variadic template
就是参数个数随意的模板,定义任意个参数的模板,可以是任意类型
而且可以依据参数重载,关键字 typename… 也可以实现递归,下面的这两种给方式可以并存
相较来看,第一个定义比较特化,第二个比较泛化,所以就会,如果传入参数是 1 + x 那么就调用第一个,否则调用第二个
1 | template <typename... types> |
Space in Template Expressionn**ullptr & std::nullptr_t
左边是一个 object,就是0的空的指针,允许使用 null 代替0
auto
auto 表示不知道是什么类型的变量,可以把任意变量赋予 auto 变量
编译过程中,编译器会自动识别类型, 但是有时候不能使用 auto,使用 aut 必须初始化,不然不能使用(由于编译器不知道类型以及大小,不好分配空间)
1 | verctor<string> v; |
lambda 函数
以 [] 开始的变量
[] 开头表示 lambda 函数,可以在函数内部定义,相当于一个仿函数
Uniform Initialization
一致性的初始化
一致初始化,一般发生在大括号,等于号
可以直接在声明变量之后加上大括号,里面放入初始化的值
编译器在看到{…}之后,就会做出一个 initializer_list<type>,关连着一个 arrary<type,n>, 调用函数时, arrary内的元素可以被编译器分解,逐一传给函数。但是如果该函数参数是一个 initializer_list<T>,调用者却不能够给予整个 T 参数,然后然后以为它们会被自动转化为一个 initializer_list<T> 传入
1 | int values[] {1,2,3}; //-> 内部有一个arrary<int, 3> |
Initializer Lists
1 | int i; // 未定义初值 |
initializer_list<T>
存在于仓库 <bits/stl_algo.h>中,是一种变量,就是定义时能够接收任意类型和数量的变量,但是所有变量类型都一样
1 | initializer_list<T> a{x,x,x,x,x}; |
其实它的背后是一个 array<T, n> 一个数组
explicit
编译器在编译时,计算时会自动把数值转化为与结果相应的类型
1 | class Complex |
如果不加上 explicit 时,编译器就会把 5 转化为复数,但是只能调用单一形参的构造函数,然后相加,但是加上 explicit 之后,禁止调用Complex的构造函数转化,所以相加时就会报错
_iter_less_iter()
位于标准库 <bits/predefined_oops.h> 中,是一个比较大小的函数,返回一个结构体 _Iter_less_iter是一个有重载 () 的结构体,使用 < 比较大小
range-based for statement
存在于c++中的语法,类似于python
1 | for(auto i :initlist) |
default & delete
C++11允许添加 =default 说明符到函数声明的末尾,以将该函数声明为显示默认构造函数。这就使得编译器为显示默认函数生成了默认实现,它比手动编程函数更加有效。
例如,每当我们声明一个有参构造函数时,编译器就不会创建默认构造函数。在这种情况下,我们可以使用default说明符来创建默认说明符。
默认函数需要用于特殊的成员函数(默认构造函数,复制构造函数,析构函数等),或者没有默认参数。例如,以下代码解释了非特殊成员函数不能默认
=default 就是定义函数为默认函数
=delete 就是定义函数已经被禁用,不能再使用
=0 是一种定义纯虚函数的方法,如果在父类结构体中声明函数=0,那么子类想要使用这个函数就必须重写
big-five
Desconstructor构造函数copy constructor复制构造operator=拷贝赋值函数copy constructor移动构造函数class_name(class_name && )Destructor析构函数
NoCopy
在结构体中,所有的拷贝操作都被删除,不能进行拷贝,就是把编译器默认的拷贝函数给删除了
1 | nocopy(const nocopy&) = delete; |
