非监督学习是指在没有标签或输出变量指导的情况下,算法自行从数据中学习模式、结构和关系的过程。这种学习方式不需要预先定义好的类别或标签,而是让模型自主地从数据中探索潜在的模式和规律,但是结果往往难以解释和评估,因为发现的模式可能不易理解
聚类
聚类算法是数据挖掘中的概念,指的是按照某个特定的标准把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象相似性尽可能大,同时不在同一个簇内的对象之间的差异尽可能大
样本的距离度量
对于样本之间的距离函数 d i s t ( x i , x j ) dist(x_i,x_j) d i s t ( x i , x j )
非负性 d i s t ( x i , x j ) ≥ 0 dist(x_i,x_j)\geq0 d i s t ( x i , x j ) ≥ 0
同一性 d i s t ( x i , x j ) = 0 dist(x_i,x_j)=0 d i s t ( x i , x j ) = 0 x i = x j x_i=x_j x i = x j
对称性 d i s t ( x i , x j ) = d i s t ( x j , x i ) dist(x_i,x_j)=dist(x_j,x_i) d i s t ( x i , x j ) = d i s t ( x j , x i )
直通性 d i s t ( x i , x j ) ≤ d i s t ( x i , x k ) + d i s t ( x k , x j ) dist(x_i,x_j)\leq dist(x_i,x_k)+dist(x_k,x_j) d i s t ( x i , x j ) ≤ d i s t ( x i , x k ) + d i s t ( x k , x j )
对于距离的度量方法
欧氏距离(Euclidean Distance):两点之间的直接距离 d ( x , y ) = ( x 1 − y 1 ) 2 + … + ( x n − y n ) 2 d(x,y)=\sqrt{(x_1-y_1)^2+…+(x_n-y_n)^2} d ( x , y ) = ( x 1 − y 1 ) 2 + … + ( x n − y n ) 2
曼哈顿距离(Manhattan Distance):在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离 d ( x , y ) = ∑ ∣ x i − y i ∣ d(x,y)=\sum\vert x_i-y_i\vert d ( x , y ) = ∑ ∣ x i − y i ∣
切比雪夫距离(Chebyshev Distance):对应于国际象棋中的国王从一个格子走到另一个格子所需要的最小步数 d ( x , y ) = max i ( ∣ x i − y i ∣ ) d(x,y)=\underset{i}{\max}(\vert x_i-y_i\vert) d ( x , y ) = i max ( ∣ x i − y i ∣ ) d ( x , y ) = lim k → ∞ ( ∑ i n ∣ x i − y i ∣ k ) 1 k d(x,y)=\underset{k\rightarrow\infty}{\lim}(\sum_i^n\vert x_i-y_i\vert^k)^{\frac{1}{k}} d ( x , y ) = k → ∞ lim ( ∑ i n ∣ x i − y i ∣ k ) k 1
闵可夫斯基距离(Minkowski Distance):是衡量数值点之间距离的一种非常常见的方法 d ( x , y ) = ( ∑ i n ∣ x i − y i ∣ p ) 1 p d(x,y)=(\sum_i^n\vert x_i-y_i\vert^p)^{\frac{1}{p}} d ( x , y ) = ( ∑ i n ∣ x i − y i ∣ p ) p 1 p p p
标准化欧式距离(Standardized Euclidean Distance):是针对欧式距离的缺点而做的一种改进。对于数据各维分量的分布不一样,那就先将各个分量都标准化 到均值和方差相等 d ( x , y ) = ∑ ( x i − y i s i ) 2 d(x,y)=\sqrt{\sum(\frac{x_i-y_i}{s_i})^2} d ( x , y ) = ∑ ( s i x i − y i ) 2 s i s_i s i i i i
马氏距离(Mahalanobis Distance):马氏距离是基于样本分布的一种距离,物理意义就是在规范化的主成分空间中的欧氏距离 d ( x , y ) = ( x − y ) T Σ − 1 ( x − y ) d(x,y)=\sqrt{(x-y)^T\Sigma^{-1}(x-y)} d ( x , y ) = ( x − y ) T Σ − 1 ( x − y ) Σ \Sigma Σ
余弦距离(Cosine Distance):在几何中,夹角余弦用于衡量两个向量方向的差异,这里用于衡量两个样本向量之间的差异 d ( x , y ) = x ⋅ y ∣ x ∣ ∣ y ∣ d(x,y)=\frac{x\cdot y}{\vert x\vert\vert y\vert} d ( x , y ) = ∣ x ∣ ∣ y ∣ x ⋅ y
汉明距离(Hamming Distance):两个等长字符串之间的汉明距离为,将其中一个变为另外一个所需要作的最小字符替换次数
杰卡德距离(Jaccard Distance):用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度 J ( A , B ) = ∣ A ∪ B ∣ − ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A,B)=\frac{\vert A\cup B\vert-\vert A\cap B\vert}{\vert A\cup B\vert} J ( A , B ) = ∣ A ∪ B ∣ ∣ A ∪ B ∣ − ∣ A ∩ B ∣
相关距离(Correlation distance):相关系数衡量随机变量X与Y相关程度的一种方法,相关系数的取值范围是 [ − 1 , 1 ] [-1,1] [ − 1 , 1 ] d ( x , y ) = 1 − ρ ( x , y ) d(x,y)=1-\rho(x,y) d ( x , y ) = 1 − ρ ( x , y ) ρ ( x , y ) \rho(x,y) ρ ( x , y )
信息熵(Information Entropy):信息熵描述的是整个系统内部样本之间的一个距离,称之为系统内样本分布的集中程度 E n t r o p y ( x ) = ∑ − p i log 2 p i Entropy(x)=\sum-p_i\log_2p_i E n t r o p y ( x ) = ∑ − p i log 2 p i p i p_i p i i i i
聚类性能评估
聚类性能度量又称为聚类的有效性指标。对于聚类结果可以根据某些性能度量来评估聚类效果,也可以将其作为优化目标来得到符合要求的聚类结果。一般来说希望簇内样本尽可能相似,簇间样本尽可能有差异
外部指标
将聚类结果与某个参考模型进行比较
对于数据集 D = { x 1 , … x m } D=\{x_1,…x_m\} D = { x 1 , … x m } C = { c 1 , . . . c k } C=\{c_1,...c_k\} C = { c 1 , . . . c k } C ⋆ = { c 1 ⋆ , … c s ⋆ } C^\star=\{c_1^\star,…c_s^\star\} C ⋆ = { c 1 ⋆ , … c s ⋆ } λ \lambda λ λ ⋆ \lambda^\star λ ⋆ C C C C ⋆ C^\star C ⋆
{ a = ∣ S S ∣ S S = { ( x i , x j ) ∣ λ i = λ j , λ i ⋆ = λ j ⋆ , i < j } b = ∣ S D ∣ S D = { ( x i , x j ) ∣ λ i = λ j , λ i ⋆ ≠ λ j ⋆ , i < j } c = ∣ D S ∣ D S = { ( x i , x j ) ∣ λ i ≠ λ j , λ i ⋆ = λ j ⋆ , i < j } d = ∣ D D ∣ D D = { ( x i , x j ) ∣ λ i ≠ λ j , λ i ⋆ ≠ λ j ⋆ , i < j } \left\{\begin{aligned}&
a=\vert SS\vert\quad SS=\{(x_i,x_j)|\lambda_i=\lambda_j,\lambda^\star_i=\lambda_j^\star,i<j\}\\&b=\vert SD\vert\quad SD=\{(x_i,x_j)|\lambda_i=\lambda_j,\lambda^\star_i\not=\lambda_j^\star,i<j\}\\&c=\vert DS\vert\quad DS=\{(x_i,x_j)|\lambda_i\not=\lambda_j,\lambda^\star_i=\lambda_j^\star,i<j\}\\&d=\vert DD\vert\quad DD=\{(x_i,x_j)|\lambda_i\not=\lambda_j,\lambda^\star_i\not=\lambda_j^\star,i<j\}\end{aligned}\right.
⎩ ⎪ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎪ ⎧ a = ∣ S S ∣ S S = { ( x i , x j ) ∣ λ i = λ j , λ i ⋆ = λ j ⋆ , i < j } b = ∣ S D ∣ S D = { ( x i , x j ) ∣ λ i = λ j , λ i ⋆ = λ j ⋆ , i < j } c = ∣ D S ∣ D S = { ( x i , x j ) ∣ λ i = λ j , λ i ⋆ = λ j ⋆ , i < j } d = ∣ D D ∣ D D = { ( x i , x j ) ∣ λ i = λ j , λ i ⋆ = λ j ⋆ , i < j }
其中 λ i = λ j \lambda_i=\lambda_j λ i = λ j C C C λ i ⋆ = λ j ⋆ \lambda_i^\star=\lambda_j^\star λ i ⋆ = λ j ⋆ C ⋆ C^\star C ⋆ a + b + c + d = m ( m − 1 ) 2 a+b+c+d=\frac{m(m-1)}{2} a + b + c + d = 2 m ( m − 1 )
常用的外部指标有
Jaccard 系数 J C = a a + b + c JC=\frac{a}{a+b+c} J C = a + b + c a
FM 指数 F M I = a a + b × a a + c FMI=\sqrt{\frac{a}{a+b}\times\frac{a}{a+c}} F M I = a + b a × a + c a
Rand 指数 R I = 2 ( a + d ) m ( m − 1 ) RI=\frac{2(a+d)}{m(m-1)} R I = m ( m − 1 ) 2 ( a + d )
这些指标结果位于 [ 0 , 1 ] [0,1] [ 0 , 1 ]
内部指标
不利用任何参考模型直接考察聚类结果
对于聚类结果的簇划分 C C C c i c_i c i
a v g ( c i ) = 2 ∣ c i ∣ ( ∣ c i ∣ − 1 ) ∑ 1 ≤ i ≤ j ≤ ∣ c i ∣ d i s t ( x i , x j ) avg(c_i)=\frac{2}{\vert c_i\vert(\vert c_i\vert-1)}\sum_{1\leq i\leq j\leq\vert c_i\vert} dist(x_i,x_j)
a v g ( c i ) = ∣ c i ∣ ( ∣ c i ∣ − 1 ) 2 1 ≤ i ≤ j ≤ ∣ c i ∣ ∑ d i s t ( x i , x j )
定义 u i = 1 ∣ c i ∣ ∑ x ∈ c i x u_i=\frac{1}{\vert c_i\vert}\sum_{x\in c_i}x u i = ∣ c i ∣ 1 ∑ x ∈ c i x c i c_i c i c i c_i c i c j c_j c j
d c e n ( c i , c j ) = d i s t ( u i , u j ) d_{cen}(c_i,c_j)=dist(u_i,u_j)
d c e n ( c i , c j ) = d i s t ( u i , u j )
常用的内部指标有
DB 指数 D B I = 1 k ∑ i = 1 k max j ≠ i ( a v g ( c i ) + a v g ( c j ) d c e n ( u i , u j ) ) DBI=\frac{1}{k}\sum_{i=1}^k\underset{j\not=i}{\max}(\frac{avg(c_i)+avg(c_j)}{d_{cen}(u_i,u_j)}) D B I = k 1 ∑ i = 1 k j = i max ( d c e n ( u i , u j ) a v g ( c i ) + a v g ( c j ) )
一般来说 DB 指数越小就意味着簇内距离越小同时簇间距离越大,说明聚类的性能好
K-means算法
需要事先指定簇类的数目或者聚类中心,通过反复迭代,直到最后达到簇内点足够近,簇间点足够远的目标。K-means 算法以 k 为参数,把 n 个对象分为 k 个簇,使簇内具有较高的相似度,而簇间相似度较低
基本原理
K-means 算法的目的是将 n 个数据点划分为 k 个簇,使得每个数据点属于离它最近的均值对应的簇,以次来最小化簇内的平方误差之和
首先定义算法中针对所有聚类所得簇 C = { c 1 , . . . c k } C=\{c_1,...c_k\} C = { c 1 , . . . c k }
E = ∑ i k ∑ x ∈ c i ∥ x − μ i ∥ 2 2 E=\sum_i^k\sum_{x\in c_i}\Vert x-\mu_i\Vert^2_2
E = i ∑ k x ∈ c i ∑ ∥ x − μ i ∥ 2 2
其中 μ i = 1 ∣ c i ∣ ∑ x ∈ c i x \mu_i=\frac{1}{\vert c_i\vert}\sum_{x\in c_i}x μ i = ∣ c i ∣ 1 ∑ x ∈ c i x c i c_i c i E E E
因此 K-means 算法的优化目标为 C ⋆ = { c 1 ⋆ , … c k ⋆ } = arg min c 1 , . . . c k E C^\star=\{c_1^\star,…c_k^\star\}=\underset{c_1,...c_k}{\arg\min}E C ⋆ = { c 1 ⋆ , … c k ⋆ } = c 1 , . . . c k arg min E
迭代步骤
初始化:随机选择 k 个数据点作为初始簇的中心
分配:计算每个数据点到各个簇中心的距离,将其分配到最近的簇中心,形成 k 个簇
更新:重新计算每个簇的均值向量
迭代:重复上述步骤,直到簇中心不再发生变化或者达到预期的迭代次数为止
优点
简单易懂
计算效率高
可以扩展到多维空间
应用广泛
缺点
对初始值敏感
需要预先指定簇的数量
对异常值敏感
只适用于凸形簇
K-means++ 聚类方法
为了提高算法收敛速度和聚类效果,提出了该方法。其初始的均值向量选择方法如下
在 m 个数据中随机选择一个作为初始质心 μ 1 \mu_1 μ 1 μ : { μ 1 } \mu:\{\mu_1\} μ : { μ 1 }
对未被选中的每个数据点 x i x_i x i μ \mu μ d ( x i ) d(x_i) d ( x i )
以概率 p i p_i p i x i x_i x i μ \mu μ p i ∝ d ( x i ) p_i\varpropto d(x_i) p i ∝ d ( x i )
重复上述步骤直到 k 个初始质心点全部被选出 μ : { μ 1 , … μ k } \mu:\{\mu_1,…\mu_k\} μ : { μ 1 , … μ k }
继续执行标准的 k-means 步骤进行迭代
层次聚类算法
层次聚类算法(Hierarchical Clustering Algorithm),又称系统聚类法或分级聚类法,是一种常用的无监督学习算法。它通过将数据集划分成多个不同层次的簇,来揭示数据的内在结构和层次关系
基本原理
层次聚类算法的基本思想就是将数据集构建成一个层次结构,这个结构通常以树状图的形式展示,其中每个样本最初表示为一个单独的簇,然后通过计算样本之间的相似度或距离来逐渐合并或分裂簇,形成更大的或更小的簇。整个过程可以表示为一棵树形结构,通过该树状图可以选择合适的切割点来确定最终的聚类结果
通常有两种主要的方法,根据层次分解的顺序分为:凝聚(自下而上)和分裂(自上而下)
簇间相似度度量方法
单链法(Single Linkage):以两个簇中最近的两个点之间的距离作为簇间距离 d m i n ( c i , c j ) = min x ∈ c i , z ∈ c j d i s t ( x , z ) d_{min}(c_i,c_j)=\underset{x\in c_i,z\in c_j}{\min}dist(x,z) d m i n ( c i , c j ) = x ∈ c i , z ∈ c j min d i s t ( x , z )
全链法(Complete Linkage):以两个簇中最远的两个点之间的距离作为簇间距离 d m a x ( c i , c j ) = max x ∈ c i , z ∈ c j d i s t ( x , z ) d_{max}(c_i,c_j)=\underset{x\in c_i,z\in c_j}{\max}dist(x,z) d m a x ( c i , c j ) = x ∈ c i , z ∈ c j max d i s t ( x , z )
平均链法(Average Linkage):以两个簇中所有点对之间的平均距离作为簇间距离 d a v g ( c i , c j ) = 1 ∣ c i ∣ ∣ c j ∣ ∑ x ∈ c i ∑ z ∈ c j d i s t ( x , z ) d_{avg}(c_i,c_j)=\frac{1}{\vert c_i\vert\vert c_j\vert}\sum_{x\in c_i}\sum_{z\in c_j}dist(x,z) d a v g ( c i , c j ) = ∣ c i ∣ ∣ c j ∣ 1 ∑ x ∈ c i ∑ z ∈ c j d i s t ( x , z )
Ward法:以合并后簇的方差增量作为相似度度量,适合欧氏距离
凝聚层次聚类
凝聚层次聚类是一种自底向上的方法,从每个数据点作为单独的簇开始,逐步合并最相似的簇,直到所有数据点合并为一个簇或达到预设的停止条件
初始化:将每个数据点视作一个单独的簇
计算相似度:计算所有簇之间的相似度
合并簇:将最相似的两个簇合并为一个新簇
更新相似度:重新计算新簇与其他簇的相似度
迭代:重复上述步骤,直到所有数据点合并为一个簇或者满足停止条件
分裂层次聚类
分裂层次聚类是一种自上而下的方法,从所有数据点作为一个簇开始,逐步将不相似的簇分裂,直到每个数据点称为一个单独的簇或者达到设定的停止条件
初始化:将所有数据视为一个簇
选择分裂簇:选择最不相似的簇进行分裂
分裂簇:将选定的簇分裂为两个簇
迭代:重复上述步骤,直到每个数据点称为一个单独的簇或者满足停止条件
优点
不需要预先指定聚类数量,灵活性高
可以发现类的层次关系,有助于理解数据内在结构
结果可以使用树状图显示
缺点
计算复杂度高,特别是对于大型数据集
对噪声和异常值敏感,可能会影响聚类结果
某些相似度度量方式容易导致链状效应,使得簇间结构不明确
密度聚类算法
密度聚类(Density-Based Clustering)是一种基于数据点密度分布的聚类方法,能够发现任意形状的簇,并且对噪声和异常值具有较好的鲁棒性。最经典的算法是 DBSCAN 算法
核心概念
ϵ \epsilon ϵ ϵ \epsilon ϵ ϵ \epsilon ϵ 核心点:如果一个样本点的 ϵ \epsilon ϵ M i n P t s MinPts M i n P t s
边界点:如果一个样本点的 ϵ \epsilon ϵ M i n P t s MinPts M i n P t s ϵ \epsilon ϵ
噪声点:既不是核心点,也不是边界点
密度直达:如果点 x i x_i x i x j x_j x j ϵ \epsilon ϵ x j x_j x j x i x_i x i x j x_j x j
密度可达:对于样本点 x i x_i x i x j x_j x j p 1 , … p n p_1,…p_n p 1 , … p n p 1 = x i , p n = x j p_1=x_i,p_n=x_j p 1 = x i , p n = x j p i + 1 p_{i+1} p i + 1 p i p_i p i x j x_j x j x i x_i x i
密度相连:如果存在点 x k x_k x k x i x_i x i x j x_j x j x k x_k x k x i x_i x i x j x_j x j
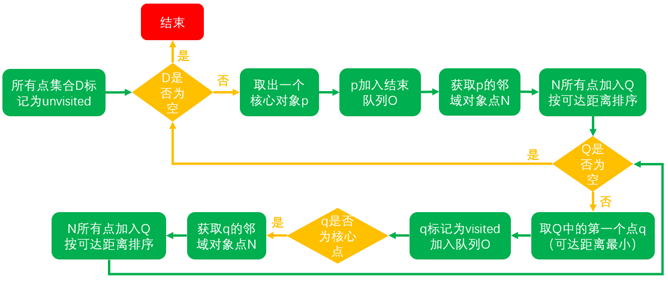
DBSCAN 算法
DBSCAN 算法初始任意选择一个核心对象,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到另一个聚类簇,一直运行到所有核心对象都有类别为止
迭代步骤
初始化:设置参数 ϵ \epsilon ϵ M i n P t s MinPts M i n P t s
遍历数据点:随机选择一个未访问的点,检查其邻域内的点数
如果该点是核心点,那么就围绕它建立一个新簇,并将其所有密度可达的点加入其中
如果不是核心点则标记为噪声点
扩展簇:对于每一个核心点,递归地将其密度直达的点加入当前簇
迭代:直到所有点都被访问
DBSCAN 算法参数选择
ϵ \epsilon ϵ M i n P t s MinPts M i n P t s
优点
能发现任意形状的簇
对噪声和异常值具有鲁棒性
不需要预先指定簇的数量
缺点
对参数 ϵ \epsilon ϵ M i n P t s MinPts M i n P t s
在高维数据中,密度定义可能失效(维度灾难)
对密度差异较大的数据集效果差
OPTICS
Ordering points to identify the clustering structure 是一种基于密度的聚类算法,是 DBSCAN 的改进版本,该算法的提出是为了帮助 DBSCAN 算法选择合适的参数,降低输入参数的敏感度。OPTICS 的输入参数和 DBSCAN 一样,也需要两个参数输入,但该算法对 ϵ \epsilon ϵ ϵ \epsilon ϵ M i n P t s MinPts M i n P t s ϵ \epsilon ϵ ϵ \epsilon ϵ
引入了两个需要的定义
核心距离:对于给定的 M i n P t s MinPts M i n P t s c d ( x ) = { u n d e f i n e d ∣ N ϵ ∣ < M i n P t s d ( x , N ϵ M i n P t s ( x ) ) ∣ N ϵ ∣ ≥ M i n P t s cd(x)=\left\{\begin{aligned}&undefined&\vert N_\epsilon\vert<MinPts\\&d(x,N_\epsilon^{MinPts}(x))&\vert N_\epsilon\vert\geq MinPts\end{aligned}\right. c d ( x ) = { u n d e f i n e d d ( x , N ϵ M i n P t s ( x ) ) ∣ N ϵ ∣ < M i n P t s ∣ N ϵ ∣ ≥ M i n P t s
N ϵ i ( x ) N_\epsilon^i(x) N ϵ i ( x ) N ϵ ( x ) N_\epsilon(x) N ϵ ( x ) x x x i i i
可达距离:对于两个样本点 x x x y y y ϵ \epsilon ϵ M i n P t s MinPts M i n P t s y y y x x x r d ( y , x ) = { u n d e f i n e d ∣ N ϵ ∣ < M i n P t s max ( c d ( x ) , d ( x , y ) ) ∣ N ϵ ∣ ≥ M i n P t s rd(y,x)=\left\{\begin{aligned}&undefined&\vert N_\epsilon\vert<MinPts\\&\max(cd(x),d(x,y))&\vert N_\epsilon\vert\geq MinPts\end{aligned}\right. r d ( y , x ) = { u n d e f i n e d max ( c d ( x ) , d ( x , y ) ) ∣ N ϵ ∣ < M i n P t s ∣ N ϵ ∣ ≥ M i n P t s
