化为 1pid_lock进程锁,自旋锁KSTACK(p)映射 trampoline page 下的内核堆栈,每个都被无效的保护页包围
allocpid
当需要一个新的进程 id 的话,可以调用这个函数,他将会返回新进程 id,并将进程计数器加一,对进程计数器进行修改需要请求锁
1 | int allocpid() { |
procinit
用于初始化进程数组,只在 0 号内核中被调用一次
1 | void procinit(void) { |
procdump
基本上是为了调试,遍历 proc 数组并且打印每一个被使用的进程的信息,进程号,状态和名字
1 | void procdump(void) { |
proc_pagetable
为给定的进程创建一个用户页表,没有用户内存,但是有 trampoline page 的映射,返回创建的页表
1 | pagetable_t |
allocproc
当需要利用 proc 数组创建一个新的进程时,调用 allocproc 函数,会找到一个未使用的进程结构体,然后初始化它并且返回一个指向它的指针。如果找到了,初始化它并且带着锁返回,如果有任何意外,就返回 NULL ,函数工作流程
- 寻找一个未使用的进程结构体
- 创建一个 trap frame 页,trampoline 被所有页面共享
- 创建一个新页表
- 添加 trap frame 和 trampoline 的映射
- 设置上下文
context(这里是寄存器保存区),也就是初始化上下文,为过程的第一个切片做准备
这个函数不会将代码或者数据添加到地址空间中,如果出现问题就撤销所作的一切操作,返回 NULL ,调用这个函数时应该在之后将这个进程设置为 RUNNABLE 的状态以在未来某一时刻运行。 allocproc 函数只在两个地方使用,一个就是进程初始化,另一个就是 fork 函数
1 | static struct proc * |
forkret
上述代码中返回时并未释放锁,所以需要释放锁,但是从调度器出来之后依旧是拿着锁的
从 fork 产生的进程,可以从 trap 中 return,但是对于新创建的进程,需要伪装一个 trap,然后返回。这里有个静态变量 first ,当这个函数是 fork 产生的,它一定会是 0
文件系统初始化必须在常规进程的上下文中运行(例如,因为它调用 sleep ),因此不能从 main() 运行。
1 | void forkret(void) { |
proc_freepagetable
释放进程的页表,首先释放掉 trampoline page 和 trap frame page,之后释放掉页表,并且释放掉所有的空间
1 | void proc_freepagetable(pagetable_t pagetable, uint64 sz) { |
freeproc
当出现问题,会调用该函数,或者进程结束也会调用该函数。传入参数为需要释放的进程的指针,会释放该进程的 trap frame page 的物理地址和进程的页表的数据页的地址和页表索引页,将进程的剩余字段清零(虽然都是不太必要的),并且进程转台标记为未使用
1 | static void |
userinit
用于设置第一个用户进程,其中的 initcode 是一段机器代码,基本功能就是执行系统调用,传入一个 /init 的参数
1 | void userinit(void) { |
system call
系统调用处理流程,基本上就是一次向下调用
uservec当中断发生就会调用这个函数,这个函数是一段汇编代码usertrap这个函数由uservec调用,这个函数决定是否要做系统调用,如果运行系统调用,会打开中断syscall该函数由usertrap调用来处理系统调用,这个函数具体决定做出怎样的系统调用,需要检查进程的killed标志位,如果置 1,那就杀死进程,退出sys_call系统调用将做一定的操作,然后返回usertrapret每当系统调用返回时都会回到这个函数,然后就会像调度程序一样返回userret被usertrapret调用,将会返回运行用户模式代码
ecall