NoDtor
就是在结构体中的析构函数被删除,无法删除生成的变量
1 | NoDtor() = default; |
PrivateCopy
此结构体中不可以被拷贝,但是可以被 friend 和 member 来拷贝,如果想要完全禁止拷贝操作,不但必须把拷贝函数放进 private,而且不可以定义它
Alias Template (template typedef)
不能对 Alias Template 进行特化,不能对这个重定义之后的名字做特化
1 | template <typename T> |
template template parameter
模板的模板参数
1 | template<typename T, template<typename>class Con> |
其实就是再定义一个结构体时,传入的模板参数是一个带有模板参数的模板参数,通常在使用时,这个参数 Con 就会用作 class 类型,而且在这个 class 里,可以定义多种的 Con 类
Type Alias
就是对原来存在的类型名称进行重新定义名字
1 | typedef zhengshu int; |
上述操作就是把 int 重命名为 zhengshu
throw
1 | void excpt_func() |
这个例子就是说,在函数声明之后,定义了一个动态异常的声明 throw(int, double) ,指出了 excpt_func 可能抛出的异常的类型
在函数抛出异常时,就会导致函数栈被依次展开,并依帧调用本帧种已经构造的变量的析构函数,来终止程序运行
在 c++11 中被 noexcept 代替
noexcept
1 | void except_func() noexcept; |
这个常量表达式会被转化为 bool 类型的,如果是 true 就不会抛出异常,否则就会抛出异常。noexcept 表示修饰的函数不会抛出异常,如果修饰的函数抛出了异常,那就会调用 std::terminate() 函数来终止程序的运行,比 throw() 效率更高,相当于是这个函数不能抛出异常
override
就是覆盖掉已经存在的一个方法,并且对其进行重写,从而达到不同的作用,通常在类的继承中搭配虚函数使用,一般就是子类对父类的虚函数进行重写,再次调用时就使用子类的该函数方法,对于普通的函数不能重写
- 纯虚函数(必须重写,否则不能使用该函数) 只有接口被继承
virtual void func() = 0; - 普通虚函数(可以重写)
virtual void func();
final
就是一种禁用派生的关键字
1 | // 1. 禁用重写 (就是该函数即使是虚函数也不能重写) |
decltype
decltype 相当于 typeof(),可以使得编译器找到表达式的类型
1 | template <typename T1, typename T2> |
就是获取数据的类型,充当返回类型,也可以用于 lambda 表达式,面对 lambda表达式 我们只有object, 没有类型,用 decltype 能获得表达式的类型
lambda 函数
- 表达式把函数当作对象,把这个表达式当作对象使用
- 表达式可以赋值给变量,也可以当作参数传给真正的函数
- 在定义包含 lambda 函数的不定序的容器时或者定义一个排序准则,会用到 lambda 类型,这时候需要用到
decltype
1 | [/*captures*/]/*<tparams>*/(/*param*/)-> /*retType*/{/*body*/}; |
captures捕获变量列表,就是在定义lambda函数的那个作用范围内的变量可以通过[]传入使用[epsilon]将参数epsilon按值传递[&epsilon]按引用传递[&]按引用捕获表达式中使用到的所有变量[=]按值捕获表达式中使用到的所有变量[&,epsilon]除了epsilon以外,其他都按引用传递[=,&epsilon]除了epsilon以外,其他都按值传递- 如果使用按值捕获,但是在 lambda 表达式中还想要修改拷贝的值,可以使用
mutable关键字修饰,但是修改也不影响表达式之外的值
tparams模板参数列表,可以省略params参数,传入的列表参数,就是形参,没有参数可以省略不写()retType返回值类型,两种情况下可以不写 :- 无返回值