r d ( y , x ) rd(y,x) r d ( y , x ) x x x y y y x x x
引入的数据结构
{ p i } i = 1 N \{p_i\}_{i=1}^N { p i } i = 1 N { c i } i = 1 N \{c_i\}_{i=1}^N { c i } i = 1 N i i i { r i } i = 1 N \{r_i\}_{i=1}^N { r i } i = 1 N i i i
算法流程
初始化核心对象集合 Ω \Omega Ω
遍历数据集合 D D D
如果核心对象集合中元素都已经被处理则算法跳入第六步
在核心对象集合中,随机选择一个未处理的核心对象 p p p O O O p p p ϵ \epsilon ϵ Q Q Q
如果集合 Q = ∅ Q=\varnothing Q = ∅ Q Q Q q q q O O O s s s Q Q Q
对于上述处理中得到的有序队列 O O O ϵ \epsilon ϵ
如果该点的核心距离大于 ϵ \epsilon ϵ
重复第六七步,直到有序队列为空
DENCLUE
Density-Based Clustering 是一种基于密度分布函数的聚类算法,通过建模数据点的密度分布来发现簇结构。它特别适合处理高维数据,并且能够识别任意形状的簇。DENCLUE 的核心思想是利用核密度估计(Kernel Density Estimation, KDE)来描述数据的密度分布,并通过密度吸引点(Density Attractors)将数据点分配到簇中
核心概念
密度函数:使用核密度估计来定义数据点的密度分布。对于给定数据集 X = { x 1 , … x n } X=\{x_1,…x_n\} X = { x 1 , … x n } f ( x ) = 1 n ∑ i = 1 n K ( x − x i h ) f(x)=\frac{1}{n}\sum_{i=1}^nK(\frac{x-x_i}{h}) f ( x ) = n 1 ∑ i = 1 n K ( h x − x i )
K K K h h h
密度吸引点:密度吸引点指的是密度函数的局部最大值点。数据点会沿着密度梯度方向“移动”到最近的密度吸引点,从而形成簇
密度吸引:对于每个数据点,通过梯度上升法找到其密度吸引点 x t + 1 = x t + α ∇ f ( x t ) x_{t+1}=x_t+\alpha\nabla f(x_t) x t + 1 = x t + α ∇ f ( x t )
α \alpha α ∇ f ( x t ) \nabla f(x_t) ∇ f ( x t ) x t x_t x t
噪声点:如果数据点的密度值低于某个阈值 ξ \xi ξ
算法步骤
初始化
设置参数:带宽 h h h ξ \xi ξ
计算每个数据点的密度值 f ( x ) f(x) f ( x )
寻找密度吸引点
对于每个数据点,利用梯度上升法找到其密度吸引点
如果密度值小于密度阈值 ξ \xi ξ
分配簇:将具有相同密度吸引点的数据点分配到同一个簇中
合并簇:如果两个密度吸引点之间的距离小于某个阈值,则将它们对应的簇合并
参数选择
带宽 h h h
控制核函数的平滑程度,影响密度估计的精度
通常通过交叉验证或经验选择
密度阈值 ξ \xi ξ
优点
能够处理高维数据
可以发现任意形状的簇
对噪声和异常值具有鲁棒性
理论基础强,基于概率密度估计
缺点
计算复杂度较高,尤其是梯度上升法的迭代过程
对参数(带宽 h h h ξ \xi ξ
需要选择合适的核函数
谱聚类算法
是一种基于图论的聚类算法,通过利用数据的相似性矩阵(或邻接矩阵)的谱(特征值和特征向量)来进行聚类。能处理复杂的簇结构,尤其是非凸形的簇,在高维数据中表现良好
谱聚类将数据点看作图中的节点,数据点之间的相似性看作边的权重。通过构建图的拉普拉斯矩阵(Laplacian Matrix),并分析其特征值和特征向量,将数据映射到低维空间,然后在低维空间中使用传统聚类算法(如 K-Means)进行聚类
步骤
构建相似性矩阵
对于给定数据集 X = { x 1 , . . . x n } X=\{x_1,...x_n\} X = { x 1 , . . . x n } W W W W i j W_{ij} W i j x i x_i x i x j x_j x j
常用高斯核函数来进行相似度度量 W i j = exp ( − ∥ x i − x j ∥ 2 2 σ 2 ) W_{ij}=\exp(-\frac{\Vert x_i-x_j\Vert^2}{2\sigma^2}) W i j = exp ( − 2 σ 2 ∥ x i − x j ∥ 2 )
其中 σ \sigma σ
构建拉普拉斯矩阵
计算度矩阵 D D D D i i = ∑ j = 1 n W i j D_{ii}=\sum_{j=1}^nW_{ij} D i i = ∑ j = 1 n W i j
计算拉普拉斯矩阵
非归一化拉普拉斯矩阵 L = D − W L=D-W L = D − W
对称归一化拉普拉斯矩阵 L s y m = I − D − 1 2 W D − 1 2 L_{sym}=I-D^{-\frac{1}{2}}WD^{-\frac{1}{2}} L s y m = I − D − 2 1 W D − 2 1
随机游走归一化拉普拉斯矩阵 L r w = I − D − 1 W L_{rw}=I-D^{-1}W L r w = I − D − 1 W
计算特征值和特征向量:对拉普拉斯矩阵进行特征值分解,选择前 k k k U ∈ R n × k U\in R^{n\times k} U ∈ R n × k
低维嵌入:将矩阵 U U U
聚类:在低维空间中使用 K-means 等算法对数据点进行聚类
参数选择
相似性矩阵的带宽参数 σ \sigma σ
控制高斯核函数的平滑程度,影响相似性矩阵的构造
通常通过实验或经验选择
聚类数量 k k k
优点
能够处理复杂的簇结构(如非凸形状的簇)
在高维数据中表现良好
理论基础强,基于图论和线性代数
缺点
计算复杂度较高,尤其是特征值分解部分
需要预先指定簇的数量 k k k
对相似性矩阵的构造和参数选择敏感
高斯混合模型 GMM
是一种基于概率模型的聚类算法,假设数据是由多个高斯分布(正态分布)混合生成的,GMM 通过最大化似然函数来估计每个高斯分布的参数(均值,协方差)以及混合系数,从而将数据分配到不同簇中
核心思想
GMM 假设数据是由 K 个高斯分布组成的混合分布生成的,每个高斯分布对应一个簇。数据点生成过程如下
随机选一个高斯分布簇,选择概率由混合系数决定
从选定的高斯分布中生成一个数据点
GMM 的目标是通过最大化似然函数,估计每个高斯分布的参数(均值 μ k \mu_k μ k Σ k \Sigma_k Σ k
数学模型
对于给定数据集 X = { x 1 , … x n } X=\{x_1,…x_n\} X = { x 1 , … x n }
p ( x ) = ∑ k = 1 K π k ⋅ N ( x ∣ μ k , Σ k ) p(x)=\sum_{k=1}^K\pi_k\cdot \mathcal{N}(x|\mu_k,\Sigma_k)
p ( x ) = k = 1 ∑ K π k ⋅ N ( x ∣ μ k , Σ k )
其中
π k \pi_k π k k k k ∑ π k = 1 \sum\pi_k=1 ∑ π k = 1 N ( x ∣ μ k , Σ k ) \mathcal{N}(x|\mu_k,\Sigma_k) N ( x ∣ μ k , Σ k ) k k k N ( x ∣ μ k , Σ k ) = 1 ( 2 π ) d 2 ∣ Σ k ∣ 1 2 exp ( − 1 2 ( x − μ k ) T Σ k − 1 ( x − μ k ) ) \mathcal{N}(x|\mu_k,\Sigma_k)=\frac{1}{(2\pi)^\frac{d}{2}\vert\Sigma_k\vert^\frac{1}{2}}\exp(-\frac{1}{2}(x-\mu_k)^T\Sigma_k^{-1}(x-\mu_k)) N ( x ∣ μ k , Σ k ) = ( 2 π ) 2 d ∣ Σ k ∣ 2 1 1 exp ( − 2 1 ( x − μ k ) T Σ k − 1 ( x − μ k ) )
参数估计
GMM 使用期望最大化(EM)算法来估计参数,算法分为两步
E 步:计算每个数据点 x i x_i x i k k k γ i k = π k ⋅ N ( x i ∣ μ k , Σ k ) ∑ j = 1 K π j N ( x i ∣ μ j , Σ j ) \gamma_{ik}=\frac{\pi_k\cdot\mathcal{N}(x_i|\mu_k,\Sigma_k)}{\sum_{j=1}^K\pi_j\mathcal{N}(x_i|\mu_j,\Sigma_j)} γ i k = ∑ j = 1 K π j N ( x i ∣ μ j , Σ j ) π k ⋅ N ( x i ∣ μ k , Σ k )
M 步:根据上述后验概率更新参数
更新混合参数 π k = 1 n ∑ i = 1 n γ i k \pi_k=\frac{1}{n}\sum_{i=1}^n\gamma_{ik} π k = n 1 ∑ i = 1 n γ i k
更新均值 μ k = ∑ i n γ i k x i ∑ i n γ i k \mu_k=\frac{\sum_i^n\gamma_{ik}x_i}{\sum_i^n\gamma_{ik}} μ k = ∑ i n γ i k ∑ i n γ i k x i
更新协方差 Σ k = ∑ i n γ i k ( x i − μ i ) ( x i − μ i ) T ∑ i n γ i k \Sigma_k=\frac{\sum_i^n\gamma_{ik}(x_i-\mu_i)(x_i-\mu_i)^T}{\sum_i^n\gamma_{ik}} Σ k = ∑ i n γ i k ∑ i n γ i k ( x i − μ i ) ( x i − μ i ) T
重复上述两步,直到参数收敛
参数选择
聚类数量 K K K
需要预先指定簇的数量
可以通过肘部法,信息准则(如 AIC、BIC)或交叉验证选择
协方差矩阵类型
完全协方差矩阵:每个簇有自己的协方差矩阵
对角协方差矩阵:协方差矩阵是对角矩阵
球形协方差矩阵:协方差矩阵是标量乘以单位矩阵
优点
基于概率模型,能够提供属于每个簇的概率
可以拟合复杂的数据分布
能够处理不同形状,大小和方向的簇
缺点
对初始值敏感,可能收敛到局部最优
计算复杂度较高,尤其是高维数据
需要预先指定簇的数量 K K K
模糊 C-means 算法
是一种基于模糊理论的聚类算法,是 K-means 的扩展版本,与 K-means 不同,FCM 允许数据点以一定的概率属于多个簇,而不是严格地属于某一个簇。这种软分配使得 FCM 在处理边界模糊地数据时更加灵活
核心思想
FCM 的目标是最小化以下目标函数
J = ∑ i n ∑ j c μ i j m ∥ x i − v j ∥ 2 J=\sum_{i}^n\sum_j^c\mu_{ij}^m\Vert x_i-v_j\Vert^2
J = i ∑ n j ∑ c μ i j m ∥ x i − v j ∥ 2
其中
n n n c c c u i j u_{ij} u i j x i x_i x i j j j ∑ j c u i j = 1 \sum_j^cu_{ij}=1 ∑ j c u i j = 1 m m m m > 1 m>1 m > 1 v j v_j v j j j j ∥ x i − v j ∥ \Vert x_i-v_j\Vert ∥ x i − v j ∥
FCM 通过迭代优化隶属度和簇中心来最小化目标函数
算法步骤
初始化
随机初始化隶属度矩阵 U = [ u i j ] U=\begin{bmatrix}u_{ij}\end{bmatrix} U = [ u i j ] ∑ j c u i j = 1 \sum_j^cu_{ij}=1 ∑ j c u i j = 1
设置模糊系数 m m m
更新簇中心:计算每个簇的中心 v j = ∑ i n u i j m x i ∑ i n u i j m v_j=\frac{\sum_i^nu_{ij}^mx_i}{\sum_i^nu_{ij}^m} v j = ∑ i n u i j m ∑ i n u i j m x i
更新隶属度:计算每个数据点 x i x_i x i j j j u i j = 1 ∑ k c ( ∥ x i − v j ∥ ∥ x i − v k ∥ ) 2 m − 1 u_{ij}=\frac{1}{\sum_k^c(\frac{\Vert x_i-v_j\Vert}{\Vert x_i-v_k\Vert})^{\frac{2}{m-1}}} u i j = ∑ k c ( ∥ x i − v k ∥ ∥ x i − v j ∥ ) m − 1 2 1
重复迭代:重复上述步骤直到目标函数趋于某个阈值或达到最大迭代次数
参数选择
簇的数量 c c c
需要预先指定簇的数量
可以通过肘部法和轮廓系数等方法选择
模糊系数 m m m
控制隶属度的模糊程度,通常取 m ∈ [ 1.5 , 3 ] m\in [1.5,3] m ∈ [ 1 . 5 , 3 ]
m m m m m m
优点
允许数据点以概率形式属于多个簇,适合处理边界模糊的数据
能够发现复杂的簇结构
对噪声和异常值具有一定的鲁棒性
缺点
计算复杂度较高,尤其是大数据集
对初始值敏感,可能收敛到局部最优
需要预先指定簇的数量 c c c m m m
降维
降维(Dimensionality Reduction)是指通过数学方法将高维数据转换到低维空间,同时尽可能保留原始数据的重要信息。降维的主要目的是减少数据的复杂性,提高计算效率,并有助于可视化和分析
核函数
多维核函数用于衡量数据点之间的相似性,并决定了模型的灵活性和性能
单维核函数(Univariate Kernel Functions)是用于一维数据的核函数,常用于核密度估计(Kernel Density Estimation, KDE)和非参数回归等任务,这些核函数通常是对称的、非负的,并且积分为 1
二维核函数
线性核:最简单的核函数,适用于线性可分的数据,计算效率高但是无法捕捉非线性关系
k ( x i , x j ) = x i T x j + c k(x_i,x_j)=x_i^Tx_j+c
k ( x i , x j ) = x i T x j + c
高斯核:函数无限可微,平滑性好
k ( x i , x j ) = exp ( − ∥ x i − x j ∥ 2 2 σ 2 ) k(x_i,x_j)=\exp(-\frac{\Vert x_i-x_j\Vert^2}{2\sigma^2})
k ( x i , x j ) = exp ( − 2 σ 2 ∥ x i − x j ∥ 2 )
σ \sigma σ
多项式核:可以捕捉数据中的多项式关系
k ( x i , x j ) = ( x i T x j + c ) d k(x_i,x_j)=(x_i^Tx_j+c)^d
k ( x i , x j ) = ( x i T x j + c ) d
d d d
Sigmoid 核:在某些情况下可能导致核矩阵非正定
k ( x i , x j ) = tanh ( α x i T x j + c ) k(x_i,x_j)=\tanh(\alpha x_i^Tx_j+c)
k ( x i , x j ) = tanh ( α x i T x j + c )
径向基函数核:具有强大的非线性建模能力,数据点距离越近,核函数值越大
k ( x i , x j ) = exp ( − γ ∥ x i − x j ∥ 2 ) k(x_i,x_j)=\exp(-\gamma\Vert x_i-x_j\Vert^2)
k ( x i , x j ) = exp ( − γ ∥ x i − x j ∥ 2 )
γ \gamma γ
Matérn 核(Matérn Kernel):是 RBF 核的广义形式
k ( x i , x j ) = 2 1 − v Γ ( v ) ( 2 v ∥ x i − x j ∥ σ ) v K v ( 2 v ∥ x i − x j ∥ σ ) k(x_i,x_j)=\frac{2^{1-v}}{\Gamma(v)}(\frac{\sqrt{2v}\Vert x_i-x_j\Vert}{\sigma})^vK_v(\frac{\sqrt{2v}\Vert x_i-x_j\Vert}{\sigma})
k ( x i , x j ) = Γ ( v ) 2 1 − v ( σ 2 v ∥ x i − x j ∥ ) v K v ( σ 2 v ∥ x i − x j ∥ )
v v v v = 1 2 v=\frac{1}{2} v = 2 1 v → ∞ v\rightarrow\infty v → ∞ σ \sigma σ K v K_v K v
指数核:比 RBF 核更不平滑,适合建模具有突变的数据
k ( x i , x j ) = exp ( − ∥ x i − x j ∥ 2 σ ) k(x_i,x_j)=\exp(-\frac{\Vert x_i-x_j\Vert}{2\sigma})
k ( x i , x j ) = exp ( − 2 σ ∥ x i − x j ∥ )
幂指数核:
k ( x i , x j ) = exp ( − ( ∥ x i − x j ∥ σ ) β ) k(x_i,x_j)=\exp(-(\frac{\Vert x_i-x_j\Vert}{\sigma})^\beta)
k ( x i , x j ) = exp ( − ( σ ∥ x i − x j ∥ ) β )
σ \sigma σ β \beta β
β = 2 \beta=2 β = 2 β = 1 \beta=1 β = 1
拉普拉斯核:对数据点的影响随距离线性衰减,比高斯核更不平滑,适合建模具有突变的数据
k ( x i , x j ) = exp ( − ∥ x i − x j ∥ σ ) k(x_i,x_j)=\exp(-\frac{\Vert x_i-x_j\Vert}{\sigma})
k ( x i , x j ) = exp ( − σ ∥ x i − x j ∥ )
ANOVA 核:基于 ANOVA(方差分析)思想,适合高维数据,对每个维度单独计算核函数,然后求和
k ( x i , x j ) = ∑ k d exp ( − σ ( x i k − x j k ) 2 ) k(x_i,x_j)=\sum_k^d\exp(-\sigma(x_i^k-x_j^k)^2)
k ( x i , x j ) = k ∑ d exp ( − σ ( x i k − x j k ) 2 )
有理二次核:可以看作多个 RBF 核的叠加,适合建模多尺度数据
k ( x i , x j ) = ( 1 + ∥ x i − x j ∥ 2 2 α σ 2 ) − α k(x_i,x_j)=(1+\frac{\Vert x_i-x_j\Vert^2}{2\alpha\sigma^2})^{-\alpha}
k ( x i , x j ) = ( 1 + 2 α σ 2 ∥ x i − x j ∥ 2 ) − α
多元二次核:核函数值随距离增加而增加,适合插值和外推任务
k ( x i , x j ) = ∥ x i − x j ∥ 2 + c 2 k(x_i,x_j)=\sqrt{\Vert x_i-x_j\Vert^2+c^2}
k ( x i , x j ) = ∥ x i − x j ∥ 2 + c 2
逆多元二次核:核函数值随距离增加而衰减
k ( x i , x j ) = 1 ∥ x i − x j ∥ 2 + c 2 k(x_i,x_j)=\frac{1}{\sqrt{\Vert x_i-x_j\Vert^2+c^2}}
k ( x i , x j ) = ∥ x i − x j ∥ 2 + c 2 1
周期核:专门用于建模周期性数据,可以捕捉数据中的重复模式
k ( x i , x j ) = exp ( − 2 sin 2 ( π ∥ x i − x j ∥ / p ) 2 σ 2 ) k(x_i,x_j)=\exp(-\frac{2\sin^2(\pi\Vert x_i-x_j\Vert/p)}{2\sigma^2})
k ( x i , x j ) = exp ( − 2 σ 2 2 sin 2 ( π ∥ x i − x j ∥ / p ) )
单维核函数
高斯核:平滑性好,对数据点的影响随距离衰减
k ( μ ) = 1 2 π exp ( − ( x − x i ) 2 2 h 2 ) k(\mu)=\frac{1}{\sqrt{2\pi}}\exp(-\frac{(x-x_i)^2}{2h^2})
k ( μ ) = 2 π 1 exp ( − 2 h 2 ( x − x i ) 2 )
均匀核:简单,但对数据点的影响是均匀的,非连续导致数据不够平滑
k ( μ ) = { 1 2 ∣ μ ∣ ≤ 1 0 ∣ μ ∣ > 1 k(\mu)=\left\{\begin{aligned}&\frac{1}{2}&\vert \mu\vert\leq1\\&0&\vert \mu\vert>1\end{aligned}\right.
k ( μ ) = ⎩ ⎪ ⎨ ⎪ ⎧ 2 1 0 ∣ μ ∣ ≤ 1 ∣ μ ∣ > 1
三角核:比均匀核更平滑,但仍有一定的突变
k ( μ ) = { 1 − ∣ μ ∣ ∣ μ ∣ ≤ 1 0 ∣ μ ∣ > 1 k(\mu)=\left\{\begin{aligned}&1-\vert\mu\vert&\vert \mu\vert\leq1\\&0&\vert \mu\vert>1\end{aligned}\right.
k ( μ ) = { 1 − ∣ μ ∣ 0 ∣ μ ∣ ≤ 1 ∣ μ ∣ > 1
Epanechnikov 核:平滑性好,计算效率高
k ( μ ) = { 3 4 ( 1 − μ 2 ) ∣ μ ∣ ≤ 1 0 ∣ μ ∣ > 1 k(\mu)=\left\{\begin{aligned}&\frac{3}{4}(1-\mu^2)&\vert \mu\vert\leq1\\&0&\vert \mu\vert>1\end{aligned}\right.
k ( μ ) = ⎩ ⎪ ⎨ ⎪ ⎧ 4 3 ( 1 − μ 2 ) 0 ∣ μ ∣ ≤ 1 ∣ μ ∣ > 1
双权重核:比 Epanechnikov 核更平滑,对数据点的影响随距离快速衰减
k ( μ ) = { 15 16 ( 1 − μ 2 ) 2 ∣ μ ∣ ≤ 1 0 ∣ μ ∣ > 1 k(\mu)=\left\{\begin{aligned}&\frac{15}{16}(1-\mu^2)^2&\vert \mu\vert\leq1\\&0&\vert \mu\vert>1\end{aligned}\right.
k ( μ ) = ⎩ ⎪ ⎨ ⎪ ⎧ 1 6 1 5 ( 1 − μ 2 ) 2 0 ∣ μ ∣ ≤ 1 ∣ μ ∣ > 1
三权重核:比双权重核更平滑,对数据点的影响随距离更快衰减
k ( μ ) = { 35 32 ( 1 − μ 2 ) 3 ∣ μ ∣ ≤ 1 0 ∣ μ ∣ > 1 k(\mu)=\left\{\begin{aligned}&\frac{35}{32}(1-\mu^2)^3&\vert \mu\vert\leq1\\&0&\vert \mu\vert>1\end{aligned}\right.
k ( μ ) = ⎩ ⎪ ⎨ ⎪ ⎧ 3 2 3 5 ( 1 − μ 2 ) 3 0 ∣ μ ∣ ≤ 1 ∣ μ ∣ > 1
余弦核:形状类似于余弦函数,平滑性好
k ( μ ) = { π 4 cos ( π μ 2 ) ∣ μ ∣ ≤ 1 0 ∣ μ ∣ > 1 k(\mu)=\left\{\begin{aligned}&\frac{\pi}{4}\cos(\frac{\pi\mu}{2})&\vert \mu\vert\leq1\\&0&\vert \mu\vert>1\end{aligned}\right.
k ( μ ) = ⎩ ⎪ ⎨ ⎪ ⎧ 4 π cos ( 2 π μ ) 0 ∣ μ ∣ ≤ 1 ∣ μ ∣ > 1
指数核:对数据点的影响随距离指数衰减,不平滑但适合建模突变数据
k ( μ ) = 1 2 exp ( − ∣ μ ∣ ) k(\mu)=\frac{1}{2}\exp(-\vert \mu\vert)
k ( μ ) = 2 1 exp ( − ∣ μ ∣ )
拉普拉斯核:与指数核相同,对数据点的影响随距离指数衰减
k ( μ ) = 1 2 exp ( − ∣ μ ∣ ) k(\mu)=\frac{1}{2}\exp(-\vert \mu\vert)
k ( μ ) = 2 1 exp ( − ∣ μ ∣ )
逻辑核:形状类似于逻辑函数,平滑且对称
k ( μ ) = 1 e μ + 2 + e − μ = 1 2 + 2 cosh ( μ ) k(\mu)=\frac{1}{e^\mu+2+e^{-\mu}}=\frac{1}{2+2\cosh(\mu)}
k ( μ ) = e μ + 2 + e − μ 1 = 2 + 2 cosh ( μ ) 1
五次核:类似于三权重核,比二权重核更平滑
k ( μ ) = { 105 64 ( 1 − μ 2 ) 3 ∣ μ ∣ ≤ 1 0 ∣ μ ∣ > 1 k(\mu)=\left\{\begin{aligned}&\frac{105}{64}(1-\mu^2)^3&\vert \mu\vert\leq1\\&0&\vert \mu\vert>1\end{aligned}\right.
