Transformer 模型
前言
Transformer 模型的提出源于传统序列建模架构在长距离依赖的捕捉与计算效率上的瓶颈。Transformer 在 2017 年由 Google 团队提出,在此之前的自然语言处理和语音处理等序列建模任务的主流架构就是循环神经网络和它的变体 LSTM 和 GRU,它们通过隐藏状态传递信息,但是存在着严重的梯度消失的问题。另外还有卷积神经网络,虽然可以并行计算,但是需要堆叠多层才能捕捉长距离的依赖,且对序列建模能力较弱,而且还会导致信息在多层传递中丢失。所以 Transformer 完全摒弃了循环和卷积结构,仅依靠注意力机制构建端到端的序列建模模型,并且基于注意力机制实现全局依赖建模,同时支持全并行计算,彻底解决了传统方法的核心痛点。
核心思想
- 自注意力机制:直接计算序列内的所有位置的依赖关系,高效捕捉长距离的关联
- 多头注意力:多子空间并行注意力计算
- 位置编码:通过正余弦函数注入序列顺序信息,弥补注意力机制的顺序无关性
- 编码器-解码器结构:模块化堆叠设计,兼顾特征编码与生成能力
自注意力机制
自注意力机制的核心就是计算 query 和 key 之间的相似度,进而为 value 分配权重
首先生成这三个矩阵,将输入向量 分别与三个可学习的权重矩阵相乘,其中 ,并且 是输入数据的维度, 是当前输出的维度。对于在 Transformer 中用的多头自注意力模块,每一个注意力机制模块的输出都是最终输出尺寸的一部分,也就是 其中 是头数。得到对应的向量
通过点积计算 与 之间的相似度,得到注意力得分矩阵
当 和 的尺寸比较大时,会导致点积结果的方差增大,导致最终的输出趋于饱和,从而导致梯度消失,此时引入缩放因子
在解码器的自注意力层中,为了防止模型关注未来位置的信息,需要对得分矩阵进行掩码操作,将未来位置的得分设置为
之后对缩放之后的得分矩阵进行 Softmax 归一化,得到注意力权重矩阵,再与 value 矩阵相乘得到最终的自注意力的输出,即
多头自注意力
多头自注意力通过将上面注意力机制中的三个矩阵拆分为 个独立的子空间,并行计算多个自注意力,从而捕捉序列中不同维度的依赖关系
首先将矩阵 分别使用 组不同的权重矩阵 进行线性变换,得到第 个头的子矩阵,即
对每一组都计算缩放点积注意力,得到对应的输出
之后将 个注意力头的输出进行拼接,再通过一个可学习的权重矩阵 进行线性变换,得到多头自注意力的最终输出
位置编码
由于自注意力机制不具备对序列顺序的感知能力,所以 Transformer 通过位置编码将序列位置信息注入输入,计算公式分为正弦和余弦两种形式,适用于任意长度的序列
其中 表示序列中词的位置索引, 表示位置编码向量的维度索引, 表示输入的维度。输入嵌入与位置编码的融合方式为逐元素相加
设计 为正弦函数有多个原因
- 多尺度建模能力:通过 控制频率,控制 和 的周期,可以编码不同粒度的顺序信息,低维捕捉长距离位置变化,高维捕捉局部变化
- 随着序列中词的位置索引的变换,编码向量是连续的
- 另外不需要额外学习参数
- 支持序列泛化:可扩展到比训练时更长的序列中
上述的位置编码是绝对位置编码。设 表示包含 维列向量,而 表示长度为 的输入序列中 位置的编码,定义如下
其中 。则存在一个线性转置 ,使得对于序列中任意有效位置的任意位置偏移,即
其中 的定义如下
矩阵中的元素都是 的矩阵,而主对角线上的 个旋转矩阵的定义如下
最后 完全由 和 指定
Transformer 工作流程
Transformer 是一个利用注意力机制来提高模型训练速度的模型,它是完全基于自注意力机制的一个深度学习模型,适用于并行化计算,本身模型的复杂度导致它在精度和性能上都要高于之前流行的 RNN 循环神经网络。Transformer 的整体结构分为两个部分:编码器和解码器,输入经过预处理之后,由编码器完整特征编码,然后解码器基于编码特征实现目标序列的自回归生成。
- 输入预处理:将原始输入转化为模型可处理的数值向量,并且注入序列位置信息。
- 编码器特征提取:每个编码器包含多头自注意力层和前馈神经网络层,且两层都挺有残差连接和归一化,将输入序列转换为富含语义的上下文特征向量
- 解码器模块:解码器每一层都包含掩码多头自注意力层和前馈神经网络层,基于编码器特征自回归生成目标序列
- 输出后阶段处理:通过线性层和 softmax 将解码器输出转换为最终预测结果
预处理
预处理分为基础文本处理和向量映射与位置编码两个子阶段,每个步骤均为后续的编码器的特征提取提供必要的前提
- 基础文本处理:将原始文本转化为离散的词单元序列
- 分词:将连续的文本拆分为墨西哥可识别的最小单元,常见的分词策略如下
- 词级分词:按空格或者标点拆分,直观但是词汇表规模过大且无法处理未登记词汇
- 子词级分词:通过合并高频字符对生成子词,既能覆盖未登录词,又能控制词汇表大小
- 字符级分词:按字符拆分,优点是词汇表极小,缺点是序列长度过长,且字符本身无独立语义
- 特殊标记:根据任务类型为序列添加标准化特殊标记
<pad>填充标记,用于将不同长度的序列补全到统一长度,便于批量并行计算<sos>序列开始标记,用于解码器的输入起始位置<eos>序列结束标记,用于界定生成序列的标记<cls>分类标记,用于文本分类等任务,通常加在序列开头,其对应的输出向量作为整个序列的语义表征<sep>分隔标记,用于句子对任务,分隔两个输入句子