所有的系统调用的汇编指令都是首先将系统调用号载入 a7 寄存器,系统调用号在后面将会被用来请求对应的内核服务,因此它起到了一个纽带的关系,将对应的内核系统调用例程一一地映射到用户态函数。然后这段汇编调用了 ecall 指令来请求内核的服务,接下来就是重头戏了:
当主动发起一个系统调用时,意味着我们要请求内核的服务(一种情况是系统调用,当用户程序执行 ecall 指令以要求内核为其执行某些操作时)。 ecall 指令就像是一个钥匙,帮助我们打开内核服务的大门,那么 ecall 指令具体功能
ecall (environment call) 指令负责提升 risc-v 的优先级模式,risc-v 有三种模式:用户模式,监视者模式和机器模式。这三种模式的优先级依次升高,当我们主动调用一个系统调用时时,需要提升CPU的特权模式,以获得对某些寄存器的访问权和某些指令的执行权。就是当处于内核态时就会提升为机器模式
事实上, ecall 主动触发了一个用户态异常,进而会导致一系列的陷阱动作,它们都是由硬件自动完成的:
- 将用户的特权模式从
U-Mode提升至S-Mode,为陷阱的处理做准备 - 将当前正在执行的指令地址(或当前指令的下一条)放入
sepc中保存 - 将
stvec中保存的trampoline程序入口地址放入pc中,准备进入 - 将当前导致陷阱的原因记录在
scause寄存器中 - 将当前模式保存在
sstatus的SPP位,并清空sstatus中的SIE位来关闭中断,之前的SIE为保存在SPIE位 - 更新
stval寄存器的值,使其指向出现异常的地址
上述步骤是处理一个陷阱的自动动作,无论导致陷阱的原因是异常还是中断,它们的硬件流程都是上面这些。一般来说在用户模式下运行时, stvec 中的内容就是 uservec 的第一行代码,但是进入到 usertrap 之后就是内核状态了,这时候设置 stvec 为 kernelvec ,也就是进入内核模式之后中断会进入内核中断处理程序
syscalls
这是一个函数指针的队列,指向各种系统调用,一共有 21 个,这些系统调用的函数都不需要传入参数,并且返回参数都是 uint64 类型的数据,返回数据将会被保存到 a0 寄存器
1 | static uint64 (*syscalls[])(void) = { |
user.h
这个文件中包含了一系列系统调用的声明和一些辅助的函数。这个函数用于获得参数,传入数字 0-5 然后获得对应的 trapframe 中的 a 寄存器中的数据
系统调用
系统调用的代码是一段汇编代码,这段汇编代码由 usys.pl 这个脚本生成,具体代码如下,实际上就是调用的 SYS_sbrk 来实现的,在 syscall.h 中有各种系统调用的指令,这些指令依次对应着一个数字。系统调用会从用户模式进入到内核模式。在 risc-v 中,参数传入一般都放在 a0, ... ,a5 寄存器
1 | .global sbrk |
如果从系统调用返回之后,将会回到用户模式继续运行代码。代码返回时将会按照 ra 寄存器中的地址返回,也就是将 ra 中的数据直接 copy 到 pc 指针去。内核将会保留所有寄存器,除了 a0 寄存器,所以可以确定 a0 的值不会改变,可以直接返回
syscall
这个函数会被 usertrap 函数调用,它将会调用一个函数指针数组中的对应的系统调用
1 | void |
argraw
该函数是功能函数,这将被使用来获得用户进程的 trap frame 页面中存储的 a 寄存器的值,这个函数相当于是从寄存器中读取原数值
这个函数将被 argint 函数调用
1 | static uint64 |
argint
这个函数直接调用 argraw 函数,将数据存储在第二个形参中,这个将数据转为一个 int 类型的变量,相当于是从寄存器中读取整数了
1 | void |
argaddr
这个函数直接将寄存器中的数据作为一个地址传入到第二个形参中,这里不需要检验地址是否合法,因为在 copyin 和 copyout 中将会进行检查
1 | void |
argstr
获取第 n 个寄存器中的字符串,存储到 buf 中,获取的最大字符串数量为 max ,如果不出错,那就返回获取到的字符串长度,否则返回 -1