- 返回值可以被编译器推导
- 如果使用
lambda表达式中含有多个返回值,可以指定返回值类型
body函数体,用于编写具体函数逻辑的地方
lambdas 函数
1 | [] () mutable throwSpec -> retType {} |
- 第一段
[]是lambdas表达式的标志性符号,看见 此符号就应该知道,这是lambdas表达式。‘[]’内可以使用外部变量 - 第二段
()里可以放入参数。 mutable关系着[]里的数据是否可以被改写。throwSpec表示抛出异常。retType是描述 [] 的返回类型。{}是函数本体
标准库
Rvalue reference
右值实现了转移语义和精确传递,主要目的:
- 消除两个对象交互时不必要的对象拷贝,节省运算存储资源,提高效率
- 能够简洁明确的定义泛型函数
判断左值还是右值时,看能不能对表达式取地址,如果能,那就是左值,否则就是右值,一般来说左值引用使用符号&,右值引用使用符号&&
std::move()作用就是将左值当作右值来处理,一旦使用move函数将左值变为右值就不能再次使用了,就是移动构造函数
事实上我们是做了一个浅拷贝(shallow copy)。至于要将之前的指针置为空的原因在于,我们的类会在析构的时候delete掉我们的数组。那么我们浅拷贝出来的这个对象的成员变量(arr指针)就变成了一个悬挂指针(空指针)
深拷贝
当一个类里面有指针时,深拷贝就是不仅复制指针,而且指针所指向的内容也复制一份
浅拷贝
当一个类里面有指针时,深拷贝就是不仅复制指针,但是指针所指向的内容不会复制,两个指针指向同一个内容
perfect Forwarding
完美转发
std::forward<T>(),作用就是将数据的左右值类型保留
是C++11中引入的一种编程技巧,它允许在编写泛型函数时保留参数的类型和值类别,从而实现高效且准确地传递参数。这种技术通过使用右值引用和模板类型推导,使得在函数中以原始参数的形式传递参数给其他函数时,不会发生不必要的拷贝操作,从而提高性能
完美转发的一个关键概念是引用折叠,即一个声明的右值引用实际上是一个左值。这为参数转发(传递)提供了可能。例如,在C++中,我们可以使用 std::move 将左值转换为右值引用,从而在需要时将左值当作右值使用,避免不必要的拷贝操作。
在函数模板中,完美转发意味着完全依照模板的参数类型,将参数传递给函数模板中调用的另一个函数。例如,在模板函数 IamForwording 中,我们希望将参数按照传入时的类型传递给目标函数 IrunCodeActually ,而不产生额外的开销。为了实现这一点,我们需要传递的是一个引用类型,因为引用类型不会有额外的开销。同时,我们需要考虑转发函数对类型的接收能力,因为目标函数可能需要即接收左值引用,又接受右值引用。
总结来说,完美转发是一种在C++中实现高效参数传递的技术,它通过使用右值引用、模板类型推导和引用折叠等特性,确保参数传递时的性能优化和类型匹配。
universal reference
通用引用
构成通用引用有两个条件:
- 必须满足
T&&这种形式 - 类型必须是能够通过编译器推断得到的
可以构成通用引用的情况:
-
函数模板参数
1
2
3template<typename T>
void func(T a); -
auto声明1
2auto a = ....;
-
typedef声明,相当于是重命名一样1
typedef unsigned int u32; // 将无符号整型重命名为 u32
-
decltype声明auto和decltype关键字都可以自动推导出变量的类型,但它们的用法是有区别的:1
2
3auto varname = value;
decltype(exp) varname = value;其中,
varname表示变量名,value表示赋给变量的值,exp表示一个表达式。auto根据=右边的初始值value推导出变量的类型,而decltype根据exp表达式推导出变量的类型,跟=右边的value没有关系。另外,
auto要求变量必须初始化,而decltype不要求,因为已知初始类型。主要依据就是引用类型合成
- T& & => T&
- T&& & => T&
- T& && => T&
- T&& && => T&&