- 序列长度截断与填充:Transformer 的计算复杂度与序列长度的平方成正比,因此需要设置最大序列长度阈值。当长度超过阈值的序列进行截断,不足阈值的序列用
<pad>标记填充,确保同批次输入的序列长度一致
- 分词:将连续的文本拆分为墨西哥可识别的最小单元,常见的分词策略如下
- 向量映射与位置编码:将离散的 Token 序列转化为连续的数值向量,并且注入位置信息
- 词嵌入:通过嵌入层将每个 Token 的索引映射为固定维度的稠密向量,嵌入层的权重是模型的可学习参数。设词汇表的大小为 ,则嵌入层的权重矩阵 ,对于 Token 索引序列 来说,词嵌入向量的计算为 ,词嵌入的作用是将 Token 的语义信息转化为数值形式,使模型能够捕捉 Token 之间的语义关联
- 位置编码:自注意力机制本身不具备序列顺序感知能力 —— 交换序列中 Token 的顺序,自注意力的计算结果不会改变,因此必须通过位置编码为每个 Token 注入位置信息
- 固定位置编码,就如上述所说的位置编码,利用正弦余弦函数编码
- 可学习位置编码,将位置编码视为模型的可学习参数,与词嵌入一同训练,适用于特定长度范围的序列任务,灵活性更强,但泛化性弱于固定编码
- 向量融合:词嵌入向量与位置编码向量进行逐元素相加,得到最终的输入向量: 。相加操作的前提是词嵌入和位置编码的维度都为 ,该操作可再不增加向量维度的前提下,同时保留 Token 的语义信息和位置信息
另外在图像处理等模型的使用中,预处理的核心就是将二维图像转化为一维的序列向量
- 图像分块:将尺寸为 的图像划分为 个大小为 的图像块,其中
- 将每个图像块平展开为一维向量,再通过线性层映射为维度 的块嵌入向量
- 位置编码:为每一个图像块添加位置编码,并且在序列开头添加
<cls>的标记,最终得到长度为 的输入向量序列
编码器模块
Transformer 编码器的特征提取就是逐层抽象输入序列语义信息的过程,核心是通过多头自注意力机制+前馈神经网络的堆叠结构,结合残差连接与层归一化,最终生成包含全局上下文的特征矩阵。
Transformer 编码器由 个完全相同的编码器层堆叠而成,每个编码器层的结构如下

整体遵循子层输出+残差连接+层归一化的范式,所有编码器层的输入输出维度都为 ,保证层间舒徐传递的一致性。
- 多头自注意力计算:核心是让序列中每个位置的 Token 关注所有位置的 Token,捕捉全局语义关联
- 线性变化生成 矩阵
- 多头拆分并行计算:将三个矩阵按照特征维度拆分,对每个子矩阵计算缩放点积注意力
- 多头拼接与线性变换,将 个注意力头的输出拼接,并且通过权重矩阵映射回原维度,得到多头自注意力的最终暑促
- 为缓解梯度消失问题,对多头自注意力的输出执行残差连接,再进行层归一化
- 前馈神经网络计算:对每个位置的特征进行独立的非线性变化,进一步提取深层语义特征。这个模块利用两个全连接层,中间使用 ReLU 激活函数,对归一化的向量做非线性变换,让向量能表达更复杂的语义
- 第二次残差连接与归一化层,对前馈神经网络的输出再次执行残差连接和层归一化,得到当前编码器层的最终输出
解码器模块
Transformer 的解码器的核心功能是基于编码器输出的源序列特征矩阵和已生成的目标序列片段,自回归式地生成完整的目标序列
解码器由 个相同的解码器层堆叠而成,且与编码器的层数保持一致,每个解码器层包含三个子层,整体结构遵循残差连接+层归一化的范式,输入输出维度均为 。单个解码器层的结构如下
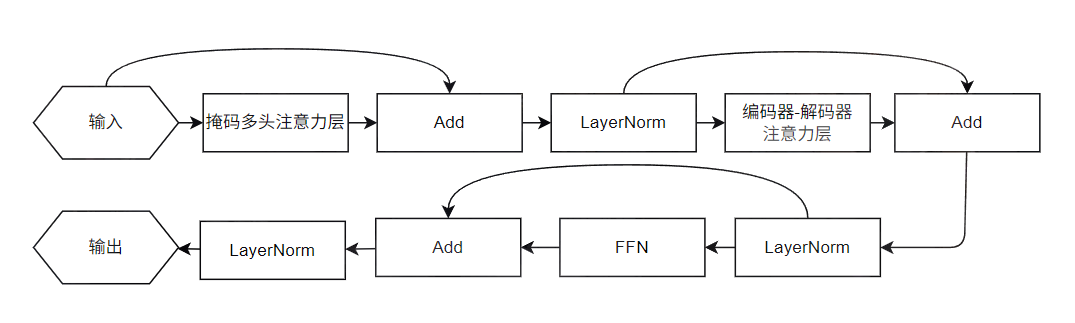
- 掩码多头自注意力层:是解码器的第一个子层,作用是捕捉已生成的目标序列的内部依赖关系,同时防止模型关注未来位置上的 Token
- 计算逻辑与编码器的多头自注意力一致,但是额外添加了掩码:将注意力得分矩阵中当前位置之后的元素设置为
- 同时结合填充掩码,忽略
<pad>标记对应的无效位置,确保注意力计算仅聚焦于有效已生成序列
- 编码器-解码器注意力层:这是解码器的核心子层,也是区别于编码器的关键模块,作用是建立目标序列与源序列的对齐关系。
- 该层的 的输入来自于上一子层的输出
- 和 来自编码器的最终输出特征矩阵,即源序列的全局特征
- 前馈神经网络层:与编码器的前馈神经网络完全相同,对每个位置的特征进行独立的非线性变换,进一步提取目标序列的深层语义特征。这个模块利用两个全连接层,中间使用 ReLU 激活函数
另外解码器的工作流程分为训练阶段和推理阶段,两者的核心差异就在于输入序列的形式不同
- 训练阶段:并行计算,全序列输入,训练阶段的目标是让模型学习源序列到目标序列的映射关系,输入为完整的目标序列预处理向量
- 推理阶段:自回归生成,逐词输出。推理阶段是模型的实际应用场景,输入仅为
<sos>标记,需要逐词生成目标序列,直到出现<eos>标记或达到最大长度。
分词算法
OOV 问题
OOV 问题,即未登录词问题,是在 NLP 领域中非常核心的基础问题,指的就是在模型训练阶段使用的词典中没有收录,但是在测试推理阶段出现的词汇。也就是说,当模型遇到没见过的词时,就会触发 OOV 问题。
在实际使用中,解决 OOV 问题的常用方法如下
- 扩充词汇表:收集目标领域的语料,补充专业术语到词汇表中
- 子词策略:将词汇拆解为更小的语义单元,即时遇到未登录词汇时,也能通过子词组合生成其向量表示
- 字符级模型:直接以字符为基本单位进行建模,绕开词汇表的限制,适合处理生僻词较多的场景