函数中,首先从寄存器中获取该字符串的地址,然后根据地址来获取字符串,这里不会检验地址的合法性,因为在 fetchstr 中会做检验的,实际上它是直接调用 copyinstr 来获取字符串的
1 | int |
argfd
读取第 n 个寄存器中的数据,将其作为文件描述符返回,会检查其合法性,出错就返回 -1 ,一切正常返回 0
n第n个寄存器的数据pfd存储文件描述符pfdpf存储对应文件的指针
1 | static int |
fetchstr
从当前进程的页表中获取字符串,通过调用 copyinstr 来获取,获取成功返回字符串长度,否则返回 -1
1 | int |
fetchaddr
从当前进程的 addr 的地址获取一个无符号 64 位整形,其实就是地址数据
成功返回 0,否则返回 -1
1 | int |
sbrk
这个系统调用将会调用 growproc() 函数,这个将会增加地址空间的大小
这个函数传入一个参数,如果是正的那就增长堆,如果是负的就缩小堆的大小,还可以是 0,这将会返回先前的内存的大小,实际上内存的大小就是最新的分配的地址。这个函数实际上会有一个传入的参数,该参数将会被保存在 a0 寄存器中,所以需要使用上述的 argxxx 函数来调用
1 | uint64 |
growproc
扩大或者缩小 n 字节的用户内存,成功返回 0,否则返回 -1
在函数中,会判断 n 的数据,如果大于 0,就申请内存,并且映射到当前进程的页表中,如果小于 0,就取消分配的进程的页表的内存,如果是 0,就不做任何操作。最后将进程的内存大小更新为最新的内存大小
1 | int growproc(int n) { |
fork
这个系统调用用于创建进程,并且是唯一一个创建进程的方式,而且创建新的进程其实就是从 initproc 的进程直接复制过来,然后开始运行自己的代码。父进程调用该函数创建子进程,而且创建出的进程与父进程完全相同。父进程调用该系统调用时,会进入内核中进行处理,成功复制进程之后,父进程与子进程都会在某一个时刻返回,从内核态返回到用户态,并且会从 fork 函数中得到返回值。不同之处在于,如果调用失败,将会在父进程中返回 -1,并且没有子进程。如果成功在父进程中 fork 函数返回子进程的 id,而子进程返回 0。可以通过判断 fork 函数的返回值来确定当前处于父进程还是子进程,从而决定进程表现按着父进程来还是子进程。如果出现内存用完了不能继续分配内存,那就会创建进程失败
该函数执行的流程
allocproc:寻找一个新的未使用的进程结构体,获取它并且对它进行初始化,会分配一个新的进程号到那个进程结构体中- 复制虚拟内存空间:创建一个空的虚拟地址空间,然后添加对 trap frame page 和 trampoline page 页面的映射。所有父进程的虚拟地址空间中的内容将被复制到子进程的虚拟地址空间中,而且所有页面的权限都与父进程相同
- 初始化
proc结构体:将初始化并且设置一些位于proc结构体中的一些变量sz虚拟地址空间中的字节数,也就是从 0 到堆的顶端trapframe由于父进程进行系统调用fork函数会保存寄存器信息到trapframe中,包括pc寄存器,所以就是说从内核中返回时,子进程将也会返回到ecall的位置并且开始运行。而对于a0寄存器,在子进程中会将其置为 0,也就是在子进程中得到返回值为 0name将会与父进程的name一致ofile将会从父进程中复制所有父进程打开的的文件描述符。也就是在父进程中打开的文件也会在子进程中打开cwd复制父进程的工作路径,子进程工作路径与父进程一致parent将在子进程的结构体中设置parent的指针,并且将会指向父进程的proc结构体state进程的状态将会被设置为RUNNABLE以接收内核的调度运行
- 在父进程中返回子进程的 id 号
系统调用会调用 sys_fork ,而 sys_fork 将会调用 fork 函数,并且 sys_fork 会返回 fork 返回的数据
1 | int fork(void) { |