tuple
就是组,一堆不同类型的东西可以储存到一起,储存为 tuple
面向对象的高级编程
C++ 98 (1.0)
C++ 03 (TR1, Tecgnical Report 1)
C++ 11 (2.0)
C++ 14
c++ 包括语言和标准库,程序对象就是包含数据和数据处理数据方法,c语言中的数据可以被任意函数处理,c++中的数据与可以处理这个数据的方法封装在一起,就是 class
1 |
|
友元(friend)
在定义 class 中,函数声明前加 friend 关键字,那么这个函数就可以任意调用 private 中的值,也就是打破了封装,而不是使用 class 内的函数来拿到 private 中的值,这样的函数执行更快
同一个 class 里的各个 object 互为友元
value必须是private中的- 参数尽可能的使用
reference引用 来传递,(const) - 返回值尽量用
reference来传递,但是不能传递局部变量的引用 - 在
class中的函数要加const - 构造函数特殊语法
return by reference
表示返回值是引用的形式,return by reference 传出者无需知道接收者是以什么形式接收的,但是只用指针来传输,就必须知道传出的类型
1 | int& compute(int* a) { |
操作符重载
对于操作符 (+=,-=,*=....) 重载时,引入参数时,第一个参数就是 this,第二个参数就是引用的另一个值,返回时可以用 return by reference
return by reference 传出者无需知道接收者是以什么形式接收的,但是只用指针来传输,就必须知道传出的类型
但是对于操作符 (+,-,...) 重载时,返回值必须是一个 local object,不能用 return by reference 传出数据
临时对象
typename() 创建临时对象,它的生命到下一行就结束了,没有名字,一般在 return 中使用
- 建立一个没有命名的非堆(non-heap)对象,也就是无名对象时,会产生临时对象
- 构造函数作为隐式类型转换函数时,会创建临时对象,用作实参传递给函数
- 函数返回一个对象时,会产生临时对象。以返回的对象最作为拷贝构造函数的实参构造一个临时对象
拷贝
浅拷贝只拷贝指针,深拷贝就是拷贝指针内的内容,但是得提前准备好内存地址,先准备一块空间,再把要拷贝的内容考进去
1 | inline String::String(const String &str) |
拷贝赋值
1 | inline String &String::operator=(const String &str) |
拷贝构造
1 | class Complex |
stack(栈) heap(堆)
stack 是存在于某个作用域的一个内存空间,当你调用函数时,函数本身就会形成一个 stack 来放置它接收到的参数,以及返回地址,在函数体内声明的任何变量其所使用的内存都取自栈
heap system heap 是指由操作系统提供的一块全局内存空间,程序可以动态分配,从其中获得若干块,但是,操作完之后必须释放掉,不然导致内存泄漏
stack objects / static local objects / global objects / heap objects
-
stack objects栈变量1
2
3
4class Complex{};
{
Complex c1(1,2);
}动态参数,生命周期只要离开作用域就会自动调用析构函数清理
-
static local objects静态本地变量1
2
3
4
5class Complex{};
int main()
{
static Complex c2(1,2);
}这就是所谓的静态参数,生命在作用域结束之后依然存在,直到整个程序结束
-
global objects全局变量1
2
3
4
5
6class Complex{};
Complex c3(1, 2);
int main()
{
c3 = {1, -1}
}其中
c3就是一种全局变量,生命在整个程序结束之后结束,也可以看作是静态变量,不同之处在于可以被所有函数调用 -
heap objects 指针变量
1
2
3
4
5
6class Complex{};
....