- 特殊标记:利用特殊标记代替所有未知词汇,但是会导致信息丢失
- 在训练过程中动态扩展词汇表,适应新词或领域特定术语
WordPiece
WordPiece 是一种贪心的子词切分算法,核心思想是:将词汇表从单个字符(基础单元)开始,不断合并出现频率最高且能最大化整体语言模型概率的字符或子词对,最终形成一个包含字符、子词、完整词的混合词汇表。在分词时,再用这个词汇表对文本进行逆向切分,把未知词拆解成已知的子词或字符。
WordPiece 的合并依据就是最大似然估计,每次选择都能让整个语料的对数似然值提升最大的子词对进行合并,合并之后的新子词加入词汇表。所以它的目标就是在给定语料库上,找到一组子词,使得这些子词组成的语言模型具有最高的似然概率,它兼顾词汇表大小和未登录词覆盖,是预训练语言模型的主流分词方案
- 训练阶段,主要是构建词汇表
- 初始化:将语料中所有单个字符作为初始词汇表
- 使用当前的词汇表对语料库进行分词,计算每个字符的似然概率
- 遍历语料库,统计语料中所有相邻子词对的出现次数,对于每个候选子词计算合并之后的得分
- 选择得分最高的子词,将其加入到词汇表中,重复上一步操作,直到词汇表达到预定的大小
- 推理阶段,分词操作
- 对输入的文本进行切分,核心是最长匹配贪心算法,即从左到右扫描字符序列,尝试匹配词汇表中最长的子词
- 如果匹配失败,就会回退到更短一点的子词进行匹配,直到匹配到单个字符
- 最终将词切分为多个子词的组合,并且将子词转化为 Token ID 输出
Byte-Pair Encoding
BPE 是 NLP 领域经典的子词分词算法,核心思想就是通过贪心合并高频字符对来构建子词词汇表。它从基础的字符单元出发,迭代合并语料中出现频率最高的相邻字符或子词对,最终生成一个包含字符、子词和完整词的混合词汇表。分词时再用这个词汇表对文本进行逆向切分,将未知词拆解为已知词。
相较于 WordPiece 来说,它的合并规则更简单,仅以相邻字符对出现的频次作为合并的依据
- 训练阶段:构建词汇表
- 初始化词汇表:将语料中所有的单词拆分为单个字符+词尾标记,通常用
</w>表示词汇结束,区分词内子词和词尾子词。另外也将词尾标记加入到词汇表中 - 统计相邻字符对频次:遍历所有单词的字符序列,统计每一对相邻字符的出现总次数
- 贪心合并高频字符对,选择频次最高的字符对进行合并,生成新的子词,并且加入到词汇表中
- 不断迭代,直到词汇表到达预设大小或没有可合并的字符对为止
- 初始化词汇表:将语料中所有的单词拆分为单个字符+词尾标记,通常用
- 推理阶段:分词,对输入文本的分词采用最长匹配贪心策略
- 对单个单词添加词尾标记
</w> - 从左到右尝试匹配词汇表中最长的子词,匹配成功之后移动到子词末尾,继续匹配剩余的部分
- 如果匹配失败,就退回到更短的子词,直到匹配到单个字符
- 最终将单词切分为多个子词的组合
- 对单个单词添加词尾标记
Byte-level BPE
Byte-level BPE 是对传统 BPE 算法的改进版本,核心是将文本的最小处理单元从字符替换为字节,解决了传统 BPE 在多语言、生僻字符场景下的局限性。
传统的 BPE 以字符为基础单元,存在着一些问题
- 不同语言的字符集差异大,直接用字符初始化词汇表会导致词汇表膨胀,且难以覆盖所有语言的生僻字符
- 部分字符编码复杂,无法高效处理
- 传统的 BPE 仍可能存在未覆盖的字符,任何文本都能被编码为 256 种基础字节,根据基础字节来进行训练和推理,理论上能完全消除 OOV 问题
Byte-level BPE 的核心目标就是以字节为基础单元,通过 BPE 的贪心合并策略构建子词词汇表,实现对任意语言、任意文本的无差别分词,即使是从未见过的 emoji、生僻字或乱码,都能被拆分为基础字节进行处理,这是它相比传统 BPE 和 WordPiece 的最大优势
- 训练阶段:与传统的 BPE 的逻辑一致,只是基础单元是字节
- 文本字节化:将训练语料种的所有文本都转化为 UTF-8 字节序列,每个字节的取值范围为
- 初始化词汇表:将基础字节作为初始词汇表,此时词汇表大小为 256
- 统计字节对频次:遍历所有字节序列,统计相邻字节对出现的频次
- 贪心合并高频字节对:选择频次最高的字节对进行合并,生成新的字节级子词,加入词汇表
- 重复迭代,直到词汇表达到预设大小
- 推理阶段:文本分词
- 输入文本字节化:将待分词的文本转化为 UTF-8 字节序列
- 最长匹配贪心切分:基于训练好的字节级词汇表,从左到右匹配最长的子词,匹配成功之后继续匹配剩下的字节,直到所有字节都被切分
- 将切分之后的字节级子词转换为词汇表种对应的 ID
Unigram
Unigram 是一种基于概率模型的子词分词算法,与 BPE、WordPiece 的贪心合并策略不同,它的核心思想是从大词汇表出发,通过迭代删除对语言模型贡献最小的子词,最终得到最优词汇表。它的核心假设是文本中的每个子词都是独立分布的,分词的目标是找到一组子词,使得文本的整体概率最大化。
它与 BPE 的核心区别在于:BPE 是从字符开始的,合并高频子词对,逐步构建词汇表;而 Unigram 是自顶向下的,从包含所有可能子词的大词汇表开始,逐步删除无用子词,精简词汇表。核心目标就是找到一个最优子词集合,技能覆盖文本中的所有词,又能让文本的生成概率最高。
- 训练阶段:构建子词词汇表
- 初始化大词汇表:生成一个包含所有可能子词的初始词汇表,通常包含语料种所有的完整词,所有词的前缀、后缀等。初始词汇表通常很大,需要后续剪枝