k ( μ ) = ⎩ ⎪ ⎨ ⎪ ⎧ 6 4 1 0 5 ( 1 − μ 2 ) 3 0 ∣ μ ∣ ≤ 1 ∣ μ ∣ > 1
柯西核:长尾分布,适合建模异常值较多的数据
k ( μ ) = 1 π ( 1 + μ 2 ) k(\mu)=\frac{1}{\pi(1+\mu^2)}
k ( μ ) = π ( 1 + μ 2 ) 1
卡方核:基于卡方分布,适合特定类型的非对称数据
k ( μ ) = 1 2 k / 2 Γ ( k / 2 ) μ k / 2 − 1 e − μ / 2 k(\mu)=\frac{1}{2^{k/2}\Gamma(k/2)}\mu^{k/2-1}e^{-\mu/2}
k ( μ ) = 2 k / 2 Γ ( k / 2 ) 1 μ k / 2 − 1 e − μ / 2
降维方法的选择
数据的线性关系
线性数据:如果数据在原始空间中呈现线性关系,可以选择线性降维方法
PCA(主成分分析):最常用的线性降维方法,适合去除冗余特征和降低维度
LDA(线性判别分析):适用于分类任务,能够最大化类间距离
ICA(独立成分分析):适用于信号分离或特征提取
非线性数据:如果数据在原始空间中呈现非线性关系,需要选择非线性降维方法
t-SNE(t-分布邻域嵌入):适合高维数据的可视化,能够保留局部结构
UMAP(Uniform Manifold Approximation and Projection):比t-SNE更快,适合大规模数据
自编码器(Autoencoder):通过神经网络学习非线性映射,适合复杂数据结构
数据的规模大小
小规模数据:可以使用计算复杂度较高的方法,如 t-SNE,核 PCA(Kernel PCA)
大规模数据:需要选择计算效率高的方法,如 PCA,UMAP,随机投影(Random Projection)
数据稀疏性:如果数据是稀疏的(例如文本数据),可以使用 Truncated SVD 或者 NMF(非负矩阵分解)
数据可视化:对于目标是可视化高维数据(降维到 2D 或者 3D)
t-SNE:适合展示局部结构,但计算较慢
UMAP:比 t-SNE 更快,并且能更好的保留全局结构
PCA:适合线性数据的快速可视化
特征提取:对于目标需要提取重要特征用于机器学习模型
PCA:适合线性数据的特征提取
LDA:适合分类任务的特征提取
自编码器:适合非线性数据的特征提取
降噪:目标是去除噪声或冗余信息
PCA:通过保留主成分去除噪声
NMF:适合非负数据的降噪
分类或聚类
对于分类问题:LDA 可以最大化类间距离
对于聚类问题:t-SNE 或 UMAP 适合展示聚类结构
计算效率
PCA、LDA、随机投影:计算速度快,适合大规模数据
t-SNE、UMAP:计算较慢,适合中小规模数据
内存需求
t-SNE:内存需求较高,不适合超大规模数据
UMAP:内存需求较低,适合较大规模数据
主成分分析
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA 的主要思想是指通过正交变换将一组高维的,可能存在相关性的样本变换为一组低维的,线性不相关的样本,转换后的新样本特征也被称为主成分,是能最大程度代表原样本特征的特性
实现思想
通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的 k 个特征所对应的特征向量组成的矩阵,就可以将数据矩阵转换到新的空间当中,实现数据特征的降维
得到协方差矩阵的特征值特征向量有两种方法:特征值分解协方差矩阵,奇异值分解协方差矩阵。所以对应的 PCA 算法有两种实现方式:基于特征值分解矩阵实现PCA算法,基于SVD分解协方差矩阵实现PCA算法
协方差和散度矩阵
对于样本 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n }
x ˉ = 1 n ∑ i n x i \bar{x}=\frac{1}{n}\sum_i^nx_i
x ˉ = n 1 i ∑ n x i
样本的方差为
S 2 = 1 n − 1 ∑ i n ( x i − x ˉ ) 2 S^2=\frac{1}{n-1}\sum_i^n(x_i-\bar{x})^2
S 2 = n − 1 1 i ∑ n ( x i − x ˉ ) 2
则样本 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n } Y : { y 1 , … y n } Y:\{y_1,…y_n\} Y : { y 1 , … y n }
C o v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = 1 n − 1 ∑ i n ( x i − x ˉ ) ( y i − y ˉ ) Cov(X,Y)=E[(X-E(X))(Y-E(Y))]=\frac{1}{n-1}\sum_i^n(x_i-\bar{x})(y_i-\bar{y})
C o v ( X , Y ) = E [ ( X − E ( X ) ) ( Y − E ( Y ) ) ] = n − 1 1 i ∑ n ( x i − x ˉ ) ( y i − y ˉ )
由于方差的计算都是一维的特征之间的计算,协方差的计算都是对于二维数据的,对于协方差,如果协方差为正,那么说明 X X X Y Y Y X X X Y Y Y
C o v ( X , Y , Z ) = [ C o v ( X , X ) C o v ( X , Y ) C o v ( X , Z ) C o v ( Y , X ) C o v ( Y , Y ) C o v ( Y , Z ) C o v ( Z , X ) C o v ( Z , Y ) C o v ( Z , Z ) ] Cov(X,Y,Z)=\begin{bmatrix}Cov(X,X)&Cov(X,Y)&Cov(X,Z)\\Cov(Y,X)&Cov(Y,Y)&Cov(Y,Z)\\Cov(Z,X)&Cov(Z,Y)&Cov(Z,Z)\end{bmatrix}
C o v ( X , Y , Z ) = ⎣ ⎢ ⎡ C o v ( X , X ) C o v ( Y , X ) C o v ( Z , X ) C o v ( X , Y ) C o v ( Y , Y ) C o v ( Z , Y ) C o v ( X , Z ) C o v ( Y , Z ) C o v ( Z , Z ) ⎦ ⎥ ⎤
对于高维的协方差矩阵也是如此,协方差矩阵是一个对称矩阵,且是一个半正定矩阵,主对角线是各个维度上的方差。对于数据集 X X X X ~ X ~ T n − 1 \frac{\tilde{X}\tilde{X}^T}{n-1} n − 1 X ~ X ~ T X ~ \tilde{X} X ~ X X X
对于数据集 X X X X ~ X ~ T \tilde{X}\tilde{X}^T X ~ X ~ T n − 1 n-1 n − 1
特征值分解矩阵
对于一个向量 v ⃗ \vec{v} v A A A
A v ⃗ = λ v ⃗ A\vec{v}=\lambda\vec{v}
A v = λ v
其中 λ \lambda λ v ⃗ \vec{v} v A A A V V V A A A
A = Q Σ Q − 1 A=Q\Sigma Q^{-1}
A = Q Σ Q − 1
其中 Q Q Q A A A Σ \Sigma Σ
SVD 分解矩阵
奇异值分解矩阵适用于任意矩阵的一种分解方法,对于任意矩阵 A A A
A = U Σ V T A=U\Sigma V^T
A = U Σ V T
对于矩阵 A ∈ R m × n A\in R^{m\times n} A ∈ R m × n U ∈ R m × m U\in R^{m\times m} U ∈ R m × m Σ ∈ R m × n \Sigma\in R^{m\times n} Σ ∈ R m × n V ∈ R n × n V\in R^{n\times n} V ∈ R n × n
求解 A A T AA^T A A T U U U
求解 A T A A^TA A T A V V V
将 A A T AA^T A A T A T A A^TA A T A Σ \Sigma Σ
基于特征值分解协方差矩阵实现 PCA
对于数据集 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n } k k k
去平均值,即去中心化,每一位特征值都减去各自的平均值
计算协方差矩阵 X ~ X ~ T n − 1 \frac{\tilde{X}\tilde{X}^T}{n-1} n − 1 X ~ X ~ T X ~ X ~ T n \frac{\tilde{X}\tilde{X}^T}{n} n X ~ X ~ T X ~ X ~ T \tilde{X}\tilde{X}^T X ~ X ~ T
用特征值分解方式来求协方差矩阵的特征值和正则化之后的特征向量
对特征值从大大小排序,选择其中最大的 k k k P P P
将数据转换到 k k k Y = P X Y=PX Y = P X
基于 SVD 分解协方差矩阵实现 PCA
去平均值,即去中心化,每一位特征值都减去各自的平均值
计算协方差矩阵 X ~ X ~ T n − 1 \frac{\tilde{X}\tilde{X}^T}{n-1} n − 1 X ~ X ~ T X ~ X ~ T n \frac{\tilde{X}\tilde{X}^T}{n} n X ~ X ~ T X ~ X ~ T \tilde{X}\tilde{X}^T X ~ X ~ T
用 SVD 方式来求协方差矩阵的特征值和正则化之后的特征向量
对特征值从大大小排序,选择其中最大的 k k k P P P
将数据转换到 k k k Y = P X Y=PX Y = P X
对于步骤 4 中选择特征值和特征向量,这里一般选择左奇异矩阵来计算,左奇异矩阵将样本数据从 n × m n\times m n × m k × m k\times m k × m n × m n\times m n × m n × k n\times k n × k Y = X P T Y=XP^T Y = X P T
PCA 推导角度
最大可分性:样本点在一个线性超平面上的投影尽可能分开,也就是样本矩阵X 投影后的各特征维度的方差最大,这个方差就是协方差矩阵的特征值
最近重构性:样本点到一个线性超平面的投影距离都足够近,由于投影距离越长,损失的信息也会越多
PCA 评估
将投影后新样本的第 k 维称为原样本的第 k 个主成分。定义方差贡献率为新样本在第 k 维的方差(即特征值 λ k \lambda_k λ k
η k = λ k ∑ i d λ i \eta_k=\frac{\lambda_k}{\sum_i^d\lambda_i}
η k = ∑ i d λ i λ k
PCA 的变种
有些时候,会选择在相关系数矩阵上进行 PCA。两个特征变量的相关系数为它们的协方差除以它们标准差的乘积,如下
ρ ( X , Y ) = C o v ( X , Y ) C o v ( X , X ) C o v ( Y , Y ) \rho(X,Y)=\frac{Cov(X,Y)}{\sqrt{Cov(X,X)Cov(Y,Y)}}
ρ ( X , Y ) = C o v ( X , X ) C o v ( Y , Y ) C o v ( X , Y )
相关系数剔除了两个特征变量量纲的影响,只是单纯反应两个特征变量每单位变化时的相似程度
PCA 选择降维后的主成分个数
根据 PCA 过程中得到的特征值矩阵 S ∈ R m × 1 S\in R^{m\times 1} S ∈ R m × 1 ε \varepsilon ε ε = 0.01 \varepsilon=0.01 ε = 0 . 0 1 1 % 1\% 1 % 99 % 99\% 9 9 % k k k
1 − ∑ i k s i ∑ i m s i ≤ ε 1-\frac{\sum_i^ks_i}{\sum_i^ms_i}\leq \varepsilon
1 − ∑ i m s i ∑ i k s i ≤ ε
也可以根据原始点与投影点之间的距离之和来判断,如下
1 m ∑ i m ∥ x i − x i ⋆ ∥ 2 1 m ∑ i m ∥ x i ∥ 2 ≤ ε \frac{\frac{1}{m}\sum_i^m\Vert x_i-x_i^\star\Vert^2}{\frac{1}{m}\sum_i^m\Vert x_i\Vert^2}\leq \varepsilon
m 1 ∑ i m ∥ x i ∥ 2 m 1 ∑ i m ∥ x i − x i ⋆ ∥ 2 ≤ ε
其中 x i x_i x i x i ⋆ x_i^\star x i ⋆
优点
能够有效去除冗余特征,降低数据维度
保留数据中方差最大的方向,尽可能减少信息损失
计算效率高,适合大规模数据
缺点
只能处理线性关系,对非线性数据效果较差
降维后的特征可解释性较差
对异常值敏感
核主成分分析
核主成分分析(Kernel Principal Component Analysis, KPCA) 是主成分分析(PCA)的非线性扩展,通过引入核方法(Kernel Method)将数据映射到高维特征空间,并在该空间中进行线性 PCA,能够捕捉数据中的非线性结构,适用于非线性降维和特征提取任务
步骤
对于给定的数据集 X : { x 1 , . . x n } ∈ R n × d X:\{x_1,..x_n\}\in R^{n\times d} X : { x 1 , . . x n } ∈ R n × d k ( x i , x j ) k(x_i,x_j) k ( x i , x j ) K ∈ R n × n K\in R^{n\times n} K ∈ R n × n
K i j = k ( x i , x j ) K_{ij}=k(x_i,x_j)
K i j = k ( x i , x j )
对核矩阵进行中心化,得到中心化核矩阵 K ~ \tilde{K} K ~
K ~ = K − 1 n K − K 1 n + 1 n K 1 n \tilde{K}=K-1_nK-K1_n+1_nK1_n
K ~ = K − 1 n K − K 1 n + 1 n K 1 n
1 n ∈ R n × n 1_n\in R^{n\times n} 1 n ∈ R n × n 1 n \frac{1}{n} n 1
对中心化核矩阵进行特征值分解
K ~ α = λ α \tilde{K}\alpha=\lambda\alpha
K ~ α = λ α
λ \lambda λ α \alpha α
归一化特征向量,使得 α T α = 1 λ \alpha^T\alpha=\frac{1}{\lambda} α T α = λ 1 α ′ \alpha^\prime α ′
将数据投影到前 k k k Y ∈ R n × k Y\in R^{n\times k} Y ∈ R n × k
Y i j = ∑ k n K ~ i k α k j ′ Y_{ij}=\sum_k^n\tilde{K}_{ik}\alpha^\prime_{kj}
Y i j = k ∑ n K ~ i k α k j ′
优点
KPCA 能够捕捉数据中的非线性关系,适用于非线性降维任务
通过核技巧,KPCA 避免了显式计算高维特征空间中的向量
可以使用不同的核函数适应不同的数据分布
缺点
核矩阵的计算和特征值分解的复杂度为 O ( n 3 ) O(n^3) O ( n 3 )
核矩阵需要存储 n × n n\times n n × n
核函数的选择核参数设置对结果影响较大,需要调参
线性判别分析
线性判别分析 LDA(Linear Discriminant Analysis)是一种监督学习的降维技术,它的数据集的每个样本都是有类别输出的
LDA 的思想是最大化类间均值,最小化类内方差,实际上就是将数据投影到低维度上,并且投影之后同种类别的数据的投影点尽可能近,不同类别数据的投影点的中心点尽可能远
投影
对于两个向量 x ⃗ 1 \vec{x}_1 x 1 x ⃗ 2 \vec{x}_2 x 2
x ⃗ 1 ⋅ x ⃗ 2 = ∣ x ⃗ 1 ∣ ∣ x 2 ⃗ ∣ cos θ \vec{x}_1\cdot\vec{x}_2=\vert\vec{x}_1\vert\vert\vec{x_2}\vert\cos\theta
x 1 ⋅ x 2 = ∣ x 1 ∣ ∣ x 2 ∣ cos θ
当 x ⃗ 2 \vec{x}_2 x 2 x ⃗ 1 \vec{x}_1 x 1 x ⃗ 2 \vec{x}_2 x 2
x ⃗ 1 ⋅ x ⃗ 2 = ∣ x ⃗ 1 ∣ cos θ \vec{x}_1\cdot\vec{x}_2=\vert\vec{x}_1\vert\cos\theta
x 1 ⋅ x 2 = ∣ x 1 ∣ cos θ
瑞利商与广义瑞利商
对于瑞利商,是如下函数
R ( A , x ) = x H A x x H x R(A,x)=\frac{x^HAx}{x^Hx}
R ( A , x ) = x H x x H A x
其中 x x x x H x^H x H A A A n × n n\times n n × n
瑞利商有一个非常重要的性质,那就是它的最大值等于矩阵 A A A A A A
λ m i n ≤ x H A x x H x ≤ λ m a x \lambda_{min}\leq\frac{x^HAx}{x^Hx}\leq\lambda_{max}
λ m i n ≤ x H x x H A x ≤ λ m a x
当向量 x x x x H x = 1 x^Hx=1 x H x = 1
R ( A , x ) = x H A x R(A,x)=x^HAx
R ( A , x ) = x H A x
定义广义瑞利商如下
R ( A , B , x ) = x H A x x H B x R(A,B,x)=\frac{x^HAx}{x^HBx}
R ( A , B , x ) = x H B x x H A x
对其进行标准化就可以转化为瑞利商的格式,令 x = B − 1 2 x ′ x=B^{-\frac{1}{2}}x^\prime x = B − 2 1 x ′
R ( A , B , x ′ ) = x ′ H B − 1 2 A B − 1 2 x ′ x ′ H x ′ R(A,B,x^\prime)=\frac{x^{\prime H}B^{-\frac{1}{2}}AB^{-\frac{1}{2}}x^\prime}{x^{\prime H}x^\prime}
R ( A , B , x ′ ) = x ′ H x ′ x ′ H B − 2 1 A B − 2 1 x ′
就得到了瑞利商形式
类间散度矩阵
对于样本数据集 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n } C C C n 1 , … n k n_1,…n_k n 1 , … n k x i j x_i^j x i j i i i j j j X i : { x i 1 , … x i n i } X_i:\{x_i^1,…x_i^{n_i}\} X i : { x i 1 , … x i n i } i i i
考虑如何使得不同类样例的投影点尽可能远离,采用类间散度矩阵来衡量类间距离,这里采用两个类别的均值向量 μ i \mu_i μ i
( w T μ 1 − w T μ 2 ) 2 = w T ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) T w (w^T\mu_1-w^T\mu_2)^2=w^T(\mu_1-\mu_2)(\mu_1-\mu_2)^Tw
( w T μ 1 − w T μ 2 ) 2 = w T ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) T w
上述公式中 w w w w T S b w w^TS_bw w T S b w
类内散度矩阵
在考虑使得同类样例的投影点尽可能接近,采用类内散度矩阵来衡量类内间距。对于一维数据,要衡量其内部间距一般会使用方差,所以这里也使用方差来衡量
所以这里可以计算出第 i i i Σ i \Sigma_i Σ i
σ i 2 = ∑ x ∈ X i ( w T x − w T μ i ) 2 = w T ( ∑ x ∈ X i ( x − μ i ) ( x − μ i ) T ) w = w T Σ i w \sigma_i^2=\sum_{x\in X_i}(w^Tx-w^T\mu_i)^2\\=w^T(\sum_{x\in X_i}(x-\mu_i)(x-\mu_i)^T)w\\=w^T\Sigma_iw
σ i 2 = x ∈ X i ∑ ( w T x − w T μ i ) 2 = w T ( x ∈ X i ∑ ( x − μ i ) ( x − μ i ) T ) w = w T Σ i w
则两个类别的方差和为
Σ 1 + Σ 2 = w T ( ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T ) w + w T ( ∑ x ∈ X 2 ( x − μ 2 ) ( x − μ 2 ) T ) w = w T ( ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T + ∑ x ∈ X 2 ( x − μ 2 ) ( x − μ 2 ) T ) w = w T ( Σ 1 + Σ 2 ) w \Sigma_1+\Sigma_2=w^T(\sum_{x\in X_1}(x-\mu_1)(x-\mu_1)^T)w+w^T(\sum_{x\in X_2}(x-\mu_2)(x-\mu_2)^T)w\\=w^T(\sum_{x\in X_1}(x-\mu_1)(x-\mu_1)^T+\sum_{x\in X_2}(x-\mu_2)(x-\mu_2)^T)w\\=w^T(\Sigma_1+\Sigma_2)w
Σ 1 + Σ 2 = w T ( x ∈ X 1 ∑ ( x − μ 1 ) ( x − μ 1 ) T ) w + w T ( x ∈ X 2 ∑ ( x − μ 2 ) ( x − μ 2 ) T ) w = w T ( x ∈ X 1 ∑ ( x − μ 1 ) ( x − μ 1 ) T + x ∈ X 2 ∑ ( x − μ 2 ) ( x − μ 2 ) T ) w = w T ( Σ 1 + Σ 2 ) w
上述类内散度写作 w T S w w w^TS_ww w T S w w
定义目标函数
根据LDA的目标,我们需要使得同类样例间的投影点尽可能接近,即类内散度矩阵 w T S w w w^TS_ww w T S w w w T S b w w^TS_bw w T S b w
J = w T S b w w T S w w J=\frac{w^TS_bw}{w^TS_ww}
J = w T S w w w T S b w
可知 J J J w ⋆ w^\star w ⋆ w T S w w = 1 w^TS_ww=1 w T S w w = 1
w ⋆ = arg min w ( − w T S b w ) s . t . w t S w w = 1 w^\star=\underset{w}{\arg\min}(-w^TS_bw)\\s.t.\quad w^tS_ww=1
w ⋆ = w arg min ( − w T S b w ) s . t . w t S w w = 1
求解上述最优问题可以构造 Lagrange 函数
L ( w , λ ) = − w T S b w + λ ( w t S w w − 1 ) \mathcal{L}(w,\lambda)=-w^TS_bw+\lambda(w^tS_ww-1)
L ( w , λ ) = − w T S b w + λ ( w t S w w − 1 )
求解可以得到
∂ L ∂ w = S b w − λ S w w = 0 \frac{\partial\mathcal{L}}{\partial w}=S_bw-\lambda S_ww=0
∂ w ∂ L = S b w − λ S w w = 0
所以最终得到的最优解应该满足
S w − 1 S b w ⋆ = λ w ⋆ λ w ⋆ = S w − 1 ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) T w ⋆ S_w^{-1}S_bw^\star=\lambda w^\star\\\lambda w^\star=S_w^{-1}(\mu_1-\mu_2)(\mu_1-\mu_2)^Tw^\star
S w − 1 S b w ⋆ = λ w ⋆ λ w ⋆ = S w − 1 ( μ 1 − μ 2 ) ( μ 1 − μ 2 ) T w ⋆
所以可以得知 w ⋆ w^\star w ⋆ S w − 1 S b S_w^{-1}S_b S w − 1 S b ( μ 1 − μ 2 ) T w ⋆ (\mu_1-\mu_2)^Tw^\star ( μ 1 − μ 2 ) T w ⋆ λ \lambda λ w ⋆ w^\star w ⋆ w ⋆ w^\star w ⋆ S w − 1 ( μ 1 − μ 2 ) S_w^{-1}(\mu_1-\mu_2) S w − 1 ( μ 1 − μ 2 )
w ⋆ = S w − 1 ( μ 1 − μ 2 ) w^\star=S_w^{-1}(\mu_1-\mu_2)
w ⋆ = S w − 1 ( μ 1 − μ 2 )
最终得到最优化参数 w ⋆ w^\star w ⋆ k k k W W W
最终得到投影数据
Y = X W Y=XW
Y = X W
优点
能够有效提升分类性能
保留类别信息,适合有监督任务
计算效率高,适合中小规模数据
缺点
假设数据服从高斯分布,对非高斯分布数据效果较差
对异常值敏感
最多只能降到 C − 1 C-1 C − 1 C C C
t-分布邻域嵌入
t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)是一种非线性降维方法,主要用于高维数据的可视化。t-SNE 通过保留数据点之间的局部结构,将高维数据映射到低维空间(通常是 2D 或 3D),从而在低维空间中展示数据的聚类结构
基本原理
t-SNE 的核心思想时通过概率分布来描述高维和低维空间中数据点之间的相似性,并最小化这两个分布之间的差异。t-SNE 由 SNE 算法改进而来,而 SNE 算法的思想是如果两个数据在高维空间中是相似的,那么降维到二维空间时它们应该距离很近
KL 散度
KL 散度(Kullback-Leibler Divergence)是用来度量两个概率分布相似度的指标,它作为经典损失函数被广泛地用于聚类分析与参数估计等机器学习任务中
假设对随机变量 ξ \xi ξ P P P Q Q Q ξ \xi ξ P P P Q Q Q
D K L ( P ∥ Q ) = ∑ i P ( i ) ln ( P ( i ) Q ( i ) ) \mathbb{D}_{KL}(P\Vert Q)=\sum_iP(i)\ln(\frac{P(i)}{Q(i)})
D K L ( P ∥ Q ) = i ∑ P ( i ) ln ( Q ( i ) P ( i ) )
如果 ξ \xi ξ P P P Q Q Q
D K L ( P ∥ Q ) = ∫ − ∞ ∞ P ( x ) ln ( P ( x ) Q ( x ) ) d x \mathbb{D}_{KL}(P\Vert Q)=\int_{-\infty}^{\infty}P(x)\ln(\frac{P(x)}{Q(x)})dx
D K L ( P ∥ Q ) = ∫ − ∞ ∞ P ( x ) ln ( Q ( x ) P ( x ) ) d x
具体步骤
计算高维空间中的相似性。对于高维空间中的两个点 x i x_i x i x j x_j x j x i x_i x i σ i \sigma_i σ i p j ∣ i p_{j|i} p j ∣ i x j x_j x j x i x_i x i p j ∣ i p_{j|i} p j ∣ i
p j ∣ i = exp ( − ∥ x i − x j ∥ 2 2 σ i 2 ) ∑ k ≠ i exp ( − ∥ x i − x k ∥ 2 2 σ i 2 ) p_{j|i}=\frac{\exp(-\frac{\Vert x_i-x_j\Vert^2}{2\sigma_i^2})}{\sum_{k\not=i}\exp(-\frac{\Vert x_i-x_k\Vert^2}{2\sigma_i^2})}
p j ∣ i = ∑ k = i exp ( − 2 σ i 2 ∥ x i − x k ∥ 2 ) exp ( − 2 σ i 2 ∥ x i − x j ∥ 2 )
p i j = p j ∣ i + p i ∣ j 2 n p_{ij}=\frac{p_{j|i}+p_{i|j}}{2n}
p i j = 2 n p j ∣ i + p i ∣ j
计算低维空间中的相似性。在低维空间中,使用 t 分布表示数据点之间的相似性
q i j = ( 1 + ∥ y i − y j ∥ 2 ) − 1 ∑ k ≠ l ( 1 + ∥ y k − y l ∥ 2 ) − 1 q_{ij}=\frac{(1+\Vert y_i-y_j\Vert^2)^{-1}}{\sum_{k\not=l}(1+\Vert y_k-y_l\Vert^2)^{-1}}
q i j = ∑ k = l ( 1 + ∥ y k − y l ∥ 2 ) − 1 ( 1 + ∥ y i − y j ∥ 2 ) − 1
最小化 KL 散度:利用梯度下降法最小化高维和低维空间相似性分布之间的 KL 散度
D K L ( P ∥ Q ) = ∑ i ≠ j p i j log p i j q i j \mathbb{D}_{KL}(P\Vert Q)=\sum_{i\not=j}p_{ij}\log\frac{p_{ij}}{q_{ij}}