{
Complex *p = new Complex;
delete p; // 重要
}p所指的就是heap object,但是在程序结束时没有delete掉,那么指针就会被释放,但是指针所指的内存中的内容不会被删除,所以在new之后一定要delete,以免造成内存泄漏
new
先分配 memory 一块空间,再调用 ctor
1 | Complex *p = new Complex; |
delete
1 | delete p; |
VC中内存的分配
在 vc 中,内存分配都是按照 16 的倍数来分配的,不足的补为16的倍数,而且在分配的区域块的第一个内存表示区块的大小,例如分配64位就会用 0x0040 来表示,一般最后一位 1 表示分配出去,0 表示未分配
arrary new 要搭配 arrary delete
不然就会导致头指针那一块内存被释放,但是剩下的内存无法释放并且找不到指针,就会造成内存泄漏
例如:
1 | String* p = new String[3]; |
& 出现在 type 类型 之后表示引用,出现在 object变量 之前,表示取地址
static
在创建函数或者变量之前加上 static 表示创建静态的函数和变量
静态的函数只能处理静态的数据
1 | class Account |
类似于内存池:把 ctors 放进 private 内
1 | class A |
下面这种创建单个唯一的a变量更好
1 | class A |
class template 类模板
需要在创建类时在之前声明 template<typename T> ,在类中要使用某种数据类型就可以用T代替
1 | template<typename T> // 或者 template<class T> 都一样 |
表示 T 还没有指定,可以创建不同类型的数据,会产生两段完全一样的代码,即代码膨胀,在编译时就会对传入的数据类型进行推导,然后把函数内的T全部改为指定的数据类型
namespace 命名空间
using directive
就是在函数开始之前声明using namespace xxusing declaration
就是在函数前声明只使用某个命令using std::cout
更多细节:
- operator type() const;
- explicit complex(…):initialization list{}
- pointer-like object
- function-like object
- Namespace
- template specialization
- Standard Library
- variadic template
- move ctor
- Rvalue reference
- auto
- lambda
- range-base for loop
- unordered contaioners
结构体的复合,继承,委托
-
结构体的复合
其实就是对原来结构体的部分功能的重新使用,感觉像是结构体中套结构体,例如:
1
2
3
4
5
6
7template <class T>
class queue{
protected:
deque<T> c;
public:
bool empty() const {return c.empty();}
}构造和析构函数
构造由内到外:
外部的结构体首先调用内部的结构体的构造函数,然后才执行外部的构造函数1
2Container::Container(...):Component() {};
析构由外到内:
析构函数执行时首先调用外部结构体的析构函数,先把自己的任务做完,再调用内部函数的析构函数1
2Container::~Container(...) {... ~Component();};
-
结构体的委托(Delegation)
就是在结构体中定义一个另一个结构体的指针
1
2
3
4
5
6
7
8
9class StringRep;
class String
{
public:
....
private:
StringRep* rep; // 记得析构函数 delete
} -
结构体的继承
可以继承父类的方法,子类的对象有父类的成分,模板方法
1
2struct list_node{};
struct listlink : public list_node{}; // public 继承构造由内而外,析构由外而内,父类的
dtor必须是virtual虚函数,否则会出现未定义的行为。
虚函数
虚函数后面加 = 0,表示这个函数为纯虚函数,纯虚函数的一般形式: virtual 函数类型 函数名 (参数表列) =0
特点:
- 纯虚函数没有函数体;
- 一个类里如果包含 =0 的纯虚函数,那么这个类就是一个抽象类
- 抽象类不能具体实例化(不能创建它的对象),而只能由它去派生子类
- 在派生类中对此函数提供定义后,它才能具备函数的功能,可被调用。
non-virtual(非虚)函数:不希望子类结构体重新定义它
virtual(虚)函数:希望子类结构体重新定义,并且在父类中已有默认定义
pure virtual(纯虚)函数:希望子类一定要重新定义它,并且在父类中没有默认定义,但是其实是可以有默认定义的
1 | class shape |
1 | document::onfileopen() |
上面的函数在运行的时候,子类结构体变量可以直接调用父类结构体的函数,函数中包含着虚函数,并且在子函数中有定义,就会跳到子函数中执行该函数(相当于执行命 mydoc.serialize()),再跳回父类的函数中
转换函数 conversion function
1 | class Fraction // 分数 |
non-explicit-one-arguement ctor
1 | class Fraction // 分数 |
上面的例子,如果函数 operate double 也存在的话,电脑会认为有两种方法,会报错
- 把f转化为
double,与4相加,再转化为Fraction - 把4转化为
Fraction,与f相加
这时就需要在构造函数之前加上 explict,这时候在加法中就不会把4转化为 Fraction,而是先把f转化为 double,再加法,在转化
智能指针 pointer-like classes
像指针的结构体,需要重载 * 和 -> 符号
1 | template <typename T> |
C++标准库中也有智能指针
1 |
|
仿函数
- – 其实就是一些小的
class组合而成,而且这些class里面有对小括号的重载
1 | class fillter |
模板:
模板的匹配规则:
-
最优化的优于次特化的,即模板参数最精确匹配的具有最高的优先权
-
非模板函数具有最高的优先权。如果不存在匹配的非模板函数的话,那么最匹配的和最特化的函数具有高优先权
其实就是精确度越高优先权越高 -
类模板
1
2
3
4
5
6template <typename T>
class A
{
T m;
T getm(){return m;}
} -
函数模板
1
2
3
4
5template <typename T>
void getvalue(T a)
{
...