- 训练语言模型,基于当前词汇表,计算每一个子词的出现频率,对任意一个单词,可能有多种子词切分的方式,选择概率乘积最大的切分方式
- 计算子词的损失值,对每个子词,计算删除该子词后文本概率的下降幅度,这个幅度就是子词的贡献度,贡献度越低的子词,越容易被删除
- 剪枝与迭代:按照损失值从小到大排序,删除一定比例的子词
- 当词汇表达到预设的大小,或者损失值过大,停止迭代,得到最终词汇表
- 推理阶段:文本分词,Unigram 的分词策略是全局最优选择,而非是贪心策略
- 对于输入的单词,生成所有可能的子词切分方式
- 计算每种切分方式的概率乘积
- 选择概率乘积最大的切分方式作为最终结果
- 为了提高效率,使用中也会使用动态规划代替暴力枚举,减少计算量
Unigram 的优点:
- 分词精度高:基于全局最优策略,相比贪心算法能得到更合理的分词切分
- 灵活性强:支持一个单词的多种切分方式,能适应不同上下文
- 词汇表质量高:剪枝过程中保留对语言模型贡献大的子词,冗余较少
缺点:
- 自顶向下的剪枝+动态规划计算,时间复杂度远高于 BPE 和 WordPiece
- 内存消耗大:初始词汇表规模大,对硬件要求较高
- 推理速度慢:分词时需要动态规划,比贪心匹配要慢
SentencePiece
SentencePiece 是一款适用于神经文本处理的语言无关性子词分词器与反分词器,核心目标就是构建端到端、无语言依赖的文本处理流程。它的工作主要分为 4 个流程
- 预处理:将语义等价的 Unicode 字符转换为标准的形式,避免因字符格式差异导致的分词偏差
- 训练:从归一化后的原始语料中直接训练子词分割模型,支持主流算法
- BPE 字节对编码
- Unigram 单语语言模型
- 编码器:先调用归一化器处理输入文本,再用训练好的子词模型将文本切分为子词序列,或直接转换为 ID 序列
- 解码器:作为编码器的逆操作,将子词序列或 ID 序列还原为归一化后的原始文本,确保编码解码的无损可逆
SentencePiece 突破传统分词工具的语言依赖限制,核心设计在以下两点
- 无损分词:SentencePiece 将所有字符(包含空格)都视为 Unicode 序列,空格用
_转义之后保留。另外子词分割时包含所有原始格式的信息,解码时通过简单的替换即可无歧义还原文本 - 直接从原始语料训练:例如 WordPiece 等分词方法,它们都是以预分的词序列作为输入,无法处理无空格分割的语言,它的核心创新点在于它将文本视作一个原始的 Unicode 字符序列,甚至移除或者忽略语言中的空格,将空格也视作一个普通字符来处理,然后在完全数据驱动的条件下来构建词表
另外在传统的 BPE 分词时,它的时间复杂度为 ,但是在 SentencePiece 使用二叉堆管理合并符号,将复杂度降低到 。在 SentencePiece 中,内置词汇表与 ID 的双向映射,编码器可以直接输出 ID 序列,解码器可以从 ID 序列还原出文本。
经典的网络示例
BERT
BERT(Bidirectional Encoder Representations from Transformers)的核心是基于多层双向 Transformer 编码器的堆叠结构 Encoder-only,设计目标是通过双向上下文建模生成高质量的文本语义表示,为各类下游 NLP 任务提供通用的预训练特征。
BERT 的整体结构是多层 Transformer Encoder 的堆叠,不包含 Transformer 的解码器的部分,所有层都遵循自注意力+前馈网络的组合。从输入到输出,完整的流程包含 3 个阶段
- 输入嵌入层:将文本转化为模型可处理的向量表示。嵌入向量由 3 部分向量相加得到
- Token Embedding:单词级别的向量表示,通过词表映射实现。BERT 使用 WordPiece 分词算法,将未登录词拆分为子词,提升对生僻词的覆盖能力
- Segment Embedding:用于区分输入序列中的不同句子,用
<SEP>来分割 - Position Embedding:用于补充 Token 的位置信息。与原始 Transformer 的正弦余弦位置编码不同,BERT 的位置编码是可学习的参数,取值范围覆盖模型支持的最大序列长度,每个位置对应一个唯一的向量
- 另外,BERT 的输入序列必须添加
<CLS>的标记,该标记位于序列最开头
- 编码器堆叠层:通过多层双向注意力捕捉上下文语义。每个编码器层都包含两个子层,且每个子层都采用残差连接+层归一化的结构
- 多头自注意力机制:实现双向上下文建模的核心,原理就是让每个 Token 同时关注序列中所有的其他的 Token 的信息,从而捕捉双向语义依赖
- 前馈神经网络层:这是一个两层的全连接网络,中间带有激活函数,对每个 Token 向量进行独立的非线性变换
- 输出层:输出每个 Token 的上下文嵌入向量,用于下游任务微调。经过多层编码器堆叠之后,BERT 会输出每个 Token 对应的上下文嵌入向量
- 对于
<CLS>标记的输出向量,可以直接用于句子级任务,只需在其基础上添加一个全连接层即可 - 对于普通的 Token 的输出向量,可用于词级任务,直接对每个 token 的向量进行分类
- 对于
BERT 的训练分为预训练和微调两个阶段,核心原则是:预训练阶段学习通用文本数据,而微调阶段适配具体的下游任务,且两个阶段共享主体架构