D K L ( P ∥ Q ) = i = j ∑ p i j log q i j p i j
优点
能够有效保留高维数据的局部结构,适合展示聚类结构
可视化效果优秀,特别适合高维数据的 2D 或 3D 可视化
缺点
计算复杂度高,适合中小规模数据
对超参数(如困惑度)敏感
不保留全局结构,可能导致不同聚类之间的距离失真
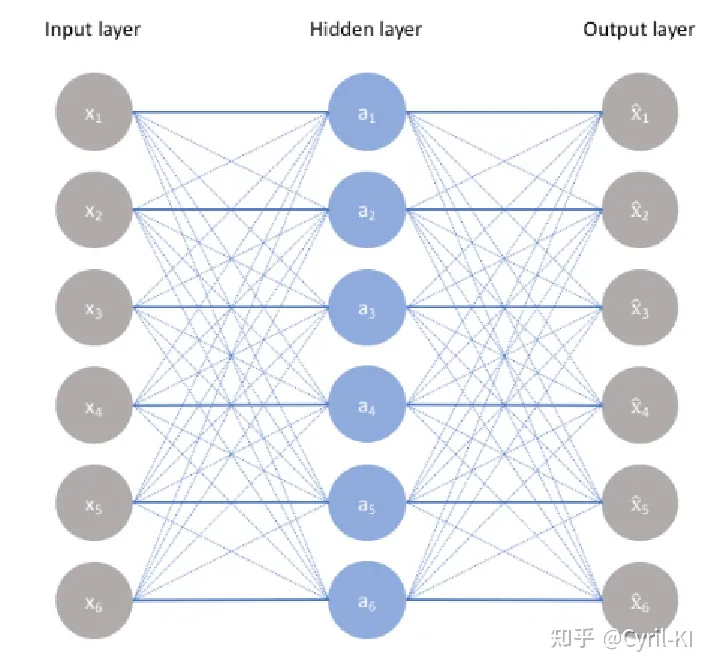
自编码器
自编码器(Autoencoder)是一种无监督学习的神经网络模型,主要用于数据的降维、特征提取和去噪。它的核心思想是通过学习数据的低维表示(编码),然后从低维表示重构原始数据(解码),从而捕捉数据中的重要特征
结构
一个简单的自编码器如上图所示,上图中只有一个隐藏层,自编码器由两部分组成
编码器:将数据映射到低维表示,如图中就是将数据从输入层映射到隐藏层
z = f ( x ) = σ ( W e x + b e ) z=f(x)=\sigma(W_ex+b_e)
z = f ( x ) = σ ( W e x + b e )
其中 W e W_e W e b e b_e b e σ \sigma σ
解码器:将低维表示映射回重构数据,图中数据从隐藏层映射到输出层
x ^ = g ( z ) = σ ( W d x + b d ) \hat{x}=g(z)=\sigma(W_dx+b_d)
x ^ = g ( z ) = σ ( W d x + b d )
其中 W d W_d W d b d b_d b d σ \sigma σ
自编码器类型
普通自编码器:由编码器和解码器组成,用于简单的降维和特征提取任务
稀疏自编码器:在损失函数中加入稀疏性约束,使得编码 z z z
去噪自编码器:在输入数据中加入噪声,训练模型从噪声数据中重构原始数据,用于数据去噪和鲁棒特征提取
变分自编码器:基于概率生成模型,学习数据的潜在分布,用于生成新数据和数据分布建模
卷积自编码器:使用卷积神经网络作为编码器和解码器,用于图像的降维和特征提取
普通自编码器
自编码器的目标是最小化输入数据与输出数据之间的差异,通常用均方误差作为损失函数
L ( x , x ^ ) = ∥ x − x ^ ∥ 2 \mathcal{L}(x,\hat{x})=\Vert x-\hat{x}\Vert^2
L ( x , x ^ ) = ∥ x − x ^ ∥ 2
通过不断学习更新参数
稀疏自编码器
稀疏性约束有两种方式实现
L1 正则化
L ( x , x ^ ) = ∥ x − x ^ ∥ 2 + λ ∥ z ∥ 1 \mathcal{L}(x,\hat{x})=\Vert x-\hat{x}\Vert^2+\lambda\Vert z\Vert_1
L ( x , x ^ ) = ∥ x − x ^ ∥ 2 + λ ∥ z ∥ 1
KL 散度约束
K L ( ρ ∥ ρ ^ ) = ρ log ρ ρ ^ + ( 1 − ρ ) log 1 − ρ 1 − ρ ^ L ( x , x ^ ) = ∥ x − x ^ ∥ 2 + λ ∑ j K L ( ρ ∥ ρ ^ j ) KL(\rho\Vert\hat{\rho})=\rho\log\frac{\rho}{\hat{\rho}}+(1-\rho)\log\frac{1-\rho}{1-\hat{\rho}}\\\mathcal{L}(x,\hat{x})=\Vert x-\hat{x}\Vert^2+\lambda\sum_jKL(\rho\Vert\hat{\rho}_j)
K L ( ρ ∥ ρ ^ ) = ρ log ρ ^ ρ + ( 1 − ρ ) log 1 − ρ ^ 1 − ρ L ( x , x ^ ) = ∥ x − x ^ ∥ 2 + λ j ∑ K L ( ρ ∥ ρ ^ j )
假设编码的激活概率为 ρ ^ \hat{\rho} ρ ^ ρ \rho ρ ρ ^ j \hat{\rho}_j ρ ^ j j j j
去噪自编码器
去噪自编码器需要对输入数据加入噪声,用得到的噪声数据 x ~ \tilde{x} x ~ x ^ \hat{x} x ^ x x x
加入噪声的方式有如下几种
加性高斯噪声: x ~ = x + ε ε ∼ N ( 0 , σ 2 ) \tilde{x}=x+\varepsilon\quad\varepsilon\sim\mathcal{N}(0,\sigma^2) x ~ = x + ε ε ∼ N ( 0 , σ 2 )
掩码噪声:随机将输入数据的一部分元素置为零
椒盐噪声:随机将输入数据的一部分元素设置为最大值或最小值
变分自编码器
核心思想如下
输入数据映射到映射到潜在分布的参数,得到潜在分布的均值和方差
从潜在分布中采样得到潜在变量 z z z
将潜在变量映射回重构数据 x ^ \hat{x} x ^
通过最大化数据的对数似然和最小化潜在分布与先验分布之间的KL散度来训练模型
假设潜在变量 z z z z ∼ ( μ , σ ) z\sim\mathcal(\mu,\sigma) z ∼ ( μ , σ ) μ , σ \mu,\sigma μ , σ z = μ + σ ε z=\mu+\sigma\varepsilon z = μ + σ ε ε ∼ N ( 0 , I ) \varepsilon\sim\mathcal{N}(0,I) ε ∼ N ( 0 , I )
变分自编码器的损失函数包括两部分
重构误差
KL 散度:衡量潜在分布 q ( z ∣ x ) q(z|x) q ( z ∣ x ) p ( z ) p(z) p ( z )
损失函数公式如下
K L ( q ( z ∣ x ) ∥ p ( z ) ) = 1 2 ∑ i ( σ i 2 + μ i 2 − 1 − log ( σ i 2 ) ) L ( x , x ^ ) = ∥ x − x ^ ∥ 2 + K L ( q ( z ∣ x ) ∥ p ( z ) ) KL(q(z|x)\Vert p(z))=\frac{1}{2}\sum_i(\sigma_i^2+\mu_i^2-1-\log(\sigma_i^2))\\\mathcal{L}(x,\hat{x})=\Vert x-\hat{x}\Vert^2+KL(q(z|x)\Vert p(z))
K L ( q ( z ∣ x ) ∥ p ( z ) ) = 2 1 i ∑ ( σ i 2 + μ i 2 − 1 − log ( σ i 2 ) ) L ( x , x ^ ) = ∥ x − x ^ ∥ 2 + K L ( q ( z ∣ x ) ∥ p ( z ) )
卷积自编码器
是一种基于卷积神经网络(CNN)的自编码器,专门用于处理图像数据
编码器:使用卷积层和池化层逐步提取图像的局部特征,并将图像压缩为低维表示
解码器:使用反卷积层(或转置卷积层)和上采样层逐步将低维表示重构为原始图像
独立成分分析
独立成分分析(Independent Component Analysis,ICA)能够有效地从混合信号中分离出相互独立的成分。ICA 假设观测信号是多个独立源信号的线性组合,通过寻找一个线性变换,使得变换后的信号尽可能独立
核心思想
ICA 的目标是从混合信号中恢复出独立的信号源。假设观测信号 x x x s s s
x = A s x=As
x = A s
其中 A A A
ICA 通过寻找一个解混矩阵 W W W y y y
y = W x y=Wx
y = W x
其中 y y y
峭度
是统计学中用于描述概率分布形状的一个重要指标,特别是用于衡量分布的尾部厚度和尖峰程度
K u r t o s i s ( X ) = E [ ( X − μ ) 4 ] σ 4 Kurtosis(X)=\frac{E[(X-\mu)^4]}{\sigma^4}
K u r t o s i s ( X ) = σ 4 E [ ( X − μ ) 4 ]
X X X μ \mu μ X X X σ \sigma σ X X X E E E
性质
基准值:对于正态分布(高斯分布),峭度为 3
超额峭度:为了便于比较一般会使用超额峭度 E x c e s s K u r t o s i s ( X ) = K u r t o s i s ( X ) − 3 Excess Kurtosis(X)=Kurtosis(X)-3 E x c e s s K u r t o s i s ( X ) = K u r t o s i s ( X ) − 3
分布形状
正峭度:分布比正态分布更尖峰
负峭度:分布比正正态分布更平坦,尾部更薄
峭度值解释
正峭度表示数据分布具有更多的极端值或异常值
负峭度表示数据分布较为平坦,极端值较少
负熵
基于信息熵的概念,用于衡量信号与高斯分布的偏离程度
J ( y ) = H ( y G a u s s ) − H ( y ) J(y)=H(y_{Gauss})-H(y)
J ( y ) = H ( y G a u s s ) − H ( y )
H ( y ) H(y) H ( y ) y y y H ( y G a u s s ) H(y_{Gauss}) H ( y G a u s s ) y y y 熵是衡量随机变量不确定性的指标,定义为 H ( y ) = − ∫ p ( y ) log p ( y ) d y H(y)=-\int p(y)\log p(y)dy H ( y ) = − ∫ p ( y ) log p ( y ) d y
对于高斯分布,熵的计算公式为 H ( y G a u s s ) = 1 2 log ( 2 π e σ 2 ) H(y_{Gauss})=\frac{1}{2}\log(2\pi e\sigma^2) H ( y G a u s s ) = 2 1 log ( 2 π e σ 2 ) σ 2 \sigma^2 σ 2
性质
非负性:负熵 J ( y ) ≥ 0 J(y)\geq0 J ( y ) ≥ 0 y y y J ( y ) = 0 J(y)=0 J ( y ) = 0
非高斯性度量:负熵越大,信号的非高斯性越强
鲁棒性:负熵对信号的幅度不敏感
步骤
ICA 假设源信号是统计独立的,独立性意味着联合概率分布可以分解为边缘概率分布的乘积 p ( s 1 , … s n ) = ∏ i = 1 n p ( s i ) p(s_1,…s_n)=\prod_{i=1}^np(s_i) p ( s 1 , … s n ) = ∏ i = 1 n p ( s i )
ICA 假设源信号是非高斯的,因为高斯信号的独立性无法通过线性变换恢复
优化目标:ICA 通过最大化非高斯性来估计解混矩阵 W W W
峭度(Kurtosis):是衡量信号分布尖峰程度的一个指标
K u r t o s i s ( y ) = E [ y 4 ] − 3 ( E [ y 2 ] ) 2 Kurtosis(y)=E[y^4]-3(E[y^2])^2
K u r t o s i s ( y ) = E [ y 4 ] − 3 ( E [ y 2 ] ) 2
负熵(Negentropy):用于衡量信号与高斯分布的偏离程度
J ( y ) = H ( y G a u s s ) − H ( y ) J(y)=H(y_{Gauss})-H(y)
J ( y ) = H ( y G a u s s ) − H ( y )
求解,常用的算法如下
FastICA:基于负熵的快速算法
收敛速度较快,适合处理大规模数据
对初始值不敏感,具有较好的鲁棒性
支持多种非线性函数,适应不同的数据特性
Infomax:基于互信息最大化的算法
基于信息理论,具有明确的数学解释
适用于多种信号分离任务
对初始值不敏感,具有较好的鲁棒性
FastICA
是一种基于负熵最大化的快速独立成分分析(ICA)算法,用于从混合信号中分离出独立的源信号,通过最大化非高斯性(通常使用负熵作为度量)来估计独立的源信号
中心化:将观测信号的均值调整为零
X ′ = X − m e a n ( X ) X^\prime=X-mean(X)
X ′ = X − m e a n ( X )
白化数据:对观测信号进行白化处理,得到白化信号
Σ X = E [ X ′ ( X ′ ) T ] Σ X = V D V T Z = D − 1 2 V T X ′ \Sigma_X=E[X^\prime(X^\prime)^T]\\\Sigma_X=VDV^T\\Z=D^{-\frac{1}{2}}V^TX^\prime
Σ X = E [ X ′ ( X ′ ) T ] Σ X = V D V T Z = D − 2 1 V T X ′
D D D V V V Z Z Z
负熵最大化,通过最大化负熵来估计解混矩阵 W W W
J ( y ) = ∑ i m k i ( E [ G i ( y ) ] − E [ G i ( v ) ] ) 2 J(y)=\sum_i^mk_i(E[G_i(y)]-E[G_i(v)])^2
J ( y ) = i ∑ m k i ( E [ G i ( y ) ] − E [ G i ( v ) ] ) 2
G i G_i G i v v v k i k_i k i
迭代更新:使用固定点算法迭代更新解混向量
w + = E [ z g ( w T z ) ] − E [ g ′ ( w T z ) ] w w^+=E[zg(w^Tz)]-E[g^\prime(w^Tz)]w
w + = E [ z g ( w T z ) ] − E [ g ′ ( w T z ) ] w
g g g 归一化处理 w = w + ∥ w + ∥ w=\frac{w^+}{\Vert w^+\Vert} w = ∥ w + ∥ w +
收敛:重复迭代直至收敛
Infomax
是一种基于信息理论的独立成分分析(ICA)算法,用于从混合信号中分离出独立的源信号。Infomax 的核心思想是通过最大化输出信号的互信息,使得变换后的信号尽可能独立
Infomax 的目标是找到一个线性变换使得变换后的信号的互信息最大化。互信息是衡量多个随机变量之间依赖性的指标,最大化互信息等价于最小化输出信号之间的依赖性
对于输出信号 y y y
I ( y ) = ∑ i n H ( y i ) − H ( y ) I(y)=\sum_i^nH(y_i)-H(y)
I ( y ) = i ∑ n H ( y i ) − H ( y )
H ( y i ) H(y_i) H ( y i ) y i y_i y i H ( y ) H(y) H ( y )
通过最大化 I ( y ) I(y) I ( y )
模型假设:假设源信号 s s s
优化目标函数,最大化输出信号的互信息
I ( y ) = ∑ i n H ( y i ) − H ( y ) I(y)=\sum_i^nH(y_i)-H(y)
I ( y ) = i ∑ n H ( y i ) − H ( y )
优化方法选择梯度上升法
∂ I ( y ) ∂ W = ∂ ∂ W ( ∑ i n H ( y i ) − H ( y ) ) \frac{\partial I(y)}{\partial W}=\frac{\partial}{\partial W}(\sum_i^nH(y_i)-H(y))
∂ W ∂ I ( y ) = ∂ W ∂ ( i ∑ n H ( y i ) − H ( y ) )
非线性变换:为了简化计算,通常对输出信号 y y y g g g
y i = g ( w i T x ) y_i=g(w_i^Tx)
y i = g ( w i T x )
优点
能够分离出独立的源信号。
适用于盲源分离问题,如语音信号分离和图像去噪等
缺点
对噪声敏感
假设源信号是非高斯的,可能不适用于高斯信号
无法确定源信号的顺序和幅度
多维缩放
多维缩放(Multidimensional Scaling,MDS)是一种降维技术,用于将高维数据映射到低维空间(通常是 2D 或 3D),同时尽可能保留数据点之间的距离关系。MDS的核心思想是通过低维空间中的点之间的距离来近似原始高维空间中的距离
基本原理
MDS 的目标是找到一个低维表示,使得低维空间中的点之间的距离(如欧氏距离)尽可能接近原始高维空间中的距离。
一般步骤就是给定高维数据,计算数据点之间的成对距离,通过优化算法(如梯度下降)找到一个低维表示,使得低维空间中的距离矩阵与原始距离矩阵尽可能接近
类型
经典 MDS
优点
计算效率高,适合中小规模数据
能够保留全局距离关系
直观且易于理解
缺点
仅适用于欧氏距离
对于非线性数据结构,效果可能不如 t-SNE 或 UMAP
度量 MDS
优点
适用于任意距离度量,灵活性高
能够保留全局距离关系
适合处理非线性数据
缺点
计算复杂度较高,尤其是对于大规模数据
对于高维数据,可能需要较长的训练时间
非度量 MDS
优点
适用于非数值型数据或基于排序的距离
能够处理非线性关系
适合处理心理学实验中的相似性评分等数据
缺点
计算复杂度较高,尤其是对于大规模数据
对于高维数据,可能需要较长的训练时间
步骤
对于高维数据点 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n }
降维优化
对于经典 MDS,通过特征值分解求解低维表示
对于度量 MDS,通过优化算法最小化应力函数
输出低维表示
得到低维空间中的点 Y : { y 1 , … y n } Y:\{y_1,…y_n\} Y : { y 1 , … y n }
经典 MDS
经典 MDS 专门用于处理欧氏距离矩阵,通过特征值分解(Eigenvalue Decomposition)直接求解低维表示,是一种高效且直观的降维方法
对于高维数据点 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n } D = { d i j = ∥ x i − x j ∥ } D=\{d_{ij}=\Vert x_i-x_j\Vert\} D = { d i j = ∥ x i − x j ∥ }
中心化距离矩阵,构造中心化矩阵 B B B
B = − 1 2 H D 2 H B=-\frac{1}{2}HD^2H
B = − 2 1 H D 2 H
D 2 D^2 D 2 H H H H = I − 1 n 1 ⃗ 1 ⃗ T H=I-\frac{1}{n}\vec{1}\vec{1}^T H = I − n 1 1 1 T 1 ⃗ \vec{1} 1
特征值分解,对 B B B
B = Q Λ Q T B=Q\Lambda Q^T
B = Q Λ Q T
Q Q Q Λ \Lambda Λ
选择主成分:选择前 k k k
Y = Q k Λ k 1 2 Y=Q_k\Lambda_k^{\frac{1}{2}}
Y = Q k Λ k 2 1
Q k Q_k Q k k k k Λ k \Lambda_k Λ k k k k
度量 MDS
度量 MDS 的目标是找到一个低维表示,使得低维空间中的点之间的距离尽可能接近原始高维空间中的距离。度量 MDS 不局限于欧氏距离,可以处理任意距离度量
对于高维数据点 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n } D = { d i j } D=\{d_{ij}\} D = { d i j }
度量MDS通过优化算法(如梯度下降)最小化下述应力函数
S t r e s s = ∑ i , j ( d i j − d ^ i j ) 2 ∑ i , j d i j 2 Stress=\sqrt{\frac{\sum_{i,j}(d_{ij}-\hat{d}_{ij})^2}{\sum_{i,j}d_{ij}^2}}
S t r e s s = ∑ i , j d i j 2 ∑ i , j ( d i j − d ^ i j ) 2
d i j d_{ij} d i j d ^ i j \hat{d}_{ij} d ^ i j
使用梯度下降或其他优化算法,逐步调整低维表示 Y : { y 1 , … y n } Y:\{y_1,…y_n\} Y : { y 1 , … y n }
非度量 MDS
非度量MDS的目标是找到一个低维表示,使得低维空间中的点之间的距离的相对顺序尽可能接近原始高维空间中的距离的相对顺序,不关注距离的绝对数值,而是关注距离的排名或顺序
对于高维数据点 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n } D = { d i j } D=\{d_{ij}\} D = { d i j }
度量MDS通过优化算法(如梯度下降)最小化下述应力函数
S t r e s s = ∑ i , j ( f ( d i j ) − d ^ i j ) 2 ∑ i , j d i j 2 Stress=\sqrt{\frac{\sum_{i,j}(f(d_{ij})-\hat{d}_{ij})^2}{\sum_{i,j}d_{ij}^2}}
S t r e s s = ∑ i , j d i j 2 ∑ i , j ( f ( d i j ) − d ^ i j ) 2
d i j d_{ij} d i j d ^ i j \hat{d}_{ij} d ^ i j f f f
使用梯度下降或其他优化算法,逐步调整低维表示 Y : { y 1 , … y n } Y:\{y_1,…y_n\} Y : { y 1 , … y n }
优点
直观且易于理解,适合可视化
能够保留数据点之间的全局距离关系
适用于多种距离度量(尤其是度量 MDS 和非度量 MDS)
缺点
计算复杂度较高,尤其是对于大规模数据
对于非线性数据结构,效果可能不如 t-SNE 或 UMAP
经典MDS仅适用于欧氏距离
UMAP
UMAP (Uniform Manifold Approximation and Projection) 是一种非线性降维和可视化算法,特别适用于可视化和聚类高维数据。UMAP 基于基于图论和流形学习理论,旨在保留数据局部和全局结构的同时,将高维数据映射到低维空间(通常是 2D 或 3D)
特点
UMAP 假设数据分布在一个低维流形上,通过近似流形的拓扑结构来实现降维,能够捕捉数据的局部和全局结构
UMAP 使用随机近邻图(k-nearest neighbors graph)和概率模型来优化降维过程,相比 t-SNE,计算效率更高,尤其是在处理大规模数据集时
与 t-SNE 相比,UMAP 在保留数据全局结构方面表现更好,同时也能捕捉局部结构
参数
n_neighbors 控制局部结构的粒度,较小的值更关注局部结构,较大的值更关注全局结构min_dist 控制低维空间中点的分布,较小的值会使点更聚集,较大的值会使点更分散n_components 指定降维之后的维度
原理
构建高维图:在高维数据中构建一个图结构,以捕捉数据的局部和全局关系
计算 k-nearest neighbors ,对于每个点找到其最近的 n_neighbors 个邻居
对于每个点及其邻居,计算它们之间的概率相似度
p i ∣ j = exp ( − d ( x i . x j ) − ρ i σ i ) p_{i|j}=\exp(-\frac{d(x_i.x_j)-\rho_i}{\sigma_i})
p i ∣ j = exp ( − σ i d ( x i . x j ) − ρ i )
d ( x i , x j ) d(x_i,x_j) d ( x i , x j ) ρ i \rho_i ρ i i i i σ i \sigma_i σ i i i i log 2 ( n ) \log_2(n) log 2 ( n ) n n n n_neighbors
将概率矩阵对称化,得到高维空间的联合概率分布
p i j = p i ∣ j + p j ∣ i − p i ∣ j p j ∣ i p_{ij}=p_{i|j}+p_{j|i}-p_{i|j}p_{j|i}
p i j = p i ∣ j + p j ∣ i − p i ∣ j p j ∣ i
在低维空间(通常是 2D 或 3D)中随机初始化点的位置
构建低维图:在低维空间中,UMAP 使用类似的图结构来表示点之间的关系
计算低维空间中的概率相似度
q i j = ( 1 + a ⋅ d ( y i , y j ) 2 b ) − 1 q_{ij}=(1+a\cdot d(y_i,y_j)^{2b})^{-1}
q i j = ( 1 + a ⋅ d ( y i , y j ) 2 b ) − 1
d ( y i , y j ) d(y_i,y_j) d ( y i , y j ) a a a b b b
低维优化,通过优化目标函数,使低维空间中的图结构尽可能接近高维空间中的图结构
目标函数,UMAP 的目标是最小化高维和低维概率分布之间的交叉熵。这个目标函数鼓励高维空间中相似的点在低维空间中靠近,而不相似的点在低维空间中远离
L = ∑ i , j p i j log p i j q i j + ( 1 − p i j ) log 1 − p i j 1 − q i j \mathcal{L}=\sum_{i,j}p_{ij}\log\frac{p_{ij}}{q_{ij}}+(1-p_{ij})\log\frac{1-p_{ij}}{1-q_{ij}}
L = i , j ∑ p i j log q i j p i j + ( 1 − p i j ) log 1 − q i j 1 − p i j
使用梯度下降法更新低维空间中点的位置,以最小化目标函数,其中 α \alpha α
y i = y i − α ∂ L ∂ y i y_i=y_i-\alpha\frac{\partial\mathcal{L}}{\partial y_i}
y i = y i − α ∂ y i ∂ L
输出低维嵌入:经过优化后,UMAP 输出低维空间中的点坐标,这些坐标可以用于可视化或进一步分析
优点
速度快:比 t-SNE 更快,适合大规模数据集
全局结构保留:在降维时能更好地保留数据的全局结构
灵活性:参数可调,适应不同场景
缺点
参数选择对结果影响较大,需要根据具体数据调整
对于某些复杂的高维数据,可能无法完全保留所有结构
Truncated SVD
Truncated SVD(截断奇异值分解,Truncated Singular Value Decomposition)是奇异值分解(SVD)的一种变体,主要用于降维和特征提取。它通过保留最重要的奇异值和对应的奇异向量,将高维数据映射到低维空间,同时尽可能保留数据的主要信息
奇异值分解
奇异值分解是将一个矩阵 A A A
A = U Σ V T A=U\Sigma V^T
A = U Σ V T
A ∈ R m × n A\in R^{m\times n} A ∈ R m × n U ∈ R m × m U\in R^{m\times m} U ∈ R m × m Σ ∈ R m × n \Sigma\in R^{m\times n} Σ ∈ R m × n V ∈ R n × n V\in R^{n\times n} V ∈ R n × n
核心思想
Truncated SVD 通过只保留前 k k k A A A A k A_k A k
A k = U k Σ k V k T A_k=U_k\Sigma_kV_k^T
A k = U k Σ k V k T
U k ∈ R m × k U_k\in R^{m\times k} U k ∈ R m × k U U U k k k Σ k ∈ R k × k \Sigma_k\in R^{k\times k} Σ k ∈ R k × k Σ \Sigma Σ k k k V k ∈ R n × k V_k\in R^{n\times k} V k ∈ R n × k V V V k k k
通过这种方式,将原始矩阵降维为 A k A_k A k
步骤
计算 SVD,对矩阵 A A A U , Σ , V U,\Sigma,V U , Σ , V
选择截断值,根据需求选择保留奇异值数量 k k k
保留前 k k k U k , Σ k , V k U_k,\Sigma_k,V_k U k , Σ k , V k
重构低秩矩阵 A k = U k Σ k V k T A_k=U_k\Sigma_kV_k^T A k = U k Σ k V k T
优点
将高维数据映射到低维空间,减少计算复杂度
通过丢弃较小的奇异值,去除数据中的噪声
提取数据的主要特征,适用于分类、聚类等任务
对于稀疏矩阵,Truncated SVD 可以高效处理
缺点
对数据缩放敏感
计算复杂度较高
对噪声敏感
需要手动选择截断值 k k k
对稀疏数据的处理效率有限
非负矩阵分解
非负矩阵分解(Non-negative Matrix Factorization, NMF) 是一种用于降维和特征提取的矩阵分解方法。与 Truncated SVD 和 PCA 不同,NMF 要求分解后的矩阵中的所有元素均为非负数
矩阵分解
对于一个非负矩阵 A ∈ R m × n A\in R^{m\times n} A ∈ R m × n W ∈ R m × k W\in R^{m\times k} W ∈ R m × k H ∈ R k × n H\in R^{k\times n} H ∈ R k × n
A ≈ W ⋅ H A\approx W\cdot H
A ≈ W ⋅ H
W W W H H H k k k
步骤
确定降维后的维度
根据输入数据 A ∈ R m × n A\in R^{m\times n} A ∈ R m × n W ∈ R m × k W\in R^{m\times k} W ∈ R m × k H ∈ R k × n H\in R^{k\times n} H ∈ R k × n
随机初始化:随机生成两个矩阵
NNDSVD(Non-negative Double Singular Value Decomposition):基于 SVD 的初始化方法,能够加速收敛
NMF 通过迭代优化算法来最小化原始矩阵 A A A W ⋅ H W\cdot H W ⋅ H
基于欧式距离的更新规则
W i j k + 1 = W i j k ( A ( H k ) T ) i j ( W k H k ( H k ) T ) i j H i j k + 1 = H i j k ( ( W k ) T A ) i j ( ( W k ) T W k H k ) i j W_{ij}^{k+1}=W_{ij}^k\frac{(A(H^k)^T)_{ij}}{(W^kH^k(H^k)^T)_{ij}}\\H_{ij}^{k+1}=H^k_{ij}\frac{((W^k)^TA)_{ij}}{((W^k)^TW^kH^k)_{ij}}