} -
成员模板
1
2
3
4
5
6
7
8
9class A
{
template <typename T>
T getx(T x)
{
return x;
}
} -
模板特化
函数模板特化是在一个统一的函数模板不能在所有类型实例下正常工作时,需要定义类型参数在实例化为特定类型时函数模板的特定实现版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// 类模板特化
template <class T>
class stack {};
template < >
class stack<bool> {};
// 函数模板特化
template <class T>
T mymax(const T t1, const T t2)
{
return t1 < t2 ? t2 : t1;
}
template < >
const char* mymax(const char* t1,const char* t2)
{
return (strcmp(t1,t2) < 0) ? t2 : t1;
} -
模板偏特化(局部特化)
对于有多个模板参数的函数或者类,只对其中一个或几个模板参数进行特化处理,但是没有全部进行特化处理,这样就是模板偏特化
-
模板泛化
-
模板模板参数
使用带模板参数的对象来作为模板1
2
3
4
5
6template <typename N,template<typename T>container>
class A
{
container<T> c;
} -
数量不定的模板参数
1
2
3template <typename T,typename... Args>
void abs(T& a, Args&... args);
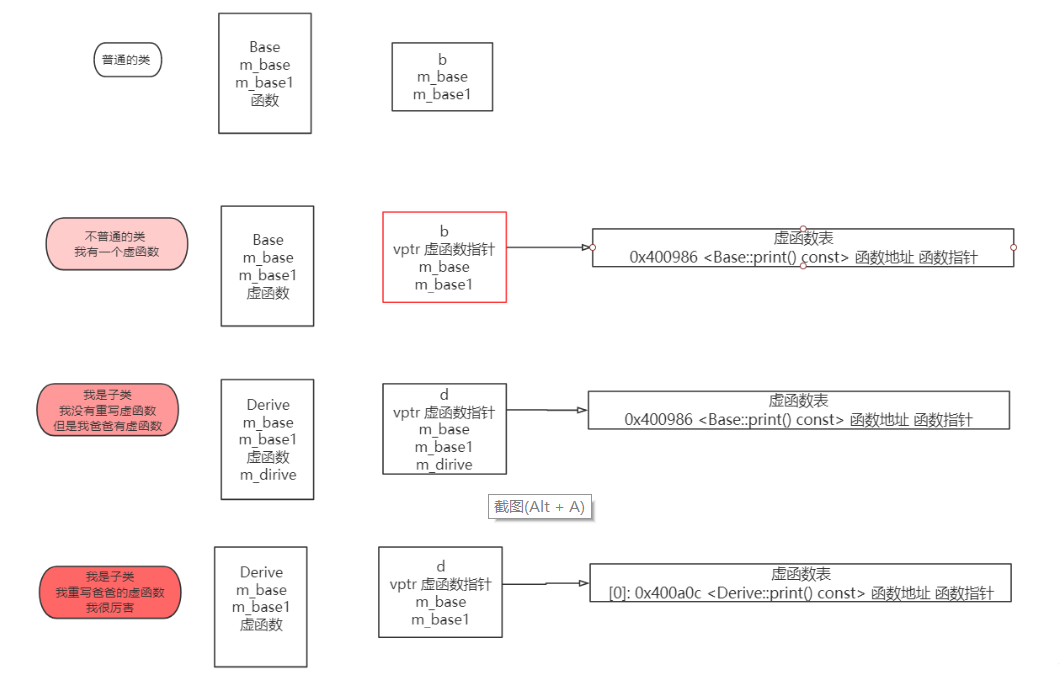
vptr(虚指针) vtbl(虚函数表)

虚指针是一个地址值,以该地址作为起始地址的一片单元格内部存放着各个虚函数地入口地址(这个函数地址也可以相当于是一个指针),这一片内存就是虚函数表,虚指针就是指向指针的指针
对于不同的子类所复写的虚函数也都存放在虚函数表中,这个虚函数表应当是自己的虚函数表,不是父类的虚函数表,对于不同类型的对象会调用不同的虚函数。但是如果子类没有重写父类的虚函数,并且父类的虚函数也不是纯虚函数,那么这个子类的虚函数表调用就是调用的是父类的虚函数表
this(对象模型)
首先,对于类的开辟空间,如果一个空的类,系统也会默认给类分配为1个字(32位)的空间,而且成员函数的定义不影响类的内存大小
this是类中指向这个调用非静态成员函数的对象,this指针不需要自己手动声明或定义,它是被系统定义的
作用
- 用于区分形参和成员变量名
- 用于返回类的本身
- 如果我们创建一个类的空指针,我们依然可以调用不涉及成员变量的类的函数,但是不能访问带有成员变量的成员函数,成员变量与具体的对象有关
常函数
就是类里面的函数不能修改成员变量的特殊函数,除非成员变量之前加上关键字 mutable ,常函数本质上是限制了 this 指针,将指针由 typename *const this 修改为 const typename *const this 让其不能对指向的内容进行修改,常用语法是 返回类型+函数名()+const
常对象
常对象就是在对象前加 const,常对象不能对成员变量进行修改,除非成员变量前加关键字 mutable,并且常对象只能调用常函数,因为通过非常函数调用有可能改变成员变量,常变量语法是 const+类型名+变量名