- 预训练阶段:基于海量的无标签的文本,通过两个互补任务联合训练,目标就是学习双向上下文和句子之间的关系
- 掩码语言模型 MLM:随机选择 15% 的 Token 进行掩码处理,其中的 80% 替换为掩码
<MASK>, 10% 替换为随机 Token,10% 保持原词 - 下一句预测 NSP:输入两个句子,50% 概率为连续语句,50% 为无关语句
- 掩码语言模型 MLM:随机选择 15% 的 Token 进行掩码处理,其中的 80% 替换为掩码
- 微调阶段:微调阶段使用标注的数据,将预训练好的模型参数作为初始化,通过微调所有参数适配具体的任务,无需修改主体的结构
- 将下游任务的输入统一为 BERT 的序列格式
- 输出层根据任务类型适配,根据任务类型添加输出层
GPT 系列
GPT-1
其中的 MoE 稀疏 FFN 用于降低标准自注意力的复杂度,核心概念如下
- 稀疏注意力:标准注意力中每个 Token 需与所有其他 Token 计算注意力,复杂度为 ,当序列长度较长时计算与显存开销极大。稀疏注意力通过限定注意力计算范围,将复杂度降低到 或 ,以此来适配长文本输入并且降低计算成本
- 稀疏激活:MoE 并非直接修改注意力层,而是替换 Transformer 中的稠密前馈网络层。核心就是稀疏激活,即每个 MoE 层包含多个专家子网络,通过门控网络为每个 Token 选择 个概率最高的网络参与计算,未被选中的网络休眠,大幅减少实际计算量,同时通过增加网络数线性扩展模型容量,而计算开销仅亚线性增长
GPT 是 OpenAI 提出的基于生成式预训练+判别式微调的通用语言理解模型,核心目标就是通过无监督预训练学习通用的语言表示,再通过少量任务适配实现多类自然语言理解任务,避免为特定的任务设计专用的架构。GPT 以 Transformer 为核心架构,采用解码器的变体设计。
- 嵌入层:双嵌入设计
- 词嵌入:将输入的 Token 映射为 768 维向量,采用字节对编码构建词汇表
- 位置嵌入:采用可学习的位置嵌入,捕捉文本的时序信息,输入序列长度固定为 512 个 Token
- 核心层:由多个 Transformer 解码器块堆叠而成,每个块中包含
- 掩码多头注意力:遮蔽未来的 Token,仅依赖前文信息,保证自回归生成逻辑
- 前馈神经网络:两层全连接+激活函数,激活函数采用 GELU 高斯误差线性单元,相比 ReLU 能缓解梯度消失问题
- 残差连接+层归一化:缓解梯度消失,稳定深度训练
- 输出层:根据不同的训练任务可调整输出头
- 预训练阶段:将最后一层的输出映射为词汇表上的概率分布,用于预测下一个 Token
- 微调阶段:再 Transformer 输出之后添加一个线形层,将 768 维隐藏状态映射为任务标签空间,通过 Softmax 输出标签概率
GPT 的训练流程采用两个阶段的训练范式:无监督预训练和有监督的微调,同时引入任务适配机制来确保任务迁移的有效性。另外整个模型的输出是在单词序列各个位置上的条件概率,例如第 个单词的条件概率定义为
- 无监督预训练:在大规模无标签文本上学习通用语言结构、语义知识和长距离依赖,为后续任务提供初始化参数
- 训练中最大化给定上下文的下一个 Token 的对数似然函数 ,之后利用梯度下降法逐步优化模型的可学习参数
- 整体的目标函数即
- 为无标签的文本语料, 为上下文的窗口大小
- 有监督训练:将预训练得到的通用语言模型适配到具体有监督任务,通过任务的标签优化模型参数,同时暴露ii预训练学到的东西
- 为解决不同任务的输入结构的差异,将所有任务的输入转换为模型可处理的连续 Token 序列,避免修改模型架构
- 最优化标签预测的对数似然函数
- 构建整体的目标函数 ,引入预训练阶段的语言建模目标作为辅助,提升泛化能力并加速收敛
- 为有标签的数据集, 是输入序列, 是标签
GPT-2
GPT-2 延续了 GPT 的生成式预训练的思路,模型结构基于 GPT 做了一些改进
- 输入层:字节级 BPE 编码
- 基础词汇表仅 256 个字节,通过 BPE 合并高频子词
- 限制 BPE 跨字节类别合并,避免常见词因标点、大小写差异被拆分,词汇表最终扩展至 50257 个
- 可处理任意的 Unicode 字符串,无需预处理或者特殊分词,适配各类数据集的原始文本格式
- 核心层:由多个 Transformer 解码器堆叠而成,对每个解码器的结构做了调整
- 残差层的权重初始化时按 缩放,用以缓解深度模型训练的梯度累积问题
- 将层归一化移至每个子块的输入,并且在最后一个自注意力块后新增一层归一化
在训练时,从 GPT-1 的 512 个 Token 扩展至 1024 Token,能更好地捕捉长文本依赖。另外 GPT-2 摒弃了 GPT-1 的预训练+微调的模式,仅通过单一的无监督预训练,让模型从文本中自发学习各类任务逻辑。训练时最大化文本序列的对数似然,让模型学习预测下一个 Token 的同时,自发捕捉任务相关模式,无需修改模型架构或参数,仅通过文本指令+输入的序列格式,引导模型生成对应任务输出,实际上就是任务的描述和输入都作为文本的序列。
GPT-3
GPT-3 的基础架构延续了之前的自回归 Transformer 解码器设计,聚焦长文本依赖捕捉和生成能力
- 核心层:基于 Transformer 解码器的规模化升级
- 稀疏注意力机制,用交替密集注意力与局部带状稀疏注意力模式,平衡计算效率与长距离依赖捕捉能力