W i j k + 1 = W i j k ( W k H k ( H k ) T ) i j ( A ( H k ) T ) i j H i j k + 1 = H i j k ( ( W k ) T W k H k ) i j ( ( W k ) T A ) i j
基于 KL 散度的更新规则
W i j k + 1 = W i j k ∑ m H j m k A i m / ( W k H k ) i m ∑ m H j m k H i j k + 1 = H i j k ∑ m W j m k A i m / ( W k H k ) i m ∑ m W j m k W^{k+1}_{ij}=W^k_{ij}\frac{\sum_mH_{jm}^kA_{im}/(W^kH^k)_{im}}{\sum_mH^k_{jm}}\\H^{k+1}_{ij}=H^k_{ij}\frac{\sum_mW_{jm}^kA_{im}/(W^kH^k)_{im}}{\sum_mW^k_{jm}}
W i j k + 1 = W i j k ∑ m H j m k ∑ m H j m k A i m / ( W k H k ) i m H i j k + 1 = H i j k ∑ m W j m k ∑ m W j m k A i m / ( W k H k ) i m
梯度下降法:通过梯度下降法更新两个矩阵
W k + 1 = W k − α W ⋅ ∇ W ∥ A − W k H k ∥ F 2 H k + 1 = H k − α H ⋅ ∇ H ∥ A − W k H k ∥ F 2 W^{k+1}=W^k-\alpha_W\cdot\nabla_W\Vert A-W^kH^k\Vert^2_F\\H^{k+1}=H^k-\alpha_H\cdot\nabla_H\Vert A-W^kH^k\Vert^2_F
W k + 1 = W k − α W ⋅ ∇ W ∥ A − W k H k ∥ F 2 H k + 1 = H k − α H ⋅ ∇ H ∥ A − W k H k ∥ F 2
其中 α w , α H \alpha_w,\alpha_H α w , α H
收敛判断:在每次迭代后,检查目标函数(如欧氏距离或 KL 散度)是否收敛。常用的收敛条件如下
输出结果,算法收敛之后,输出基矩阵和系数矩阵
基矩阵 W W W
系数矩阵 H H H
NNDSVD
NNDSVD(Non-negative Double Singular Value Decomposition) 是一种用于非负矩阵分解(NMF)的初始化方法,通过奇异值分解(SVD)为 NMF 提供一个更好的初始解,从而加速收敛并提高分解结果的质量
对矩阵 A A A
A = U Σ V T A=U\Sigma V^T
A = U Σ V T
A ∈ R m × n A\in R^{m\times n} A ∈ R m × n U ∈ R m × m U\in R^{m\times m} U ∈ R m × m Σ ∈ R m × n \Sigma\in R^{m\times n} Σ ∈ R m × n V ∈ R n × n V\in R^{n\times n} V ∈ R n × n
选择前 k k k
U k ∈ R m × k U_k\in R^{m\times k} U k ∈ R m × k U U U k k k Σ k ∈ R k × k \Sigma_k\in R^{k\times k} Σ k ∈ R k × k Σ \Sigma Σ k k k V k ∈ R n × k V_k\in R^{n\times k} V k ∈ R n × k V V V k k k
构造非负初始化矩阵 W W W H H H
基矩阵 W = U k Σ k W=U_k\sqrt{\Sigma_k} W = U k Σ k
系数矩阵 H = Σ k V k T H=\sqrt{\Sigma_k}V_k^T H = Σ k V k T
计算完成之后,将两个矩阵中的负值设置为 0,保证非负性
调整初始值:进一步提高初始化的质量
将两个矩阵中的零值替换为一个较小的整数
对两个矩阵进行归一化,使其满足某些约束条件
优点
非负性:分解结果均为非负数
由于非负约束,NMF 的结果通常更容易解释
NMF 能够很好地处理稀疏矩阵
NMF 可以提取数据的局部特征,适用于图像分解、主题建模等任务
缺点
NMF 的优化目标是非凸的,可能导致局部最优解
分解结构依赖于 W W W H H H
对于大规模数据,NMF 的计算成本较高
需要手动选择降维后的维度 k k k
NMF 要求输入矩阵为非负数,对于包含负值的数据需要预处理
随机投影
随机投影(Random Projection) 是一种用于降维的快速且高效的技术,特别适用于高维数据的降维和近似计算。核心思想是通过随机矩阵将高维数据投影到低维空间,同时保留数据的主要结构
Johnson-Lindenstrauss 引理
给定一组 n n n k = O ( ϵ 2 log n ) k=O(\epsilon^2\log n) k = O ( ϵ 2 log n ) 1 ± ϵ 1\plusmn\epsilon 1 ± ϵ
步骤
输入高维数据矩阵 X ∈ R n × d X\in R^{n\times d} X ∈ R n × d k k k
构造随机矩阵 R ∈ R d × k R\in R^{d\times k} R ∈ R d × k
高斯随机矩阵:矩阵所有元素服从标准正态分布 N ( 0 , 1 ) \mathcal{N}(0,1) N ( 0 , 1 )
稀疏随机矩阵:矩阵元素以概率 p 2 \frac{p}{2} 2 p ± s \plusmn s ± s 1 − p 1-p 1 − p s s s 3 \sqrt{3} 3
Achlioptas 随机矩阵:矩阵元素以概率 1 6 \frac{1}{6} 6 1 ± 3 \plusmn\sqrt{3} ± 3 2 3 \frac{2}{3} 3 2
Li 随机矩阵:矩阵元素以 1 2 d \frac{1}{2\sqrt{d}} 2 d 1 ± 1 \plusmn1 ± 1 1 − 1 d 1-\frac{1}{\sqrt{d}} 1 − d 1
计算并输出低维投影 Y = X R Y=XR Y = X R
优点
随机投影的计算复杂度为 O ( n d k ) O(ndk) O ( n d k )
由于计算效率高,随机投影特别适合处理大规模高维数据
随机投影能够近似保持高维数据中的距离和相似性
随机投影不需要对数据进行训练,直接生成随机矩阵即可
缺点
随机投影是一种近似方法,可能会引入一定的误差
由于随机矩阵的生成具有随机性,每次投影的结果可能不同
随机投影是一种线性降维方法,无法捕捉数据中的非线性结构
关联规则学习
关联规则学习(Association Rule Learning) 是一种从大规模数据集中发现变量之间有趣关系的数据挖掘技术,主要用于发现数据中的频繁模式、关联规则和相关性
一些基本概念
项集:一个项集是数据集中一个或多个项的集合
支持度:项集的支持度是指数据集中包含该项集的事务的比例
S u p p o r t ( { A , B } ) = 包含 A 和 B 的事务数 总事务数 Support(\{A,B\})=\frac{\text{包含}A\text{和}B\text{的事务数}}{\text{总事务数}}
S u p p o r t ( { A , B } ) = 总事务数 包含 A 和 B 的事务数
置信度:置信度是指包含一个项集的事务中同时包含另一个项集的比例,表示这条规则的可信度
C o n f i d e n c e ( A → B ) = S u p p o r t ( { A , B } ) S u p p o r t ( { A } ) Confidence(A\rightarrow B)=\frac{Support(\{A,B\})}{Support(\{A\})}
C o n f i d e n c e ( A → B ) = S u p p o r t ( { A } ) S u p p o r t ( { A , B } )
提升度:用于衡量规则的相关性
L i f t ( A → B ) = S u p p o r t ( { A , B } ) S u p p o r t ( { A } ) ⋅ S u p p o r t ( { B } ) Lift(A\rightarrow B)=\frac{Support(\{A,B\})}{Support(\{A\})\cdot Support(\{B\})}
L i f t ( A → B ) = S u p p o r t ( { A } ) ⋅ S u p p o r t ( { B } ) S u p p o r t ( { A , B } )
如果提升度大于 1,说明 A A A B B B
如果提升度等于 1,说明 A A A B B B
如果提升度小于 1,说明 A A A B B B
频繁项集:对于项集 A A A A A A
最小支持度:衡量支持度的一个阈值,表示项目集在统计意义上的最低重要性
最小置信度:衡量置信度的一个阈值,表示关联规则的最低可靠性
强规则:同时满足最小支持度阈值和最小置信度阈值的规则
步骤
生成频繁项集:使用算法找出支持度大于最小支持度阈值的频繁项集
Apriori 算法
FP-Growth 算法
Eclat 算法
生成关联规则:从频繁项集中生成置信度大于最小置信度阈值的关联规则,从频繁项集中生成置信度大于最小置信度的规则,计算置信度还是要使用原来的事务来计算
评估规则:使用支持度、置信度、提升度等指标评估规则的有效性和相关性
Apriori 算法
Apriori 算法是生成频繁项集的经典方法,基于逐层搜索和剪枝的思想
核心原理
先验性质:如果一个项集是频繁的,那么它的所有子集也一定是频繁的
通过逐层生成候选项集并剪枝,逐步找到所有频繁项集
算法步骤
生成候选项集
从单个项(1-项集)开始,生成所有可能的候选项集
对于数据集中的项 { A , B , C } \{A,B,C\} { A , B , C } { A } , { B } , { C } \{A\},\{B\},\{C\} { A } , { B } , { C }
扫描数据集,计算每个候选项集的支持度
S u p p o r t ( { X } ) = 包含 X 的事务数 总事务数 Support(\{X\})=\frac{\text{包含}X\text{的事务数}}{\text{总事务数}}
S u p p o r t ( { X } ) = 总事务数 包含 X 的事务数
删除支持度低于最小支持度阈值的项集,保留频繁项集
生成更高阶的候选项集,通过连接频繁项集生成更高阶的候选项集
例如频繁 1-项集 { A } , { B } , { C } \{A\},\{B\},\{C\} { A } , { B } , { C } { A , B } , { B , C } , { A , C } \{A,B\},\{B,C\},\{A,C\} { A , B } , { B , C } , { A , C }
重复上述迭代步骤,直到无法生成更高阶的候选项集
用例子介绍具体步骤
首先定义最小支持度为 0.5,对于一组事务如下
TID
项
001
r z h j p
002
z y x w v u t s
003
z
004
r x n o s
005
y r x z q t p
006
y z x e q s t m
生成候选项集 1-项集,计算每个候选项集的支持度,如下
r
z
h
j
p
y
x
w
v
u
t
s
n
o
q
e
m
0.50
0.83
0.17
0.17
0.33
0.50
0.67
0.17
0.17
0.17
0.50
0.50
0.17
0.17
0.17
0.17
0.17
将不满足最小支持度的项都去掉,得到最终得到 r , z , y , x , t , s r,z,y,x,t,s r , z , y , x , t , s
{r, z}
{r, y}
{r, x}
{r, t}
{r, s}
{z, y}
{z, x}
{z, t}
{z, s}
{y, x}
{y, t}
{y, s}
{x, t}
{x, s}
{t, s}
0.33
0.17
0.33
0.17
0.17
0.5
0.5
0.5
0.33
0.5
0.5
0.33
0.5
0.5
0.33
将不满足最小支持度的项去掉,得到满足的项有 { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s } \{z,y\}, \{z,x\}, \{z,t\}, \{y,x\}, \{y,t\}, \{x,t\}, \{x,s\} { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s }
{z, y, x}
{z, y, t}
{z, x, y, t}
{z, y, x, s}
{z, x, t}
{z, x, s}
{z, x, s, t}
{y, x, t}
{y, x, s}
{y, x, s, t}
{x, s, t}
0.5
0.5
0.5
0.33
0.5
0.33
0.33
0.5
0.33
0.33
0.33
将不满足最小支持度的项都去掉,得到满足的项有 { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t } \{z, y, x\},\{z, y, t\},\{z, x, y, t\},\{z, x, t\},\{y, x, t\} { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t }
上述的项集中,满足最小支持度要求的都是频繁项集,如下
1-项集 { r } , { z } , { y } , { x } , { t } , { s } \{r\},\{z\},\{y\},\{x\},\{t\},\{s\} { r } , { z } , { y } , { x } , { t } , { s }
2-项集 { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s } \{z,y\}, \{z,x\}, \{z,t\}, \{y,x\}, \{y,t\}, \{x,t\}, \{x,s\} { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s }
3-项集 { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t } \{z, y, x\},\{z, y, t\},\{z, x, y, t\},\{z, x, t\},\{y, x, t\} { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t }
优点
缺点
计算复杂度高,需要多次扫描数据集
生成的候选项集数量可能非常大
FP-Growth 算法
FP-Growth 算法是一种基于 FP 树(Frequent Pattern Tree)的高效频繁项集生成方法
核心思想
通过构建 FP 树压缩数据集,避免生成候选项集
使用分治法递归挖掘频繁项集
步骤
构建 FP 树
扫描数据集,统计每个项的支持度,删除支持度低于阈值的项,将剩余的项按支持度从高到低排序
再次扫描数据集,将每条事务插入 FP 树中,FP 树的每个节点包含事务中的项的名称和支持度计数,每条事务中的项按支持度从高到低排序
如果 FP 树中已存在相同前缀路径,则增加相应节点的计数,否则,创建新节点
对于每个项,生成其条件模式基(即包含该项的所有路径的前缀路径)
对于每个项,根据条件模式基构建条件 FP 树
从条件 FP 树中递归挖掘频繁项集
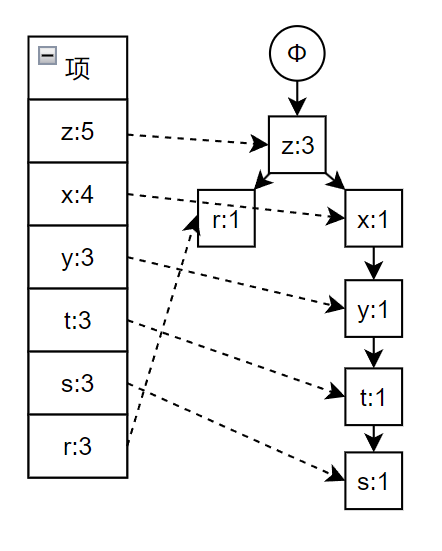
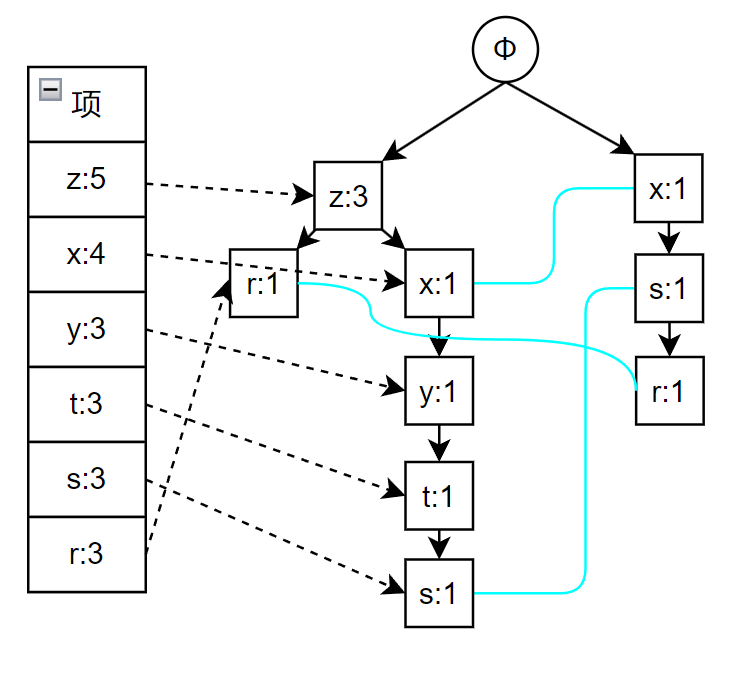
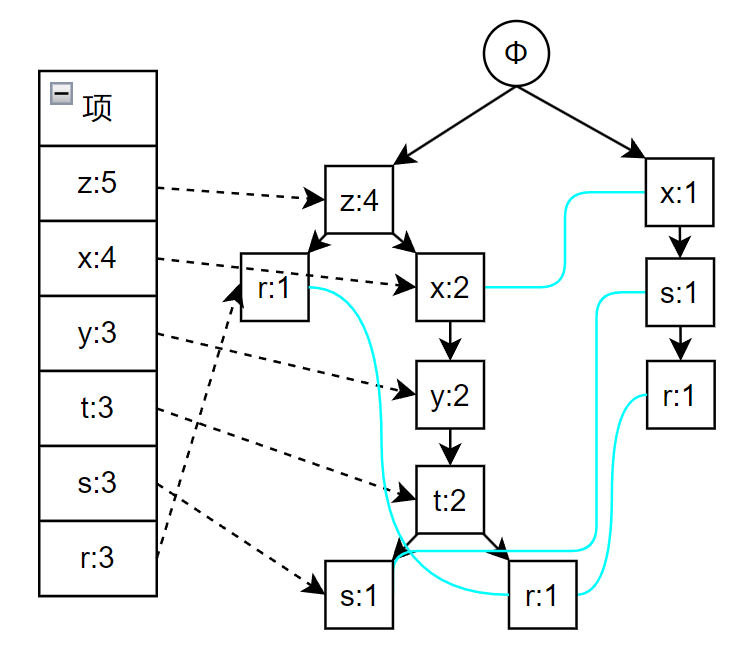
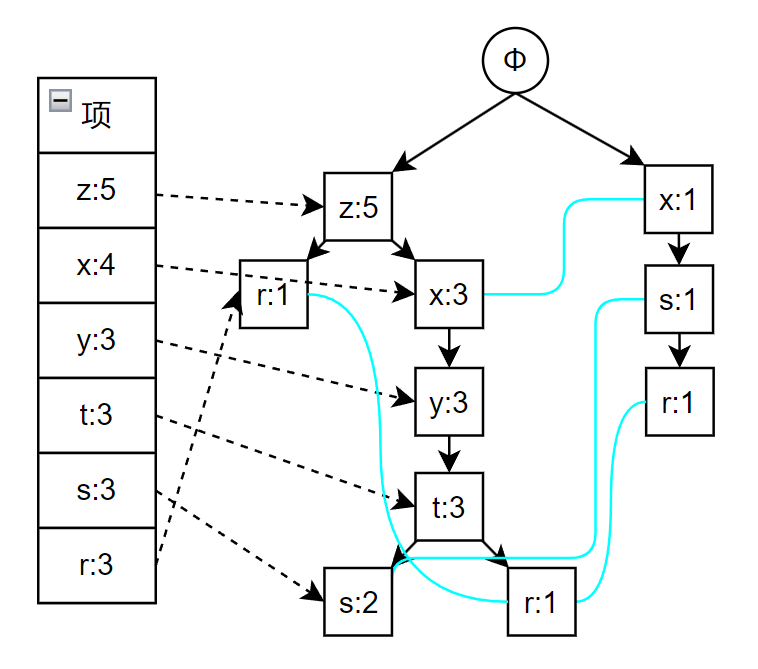
构建 FP 树
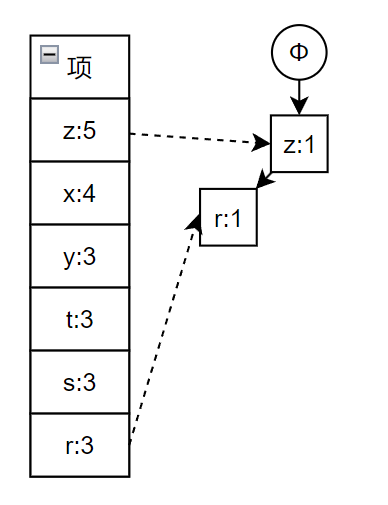
由于构建 FP 树的流程比较复杂,所以这里详细解释一下
对于一组事务如下
TID
项
001
r z h j p
002
z y x w v u t s
003
z
004
r x n o s
005
y r x z q t p
006
y z x e q s t m
计算每个项的支持度,就是包含该项的事务占所有事务的比例
r
z
h
j
p
y
x
w
v
u
t
s
n
o
q
e
m
0.50
0.83
0.17
0.17
0.33
0.50
0.67
0.17
0.17
0.17
0.50
0.50
0.17
0.17
0.17
0.17
0.17
这里选择最小支持度为 0.2,将上述事务中的项按照支持度重新排列
项
001
z r
002
z x y t s
003
z
004
x s r
005
z x y t r
006
z x y t s
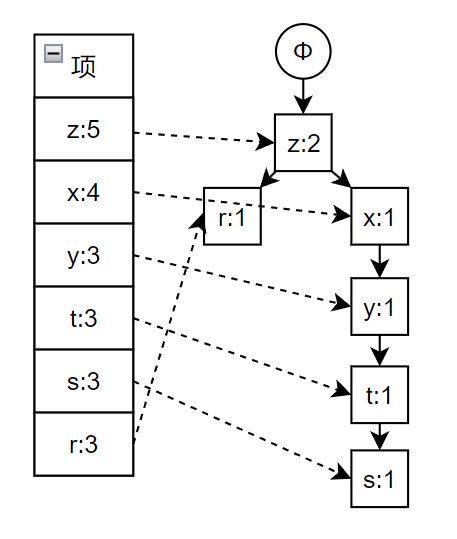
再次扫描,开始构造 FP 树,具体过程如下图所示,依次是事务 1 到 6 构建 FP 树,其中蓝色的线表示相同项,最后一张图片就是最终创建出的 FP 树
得到条件模式基
对于每一个元素项,获得其对应的条件模式基(conditional pattern base),单个元素项的条件模式基也就是元素项的关键字,条件模式基是以所查找元素项为结尾的路径集合。每一条路径其实都是一条前辍路径,一条前缀路径是介于所査找元素项与树根节点之间的所有内容
对于上述创建出的 FP 树,求每一个元素项的条件模式基,寻找条件模式基的过程实际上是从 FP 树的每个叶子节点回溯到根节点的过程
条件模式基
z
{}
x
{z}
y
{z, x}
t
{z, x, y}
s
{z}, {z, x, y, t}, {x}
r
{z}, {z, x, y, t}, {x, s}
构建条件树
为了发现更多的频繁项集,对于每一个频繁项,都创建一棵条件 FP 树,使用上述的条件模式基作为输入数据,构建条件 FP 树。然后,递归地发现频繁项、发现条件模式基,以及发现另外的条件树
例如,对于 r 元素的条件模式基来说,将其的每一个条件模式基都作为一个事务,以次来构建 FP 树,这里选择最小支持度为 0.5,可以得到如下支持度列表
z
x
y
t
s
0.67
0.67
0.33
0.33
0.33
将事务项重新排列得到
构建出的条件 FP 树如下
得到 r 的条件模式为 { z , x } , { x } \{z,x\},\{x\} { z , x } , { x } { z , x } \{z,x\} { z , x } { x } \{x\} { x } { z , x } \{z,x\} { z , x } { z , x } , { x } \{z,x\},\{x\} { z , x } , { x }
对于每一个元素项都进行构建条件树,最终发现频繁项集 { z , x } , { x } \{z,x\},\{x\} { z , x } , { x }
优点
计算效率高,只需扫描数据集两次
不生成候选项集,节省存储空间和计算资源
适用于稀疏数据集和大规模数据
内存效率高,通过 FP 树压缩数据
缺点
实现复杂,尤其是 FP 树的构建和递归挖掘
对内存要求较高,处理超大规模数据时可能受限
不适合动态数据集
对最小支持度敏感,设置不当可能导致性能下降
难以并行化,限制了在分布式环境中的应用
Eclat 算法
Eclat算法(Equivalence Class Clustering and bottom-up Lattice Traversal)是一种用于挖掘频繁项集的算法,采用垂直数据格式和深度优先搜索策略,通过交集操作高效发现频繁项集,特别适合处理稠密数据集
步骤
将水平格式的事务数据集转换为垂直格式(项-TID 集),移除支持度低于最小支持度的项
扫描垂直数据格式,统计每个项的支持度,筛选出频繁 1-项集
对于每个频繁 (k-1)-项集,与其他频繁 (k-1)-项集进行交集操作,生成候选 k-项集。计算候选 k-项集的支持度(交集的大小),如果支持度满足最小支持度,则保留为频繁k-项集
当无法生成新的频繁项集时,算法终止
用例子介绍具体步骤
首先定义最小支持度为 0.5,对于一组事务如下
TID
项
001
r z h j p
002
z y x w v u t s
003
z
004
r x n o s
005
y r x z q t p
006
y z x e q s t m
转换为垂直格式得到
r
z
h
j
p
y
x
w
v
u
t
s
n
o
q
e
m
1, 4, 5
1, 2, 3, 5, 6
1
1
1, 5
2, 5, 6
2, 4, 5, 6
2
2
2
2, 5, 6
2, 4, 6
4
4
5
6
6
扫描生成频繁 1-项集 r , z , y , x , t , s r, z, y, x, t, s r , z , y , x , t , s
生成频繁 2-项集
r ∩ z {r\cap z} r ∩ z r ∩ y {r\cap y} r ∩ y r ∩ x {r\cap x} r ∩ x r ∩ t {r\cap t} r ∩ t r ∩ s {r\cap s} r ∩ s z ∩ y {z\cap y} z ∩ y z ∩ x {z\cap x} z ∩ x z ∩ t {z\cap t} z ∩ t z ∩ s {z\cap s} z ∩ s y ∩ x {y\cap x} y ∩ x y ∩ t {y\cap t} y ∩ t y ∩ s {y\cap s} y ∩ s x ∩ t {x\cap t} x ∩ t x ∩ s {x\cap s} x ∩ s t ∩ s {t\cap s} t ∩ s
1, 5
5
4, 5
5
4
2, 5, 6
2, 5, 6
2, 5, 6
2, 6
2, 5, 6
2, 5, 6
2, 6
2, 5, 6
2, 4, 6
2, 6
生成频繁 2-项集为 { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s } \{z,y\}, \{z,x\}, \{z,t\}, \{y,x\}, \{y,t\}, \{x,t\}, \{x,s\} { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s }
生成频繁 3-项集
z ∩ y ∩ x {z\cap y\cap x} z ∩ y ∩ x z ∩ y ∩ t {z\cap y\cap t} z ∩ y ∩ t z ∩ x ∩ y ∩ t {z\cap x\cap y\cap t} z ∩ x ∩ y ∩ t z ∩ y ∩ x ∩ s {z\cap y\cap x\cap s} z ∩ y ∩ x ∩ s z ∩ x ∩ t {z\cap x\cap t} z ∩ x ∩ t z ∩ x ∩ s {z\cap x\cap s} z ∩ x ∩ s z ∩ x ∩ s ∩ t {z\cap x\cap s\cap t} z ∩ x ∩ s ∩ t y ∩ x ∩ t {y\cap x\cap t} y ∩ x ∩ t y ∩ x ∩ s {y\cap x\cap s} y ∩ x ∩ s y ∩ x ∩ s ∩ t {y\cap x\cap s\cap t} y ∩ x ∩ s ∩ t x ∩ s ∩ t {x\cap s\cap t} x ∩ s ∩ t
2, 5, 6
2, 5, 6
2, 5, 6
2, 6
2, 5, 6
2, 6
2, 6
2, 5, 6
2, 6
2, 6
2, 6
生成频繁 3-项集为 { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t } \{z, y, x\},\{z, y, t\},\{z, x, y, t\},\{z, x, t\},\{y, x, t\} { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t }
此时无法生成新的频繁项集时,算法终止
得到频繁项集如下
1-项集 { r } , { z } , { y } , { x } , { t } , { s } \{r\},\{z\},\{y\},\{x\},\{t\},\{s\} { r } , { z } , { y } , { x } , { t } , { s }
2-项集 { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s } \{z,y\}, \{z,x\}, \{z,t\}, \{y,x\}, \{y,t\}, \{x,t\}, \{x,s\} { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s }
3-项集 { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t } \{z, y, x\},\{z, y, t\},\{z, x, y, t\},\{z, x, t\},\{y, x, t\} { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t }
优点
使用垂直数据格式和交集操作,避免了生成大量候选集
在项集出现频率较高的情况下表现优异
深度优先搜索策略减少了内存占用
缺点
在项集出现频率较低的情况下,性能可能下降
对于大规模数据集,TID 集的存储和计算可能成为瓶颈
生成关联规则示例
首先定义最小支持度为 0.5,设定最小置信度为 0.7,对于一组事务如下
TID
项
001
r z h j p
002
z y x w v u t s
003
z
004
r x n o s
005
y r x z q t p
006
y z x e q s t m
通过 Apriori 算法中所得到的频繁项集如下
1-项集 { r } , { z } , { y } , { x } , { t } , { s } \{r\},\{z\},\{y\},\{x\},\{t\},\{s\} { r } , { z } , { y } , { x } , { t } , { s }
2-项集 { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s } \{z,y\}, \{z,x\}, \{z,t\}, \{y,x\}, \{y,t\}, \{x,t\}, \{x,s\} { z , y } , { z , x } , { z , t } , { y , x } , { y , t } , { x , t } , { x , s }
3-项集 { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t } \{z, y, x\},\{z, y, t\},\{z, x, y, t\},\{z, x, t\},\{y, x, t\} { z , y , x } , { z , y , t } , { z , x , y , t } , { z , x , t } , { y , x , t }
先在 3-项集中寻找规则
z , y → x = 3 3 = 1 z,y\rightarrow x=\frac{3}{3}=1 z , y → x = 3 3 = 1 x , y → z = 3 3 = 1 x,y\rightarrow z=\frac{3}{3}=1 x , y → z = 3 3 = 1 x , z → y = 3 3 = 1 x,z\rightarrow y=\frac{3}{3}=1 x , z → y = 3 3 = 1 ……
在 2-项集中寻找规则
z → y = 3 5 = 0.6 z\rightarrow y=\frac{3}{5}=0.6 z → y = 5 3 = 0 . 6 y → z = 3 3 = 1 y\rightarrow z=\frac{3}{3}=1 y → z = 3 3 = 1 ……
可以得到有用的关联规则
密度估计
密度估计是机器学习中的一种重要技术,用于估计数据的概率分布,在许多任务中都有应用,例如异常检测、生成模型和数据可视化
密度估计的目标是从观测数据中估计出数据的概率密度函数
马尔可夫链蒙特卡罗
马尔可夫链蒙特卡罗(MCMC,Markov Chain Monte Carlo)方法是一类通过构建马尔可夫链来从复杂概率分布中采样的算法,在难以直接采样时非常有效
步骤
选择一个初始状态 x 0 x_0 x 0
通过采样算法来逐步生成新状态 x t + 1 x_{t+1} x t + 1
Hamiltonian Monte Carlo
Metropolis-Hastings 算法
Gibbs 采样
运行足够长的时间以达到平稳分布,判断收敛的方法有
目测法:观察样本路径是否稳定
统计检验:如 Gelman-Rubin 统计量
自相关性分析:检查样本的自相关性是否降低
当马尔可夫链达到平稳分布时,生成的样本可以视为来自目标分布 p ( x ) p(x) p ( x )
这些样本用于蒙特卡罗估计来计算需要的数据,例如计算目标函数的期望
E [ f ( x ) ] = 1 N ∑ t N f ( x t ) E[f(x)]=\frac{1}{N}\sum_t^Nf(x_t)
E [ f ( x ) ] = N 1 t ∑ N f ( x t )
Hamiltonian Monte Carlo
是一种高效的马尔可夫链蒙特卡罗(MCMC)方法,特别适用于高维空间的采样,结合了物理系统中的哈密顿动力学和蒙特卡罗采样,通过引入动量变量来探索目标分布,避免了随机游走的低效性
物理类比
将目标分布 p ( x ) p(x) p ( x ) U ( x ) = − log p ( x ) U(x)=-\log p(x) U ( x ) = − log p ( x )
引入动量 v v v x x x ( x , v ) (x,v) ( x , v )