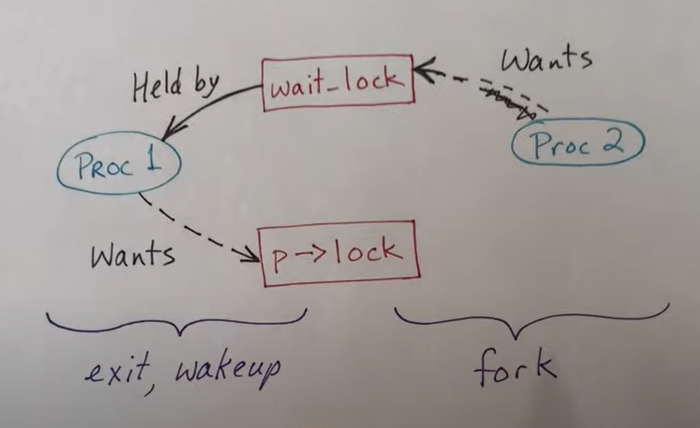
在 exit 和 wakeup 函数中会发生持有 wait_lock 然后申请进程锁,这与 fork 函数会发生死锁情况,所以 fork 函数做出了让步,释放掉进程锁再获取 wait_lock
子进程的运行
当子进程状态为 RUNNABLE 时,CPU 就会给它分配时间片来运行,子进程将会调用 swtch 来进行上下文切换,将内核的寄存器保存,并且加载该进程的寄存器,并且会加载 ra 寄存器。在 swtch 返回时,会返回到 ra 寄存器的地址处开始运行,而 ra 寄存器中保存的是函数 forkret 的地址,也就是程序在 swtch 之后会返回到 forkret 中去,在 sp 寄存器中保存栈的地址。在一般的流程中,从 swtch 函数返回之后应当是返回到 yield 函数中,然后进入 usertrapret 中,然后调用 sret 返回到用户模式中。一般的进程被调度之后的流程类似于 scheduler()->swtch()->sched()->yield()->usertrap->usertrapret->userret->sret但是对于一个还未运行过的程序是不行的,所以对于子进程来说需要一个初始化程序,就是 forkret 这个函数将会在 allocproc 中调用,在其中会设置 p->context.ra=(uint64)forkret 来指定第一次被调度的函数入口。调度器调度这个子进程时,就会进入 forkret 中并且开始运行
所以子函数调用流程就是 scheduler()->swtch()->forkret()->usertrapret()->userret()->sret
forkret
在这个代码中所作的就是解开进程锁,然后直接调用 usertrapret 函数。
会进行判断,也就是对于父进程(从 initproc 中 fork 来的进程)来说,会执行文件系统的初始化。而对于子系统,运行到这里时 first 已经置为 0,就不会再运行文件系统初始化了。况且子进程会对父进程中的所有内容进行复制,所以也不需要初始化文件系统
1 | void forkret(void) { |
exit
该函数用于结束一个进程,可以传入参数作为退出的状态,这将会返回到其它的进程。在 linux/unix 中,该状态参数为 char 类型的,而在 xv6 中,该状态量为 int 类型的。在 linux/unix 中,高位用于传递二外的信息给其它进程,例如导致进程结束的信号量等。但是在 xv6 中没有信号量,所以使用 int 类型的变量。但是不论是在 linux/unix/xv6 中,状态 0 表示成功返回。任何正数都被用来说明出错了
1 | uint64 |
当父进程等待子进程结束
- 状态参数传入到父进程中
- 父进程被唤醒
- 父进程将会清理进程,也就是将子进程的
proc结构体状态设为UNUSE,并且需要释放掉进程的数据结构
其它
- 如果该进程没有父进程,或者父进程先退出不等待子进程退出,那么该子进程将会被冻结,进而变成僵尸进程
ZOMBIE,并且停止运行程序,并且进程的数据结构还没有释放掉,淫威需要地方存储退出状态 - 当父进程一直等待,操作就会完成
如果父进程退出没有等待子进程结束
- 所有子进程将会重新把
init进程作为父进程 init进程会在一个循环中等待,无论哪个子进程退出,init进程都会收集其退出状态,允许僵尸进程退出
reparent
传递一个进程,将其所有子进程都重新设置为 initproc 的子进程
1 | void reparent(struct proc *p) { |
wait
等待其中一个子进程退出并且返回其进程 id 号。传入参数为地址,也就是将进程退出的状态写入这个地方
该函数执行的流程为
- 找到一个僵尸子进程
ZOMBIE- 获取退出状态
- 调用
freeproc将该进程状态修改为UNUSED,然后释放对应进程的地址空间 - 返回进程 id 号
- 如果没有找到
- 进程将会进入
sleep状态,而且唤醒条件是父进程的proc结构体的地址 - 当子进程退出时,必须唤醒父进程,唤醒的信号量是父进程的