- 沿用 GPT-2 的预激活层归一化,残差层权重初始化按照 缩放
训练时将上下文窗口扩展到 2048,支持更长文本输入与生成
T5
T5(Text-to-Text Transfer Transformer)的核心架构是 Encoder-Decoder 结构的 Transformer,最大的特点就是将所有自然语言处理任务统一为文本输入到文本输出的范式,打破了传统的分类、生成等任务的格式
- 输入层:文本序列化与嵌入
- 分词方式采用 SentencePiece 进行 WordPiece 分词
- 嵌入层:包含词嵌入和位置嵌入两个部分。词嵌入将分词之后的 Token 映射为固定维度的向量,位置嵌入采用相对位置编码,更好地捕捉长序列中 Token 的相对位置关系
- 为了实现任务同一,输入文本需添加任务特定前缀,模型通过前缀识别任务类型
- 编码器:由多个相同的 Transformer 编码器块堆叠而成,每个编码器块包含两个子层,每层结构完全一致,并行处理输入序列
- 多头注意力层
- 前馈神经网络层 FNN
- 残差连接与层归一化
- 解码器:由多个相同的 Transformer 解码器块堆叠而成,自回归生成与交叉注意力
- 掩码多头自注意力层
- 编码器-解码器注意力层
- 前馈神经网络层 FNN
- 残差连接与层归一化
- 输出层:文本生成与任务映射。解码器的最终输出向量通过一层线性变换映射到词表维度,再经过 softmax 函数得到每个 Token 的生成概率
在 T5 架构下,所有 NLP 任务都转化为文本到文本的形式,无需为不同的任务设计专用的输出层,简化了模型的适配流程。另外采用预训练任务,即随机覆盖输入文本中的连续片段,让模型预测被遮盖的内容,预训练与微调的任务一致性更高。
- 预训练阶段
- 随机选择 15% 的输入 Tokens,将连续掩码区域替换为
<MASK>,模型需要预测掩码区域的原始文本
- 随机选择 15% 的输入 Tokens,将连续掩码区域替换为
- 微调阶段
- 所有任务通过前缀标注转化为从文本输入到文本输出的格式
- 单个任务微调时更新所有的参数
Transformer-XL
Transformer-XL 是针对传统 Transformer 在语言建模中固定长度上下文限制的核心改进方案,它的结构基于标准的 Transformer 解码器,单新增了段级循环机制和相对位置编码,整体的结构如下
- 预处理层:将长文本转化为可处理的输入单元
- 输入内容为原始语料库,以 Token 为基本单位
- 段划分:将整个语料按固定长度 L 分割为连续无重叠的段序列,每个段序列中包含若干个 Token
- 段与段是连续的语义单元,便于后续的跨段记忆复用
- 输入嵌入层:将预处理之后的 Token 序列转化为向量表示,同时引入位置信息,暂存基础的位置信息
- 段级循环:这是 Transformer-XL 的网络的核心,接收嵌入层的输出,融合历史段信息,扩展有效上下文长度
- 记忆缓存加载:处理当前段时,加载前一段各层的隐藏状态,作为历史记忆
- 另外对历史记忆停止梯度,避免梯度回传到前一段,降低计算复杂度
- 将当前段嵌入层的输出与历史记忆沿着长度维度拼接,得到扩展上下文
- 相对位置注意力与前馈网络层
- 在自注意力计算中融入相对位置信息,替代绝对位置编码,确保跨段时序的一致性。其中的 矩阵来自于当前端的隐藏状态; 矩阵分为来自扩展上下文的 和来自相对位置编码的 两部分, ; 矩阵来自扩展上下文。另外计算注意力的分数,通过 softmax 得到注意力的权重,与 加权求和得到注意力输出
- 残差连接与归一化层:缓解深层网络梯度消失,稳定训练
- 前馈神经网络:由两层全连接组成,中间的激活函数选择 ReLU 或 GELU,输出当前层的隐藏状态,并缓存该状态作为下一段的历史记忆
- 输出层:承接最后一层 Transformer 核心层的输出,完成语言建模的最终预测任务
- 将最后一层的隐藏状态通过线性层映射到词表维度,得到 logits
- 对 logits 施加 Softmax 归一化,得到每个位置下一个 Token 的概率分布
- 之后利用交叉熵损失,最小化预测概率与真实次元的差距,优化模型参数
Transformer-XL 的训练流程以段级循环复用+自回归语言建模为核心,以解决传统的 Transformer 固定长度限制和上下文碎片化为目标
- 预处理:将输入语料按照固定长度分割为连续无重叠的段序列,建词表并初始化词嵌入矩阵,设置网络层数并初始化所有可学习参数
- 逐段迭代:训练以段位单位迭代,每段均复用前一段的隐藏状态,确保跨段信息流动
- 加载当前段与历史记忆
- 逐层计算隐藏状态:上下文扩展计算,相对位置注意力计算
- 计算损失
- 梯度优化与参数更新
- 缓存记忆,迭代下一段
- 训练关键优化策略
- 停止梯度:仅让当前段梯度更新当前参数,避免梯度回传到前一段导致计算复杂度增长
- 自适应 Softmax:针对大词表场景,减少 Softmax 计算量
- 正则化:提升模型泛化能力
XLNet
XLNet 是融合了自回归语言建模和去噪自编码优势的广义自回归预训练模型,核心的创新点在于通过排列语言建模实现双向上下文学习,同时规避 BERT 的预训练-微调差异与独立性假设问题
XLNet 的网络结构以 Transformer-XL 为基础,补充了双流自注意力机制、相对编码扩展等模块
- 段循环机制:处理长文本时,缓存前一段的隐藏状态作为当前段的上下文补充,避免长序列分割导致的信息丢失