系统的总能量(哈密顿量)为 H ( x , v ) = U ( x ) + K ( v ) H(x,v)=U(x)+K(v) H ( x , v ) = U ( x ) + K ( v ) K ( v ) = v T v 2 K(v)=\frac{v^Tv}{2} K ( v ) = 2 v T v
动力学模拟
通过模拟哈密顿动力学生成 ( x , v ) (x,v) ( x , v )
动力学方程由哈密顿方程描述 d x d t = ∂ H ∂ v , d v d t = − ∂ H ∂ x \frac{dx}{dt}=\frac{\partial H}{\partial v},\frac{dv}{dt}=-\frac{\partial H}{\partial x} d t d x = ∂ v ∂ H , d t d v = − ∂ x ∂ H
蒙特卡罗采样
利用动力学轨迹生成候选状态
通过 Metropolis-Hastings 步骤接受或拒绝候选状态,确保采样正确性
具体步骤
选择初始状态 x 0 x_0 x 0 v 0 v_0 v 0 v 0 ∼ N ( 0 , M ) v_0\sim\mathcal{N}(0,M) v 0 ∼ N ( 0 , M ) M M M
从当前状态 ( x t , v t ) (x_t,v_t) ( x t , v t )
计算梯度:计算势能函数的梯度 ∇ U ( x ) \nabla U(x) ∇ U ( x )
交替更新动量和位置,其中 ϵ \epsilon ϵ
v k + 1 = v k − ϵ 2 ∇ U ( x ) x k + 1 = x k + ϵ M − 1 v v_{k+1}=v_k-\frac{\epsilon}{2}\nabla U(x)\\x_{k+1}=x_{k}+\epsilon M^{-1}v
v k + 1 = v k − 2 ϵ ∇ U ( x ) x k + 1 = x k + ϵ M − 1 v
重复上述步骤 L L L ( x ⋆ , v ⋆ ) (x^\star,v^\star) ( x ⋆ , v ⋆ ) L L L
M-H 接受/拒绝
计算哈密顿量的变化
Δ H = H ( x ⋆ , v ⋆ ) − H ( x t , v t ) \Delta H=H(x^\star,v^\star)-H(x_t,v_t)
Δ H = H ( x ⋆ , v ⋆ ) − H ( x t , v t )
计算接受概率
A = min ( 1 , exp ( − Δ H ) ) A=\min(1,\exp(-\Delta H))
A = min ( 1 , exp ( − Δ H ) )
从均匀分布 U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) u u u
u ≤ A u\leq A u ≤ A x ⋆ x^\star x ⋆ x t + 1 x_{t+1} x t + 1 否则保留 x t + 1 = x t x_{t+1}=x_t x t + 1 = x t
重复迭代,直到生成足够多的样本
丢弃预热样本,例如丢弃前 1000 个样本,以减少初始值的影响
Metropolis-Hastings
Metropolis-Hastings(MH)是一种经典的马尔可夫链蒙特卡罗(MCMC)方法,用于从复杂的目标分布中采样
初始化,选择一个初始状态 x 0 x_0 x 0 S : { } S:\{\} S : { }
迭代采样,对于每次迭代 t = 0 , 1 , … t=0,1,… t = 0 , 1 , …
从提议分布 q ( x ′ ∣ x t ) q(x^\prime\vert x_t) q ( x ′ ∣ x t ) x ′ x^\prime x ′ q ( x ′ ∣ x t ) = q ( x t ∣ x ′ ) q(x^\prime\vert x_t)=q(x_t\vert x^\prime) q ( x ′ ∣ x t ) = q ( x t ∣ x ′ )
计算接受概率 A ( x ′ ∣ x t ) A(x^\prime\vert x_t) A ( x ′ ∣ x t )
A ( x ′ ∣ x t ) = min ( 1 , p ( x ′ ) q ( x t ∣ x ′ ) p ( x t ) q ( x ′ ∣ x t ) ) A(x^\prime\vert x_t)=\min(1,\frac{p(x^\prime)q(x_t\vert x^\prime)}{p(x_t)q(x^\prime\vert x_t)})
A ( x ′ ∣ x t ) = min ( 1 , p ( x t ) q ( x ′ ∣ x t ) p ( x ′ ) q ( x t ∣ x ′ ) )
从均匀分布 U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) u u u
u ≤ A ( x ′ ∣ x t ) u\leq A(x^\prime\vert x_t) u ≤ A ( x ′ ∣ x t ) x ⋆ x^\star x ⋆ x t + 1 x_{t+1} x t + 1 否则保留 x t + 1 = x t x_{t+1}=x_t x t + 1 = x t
从均匀分布 U ( 0 , 1 ) U(0,1) U ( 0 , 1 ) u u u
u ≤ A ( x ′ ∣ x t ) u\leq A(x^\prime\vert x_t) u ≤ A ( x ′ ∣ x t ) x ⋆ x^\star x ⋆ x t + 1 x_{t+1} x t + 1 否则保留 x t + 1 = x t x_{t+1}=x_t x t + 1 = x t
将新状态加入样本集合
运行马尔可夫链足够长的时间,直到链达到平稳分布
丢弃预热样本,例如丢弃前 1000 个样本,以减少初始值的影响
Gibbs 采样
Gibbs 采样 是一种特殊的马尔可夫链蒙特卡罗(MCMC)方法,用于从多维概率分布中采样,通过依次更新每个维度,利用条件分布生成样本,避免了接受概率的计算
选择多维初始状态 x ( 0 ) = { x 1 ( 0 ) , . . . x n ( 0 ) } x^{(0)}=\{x_1^{(0)},...x_n^{(0)}\} x ( 0 ) = { x 1 ( 0 ) , . . . x n ( 0 ) } S : { } S:\{\} S : { }
迭代采样,对于每次迭代 t = 0 , 1 , … t=0,1,… t = 0 , 1 , …
对于每个维度做如下工作
从条件分布 P ( x i ∣ x − i ( t ) ) P(x_i\vert x_{-i}^{(t)}) P ( x i ∣ x − i ( t ) ) x i ( t + 1 ) x_i^{(t+1)} x i ( t + 1 ) x − i ( t ) x_{-i}^{(t)} x − i ( t ) i i i
将 x i ( t + 1 ) x_i^{(t+1)} x i ( t + 1 )
完成所有维度的更新之后,将新状态 x ( t + 1 ) = { x 1 ( t + 1 ) , . . . x n ( t + 1 ) } x^{(t+1)}=\{x_1^{(t+1)},...x_n^{(t+1)}\} x ( t + 1 ) = { x 1 ( t + 1 ) , . . . x n ( t + 1 ) } S S S
运行足够长时间,直到马尔可夫链达到平稳
丢弃预热样本,例如丢弃前 1000 个样本,以减少初始值的影响
优点
适用于各种复杂分布
在满足条件下,马尔可夫链都会收敛到目标分布
缺点
变分推断
变分推断(Variational Inference, VI) 是一种用于近似复杂概率分布的方法,广泛应用于贝叶斯推断和机器学习中,与马尔可夫链蒙特卡罗(MCMC)方法不同,变分推断通过优化问题来找到一个近似分布,而不是通过采样,将推断问题转化为优化问题,从而在计算效率和精度之间取得平衡
核心思想
目标:给定一个复杂的后验分布 P ( z ∣ x ) P(z\vert x) P ( z ∣ x ) Q ( z ) Q(z) Q ( z ) P ( z ∣ x ) P(z\vert x) P ( z ∣ x )
通过最小化 Q ( z ) Q(z) Q ( z ) P ( z ∣ x ) P(z\vert x) P ( z ∣ x )
Q ( z ) Q(z) Q ( z )
步骤
定义变分分布族,选择一个简单的分布族 Q ( z , θ ) Q(z,\theta) Q ( z , θ ) θ \theta θ
目标是最小化 Q ( z , θ ) Q(z,\theta) Q ( z , θ ) P ( z ∣ x ) P(z\vert x) P ( z ∣ x )
K L ( Q ( z , θ ) ∥ P ( z ∣ x ) ) = E Q ( z , θ ) [ log Q ( z , θ ) P ( z ∣ x ) ] KL(Q(z,\theta)\Vert P(z\vert x))=E_{Q(z,\theta)}[\log\frac{Q(z,\theta)}{P(z\vert x)}]
K L ( Q ( z , θ ) ∥ P ( z ∣ x ) ) = E Q ( z , θ ) [ log P ( z ∣ x ) Q ( z , θ ) ]
由于 P ( z ∣ x ) P(z\vert x) P ( z ∣ x )
L ( θ ) = E Q ( z , θ ) [ log P ( z ∣ x ) − log Q ( z , θ ) ] \mathcal{L}(\theta)=E_{Q(z,\theta)}[\log{P(z\vert x)}-\log{Q(z,\theta)}]
L ( θ ) = E Q ( z , θ ) [ log P ( z ∣ x ) − log Q ( z , θ ) ]
L ( θ ) \mathcal{L}(\theta) L ( θ )
通过梯度上升等优化算法,最大化 ELBO
θ ⋆ = arg max θ L ( θ ) \theta^\star=\underset{\theta}{\arg\max}\mathcal{L}(\theta)
θ ⋆ = θ arg max L ( θ )
由于优化过程中需要计算梯度 ∇ θ L ( θ ) = ∇ θ E Q ( z , θ ) [ log P ( z ∣ x ) − log Q ( z , θ ) ] \nabla_\theta\mathcal{L}(\theta)=\nabla_\theta E_{Q(z,\theta)}[\log{P(z\vert x)}-\log{Q(z,\theta)}] ∇ θ L ( θ ) = ∇ θ E Q ( z , θ ) [ log P ( z ∣ x ) − log Q ( z , θ ) ]
优化完成之后,得到变分分布 Q ( z , θ ⋆ ) Q(z,\theta^\star) Q ( z , θ ⋆ ) P ( z ∣ x ) P(z\vert x) P ( z ∣ x )
优点
相比 MCMC,变分推断通常更快,适合大规模数据
变分推断是确定性方法,避免了 MCMC 的随机性
缺点
变分分布族的选择可能引入偏差,导致近似不准确
优化过程可能陷入局部最优
需要对联合分布 P ( x , z ) P(x,z) P ( x , z )
密度估计的方法
参数化的方法,假设数据服从某种已知的概率分布(如高斯分布),然后通过估计分布参数来拟合数据
非参数化方法,不对数据的分布做任何假设,直接从数据中估计密度函数
直方图法(Histogram)
核密度估计(Kernel Density Estimation, KDE)
K 近邻密度估计(K-Nearest Neighbors, KNN)
基于模型的方法,利用机器学习模型直接估计密度函数
自回归模型(Autoregressive Models)
归一化流(Normalizing Flows)
变分自编码器(VAE)
生成对抗网络(Generative Adversarial Networks, GAN)
其他方法
高斯分布密度估计
高斯分布(正态分布)密度估计是一种参数化方法,假设数据服从高斯分布,并通过估计分布的参数(均值和方差)来拟合数据
高斯分布
高斯分布的概率密度函数为
p ( x ∣ μ , σ 2 ) = 1 2 π σ 2 exp ( − ( x − μ ) 2 2 σ 2 ) p(x\vert \mu,\sigma^2)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp(-\frac{(x-\mu)^2}{2\sigma^2})
p ( x ∣ μ , σ 2 ) = 2 π σ 2 1 exp ( − 2 σ 2 ( x − μ ) 2 )
μ \mu μ σ 2 \sigma^2 σ 2
高斯分布的步骤
假设输入数据 x : { x 1 , … x n } x:\{x_1,…x_n\} x : { x 1 , … x n } N ( μ , σ 2 ) \mathcal{N}(\mu,\sigma^2) N ( μ , σ 2 )
估计参数,使用最大似然估计计算均值和方差
μ = 1 n ∑ i n x i σ 2 = 1 n ∑ i n ( x i − μ ) 2 \mu=\frac{1}{n}\sum_i^nx_i\\\sigma^2=\frac{1}{n}\sum_i^n(x_i-\mu)^2
μ = n 1 i ∑ n x i σ 2 = n 1 i ∑ n ( x i − μ ) 2
将估计的均值和方差带入高斯分布的概率密度函数,得到密度函数 p ^ ( x ) \hat{p}(x) p ^ ( x )
可视化结果:绘制原始数据的直方图和估计的高斯分布曲线
优点
简单高效,计算速度快
对于服从高斯分布的数据,估计结果准确
缺点
假设数据服从高斯分布,可能不适用于复杂数据(如多峰分布)
对于非高斯分布的数据,估计结果可能不准确
混合高斯模型
混合高斯模型(Gaussian Mixture Model, GMM)是一种强大的密度估计方法,适用于数据分布复杂(如多峰分布)的情况,假设数据是由多个高斯分布混合而成,通过估计每个高斯分布的参数(均值、方差和混合系数)来拟合数据
模型定义
混合高斯模型的概率密度函数为
p ( x ) = ∑ k K π k ⋅ N ( x ∣ μ k , σ k ) p(x)=\sum_k^K\pi_k\cdot\mathcal{N}(x\vert \mu_k,\sigma_k)
p ( x ) = k ∑ K π k ⋅ N ( x ∣ μ k , σ k )
K K K
π k \pi_k π k k k k ∑ k K π k = 1 \sum_k^K\pi_k=1 ∑ k K π k = 1
N ( x ∣ μ k , σ k ) \mathcal{N}(x\vert \mu_k,\sigma_k) N ( x ∣ μ k , σ k ) k k k
N ( x ∣ μ k , σ k ) = 1 ( 2 π ) d / 2 ∣ σ k ∣ 1 / 2 exp ( − 1 2 ( x − μ k ) T σ k − 1 ( x − μ k ) ) \mathcal{N}(x\vert \mu_k,\sigma_k)=\frac{1}{(2\pi)^{d/2}\vert\sigma_k\vert^{1/2}}\exp(-\frac{1}{2}(x-\mu_k)^T\sigma_k^{-1}(x-\mu_k))
N ( x ∣ μ k , σ k ) = ( 2 π ) d / 2 ∣ σ k ∣ 1 / 2 1 exp ( − 2 1 ( x − μ k ) T σ k − 1 ( x − μ k ) )
混合高斯模型密度估计的步骤
初始化每个高斯分布的均值 μ k \mu_k μ k σ k \sigma_k σ k π k \pi_k π k
E 步:计算每个数据点 x i x_i x i k k k
γ i k = π k N ( x i ∣ μ k , σ k ) ∑ j K π j N ( x i ∣ μ j , σ j ) \gamma_{ik}=\frac{\pi_k\mathcal{N}(x_i\vert \mu_k,\sigma_k)}{\sum_j^K\pi_j\mathcal{N}(x_i\vert \mu_j,\sigma_j)}
γ i k = ∑ j K π j N ( x i ∣ μ j , σ j ) π k N ( x i ∣ μ k , σ k )
M 步:更新参数
π k = 1 n ∑ i n γ i k μ k = ∑ i n γ i k x i ∑ i n γ i k σ k = ∑ i n γ i k ( x i − μ k ) ( x i − μ k ) T ∑ i n γ i k \pi_k=\frac{1}{n}\sum_i^n\gamma_{ik}\\\mu_k=\frac{\sum_i^n\gamma_{ik}x_i}{\sum_i^n\gamma_{ik}}\\\sigma_k=\frac{\sum_i^n\gamma_{ik}(x_i-\mu_k)(x_i-\mu_k)^T}{\sum_i^n\gamma_{ik}}
π k = n 1 i ∑ n γ i k μ k = ∑ i n γ i k ∑ i n γ i k x i σ k = ∑ i n γ i k ∑ i n γ i k ( x i − μ k ) ( x i − μ k ) T
迭代重复 E 步和 M 步,直到参数收敛或达到最大迭代次数
使用估计的参数计算混合高斯模型的概率密度函数
优点
可以拟合复杂的多峰分布
灵活性强,适用于多种数据分布
缺点
计算复杂度较高,尤其是高维数据
对初始参数敏感,可能收敛到局部最优解
直方图法密度估计
直方图法(Histogram)是一种简单直观的非参数化密度估计方法,通过将数据空间划分为若干区间,统计每个区间内的样本数量来估计概率密度函数
直方图法定义
直方图法将数据空间划分为若干个区间,统计每个区间内样本的数量,然后除以总样本数和区间密度,得到每个区间的概率密度
得到概率密度函数的估计公式
p ^ ( x ) = n s n h \hat{p}(x)=\frac{n_s}{nh}
p ^ ( x ) = n h n s
n s n_s n s n n n h h h
直方图密度估计的步骤
划分区间
将数据范围划分为若干个等宽的区间
区间数量 k k k k = log 2 n + 1 k=\log_2n+1 k = log 2 n + 1 n n n
统计每个区间内的样本数量
用每个区间的样本数量除以总样本数和区间宽度,得到概率密度
绘制直方图,横轴为区间,纵轴为概率密度
优点
缺点
结果依赖于区间的划分,区间宽度选择对结果影响较大
密度估计不够平滑,可能丢失数据的细节信息
核密度估计
核密度估计(Kernel Density Estimation,KDE)是一种非参数化密度估计方法,通过对每个数据点放置一个核函数并将所有核函数叠加,得到平滑的概率密度函数
和密度估计的概率密度函数
p ^ ( x ) = 1 n h ∑ i = 1 n K ( x − x i h ) \hat{p}(x)=\frac{1}{nh}\sum_{i=1}^nK(\frac{x-x_i}{h})
p ^ ( x ) = n h 1 i = 1 ∑ n K ( h x − x i )
n n n h h h K K K
核密度估计的步骤
选择核函数
选择带宽,带宽 h h h
小带宽:核函数较窄,密度估计更关注局部细节,可能导致过拟合
大带宽:核函数较宽,密度估计更平滑,可能导致欠拟合
计算密度函数:对每个数据点 x i x_i x i x x x
绘制核密度估计曲线
核函数选择方法
高斯核适用于大多数场景,平滑性好 K ( u ) = 1 2 π exp ( − 1 2 u 2 ) K(u)=\frac{1}{\sqrt{2\pi}}\exp(-\frac{1}{2}u^2) K ( u ) = 2 π 1 exp ( − 2 1 u 2 )
均匀核适用于离散数据,计算简单 K ( u ) = { 1 2 ∣ u ∣ ≤ 1 0 ∣ u ∣ > 1 K(u)=\left\{\begin{aligned}&\frac{1}{2}&\vert u\vert\leq1\\&0&\vert u\vert>1\end{aligned}\right. K ( u ) = ⎩ ⎪ ⎨ ⎪ ⎧ 2 1 0 ∣ u ∣ ≤ 1 ∣ u ∣ > 1
三角核介于高斯核和均匀核之间,平滑性较好 K ( u ) = { 1 − ∣ u ∣ ∣ u ∣ ≤ 1 0 ∣ u ∣ > 1 K(u)=\left\{\begin{aligned}&1-\vert u\vert&\vert u\vert\leq1\\&0&\vert u\vert>1\end{aligned}\right. K ( u ) = { 1 − ∣ u ∣ 0 ∣ u ∣ ≤ 1 ∣ u ∣ > 1
Epanechnikov 核在均方误差意义下最优,计算效率高 K ( u ) = { 3 4 ( 1 − u 2 ) ∣ u ∣ ≤ 1 0 ∣ u ∣ > 1 K(u)=\left\{\begin{aligned}&\frac{3}{4}(1-u^2)&\vert u\vert\leq1\\&0&\vert u\vert>1\end{aligned}\right. K ( u ) = ⎩ ⎪ ⎨ ⎪ ⎧ 4 3 ( 1 − u 2 ) 0 ∣ u ∣ ≤ 1 ∣ u ∣ > 1
二次核比 Epanechnikov 核更平滑,计算复杂度较高 K ( u ) = { 15 16 ( 1 − u 2 ) 2 ∣ u ∣ ≤ 1 0 ∣ u ∣ > 1 K(u)=\left\{\begin{aligned}&\frac{15}{16}(1-u^2)^2&\vert u\vert\leq1\\&0&\vert u\vert>1\end{aligned}\right. K ( u ) = ⎩ ⎪ ⎨ ⎪ ⎧ 1 6 1 5 ( 1 − u 2 ) 2 0 ∣ u ∣ ≤ 1 ∣ u ∣ > 1
余弦核适用于周期性数据 K ( u ) = { π 4 cos ( π u 2 ) ∣ u ∣ ≤ 1 0 ∣ u ∣ > 1 K(u)=\left\{\begin{aligned}&\frac{\pi}{4}\cos(\frac{\pi u}{2})&\vert u\vert\leq1\\&0&\vert u\vert>1\end{aligned}\right. K ( u ) = ⎩ ⎪ ⎨ ⎪ ⎧ 4 π cos ( 2 π u ) 0 ∣ u ∣ ≤ 1 ∣ u ∣ > 1
指数核适用于长尾分布 K ( u ) = 1 2 exp ( − ∣ u ∣ ) K(u)=\frac{1}{2}\exp(-\vert u\vert) K ( u ) = 2 1 exp ( − ∣ u ∣ )
带宽的选择
优点
结果平滑,能够更好地反映数据的分布
无需假设数据分布,适用于复杂数据
缺点
计算复杂度较高,尤其是大规模数据
带宽选择对结果影响较大
K 近邻密度估计
K 近邻密度估计(K-Nearest Neighbors Density Estimation,KNN-DE) 是一种非参数化密度估计方法,基于数据点的局部邻域信息来估计概率密度函数。与核密度估计不同,K 近邻密度估计的带宽是自适应的,取决于每个数据点的局部密度
K 近邻密度估计函数
对于数据点 x x x
p ^ ( x ) = k n V ( R k ) \hat{p}(x)=\frac{k}{nV(R_k)}
p ^ ( x ) = n V ( R k ) k
k k k n n n R k R_k R k x x x k k k V ( R k ) V(R_k) V ( R k ) R k R_k R k
一维 V ( R k ) = 2 R k V(R_k)=2R_k V ( R k ) = 2 R k
二维 V ( R k ) = π R k 2 V(R_k)=\pi R_k^2 V ( R k ) = π R k 2
在 d d d V ( R k ) = π d / 2 Γ ( d / 2 + 1 ) R k d V(R_k)=\frac{\pi^{d/2}}{\Gamma(d/2+1)}R_k^d V ( R k ) = Γ ( d / 2 + 1 ) π d / 2 R k d Γ ( α ) = ∫ 0 ∞ x α − 1 e − x d x \Gamma(\alpha)=\int_0^\infty x^{\alpha-1}e^{-x}dx Γ ( α ) = ∫ 0 ∞ x α − 1 e − x d x
步骤
选择近邻的数量 k k k
计算每个数据点的 R k R_k R k
利用上述密度估计函数计算每个数据点的密度
绘制密度估计曲线
K 值的作用
k 值小:
密度估计更关注局部细节,可能捕捉到噪声
结果波动较大,容易过拟合
k 值大:
密度估计更平滑,可能丢失数据的局部特征
结果过于平滑,容易欠拟合
K 值的选择
经验公式法,通过简单的经验公式快速估计 k k k
k ≈ n k\approx\sqrt{n}
k ≈ n
交叉验证法,通过优化某种准则选择最优 k k k
将数据集分为训练集和验证集
对于每个候选的 k k k
L = ∑ i n log p ^ k ( x i ) L=\sum_i^n\log\hat{p}_k(x_i)
L = i ∑ n log p ^ k ( x i )
p ^ k \hat{p}_k p ^ k k k k 结果准确但是计算复杂度高
肘部法:通过绘制 k k k k k k
计算不同 k k k
绘制 k k k
选择方差下降速度明显减缓的肘部点
简单易懂,但是需要主观判断肘部点
网格搜索法:通过网格搜索和交叉验证选择最优 k k k
定义 k k k k ∈ [ 1 , 100 ] k\in[1,100] k ∈ [ 1 , 1 0 0 ]
对于每个 k k k
选择使对数似然最大的 k k k
结果准确,但是计算复杂度高
优点
自适应带宽:带宽 R k R_k R k
无需假设数据分布:完全依赖数据本身,适用于复杂分布
缺点
计算复杂度高:需要计算每个数据点的 k k k O ( n 2 ) O(n^2) O ( n 2 )
结果可能不够平滑:密度估计曲线可能呈现阶梯状
K 近邻密度估计的改进
在 k k k
p ^ ( x ) = 1 n ∑ i n 1 R k ( x i ) K ( x − x i R k ( x i ) ) \hat{p}(x)=\frac{1}{n}\sum_i^n\frac{1}{R_k(x_i)}K(\frac{x-x_i}{R_k(x_i)})
p ^ ( x ) = n 1 i ∑ n R k ( x i ) 1 K ( R k ( x i ) x − x i )
其中 K K K R k ( x i ) R_k(x_i) R k ( x i ) x i x_i x i k k k
自回归模型
自回归模型(Autoregressive Model,AR) 是一种用于密度估计的生成模型,通过对数据的条件概率分布进行建模来估计联合概率密度函数。自回归模型的核心思想是将高维数据的联合分布分解为一系列条件分布的乘积,逐步生成数据
自回归模型定义
自回归模型假设数据的联合概率密度函数可以分解为一系列条件概率分布的乘积
p ( x ) = ∏ i d p ( x i ∣ x 1 , . . . x i − 1 ) p(x)=\prod_i^dp(x_i\vert x_1,...x_{i-1})
p ( x ) = i ∏ d p ( x i ∣ x 1 , . . . x i − 1 )
x = ( x 1 , … x d ) x=(x_1,…x_d) x = ( x 1 , … x d ) d d d p ( x i ∣ x 1 , . . . x i − 1 ) p(x_i\vert x_1,...x_{i-1}) p ( x i ∣ x 1 , . . . x i − 1 ) i i i
自回归模型密度估计的步骤
对数据进行标准化或归一化处理,将数据划分为训练集和测试集
选择用于建模条件概率分布的模型
对每个维度 i i i x i x_i x i p ( x i ∣ x 1 , . . . x i − 1 ) p(x_i\vert x_1,...x_{i-1}) p ( x i ∣ x 1 , . . . x i − 1 )
使用训练好的模型计算联合概率密度函数 p ( x ) = ∏ i d p ( x i ∣ x 1 , . . . x i − 1 ) p(x)=\prod_i^dp(x_i\vert x_1,...x_{i-1}) p ( x ) = ∏ i d p ( x i ∣ x 1 , . . . x i − 1 )
使用测试集评估模型的性能
优点
灵活性高:可以建模复杂的条件分布
可扩展性强:适用于高维数据
生成能力强:可以用于生成新样本
缺点
计算复杂度高:需要逐步计算条件概率分布
训练难度大:需要大量数据和计算资源
归一化流
归一化流(Normalizing Flows,NF) 是一种强大的密度估计方法,通过一系列可逆变换将简单分布(如高斯分布)映射到复杂分布,从而实现对复杂数据分布的建模。归一化流的核心思想是通过可逆变换将数据从原始空间转换到一个隐空间,并在隐空间中计算概率密度
归一化流的概率密度函数
p ( x ) = p z ( f ( x ) ) ∣ det ( ∂ f ( x ) ∂ x ) ∣ p(x)=p_z(f(x))\vert \det(\frac{\partial f(x)}{\partial x})\vert
p ( x ) = p z ( f ( x ) ) ∣ det ( ∂ x ∂ f ( x ) ) ∣
f f f p z p_z p z det ( ∂ f ( x ) ∂ x ) \det(\frac{\partial f(x)}{\partial x}) det ( ∂ x ∂ f ( x ) )
归一化流密度估计的步骤
选择隐空间的简单分布 p z p_z p z
设计一系列可逆变换 f f f
通过上述公式使用变换的逆函数和雅可比行列式计算原始空间的概率密度
通过最大化对数似然函数训练模型