proc结构体的地址
- 进程将会进入
- 然后循环该进程,直到没有子进程了,就退出
1 | uint64 |
在 linux/unix 中有个系统调用 waitpid 就是等待对应进程号的进程退出。而且不用进入 sleep 状态,可以直接返回
kill
杀死对应 id 号的进程
1 | uint64 |
锁
spinlock
Spin Locks 自旋锁,在内存中只有一个字节来表示锁。如果锁是未持有的或者自由的,这个字为 0,否则为 1。这个锁在多线程经常被使用,可以被其它进程调用。所以自旋锁不能被长期占用。而且对于 release 和 acquire 操作必须成对在同一个内核中调用。
有四个可调用的方法。
acquire(spinlock* lk)获取,就是等待自旋锁状态被释放,一旦获取锁就会将其置为 1,但是如果没有得到锁会一直不断循环来获得锁,直到获得为止,这个进程中不能够进入sleep状态,而且没有时间分配,所以相当于会堵死。release(spinlock* lk)释放,就是简单的将自旋锁状态设置为 0initlock(spinlock* lk, str)初始化锁holding(spinlock* lk)当前进程是否持有锁
当自旋锁的 acquire 和 release 之间需要 sleep (这是自旋锁无法解决的),就需要 sleeplocks
sleeplock
这是一种可以长期上锁的一个锁
1 | struct sleeplock { |
这个锁与自旋锁十分相似,也是有 acquire 和 release 的方法
有四个可调用的方法
-
acquiresleep(sleeplock*)请求sleeplocks1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void
acquiresleep(struct sleeplock *lk)
{
// 对锁内数据修改需要获得自旋锁
acquire(&lk->lk);
// 退出 sleep 之后重新检查该锁的状态是否被释放
while (lk->locked) {
// 如果锁已经被使用就进入睡眠来等待锁被释放
// 当一个锁释放会使得所有等待该锁的进程中的其中一个获得锁并且开始运行
sleep(lk, &lk->lk);
}
// 设置锁的状态和持有该锁的进程
lk->locked = 1;
lk->pid = myproc()->pid;
release(&lk->lk);
} -
releasesleep(sleeplock*)释放sleeplocks1
2
3
4
5
6
7
8
9
10void
releasesleep(struct sleeplock *lk)
{
// 获取锁,将锁释放并且调用 wakeup 函数,唤醒等待该锁的进程
acquire(&lk->lk);
lk->locked = 0;
lk->pid = 0;
wakeup(lk);
release(&lk->lk);
} -
initsleep(sleeplock*, str)初始化sleeplocks1
2
3
4
5
6
7
8
9void
initsleeplock(struct sleeplock *lk, char *name)
{
// 初始化其中的自旋锁
initlock(&lk->lk, "sleep lock");
lk->name = name;
lk->locked = 0; // 初始化未被 hold
lk->pid = 0; // 未被持有所以初始化为 0
} -
holdingsleep(sleeplock*)当前进程是否持有sleeplocks,如果当前进程获得锁就返回true否则返回false。这个函数主要用来错误检查1
2
3
4
5
6
7
8
9
10int
holdingsleep(struct sleeplock *lk)
{
int r;
// 返回是否被当前进程所持有
acquire(&lk->lk);
r = lk->locked && (lk->pid == myproc()->pid);
release(&lk->lk);
return r;
}