- 相对位置编码:摒弃传统的绝对位置编码,通过学习位置之间的相对关系生成编码,保持原始序列位置信息,同时提升长序列建模的泛化性
- 双流自注意力:为解决排列语言建模中的目标位置问题,设计了两组并行的隐藏表示流动
- 内容流:编码上下文信息与当前位置的内容,自注意力计算可访问当前位置的内容与所有前置排列位置的上下文。在微调阶段直接作为模型的输出,与下游任务的输入格式兼容
- 查询流:仅编码上下文信息与目标位置的位置信息,不访问目标位置的内容,确保预测无偏性,自注意力计算仅能访问前置排列位置的上下文,无法访问当前位置的内容。在预训练阶段用于计算目标的 Token 的预测分布,避免直接使用内容流导致信息泄露
- 多段建模与相对段编码:针对下游任务的多段输入场景,XLNet 扩展了 Transformer-XL 的编码机制
- 沿用 BERT 的段后添加
<SEP>标记,文本开始前添加<CLS>标记,将两个段拼接成单个序列进行预训练 - 相对段编码:不使用绝对段嵌入,而是学习是否同段的相对关系。如果位置 和 来自同一段,则段编码为 ,否则为 ,它们都是可训练的参数。在注意力计算时,段编码融入到权重中以支持超过两段的下游任务泛化
- 沿用 BERT 的段后添加
XLNet 的训练流程围绕排列语言建模的目标展开,分为预训练和微调两个阶段
- 预训练阶段:预训练的核心就是排列语言模板,即通过对序列的分解顺序进行随机排列,让模型在自回归框架下学习双向上下文
- 数据预处理:采用大规模无标注的文本,固定序列长度为 512,随机采样两个段拼接作为输入序列。
- 排列采样:对于长度为 的序列,就存在 种可能的分解顺序,记排列集合为 。每次训练时随机采样一个排列 ,将序列的联合概率分解 ,其中 是排列 中的第 个。另外仅排列分解顺序,不改变原始序列的位置编码,确保在微调时与自然序列顺序兼容
- 部分预测:直接预测排列中所有的 Token 会导致训练难度大且收敛慢。将排列 分为非目标部分和目标部分,利用超参数 分割,控制目标比例,即排列末尾 的部分作为预测目标
- 双流注意力计算:基于采样的排列,通过双流自注意力计算各层的内容流和查询流。对于长序列,缓存前一段的内容流隐藏状态作为内存,融入当前段的注意力计算。另外定义损失函数为最大化目标部分的对数似然
- 微调阶段:微调阶段的核心是复用预训练的内容流参数,根据不同任务调整输入处理与输出层,无需保留查询流
- 输入处理:根据任务调整序列长度,对多段任务沿用
<CLS>, A, <SEP>, B, <SEP>格式 - 输出层适配:对于不同的任务,使用不同的输出头
- 输入处理:根据任务调整序列长度,对多段任务沿用
UniLM
UniLM 的核心是共享参数的多层 Transformer 架构,通过灵活的自注意力掩码机制,实现对自然语言的理解和生成任务的统一建模,整体结构如下
- 输入层:输入层遵循 BERT 的设计范式,同时适配多任务场景,具体包含三个部分的嵌入
- Token Embedding:单词级别的向量表示,通过词表映射实现。使用 WordPiece 分词算法,将未登录词拆分为子词,提升对生僻词的覆盖能力
- Segment Embedding:用于区分输入序列中的不同句子,用
<SEP>来分割 - Position Embedding:用于补充 Token 的位置信息。与原始 Transformer 的正弦余弦位置编码不同,BERT 的位置编码是可学习的参数,取值范围覆盖模型支持的最大序列长度,每个位置对应一个唯一的向量
- 将输入格式统一,对于不同的任务采用同样的输入格式,即均在开头添加
<SOS>特殊 Token,每个段末尾添加<EOS>特殊 Token
- 核心层:多层 Transformer 的架构,利用自注意力掩码实现多任务统一,通过不同的掩码矩阵控制 Token 可访问的上下文范围
- 双向 LM 掩码:全零矩阵,允许所有的 Token 相互访问
- 单向 LM 掩码:三角矩阵,从左到右的 LM 中的 Token 仅能访问左侧上下文,而从右到左的 LM 仅能访问右侧上下文
- 序列到序列 LM 掩码:源序列内部可双向访问,目标序列仅能访问左侧上下文以及全部源序列,阻断源序列对目标序列的反向访问
- 任务适配层:预训练之后通过轻量级适配层对接下游任务,无需修改骨干网络参数
- NLU 任务:使用双向 LM 掩码,将
<SOS>的隐藏状态接入 softmax 分类器或跨度测量层 - NLG 任务:使用 Seq2Seq 掩码,将源序列与目标序列拼接,只对目标序列掩码,利用
<EOS>来判断停止
- NLU 任务:使用双向 LM 掩码,将
UniLM 的训练分为预训练和下游任务微调两个阶段,核心是通过多目标联合预训练实现通用语言能力建模,再通过任务特定微调适配具体场景
- 预训练:预训练的目标是四大掩码填空任务的联合优化,同时引入下一句预测任务
- 双向 LM 任务占比 ,随机掩码 15% 的 Token,将其中的 80% 替换为
<MASK>,10% 替换为随机 Token,10% 保留原有 Token,允许 Token 访问全部上下文,学习双向语义融合 - 单向 LM 任务各占 ,掩码与上述一致,但仅允许 token 访问单侧上下文,学习文本生成的顺序依赖
- 序列到序列 LM 任务:输入为源序列 + 目标序列的拼接,源序列可双向访问,而目标序列仅能访问左侧上下文及源序列,学习源与目标间的映射关系