log p ( x ) = log p z ( f ( x ) ) + log ∣ det ( ∂ f ( x ) ∂ x ) ∣ \log p(x)=\log p_z(f(x))+\log\vert\det(\frac{\partial f(x)}{\partial x})\vert
log p ( x ) = log p z ( f ( x ) ) + log ∣ det ( ∂ x ∂ f ( x ) ) ∣
从隐空间生成样本,并通过逆变换映射到原始空间
归一化流的可逆函数
Affine Coupling Layer 仿射耦合层
通过将输入数据分为两部分,保持其中一部分不变,另一部分通过仿射变换(加法、乘法)来修改
对于输入 x = x 1 , x 2 x={x_1,x_2} x = x 1 , x 2
y 1 = x 1 y 2 = x 2 ⋅ exp ( s ( x 1 ) ) + t ( x 1 ) y_1=x_1\\y_2=x_2\cdot\exp(s(x_1))+t(x_1)
y 1 = x 1 y 2 = x 2 ⋅ exp ( s ( x 1 ) ) + t ( x 1 )
其中 s s s t t t x 1 x_1 x 1
Real NVP (Real-valued Non-Volume Preserving) / Masked Autoregressive Flow (MAF) 一种基于仿射耦合层的结构,通过特定的mask操作将输入数据分为两部分,使得每次变换只影响数据的部分维度
例如对于上述的仿射耦合层的变换,数据分块通过掩码完成,例如这里掩码通过向量 b b b
y = b x + ( 1 − b ) ( x ⋅ exp ( s ( b x ) ) + t ( b x ) ) y=bx+(1-b)(x\cdot\exp(s(bx))+t(bx))
y = b x + ( 1 − b ) ( x ⋅ exp ( s ( b x ) ) + t ( b x ) )
Invertible 1x1 Convolutions 一种用于图像数据的可逆卷积变换,通过对输入图像进行 1x1 卷积操作实现可逆性,通过正交矩阵(可逆)保证了其可逆性,并且不会影响数据的维度
Residual Flows 采用了残差结构,在每一步变换时,通过添加一个残差项来保证变换的可逆性(每次变换都通过一个加法操作来保持其可逆性)
Spline-based Flows 通过使用光滑的插值来建模可逆的映射,特别适合处理高维数据,通过使用特定的光滑函数来学习复杂的变换,且通过特殊的参数化保证可逆性
优点
精确计算概率密度:可以精确计算数据的概率密度
生成能力强:可以生成新样本
灵活性高:可以建模复杂的分布
缺点
计算复杂度高:需要计算雅可比行列式
设计复杂:需要设计可逆变换
变分自编码器
变分自编码器(Variational Autoencoder, VAE)是一种基于概率生成模型的深度学习方法,广泛用于密度估计、数据生成和表示学习,通过变分推断近似数据的潜在分布,并利用编码器-解码器结构实现数据的生成和重构
变分自编码器密度估计函数
密度估计的目标是建模数据的概率分布 p ( x ) p(x) p ( x ) x x x z z z
p ( x ) = ∫ p ( x ∣ z ) p ( z ) d z p(x)=\int p(x\vert z)p(z)dz
p ( x ) = ∫ p ( x ∣ z ) p ( z ) d z
p ( z ) p(z) p ( z ) N ( 0 , I ) \mathcal{N}(0,I) N ( 0 , I ) p ( x ∣ z ) p(x\vert z) p ( x ∣ z )
直接计算 p ( x ) p(x) p ( x )
变分推断
VAE 通过变分判断来近似真实后验分布 p ( z ∣ x ) p(z\vert x) p ( z ∣ x )
引入变分分布,使用一个由编码器实现的参数化的分布 q ( z ∣ x ) q(z\vert x) q ( z ∣ x ) p ( z ∣ x ) p(z\vert x) p ( z ∣ x )
优化目标:最大化证据下界,近似化解码器生成的数据与原始数据
E L B O = E q ( z ∣ x ) log p ( x ∣ z ) − K L ( q ( z ∣ x ) ∥ p ( z ) ) ELBO=\mathbb{E}_{q(z\vert x)}\log p(x\vert z)-KL(q(z\vert x)\Vert p(z))
E L B O = E q ( z ∣ x ) log p ( x ∣ z ) − K L ( q ( z ∣ x ) ∥ p ( z ) )
第一项是重构误差,衡量解码器生成的数据与原始数据的相似度
第二项是 KL 散度,衡量变分分布 q ( z ∣ x ) q(z\vert x) q ( z ∣ x ) p ( z ) p(z) p ( z )
通过最大化 ELBO,VAE 间接优化了数据的对数似然 log p ( x ) \log p(x) log p ( x )
VAE 的密度估计步骤
编码器:将输入数据 x x x z z z q ( z ∣ x ) q(z\vert x) q ( z ∣ x )
从 q ( z ∣ x ) q(z\vert x) q ( z ∣ x ) z = μ + σ ϵ z=\mu+\sigma\epsilon z = μ + σ ϵ ϵ ∼ N ( 0 , I ) \epsilon\sim\mathcal{N}(0,I) ϵ ∼ N ( 0 , I )
解码器:将采样得到的潜在变量 z z z z z z p ( x ∣ z ) p(x\vert z) p ( x ∣ z )
优化最大化证据下界
利用上述密度估计函数,通过蒙特卡罗采样近似计算数据的概率密度
p ( x ) ≈ 1 L ∑ i L p ( x ∣ z i ) z i ∼ q ( z ∣ x ) p(x)\approx\frac{1}{L}\sum_i^Lp(x\vert z_i)\quad z_i\sim q(z\vert x)
p ( x ) ≈ L 1 i ∑ L p ( x ∣ z i ) z i ∼ q ( z ∣ x )
优点
显式概率模型:直接建模数据的概率分布,适合密度估计任务
潜在表示:通过学习潜在变量,能够捕捉数据的低维结构
生成能力:可以从 p ( z ) p(z) p ( z )
缺点
近似误差:变分推断引入的近似可能导致密度估计不准确
生成质量:生成的样本可能不如GAN(生成对抗网络)清晰
计算复杂度:需要采样和蒙特卡罗近似,计算成本较高
改进方法
使用混合高斯分布或标准化流(Normalizing Flow)替代标准正态分布
使用归一化流或层次化变分分布来提高 q ( z ∣ x ) q(z\vert x) q ( z ∣ x )
正则化,例如 KL 散度退火或信息瓶颈,防止过拟合
将VAE与其他生成模型(如GAN)结合,提升生成质量和密度估计精度
变分贝叶斯自编码器
变分贝叶斯自编码器(Variational Bayesian Autoencoder, VBAE)是变分自编码器(VAE)的扩展,结合了贝叶斯推断的思想,能够更灵活地建模数据分布和潜在变量的不确定性
变分贝叶斯自编码器的核心思想
变分贝叶斯自编码器在 VAE 的基础上引入了贝叶斯推断,对模型参数(如编码器和解码器的权重)也进行概率建模,而不是像传统 VAE 那样使用确定性参数
模型参数的概率化:将编码器和解码器的权重视为随机变量,赋予其先验分布
变分推断:通过变分分布近似模型参数和潜在变量的后验分布
这种方法能更好地捕捉模型的不确定性,提高密度估计的鲁棒性
模型结构
VBAE 的模型结构如下
编码器:将输入数据映射到潜在变量的分布参数,得到潜在变量分布 q ( z ∣ x ) q(z\vert x) q ( z ∣ x )
解码器:将潜在变量 z z z p ( x ∣ z ) p(x\vert z) p ( x ∣ z )
贝叶斯参数:编码器和解码器的权重 θ \theta θ p ( θ ) p(\theta) p ( θ )
变分推断
VBAE 的目标是近似联合后验分布 p ( z , θ ∣ x ) p(z,\theta\vert x) p ( z , θ ∣ x )
变分分布:引入变分分布 q ( z , θ ∣ x ) q(z,\theta\vert x) q ( z , θ ∣ x ) p ( z , θ ∣ x ) p(z,\theta\vert x) p ( z , θ ∣ x )
分解假设:通常假设 q ( z , θ ∣ x ) = q ( z ∣ x ) q ( θ ) q(z,\theta\vert x)=q(z\vert x)q(\theta) q ( z , θ ∣ x ) = q ( z ∣ x ) q ( θ )
优化目标:最大化证据下界
E L B O = E q ( z , θ ∣ x ) log p ( x ∣ z , θ ) − K L ( q ( z ∣ x ) ∥ p ( z ) ) − K L ( q ( θ ) ∥ p ( θ ) ) ELBO=\mathbb{E}_{q(z,\theta\vert x)}\log p(x\vert z,\theta)-KL(q(z\vert x)\Vert p(z))-KL(q(\theta)\Vert p(\theta))
E L B O = E q ( z , θ ∣ x ) log p ( x ∣ z , θ ) − K L ( q ( z ∣ x ) ∥ p ( z ) ) − K L ( q ( θ ) ∥ p ( θ ) )
第一项是重构误差,衡量生成数据与原始数据的相似度
第二项是潜在变量的 KL 散度,衡量 q ( z ∣ x ) q(z\vert x) q ( z ∣ x ) p ( z ) p(z) p ( z )
第三项是模型参数的 KL 散度,衡量 q ( θ ) q(\theta) q ( θ ) p ( θ ) p(\theta) p ( θ )
最大化 ELBO,同时优化了潜在变量和模型参数的后验分布
变分贝叶斯自编码器密度估计的步骤
编码器:将输入数据 x x x q ( z ∣ x ) q(z\vert x) q ( z ∣ x )
采样:从 q ( z ∣ x ) q(z\vert x) q ( z ∣ x ) q ( θ ) q(\theta) q ( θ ) z z z θ \theta θ
解码器:使用采样的 z z z θ \theta θ p ( x ∣ z , θ ) p(x\vert z,\theta) p ( x ∣ z , θ )
通过蒙特卡罗采样近似计算数据的概率密度
p ( x ) ≈ 1 L ∑ i L p ( x ∣ z i , θ i ) z i ∼ q ( z ∣ x ) , θ i ∼ q ( θ ) p(x)\approx\frac{1}{L}\sum_i^Lp(x\vert z_i,\theta_i)\quad z_i\sim q(z\vert x),\theta_i\sim q(\theta)
p ( x ) ≈ L 1 i ∑ L p ( x ∣ z i , θ i ) z i ∼ q ( z ∣ x ) , θ i ∼ q ( θ )
优点
通过对模型参数进行贝叶斯建模,VBAE 能够更好地量化模型的不确定性
贝叶斯方法对过拟合具有更强的鲁棒性
可以结合更复杂的先验分布和变分分布,提高模型的表达能力
缺点
计算复杂度高
由于 VBAE 的优化目标是非凸的,可能导致训练过程陷入局部最优
对先验分布的选择和变分分布的形式等非常敏感,调参过程复杂
改进
使用混合高斯分布或标准化流(Normalizing Flow)替代简单的先验分布
使用层次化变分分布或依赖结构来提高变分分布的灵活性
使用随机梯度下降优化 ELBO,提高训练效率
正则化 ELBO 函数,如 KL 散度退火或信息瓶颈,防止过拟合
生成对抗网络
生成对抗网络(Generative Adversarial Networks,GAN),与一般的生成式模型不同,GAN 不直接建模 p ( x ) p(x) p ( x ) z z z x x x
基本原理
GAN 由两个神经网络组成
生成器:将随机噪声 z z z G ( z ) G(z) G ( z )
判别器:区分真实数据 x x x G ( z ) G(z) G ( z )
GAN 的训练目标是一个极小极大博弈
min G max D E x ∼ p ( x ) log D ( x ) + E z ∼ p ( z ) log ( 1 − D ( G ( z ) ) ) \underset{G}{\min}\underset{D}{\max}\mathbb{E}_{x\sim p(x)}\log D(x)+\mathbb{E}_{z\sim p(z)}\log(1-D(G(z)))
G min D max E x ∼ p ( x ) log D ( x ) + E z ∼ p ( z ) log ( 1 − D ( G ( z ) ) )
p ( x ) p(x) p ( x ) p ( z ) p(z) p ( z ) p G ( x ) p_G(x) p G ( x )
基于 GAN 的密度估计方法
由于 GAN 本身不直接支持密度估计,但研究者提出了多种方法来实现这一目标
基于生成器的密度估计
逆映射方法:通过训练一个额外的逆映射网络,将数据 x x x z z z p ( z ) p(z) p ( z )
p ( x ) ≈ p ( z ) ∣ det ( ∂ G ( z ) ∂ z ) ∣ − 1 p(x)\approx p(z)\vert\det(\frac{\partial G(z)}{\partial z})\vert^{-1}
p ( x ) ≈ p ( z ) ∣ det ( ∂ z ∂ G ( z ) ) ∣ − 1
其中 z = G − 1 ( x ) z=G^{-1}(x) z = G − 1 ( x )
标准化流:将生成器设计为可逆的标准化流模型,从而可以直接计算概率密度
基于判别器的密度估计
能量模型:将判别器 D ( x ) D(x) D ( x )
p ( x ) ∝ exp ( − E ( x ) ) E ( x ) = − log D ( x ) p(x)\propto\exp(-E(x))\quad E(x)=-\log D(x)
p ( x ) ∝ exp ( − E ( x ) ) E ( x ) = − log D ( x )
密度比估计:利用判别器估计真实数据分布 p ( x ) p(x) p ( x ) p G ( x ) p_G(x) p G ( x )
p ( x ) p G ( x ) ≈ D ( x ) 1 − D ( x ) \frac{p(x)}{p_G(x)}\approx\frac{D(x)}{1-D(x)}
p G ( x ) p ( x ) ≈ 1 − D ( x ) D ( x )
基于采样的密度估计
蒙特卡罗采样:从生成器中采样大量样本,利用核密度估计等方法近似真实数据分布
重要性采样:通过生成器生成样本,并利用判别器计算重要性权重,从而估计密度
混合模型
VAE-GAN 混合模型:将变分自编码器(VAE)与 GAN 结合,利用 VAE 的显式密度模型和 GAN 的生成能力,实现密度估计
Flow-GAN 混合模型:将标准化流与 GAN 结合,利用标准化流的可逆性计算概率密度
优点
高质量生成样本:GAN 生成的样本通常比 VAE 更清晰、更逼真
灵活性:GAN 可以建模复杂的数据分布,适用于高维数据
缺点
计算复杂度高:基于 GAN 的密度估计方法通常需要额外的网络或复杂的采样过程
训练不稳定性:GAN 的训练过程容易出现模式崩溃和不稳定性
无显式密度模型:需要额外的技术(如逆映射或标准化流)来实现密度估计
改进方法
为了提高 GAN 在密度估计中的性能,有如下几种改进方法
可逆生成器:设计可逆的生成器结构,如标准化流。
正则化技术:如梯度惩罚(Gradient Penalty)或谱归一化(Spectral Normalization),提高训练稳定性
混合模型:将 GAN 与其他生成模型(如 VAE 或标准化流)结合,提升密度估计能力
最大熵密度估计
最大熵密度估计(Maximum Entropy Density Estimation)是一种基于信息论的统计方法,用于从有限的已知信息中推断出最合理的概率分布
最大熵密度估计在所有满足已知约束条件的概率分布中,选择熵最大的分布作为估计结果,这种方法在缺乏完整信息的情况下,能够提供一种最不偏不倚的估计
最大熵原理
最大熵原理的核心思想就是在已知部分信息(如期望值和方差等)的情况下,选择熵最大的分布作为估计结果
熵是衡量分布不确定性的指标,熵最大的分布意味着在已知约束下对未知信息做出了最少的假设
在数学上,对于一个一维的连续型的随机变量,其概率密度分布函数为 p ( x ) p(x) p ( x )
H ( x ) = − ∫ p ( x ) log p ( x ) d x H(x)=-\int p(x)\log p(x)dx
H ( x ) = − ∫ p ( x ) log p ( x ) d x
对于离散型的随机变量,概率密度分布为
H ( x ) = ∑ i p ( x i ) log ( p ( x i ) ) H(x)=\sum_ip(x_i)\log(p(x_i))
H ( x ) = i ∑ p ( x i ) log ( p ( x i ) )
最大熵原理密度估计步骤
最大熵密度估计的目标是找到一个概率分布 p ( x ) p(x) p ( x ) H ( p ) H(p) H ( p )
假设已知一些关于分布的约束条件,例如
对于已知的函数 f i ( x ) f_i(x) f i ( x ) E [ f i ( x ) ] = μ i i = ( 1 , 2 , . . . m ) E[f_i(x)]=\mu_i\quad i=(1,2,...m) E [ f i ( x ) ] = μ i i = ( 1 , 2 , . . . m )
归一化条件 ∫ p ( x ) d x = 1 \int p(x)dx=1 ∫ p ( x ) d x = 1
最大化熵密度估计可以表示为以下约束优化问题
max p ( x ) H ( x ) = − ∫ p ( x ) log p ( x ) d x s . t . ∫ p ( x ) f i ( x ) d x = μ i ∫ p ( x ) d x = 1 \underset{p(x)}{\max}H(x)=-\int p(x)\log p(x)dx\\s.t.\int p(x)f_i(x)dx=\mu_i\\\int p(x)dx=1
p ( x ) max H ( x ) = − ∫ p ( x ) log p ( x ) d x s . t . ∫ p ( x ) f i ( x ) d x = μ i ∫ p ( x ) d x = 1
通过拉格朗日乘数法,可以将上述约束优化问题转化为无约束优化问题,引入拉格朗日乘数 λ 0 \lambda_0 λ 0 λ i \lambda_i λ i
L ( p , λ 0 , λ 1 ) = − ∫ p ( x ) log p ( x ) d x + λ 0 ( ∫ p ( x ) d x − 1 ) + ∑ i m λ i ( ∫ p ( x ) f i ( x ) d x − μ i ) \mathcal{L}(p,\lambda_0,\lambda_1)=-\int p(x)\log p(x)dx+\lambda_0(\int p(x)dx-1)+\sum_i^m\lambda_i(\int p(x)f_i(x)dx-\mu_i)
L ( p , λ 0 , λ 1 ) = − ∫ p ( x ) log p ( x ) d x + λ 0 ( ∫ p ( x ) d x − 1 ) + i ∑ m λ i ( ∫ p ( x ) f i ( x ) d x − μ i )
求解上述拉格朗日函数,对 p ( x ) p(x) p ( x )
p ( x ) = 1 Z exp ( − ∑ i m λ i f i ( x ) ) Z = ∫ exp ( − ∑ i m λ i f i ( x ) ) d x p(x)=\frac{1}{Z}\exp(-\sum_i^m\lambda_if_i(x))\\Z=\int\exp(-\sum_i^m\lambda_if_i(x))dx
p ( x ) = Z 1 exp ( − i ∑ m λ i f i ( x ) ) Z = ∫ exp ( − i ∑ m λ i f i ( x ) ) d x
最大熵分布的性质
在给定约束条件下,最大熵分布是唯一的
通过选择不同的约束条件,可以得到不同的最大熵分布
如果约束条件是均值和方差,则最大熵分布是高斯分布
如果约束条件是均值,则最大熵分布是指数分布
最大熵分布属于指数族分布 p ( x ) ∝ exp ( λ T f ( x ) ) p(x)\propto\exp(\lambda^Tf(x)) p ( x ) ∝ exp ( λ T f ( x ) )
优点
在已知约束下,最大熵分布对未知信息做出了最少的假设
可以通过选择不同的约束条件,适应不同的应用场景
最大熵分布是唯一满足约束条件且熵最大的分布
缺点
求解拉格朗日乘数和归一化常数可能需要数值方法,计算复杂度较高
约束条件的选择对结果影响较大,需要领域知识
贝叶斯密度估计
贝叶斯密度估计(Bayesian Density Estimation)是一种基于贝叶斯统计理论的概率密度估计方法,将概率密度函数的参数视为随机变量,并通过先验分布和观测数据来推断后验分布,从而得到概率密度的估计
核心思想
将概率密度函数的参数 θ \theta θ p ( θ ) p(\theta) p ( θ )
对于观测数据 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n } p ( θ ∣ X ) p(\theta\vert X) p ( θ ∣ X )
基于后验分布,对概率密度函数 p ( x ∣ θ ) p(x\vert\theta) p ( x ∣ θ )
p ( θ ∣ X ) = p ( X ∣ θ ) p ( θ ) p ( X ) p(\theta\vert X)=\frac{p(X\vert\theta)p(\theta)}{p(X)}
p ( θ ∣ X ) = p ( X ) p ( X ∣ θ ) p ( θ )
p ( X ∣ θ ) p(X\vert\theta) p ( X ∣ θ ) θ \theta θ X X X p ( θ ) p(\theta) p ( θ ) p ( X ) p(X) p ( X )
贝叶斯密度估计的步骤
选择一个参数化的概率密度函数 p ( x ∣ θ ) p(x\vert\theta) p ( x ∣ θ )
为参数 θ \theta θ p ( θ ) p(\theta) p ( θ )
利用观测的数据 X X X θ \theta θ
p ( θ ∣ X ) ∝ p ( X ∣ θ ) p ( θ ) p(\theta\vert X)\propto p(X\vert\theta)p(\theta)
p ( θ ∣ X ) ∝ p ( X ∣ θ ) p ( θ )
基于后验概率分布 p ( θ ∣ X ) p(\theta\vert X) p ( θ ∣ X ) p ( x ∣ X ) p(x\vert X) p ( x ∣ X )
p ( x ∣ X ) = ∫ p ( x ∣ θ ) p ( θ ∣ X ) d θ p(x\vert X)=\int p(x\vert\theta)p(\theta\vert X)d\theta
p ( x ∣ X ) = ∫ p ( x ∣ θ ) p ( θ ∣ X ) d θ
这一步可以通过马尔可夫链蒙特卡罗或变分推断来近似计算
贝叶斯密度估计的方法
基于高斯分布的贝叶斯密度估计
高斯分布的概率密度函数为
p ( x ∣ μ , σ 2 ) = 1 2 π σ 2 exp ( − ( x − μ ) 2 2 σ 2 ) p(x\vert \mu,\sigma^2)=\frac{1}{\sqrt{2\pi\sigma^2}}\exp(-\frac{(x-\mu)^2}{2\sigma^2})
p ( x ∣ μ , σ 2 ) = 2 π σ 2 1 exp ( − 2 σ 2 ( x − μ ) 2 )
对于多维数据,高斯分布的概率密度函数为
p ( x ∣ μ , Σ ) = 1 ( 2 π ) d / 2 ∣ Σ ∣ 1 / 2 exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x\vert \mu,\Sigma)=\frac{1}{(2\pi)^{d/2}\vert\Sigma\vert^{1/2}}\exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))
p ( x ∣ μ , Σ ) = ( 2 π ) d / 2 ∣ Σ ∣ 1 / 2 1 exp ( − 2 1 ( x − μ ) T Σ − 1 ( x − μ ) )
μ \mu μ σ 2 \sigma^2 σ 2 Σ \Sigma Σ d d d
在高斯分布贝叶斯密度估计中,将高斯分布的参数 μ , σ , Σ \mu,\sigma,\Sigma μ , σ , Σ
计算先验分布,为高斯分布的参数 μ \mu μ σ 2 \sigma^2 σ 2
均值:通常选择高斯分布 μ ∼ N ( μ 0 , σ 0 2 ) \mu\sim\mathcal{N}(\mu_0,\sigma_0^2) μ ∼ N ( μ 0 , σ 0 2 )
方差:通常选择逆伽马分布 σ 2 ∼ I n v − G a m m a ( α , β ) \sigma^2\sim Inv-Gamma(\alpha,\beta) σ 2 ∼ I n v − G a m m a ( α , β )
协方差矩阵:通常选择逆威沙特分布
计算后验分布,利用观测数据 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n }
对于一维高斯分布
p ( μ , σ 2 ∣ X ) ∝ p ( X ∣ μ , σ 2 ) p ( μ ) p ( σ 2 ) p(\mu,\sigma^2\vert X)\propto p(X\vert\mu,\sigma^2)p(\mu)p(\sigma^2)
p ( μ , σ 2 ∣ X ) ∝ p ( X ∣ μ , σ 2 ) p ( μ ) p ( σ 2 )
对于多维高斯分布
p ( μ , Σ ∣ X ) ∝ p ( X ∣ μ , Σ ) p ( μ ) p ( Σ ) p(\mu,\Sigma\vert X)\propto p(X\vert\mu,\Sigma)p(\mu)p(\Sigma)
p ( μ , Σ ∣ X ) ∝ p ( X ∣ μ , Σ ) p ( μ ) p ( Σ )
推断概率密度,基于后验分布 p ( μ , σ 2 ∣ X ) p(\mu,\sigma^2\vert X) p ( μ , σ 2 ∣ X ) p ( μ , Σ ∣ X ) p(\mu,\Sigma\vert X) p ( μ , Σ ∣ X ) p ( x ∣ X ) p(x\vert X) p ( x ∣ X )
对于一维高斯分布
p ( x ∣ X ) = ∫ p ( x ∣ μ , σ 2 ) p ( μ , σ 2 ∣ X ) d μ d σ 2 p(x\vert X)=\int p(x\vert\mu,\sigma^2)p(\mu,\sigma^2\vert X)d\mu d\sigma^2
p ( x ∣ X ) = ∫ p ( x ∣ μ , σ 2 ) p ( μ , σ 2 ∣ X ) d μ d σ 2
对于多维高斯分布
p ( x ∣ X ) = ∫ p ( x ∣ μ , Σ ) p ( μ , Σ ∣ X ) d μ d Σ p(x\vert X)=\int p(x\vert\mu,\Sigma)p(\mu,\Sigma\vert X)d\mu d\Sigma
p ( x ∣ X ) = ∫ p ( x ∣ μ , Σ ) p ( μ , Σ ∣ X ) d μ d Σ
这一步通常需要通过数值方法或解析近似来计算
基于混合高斯分布的贝叶斯密度估计
混合高斯分布的概率密度函数为
p ( x ∣ Θ ) = ∑ k K π k N ( x ∣ μ k , Σ k ) p(x\vert\Theta)=\sum_k^K\pi_k\mathcal{N}(x\vert\mu_k,\Sigma_k)
p ( x ∣ Θ ) = k ∑ K π k N ( x ∣ μ k , Σ k )
x x x K K K π k \pi_k π k k k k π k ≥ 0 , ∑ k K π k = 1 \pi_k\geq0,\sum_k^K\pi_k=1 π k ≥ 0 , ∑ k K π k = 1 N ( x ∣ μ k , Σ k ) \mathcal{N}(x\vert\mu_k,\Sigma_k) N ( x ∣ μ k , Σ k ) k k k Θ = { π k , μ k , Σ k } k K \Theta=\{\pi_k,\mu_k,\Sigma_k\}_k^K Θ = { π k , μ k , Σ k } k K
步骤
对混合高斯分布的参数集合 Θ \Theta Θ
混合系数 π k \pi_k π k p ( π ) = D i r i c h l e t ( π ∣ α ) p(\pi)=Dirichlet(\pi\vert\alpha) p ( π ) = D i r i c h l e t ( π ∣ α )
均值 μ k \mu_k μ k p ( μ k ) = N ( μ k ∣ m 0 , S 0 ) p(\mu_k)=\mathcal{N}(\mu_k\vert m_0,S_0) p ( μ k ) = N ( μ k ∣ m 0 , S 0 )
协方差矩阵 Σ k \Sigma_k Σ k p ( Σ k ) = W − 1 ( Σ k ∣ v 0 , Ψ 0 ) p(\Sigma_k)=W^{-1}(\Sigma_k\vert v_0,\Psi_0) p ( Σ k ) = W − 1 ( Σ k ∣ v 0 , Ψ 0 )