const
当成员函数的 const 和 non-const 两个版本都存在,那么 const object 只会调用 const 版本, non-const object 只能调用 non-const 版本
| const object(data members 不变) | non-const object(data members 可变动) | |
|---|---|---|
| const member function(保证不更改data members) | true | true |
| non-const member function(不保证不更改data members) | false | true |
| 函数形参使用const来修饰的话,既可以引入常量也可以引入非常量 |
1 | const String str("hello world"); |
mutable
是可变的,易变的,与 const 相反,这个关键字是为了突破 const 的限制而设计的,被 mutable 所修饰的变量,将永远处于可变的状态,即使在 const 函数中也是可变的
1 | class A { |
new delete
new 先分配内存 再调用构造函数
delete 先调用析构函数 再释放内存
可以重载 new 和 delete 函数
对于函数重载
1 | template <typename... types> |
第一种比较特化,如果传入参数的话,优先考虑第一种情况
nullptr and std::nullptr_t
用 nullptr 表示0或者空指针,nullptr 的类型是 std::nullptr_t
auto 变量
auto 表示不知道是什么类型的变量,可以把任意变量赋予 auto 变量,编译过程中,编译器会自动识别类型
1 | verctor<string> v; |
auto keywiord
用 auto 关键字来定义函数的返回值
uniform initializtion
一致初始化,一般发生在大括号,等于号,可以直接在声明变量之后加上大括号,里面放入初始化的值,编译器在看到 {...} 之后,就会做出一个 initializer_list<type> ,关连着一个 arrary<type,n>, 调用函数时, arrary 内的元素可以被编译器分解,逐一传给函数。但是如果该函数参数是一个 initializer_list<T> ,调用者却不能够给予整个 T 参数,然后然后以为它们会被自动转化为一个 initializer_list<T> 传入
1 | int values[] {1,2,3}; -> arrary<int, 3> |
函数的参数为 initializer_list<T>
对于 {"Berlin","NewYork"} 会形成一个 initializer_list<string> ,背后会有一个 arrary<string, n> 。
调用 vectir<string>ctors 时,编译器找到了一个 vector<string>ctor 接受 initializer_list<string>。 所有的容器都如此
函数的参数为单个的变量
对于 complex<double> c {4.0,3.0} ,会把 arrary<type> 中的每一个参数分开,以此执行 complex<type> ctor
complex<type> 并没有任何 ctor 接受 initializer_list<type>
initializer_list