- 下一句预测任务:仅用于双向 LM 任务,判断两个句子是否为连续上下文,增强句间关系建模
- 双向 LM 任务占比 ,随机掩码 15% 的 Token,将其中的 80% 替换为
- 下游任务微调:预训练完成之后,针对 NLU 和 NLG 任务采用不同的微调策略,复用预训练的 Transformer 骨干,仅调整适配层的参数
- NLU 任务:使用双向 LM 掩码的 Transformer 编码器,关闭单向和序列到序列的掩码逻辑,例如在分类任务中,将
<SOS>的最终隐藏向量接入分类器或跨度预测层 - NLG 任务:使用 Seq2Seq 掩码,源序列与目标序列拼接为输入,每个序列的末尾连接
<EOS>作为终止符,随机掩码目标序列中 50%-70% 的 Token,模型学习恢复掩码 Token,同时<EOS>可被掩码以学习生成终止
- NLU 任务:使用双向 LM 掩码的 Transformer 编码器,关闭单向和序列到序列的掩码逻辑,例如在分类任务中,将
Causal LM
Causal LM 是基于 Transformer 架构的自回归语言模型,是单向自回归语言模型的典型代表,核心设计是强制模型只能利用前文信息预测下一个 Token,无法看到后文内容,即当前的输出仅由历史输入决定
核心原理在于注意力掩码,它的注意力掩码采用下三角掩码。在 Transformer 的自注意力层中,对于第 个 Token,只允许它关注第 个 Token,完全屏蔽对 之后的 Token 的注意力。采用的训练目标是最大化预测的概率,即 。在训练时,输入完整序列,通过掩码让模型只能基于前文预测每个位置的 Token
Causal LM 擅长开放式文本生成,在续写文章等方面有较好效果。它的生成能力强,但是对上下文的双向理解能力较弱,因为模型无法利用后文信息优化对前文的理解
Prefix LM
Prefix LM 是基于 Transformer 架构的自回归语言模型,它是对 Causal LM 的改进架构,核心设计是将输入序列分为前缀部分和生成部分,并对两个部分采用不同的注意力策略,它兼顾上下文理解和自回归生成的能力。它的核心原理如下
- 序列划分:将输入序列划分两段
- Prefix 前缀段
- Generation 生成段
- 注意力掩码
- 对 Prefix 段采用双向注意力,允许 Token 之间互相关注,让模型充分理解上下文的语义
- 对 Generation 段采用下三角掩码,只允许 Token 关注前缀段和已生成的 Token,保证自回归生成的因果性
- 训练目标:最大化给定前缀段,生成目标生成段的概率,即 ,其中 为前缀, 为生成内容
VIT
VIT 的核心是将 Transformer 架构从自然语言处理迁移到计算机视觉,通过图像分块+Token 编码+Transformer 编码实现全局特征提取
- 图像分块:将二维图像转化为 Transformer 可处理的一维序列
- 输入图像维度为
- 分块操作:将图像均匀分割为 个固定大小的正方形 patch,每个 patch 的分辨率为
- 图像分割之后,得到的序列长度为
- 展平处理:将每个 patch 展平为一维向量,尺寸为 ,最终得到 patch 序列
- Patch 线性投影:将高维 patch 向量映射到 Transformer 所需的固定维度
- 通过一个可学习的线性投影层 ,将每个展平的 patch 向量映射为 维嵌入,即
- 最终得到 patch 嵌入序列为 ,维度为
- 位置编码:用于补充 patch 的空间位置信息
- 采用可学习的一维位置编码
- 这里不适用二维位置编码的原因是二维位置编码未带来显著性能提升,一维编码已足够捕捉空间关系
- 将位置编码直接加在 patch 的嵌入序列上
- 分类 Token:提供一个专门用于分类的全局特征
- 增加一个可学习的嵌入向量 ,嵌入到 patch 嵌入序列的最前面
- 最终输入 Transformer 的序列为 维度为
- Transformer 编码器:与 Transformer 标准的编码器结构一致,由 层堆叠而成,它包含两个核心子模块
- 多头自注意力:捕捉 patch 之间的全局依赖关系,对 LayerNorm 处理后的输入计算多头注意力,再叠加残差连接
- 多层感知机:对每个 Token 进行非线性变换,两层全连接网络 + GELU 激活函数
- 输出经过 层编码器之后,将分类 Token 的输出进行 LayerNorm 处理,得到最终图像特征
- 分类头
- 预训练阶段:利用两层多层感知机,输出维度为预测训练数据集的类别数
- 微调阶段:简化为单个线性层,输出维度为下游任务的类别数
- 可选择混合架构:利用 CNN 的特征图替代原始图像 patch 作为输入序列,用以弥补 VIT 缺乏对局部视觉结构建模的内在归纳偏置
VIT 的训练遵循大规模预训练+下游任务微调的范式,核心是通过大规模数据抵消其缺乏图像归纳偏置的劣势,同时优化训练效率
- 预训练:学习通用的图像特征表示,需要在超大规模有标签的图像数据集上训练
- 微调阶段:将预训练的通用特征适配到具体的任务
- 模型适配:移除预训练的分类头,替换为零初始化的线性分类头
- 分辨率调整:可以采用比预训练更高的分辨率,以提升细节捕捉能力。另外当输入分辨率变化时,原预训练位置编码不再适用,采用 2D 插值调整位置编码的维度
后记
先这样吧,后续再改进,先做点其他的,后续对这些网络要做一下实现和训练