1 | int i; // 未定义初值 |
1 | void print(std::initializer_list<int> vals) |
1 | class P |
对于只包含少量的参数的函数,可以用{…args}传入多个参数
1 | max({1,2,3,4,5}); |
explicit 明确的 不允许转化类型
默认的编译器在编译时,计算时会自动把数值转化为与结果相应的类型
1 | class Complex |
如果不加上 explicit 时,编译器就会把 5 转化为复数,但是只能调用单一形参的构造函数,然后相加
但是加上 explicit 之后,禁止调用 Complex 的构造函数转化,所以相加时就会报错,这个关键字加在构造函数中
default & delete
C++11 允许添加 =default 说明符到函数声明的末尾,以将该函数声明为显示默认构造函数。这就使得编译器为显示默认函数生成了默认实现,它比手动编程函数更加有效。
例如,每当我们声明一个有参构造函数时,编译器就不会创建默认构造函数。在这种情况下,我们可以使用 default 说明符来创建默认说明符。
默认函数需要用于特殊的成员函数(默认构造函数,复制构造函数,析构函数等),或者没有默认参数。例如,以下代码解释了非特殊成员函数不能默认
default 就是默认函数,只针对特殊的函数,例如构造函数与析构函数
delete 就是禁用函数,可以用在任意函数上,与=0不同,=0只能用于虚函数中
big-three(big-five)
Desconstructor构造函数copy constructor复制构造operator =拷贝赋值函数copy constructor移动构造函数class_name(class_name && )Destructor析构函数
NoCopy
在结构体中,所有的拷贝操作都被删除,不能进行拷贝,就是把编译器默认的拷贝函数给删除了
1 | nocopy(const nocopy&) = delete; // 拷贝函数 |
NoDtor
就是在结构体中的析构函数被删除,无法删除生成的类的变量,而且这个变量依然在栈中,需要我们手动删除
1 | NoDtor() = default; |
PrivateCopy
此结构体中不可以被拷贝,但是可以被friend和member来拷贝,如果想要完全禁止,不但必须把拷贝函数放进private,而且不可以定义它
Alias Template (template typedef)
不能对 Alias Template 进行特化,不能对这个重定义之后的名字做特化
1 | template <typename T> |
排序函数
排序函数一般都会规定排序方法,这个排序方法有多种形式
- 函数
- lambda 函数
- 类,前提是这个类里面必须有重载()的函数
引用&
相当于是一个常量指针
- 用于定义变量,必须在定义时初始化,并且之后不再改变(常量指针)
- 用于函数参数的类型限定,相当于是传入一个指针,可以更快并且内存也占用更少
- 可以作为函数返回值,返回一个常量指针
volatile 关键字
用于修饰变量,作用是告诉编译器不要对这个变量做过度的优化,并且这个变量是易变的,每次读取使用这个变量时,是从变量的地址直接读取的。
1 | const volatile int a; |
constexpr 关键字
修饰的变量在编译阶段就可以运算结束,程序中不能更改
数据可以存在只读区.嵌入式开发感知更强.
可以用在需要完整常量表达式的场合. 还能做一下简单计算.