对于给定数据 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n }
p ( X ∣ Θ ) = ∏ i n ∑ k K π k N ( x i ∣ μ k , Σ k ) p(X\vert\Theta)=\prod_i^n\sum_k^K\pi_k\mathcal{N}(x_i\vert\mu_k,\Sigma_k)
p ( X ∣ Θ ) = i ∏ n k ∑ K π k N ( x i ∣ μ k , Σ k )
根据贝叶斯定理计算参数的后验分布
p ( Θ ∣ X ) ∝ p ( X ∣ Θ ) p ( θ ) p(\Theta\vert X)\propto p(X\vert\Theta)p(\theta)
p ( Θ ∣ X ) ∝ p ( X ∣ Θ ) p ( θ )
基于后验分布,计算新数据点 x ⋆ x^\star x ⋆
p ( x ⋆ ∣ X ) = ∫ p ( x ⋆ ∣ Θ ) p ( Θ ∣ X ) d Θ p(x^\star\vert X)=\int p(x^\star\vert\Theta)p(\Theta\vert X)d\Theta
p ( x ⋆ ∣ X ) = ∫ p ( x ⋆ ∣ Θ ) p ( Θ ∣ X ) d Θ
基于狄利克雷过程混合模型的贝叶斯密度估计
狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)是一种非参数贝叶斯模型,常用于密度估计和聚类分析,结合了狄利克雷过程(Dirichlet Process, DP)和混合模型的特点,能够自动确定数据中的聚类数量,适合处理复杂的数据分布
DPMM的核心是将狄利克雷过程与混合模型结合,假设数据来自无限混合分布,模型设定如下
基分布 G 0 G_0 G 0 θ \theta θ
集中参数 α \alpha α α \alpha α
混合分布 G G G D P ( α , G 0 ) DP(\alpha,G_0) D P ( α , G 0 )
数据生成分布 F ( θ ) F(\theta) F ( θ ) θ \theta θ x x x
目标是估计数据的概率密度函数 p ( x ) p(x) p ( x )
p ( x ) = ∫ p ( x ∣ θ ) p ( θ ) d θ p(x)=\int p(x\vert\theta)p(\theta)d\theta
p ( x ) = ∫ p ( x ∣ θ ) p ( θ ) d θ
p ( x ∣ θ ) p(x\vert\theta) p ( x ∣ θ ) p ( θ ) p(\theta) p ( θ ) DPMM 是非参数模型, p ( θ ) p(\theta) p ( θ )
DPMM 的贝叶斯密度估计步骤如下
初始化
设定超参数 α \alpha α G 0 G_0 G 0
初始化聚类分配和参数
使用 MCMC 方法迭代更新每个数据点的聚类分配,对于数据点 x i x_i x i
计算其分配到现有聚类 k k k
p ( z i = k ∣ z − i , x i ) ∝ n k n − 1 + α p ( x i ∣ θ k ) p(z_i=k\vert z_{-i},x_i)\propto \frac{n_k}{n-1+\alpha}p(x_i\vert\theta_k)
p ( z i = k ∣ z − i , x i ) ∝ n − 1 + α n k p ( x i ∣ θ k )
n k n_k n k k k k z − i z_{-i} z − i p ( x i ∣ θ k ) p(x_i\vert\theta_k) p ( x i ∣ θ k ) x i x_i x i k k k
计算其分配到新聚类的概率
p ( z i = n e w ∣ z − i , x i ) ∝ α n − 1 + α ∫ p ( x i ∣ θ ) d G 0 ( θ ) p(z_i=new\vert z_{-i},x_i)\propto\frac{\alpha}{n-1+\alpha}\int p(x_i\vert\theta)dG_0(\theta)
p ( z i = n e w ∣ z − i , x i ) ∝ n − 1 + α α ∫ p ( x i ∣ θ ) d G 0 ( θ )
对于每个聚类 k k k θ k \theta_k θ k
θ k ∼ p ( θ k ∣ { x i : z i = k } , G 0 ) \theta_k\sim p(\theta_k\vert\{x_i:z_i=k\},G_0)
θ k ∼ p ( θ k ∣ { x i : z i = k } , G 0 )
具体形式取决于基分布 G 0 G_0 G 0 F ( θ ) F(\theta) F ( θ )
重复上述迭代,得到稳定的聚类分配和参数
基于采样结果,估计数据的概率密度函数 p ( x ) p(x) p ( x )
p ( x ) ≈ 1 T ∑ t T p ( x ∣ θ t ) p(x)\approx\frac{1}{T}\sum_t^Tp(x\vert\theta^t)
p ( x ) ≈ T 1 t ∑ T p ( x ∣ θ t )
T T T θ t \theta^t θ t t t t
对于新数据点 x ⋆ x^\star x ⋆
p ( x ⋆ ) ≈ 1 T ∑ t T p ( x ⋆ ∣ θ t ) p(x^\star)\approx\frac{1}{T}\sum_t^Tp(x^\star\vert\theta^t)
p ( x ⋆ ) ≈ T 1 t ∑ T p ( x ⋆ ∣ θ t )
基于高斯过程的贝叶斯密度估计
基于高斯过程(Gaussian Process, GP)的贝叶斯密度估计是一种非参数方法,利用高斯过程的性质来估计未知的概率密度函数,高斯过程是一种强大的工具,能够对函数进行建模,并通过贝叶斯推断提供后验分布
高斯过程是定义在连续域上的无限维高斯分布,完全由其均值函数 m ( x ) m(x) m ( x ) k ( x , x ′ ) k(x,x^\prime) k ( x , x ′ ) { x 1 , … x n } \{x_1,…x_n\} { x 1 , … x n } f ( x 1 ) , … f ( x n ) f(x_1),…f(x_n) f ( x 1 ) , … f ( x n ) m ( x ) = 0 m(x)=0 m ( x ) = 0
f ∼ G P ( m ( x ) , k ( x , x ′ ) ) f\sim \mathcal{GP}(m(x),k(x,x^\prime))
f ∼ G P ( m ( x ) , k ( x , x ′ ) )
密度估计的目标是估计未知的概率密度函数 p ( x ) p(x) p ( x )
给定一组独立同分布的观测数据 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n }
高斯过程是一种随机过程,适合建模函数分布,将 log p ( x ) \log p(x) log p ( x )
log p ( x ) ∼ G P ( m ( x ) , k ( x , x ′ ) ) \log p(x)\sim\mathcal{GP}(m(x),k(x,x^\prime))
log p ( x ) ∼ G P ( m ( x ) , k ( x , x ′ ) )
m ( x ) m(x) m ( x ) k ( x , x ′ ) k(x,x^\prime) k ( x , x ′ )
由于 p ( x ) p(x) p ( x )
L = ∏ i n p ( x i ) log L = ∑ i n log p ( x i ) \mathcal{L}=\prod_i^np(x_i)\\\log\mathcal{L}=\sum_i^n\log p(x_i)
L = i ∏ n p ( x i ) log L = i ∑ n log p ( x i )
后验推断,通过贝叶斯定理,得到后验分布为
p ( log p ( x ) ∣ X ) ∝ p ( X ∣ log p ( x ) ) p ( log p ( x ) ) p(\log p(x)\vert X)\propto p(X\vert \log p(x))p(\log p(x))
p ( log p ( x ) ∣ X ) ∝ p ( X ∣ log p ( x ) ) p ( log p ( x ) )
通过后验分布 p ( log p ( x ) ∣ X ) p(\log p(x)\vert X) p ( log p ( x ) ∣ X ) log p ( x ) \log p(x) log p ( x ) p ( x ) p(x) p ( x )
计算 log p ( x ) \log p(x) log p ( x )
找到使后验分布最大的 log p ( x ) \log p(x) log p ( x )
使用马尔可夫链蒙特卡洛(MCMC)或变分推断等方法从后验分布中采样,得到 log p ( x ) \log p(x) log p ( x )
贝叶斯核密度估计
贝叶斯核密度估计(Bayesian Kernel Density Estimation, BKDE)是一种结合贝叶斯推断和核密度估计的非参数密度估计方法。它通过引入先验分布和后验分布,能够更好地处理小样本数据,并提供对密度估计的不确定性量化
对于给定样本 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n }
f ( x ) = 1 n h ∑ i n K ( x − x i h ) f(x)=\frac{1}{nh}\sum_i^nK(\frac{x-x_i}{h})
f ( x ) = n h 1 i ∑ n K ( h x − x i )
K K K h h h
假设密度函数 f ( x ) f(x) f ( x )
对于给定样本 X : { x 1 , … x n } X:\{x_1,…x_n\} X : { x 1 , … x n }
p ( { x i } ∣ f ) = ∏ i = 1 n f ( x i ) p(\{x_i\}\vert f)=\prod_{i=1}^n f(x_i)
p ( { x i } ∣ f ) = i = 1 ∏ n f ( x i )
根据贝叶斯定理,计算后验分布为
p ( f ∣ { x i } ) ∝ p ( { x i } ∣ f ) p ( f ) p(f\vert\{x_i\})\propto p(\{x_i\}\vert f)p(f)
p ( f ∣ { x i } ) ∝ p ( { x i } ∣ f ) p ( f )
通过后验分布 p ( f ∣ { x i } ) p(f\vert\{x_i\}) p ( f ∣ { x i } ) f ( x ) f(x) f ( x )
计算 f ( x ) f(x) f ( x )
找到使后验分布最大的 f ( x ) f(x) f ( x )
使用马尔可夫链蒙特卡洛(MCMC)或变分推断等方法从后验分布中采样,得到 f ( x ) f(x) f ( x )
优点
贝叶斯方法能够提供参数和概率密度的后验分布,从而量化估计的不确定性
通过选择不同的先验分布和概率密度模型,可以适应不同的应用场景
可以利用领域知识指定先验分布,提高估计的准确性
缺点
贝叶斯方法通常需要复杂的数值计算或近似推断(如变分推断)。
先验分布的选择可能对结果产生影响
方法选择
低维数据:核密度估计(KDE)、直方图法
高维数据:归一化流、变分自编码器(VAE)、自回归模型
简单分布:参数化方法(如高斯分布)
复杂分布:非参数化方法(如KDE)或基于模型的方法(如归一化流)
密度估计的评估
对数似然(Log-Likelihood):评估模型在测试数据上的对数似然值,值越大越好
KL散度(Kullback-Leibler Divergence):衡量估计分布与真实分布之间的差异
可视化:绘制估计的密度函数,直观评估其与真实分布的接近程度
异常检测
机器学习异常检测是一种用于识别数据集中异常或罕见事件的技术。这些异常可能是数据中的错误、欺诈行为、设备故障或其他不寻常的模式
需要用到的知识
ARIMA 模型
ARIMA(AutoRegressive Integrated Moving Average) 是一种经典的时间序列预测模型,广泛应用于时间序列分析和预测。ARIMA 模型结合了自回归(AR)、差分(I)和移动平均(MA)三个部分,能够捕捉时间序列的趋势和季节性
AR 自回归,利用时间序列的历史值预测未来值
y t = c + ϕ 1 y t − 1 + ⋯ + ϕ p y t − p + ϵ t y_t=c+\phi_1y_{t-1}+\cdots+\phi_py_{t-p}+\epsilon_t
y t = c + ϕ 1 y t − 1 + ⋯ + ϕ p y t − p + ϵ t
I 差分,通过差分使时间序列平稳
Δ y t = y t − y t − 1 \Delta y_t=y_t-y_{t-1}
Δ y t = y t − y t − 1
MA 移动平均,利用历史预测误差改进预测
y t = c + ϵ t + θ 1 ϵ t − 1 + ⋯ + θ q ϵ t − q y_t=c+\epsilon_t+\theta_1\epsilon_{t-1}+\cdots+\theta_q\epsilon_{t-q}
y t = c + ϵ t + θ 1 ϵ t − 1 + ⋯ + θ q ϵ t − q
ARIMA 模型的数学表示为 A R I M A ( p , d , q ) \mathrm{ARIMA}(p,d,q) A R I M A ( p , d , q )
p p p
d d d
q q q
LSTM 模型
LSTM(Long Short-Term Memory) 是一种特殊的循环神经网络(RNN),专门设计用于解决长序列数据中的梯度消失和梯度爆炸问题,LSTM 通过引入记忆单元和门控机制(输入门、遗忘门、输出门),能够有效地捕捉时间序列中的长期依赖关系
LSTM 的核心思想是通过引入记忆单元和门控机制,选择性地记住或遗忘信息。LSTM 单元的结构包括以下几个部分
记忆单元,是 LSTM 的核心,用于存储长期信息
遗忘门,决定哪些信息需要从记忆单元中遗忘
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f\cdot[h_{t-1},x_t]+b_f)
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f )
f t f_t f t σ \sigma σ W f W_f W f h t − 1 h_{t-1} h t − 1 x t x_t x t b f b_f b f
输入门,决定哪些新信息需要存储到记忆单元中
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) i_t=\sigma(W_i\cdot[h_{t-1},x_t]+b_i)\\\tilde{C}_t=\tanh(W_C\cdot[h_{t-1},x_t]+b_C)
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C )
i t i_t i t C ~ t \tilde{C}_t C ~ t
更新记忆单元,结合遗忘门和输入门的输出,更新记忆单元状态
C t = f t ⋅ C t − 1 + i t ⋅ C ~ t C_t=f_t\cdot C_{t-1}+i_t\cdot\tilde{C}_t
C t = f t ⋅ C t − 1 + i t ⋅ C ~ t
输出门,决定哪些信息需要输出到隐藏状态
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) h t = o t tanh ( C t ) o_t=\sigma(W_o\cdot[h_{t-1},x_t]+b_o)\\h_t=o_t\tanh(C_t)
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) h t = o t tanh ( C t )
o t o_t o t h t h_t h t
Prophet 模型
Prophet 是由 Facebook 开发的一种时间序列预测工具,适用于具有强烈季节性和趋势的时间序列数据。Prophet 的设计目标是简单易用,同时能够灵活地捕捉时间序列中的趋势、季节性和节假日效应
Prophet 模型将时间序列分解为三个主要部分
趋势:描述时间序列的长期变化趋势,支持两种趋势模型
线性趋势:适用于线性增长或下降的趋势
饱和增长趋势:适用于具有饱和点的增长趋势
季节性:描述时间序列中的周期变化,支持多种季节性模式
年季节性:每年季节性变化
周季节性:每周季节性变化
日季节性:每日季节性变化
节假日效用:描述节假日对时间序列的影响
模型的数学表示为
y ( t ) = g ( t ) + s ( t ) + h ( t ) + ϵ ( t ) y(t)=g(t)+s(t)+h(t)+\epsilon(t)
y ( t ) = g ( t ) + s ( t ) + h ( t ) + ϵ ( t )
y ( t ) y(t) y ( t ) g ( t ) g(t) g ( t ) s ( t ) s(t) s ( t ) h ( t ) h(t) h ( t ) ϵ ( t ) \epsilon(t) ϵ ( t )
STL 模型
STL(Seasonal and Trend decomposition using Loess) 是一种时间序列分解方法,能够将时间序列分解为趋势、季节性和残差三个部分,STL 的核心思想是通过局部加权回归来捕捉时间序列的趋势和季节性,适用于具有强烈季节性和趋势的时间序列数据
STL 模型将时间序列分解为三个部分
趋势,描述时间序列的长期变化趋势,通过局部加权回归拟合趋势
季节性,描述时间序列的周期性变化,通过局部加权回归拟合季节性
残差,描述时间序列中无法被趋势和季节性解释的部分,通过原始时间序列减去趋势和季节性得到
模型的数学表示为
y ( t ) = T ( t ) + S ( t ) + R ( t ) y(t)=T(t)+S(t)+R(t)
y ( t ) = T ( t ) + S ( t ) + R ( t )
y ( t ) y(t) y ( t ) T ( t ) T(t) T ( t ) S ( t ) S(t) S ( t ) R ( t ) R(t) R ( t )
异常检测的类型
点检测:单个数据点与大多数数据明显不同
上下文检测:在特定上下文中,数据点表现异常,但在其他上下文中可能是正常的
集体检测:一组数据点作为一个整体表现出异常行为,尽管单个点可能并不异常
异常检测的评估指标
准确率:正确分类的样本占所有样本数的比例,但是存在局限性
精确率:在模型预测为正类的样本实际为正类的比例
召回率:在所有真正的正类中,被模型预测为正类的比例
F1 分数:精确率和召回率的调和值,用于评估模型的稳健性,用于多分类问题和目标检测等。F1 分数位于 0 到 1 之间
F1 越接近 1 表示模型的性能越好,即模型在精确率和召回率上都表现得很好
F1 越接近 0 表示模型的性能越差
F 1 = 2 × p r e c i s i o n × r e c a l l p r e c i s i o n + r e c a l l F1=\frac{2\times precision\times recall}{precision+recall}
F 1 = p r e c i s i o n + r e c a l l 2 × p r e c i s i o n × r e c a l l
AUC(Area Under Curve):ROC 曲线下的面积,主要用于评估样本不均衡的情况。ROC 曲线以假正例率(FPR)为横轴,真正例率(TPR)为纵轴绘制
假正例率:被错误分类为正样本的负样本占所有实际负样本的比例
真正例率:被正确分类为正样本的正样本占所有实际正样本的比例
取值范围为 0.5 到 1,AUC 值越接近 1,表示模型性能越好,即模型能更好的区分正负样本
混淆矩阵:一个二维矩阵,用于战士模型预测结果与实际标签之间的关系。通过混淆矩阵,可以计算出准确率,精确率和召回率等指标,并且诊断模型问题。混淆矩阵一般包括以下四个元素
真正例(True Positives, TP):模型正确地将正类预测为正类的数量
假正例(False Positives, FP):模型错误地将负类预测为正类的数量
假负例(False Negatives, FN):模型错误地将正类预测为负类的数量
真负例(True Negatives, TN):模型正确地将负类预测为负类的数量
统计方法异常检测
单变量高斯分布异常检测方法
高斯分布是连续概率分布,其概率密度函数为
p ( x ; μ , σ 2 ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) p(x;\mu,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(x-\mu)^2}{2\sigma^2})
p ( x ; μ , σ 2 ) = 2 π σ 1 exp ( − 2 σ 2 ( x − μ ) 2 )
选择一个阈值 ϵ \epsilon ϵ p ( x ) < ϵ p(x)<\epsilon p ( x ) < ϵ
多变量高斯分布异常检测方法
多变量高斯分布是连续概率分布,其概率密度函数如下,其中 n n n
p ( x ; μ , Σ ) = 1 ( 2 π ) n / 2 ∣ Σ ∣ 1 / 2 exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x;\mu,\Sigma)=\frac{1}{(2\pi)^{n/2}\vert\Sigma\vert^{1/2}}\exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))
p ( x ; μ , Σ ) = ( 2 π ) n / 2 ∣ Σ ∣ 1 / 2 1 exp ( − 2 1 ( x − μ ) T Σ − 1 ( x − μ ) )
选择一个阈值 ϵ \epsilon ϵ p ( x ) < ϵ p(x)<\epsilon p ( x ) < ϵ
箱线图异常检测方法
计算数据的第一四分位数 Q 1 Q_1 Q 1 Q 2 Q_2 Q 2 Q 3 Q_3 Q 3
计算四分距 I Q R = Q 3 − Q 1 IQR=Q_3-Q_1 I Q R = Q 3 − Q 1
确定异常值的阈值 [ Q 1 − 1.5 I Q R , Q 3 + 1.5 I Q R ] [Q_1-1.5IQR,Q_3+1.5IQR] [ Q 1 − 1 . 5 I Q R , Q 3 + 1 . 5 I Q R ]
任何不在范围内的数据点都被视作异常值
Z-Score 异常检测方法
计算数据集的均值和标准差
μ = 1 n ∑ i n x i σ = 1 n ∑ i n ( x i − μ ) 2 \mu=\frac{1}{n}\sum_i^nx_i\\\sigma=\sqrt{\frac{1}{n}\sum_i^n(x_i-\mu)^2}
μ = n 1 i ∑ n x i σ = n 1 i ∑ n ( x i − μ ) 2
对于每个数据点 x x x
z = x − μ σ z=\frac{x-\mu}{\sigma}
z = σ x − μ
一般将阈值 ϵ \epsilon ϵ
如果 ∣ z ∣ > ϵ \vert z\vert>\epsilon ∣ z ∣ > ϵ
基于距离的方法
K 近邻异常检测方法
选择最近邻居的数量 k k k
较小的 k k k
较大的 k k k
对于每个数据点,计算其与所有其他数据点的距离
对于每个数据点,找到其最近邻的 k k k
计算异常得分,有下面两中方法
使用与第 k k k
使用与 k k k
设定阈值,如果异常得分高于阈值,则被视作异常点
局部异常因子异常检测方法
选择最近邻居的数量 k k k
较小的 k k k
较大的 k k k
对每个数据点 x x x k k k k d ( x ) kd(x) k d ( x )
对每个数据点 x x x
r d k ( x , y ) = max ( k d ( x ) , d ( x , y ) ) rd_k(x,y)=\max(kd(x),d(x,y))
r d k ( x , y ) = max ( k d ( x ) , d ( x , y ) )
d ( x , y ) d(x,y) d ( x , y ) x x x y y y
对每个数据点 x x x
L R D k ( x ) = 1 ( ∑ y ∈ N k ( x ) r d k ( x , y ) ∣ N k ( x ) ∣ ) LRD_k(x)=\frac{1}{(\frac{\sum_{y\in N_k(x)}rd_k(x,y)}{\vert N_k(x)\vert})}
L R D k ( x ) = ( ∣ N k ( x ) ∣ ∑ y ∈ N k ( x ) r d k ( x , y ) ) 1
N k ( x ) N_k(x) N k ( x ) x x x
对于数据点 x x x
L O F k ( x ) ∑ y ∈ N k ( x ) L R D k ( y ) L R D k ( x ) ∣ N k ( x ) ∣ LOF_k(x)\frac{\sum_{y\in N_k(x)}\frac{LRD_k(y)}{LRD_k(x)}}{\vert N_k(x)\vert}
L O F k ( x ) ∣ N k ( x ) ∣ ∑ y ∈ N k ( x ) L R D k ( x ) L R D k ( y )
如果 L O F k ( x ) ≈ 1 LOF_k(x)\approx1 L O F k ( x ) ≈ 1
如果 L O F k ( x ) > 1 LOF_k(x)>1 L O F k ( x ) > 1
设定阈值 ϵ \epsilon ϵ L O F k ( x ) > ϵ LOF_k(x)>\epsilon L O F k ( x ) > ϵ
基于 PCA 异常检测方法
对输入的高维数据进行标准化处理,使每个特征的均值为 0,方差为 1
计算数据的协方差矩阵,并对其进行特征值分解
选择前 k k k
将降维后的数据重构回原始空间
计算原始数据与重构数据之间的误差
设定阈值 ϵ \epsilon ϵ
基于聚类的方法
K-means 聚类异常检测方法
选择最近邻居的数量 k k k
较小的 k k k
较大的 k k k
使用 K-means 算法将数据划分为 k k k
对于每个数据点,计算其与所属簇中心的距离
根据距离分布设定阈值 ϵ \epsilon ϵ ϵ \epsilon ϵ
DBSCAN 异常检测方法
初始化:选择邻域半径 ϵ \epsilon ϵ M i n P t s MinPts M i n P t s
对于每个点,计算其在 ϵ \epsilon ϵ ≥ M i n P t s \geq MinPts ≥ M i n P t s
从核心点出发,将所有密度可达的点归为一个簇
未被分配到任何簇的点标记为噪声点也就是异常点
基于密度的方法
孤立森林异常检测方法
建立孤立树
随机选择一个特征和一个分割值
递归地将数据划分为左右两个子空间,直到数据点被完全隔离或者树达到最大深度
构建多棵孤立树,形成孤立森林
对于每个数据点,计算其在所有树种地平均路径长度
根据路径长度计算异常分数为 s ( x , n ) = 2 − E ( h ( x ) ) c ( n ) s(x,n)=2^{-\frac{E(h(x))}{c(n)}} s ( x , n ) = 2 − c ( n ) E ( h ( x ) )
E ( h ( x ) ) E(h(x)) E ( h ( x ) ) x x x c ( n ) c(n) c ( n )
判断异常点
异常分数接近 1 的点被认为是异常点
异常分数接近 0 的点被认为是正常点
One-Class SVM 异常检测方法
输入未标注的数据,假设大部分数据都是正常的
使用核函数将数据映射到高维空间
在高维空间中寻找一个超平面,使得大部分数据点位于该超平面
计算每个数据点到决策边界的距离,距离越远异常分数越高
设定阈值 ϵ \epsilon ϵ
基于深度学习的方法
自编码器异常检测方法
输入未标注的数据集,假设大部分数据都是正常的
使用正常数据训练自编码器,使其能够较好的重构正常数据
编码器:将输入数据压缩为低维表示
解码器:从低维表示重构原始数据
对每个数据点,计算其输入与重构输出之间的误差
正常数据通常能够被自编码器较好地重构,因此重构误差较低
异常数据由于与训练数据的分布不同,重构误差较高
设定阈值 ϵ \epsilon ϵ
生成对抗网络异常检测方法
输入未标注的数据集,假设大部分数据是正常的
使用正常数据训练 GAN,使生成器能够生成与正常数据相似的样本
生成器:生成与真实数据相似的假数据
判别器:区分真实数据与生成器生成的假数据
对于每个数据点,计算其异常分数
训练 GAN 使其能够生成正常数据的分布。
异常数据由于与正常数据的分布不同,判别器会将其识别为异常
生成器无法很好地重构异常数据
设定阈值 ϵ \epsilon ϵ
变分自编码器异常检测方法
输入未标注的数据集,假设大部分数据是正常的
使用正常数据训练 VAE,使其能够较好地重构正常数据
编码器:将输入数据映射到潜在空间的均值和方差
解码器:从潜在空间采样并重构原始数据
对每个数据点,计算其输入与重构输出之间的误差
正常的数据一般能被 VAE 较好地重构,重构误差较低
异常数据由于与训练数据的分布不同,重构误差较高
设定阈值 ϵ \epsilon ϵ
时间序列异常检测
ARIMA 模型异常检测方法
输入时间序列数据
检查时间序列是否平稳,如果不平稳就进行差分
选择合适地 ARIMA 参数来训练模型
使用训练好的模型预测时间序列地未来值
计算预测值与实际值之间的残差
设定阈值 ϵ \epsilon ϵ
LSTM 长短期记忆网络异常检测方法
输入时间序列数据
将数据划分为训练集和测试集
对数据进行标准化或归一化
将时间序列数据转换为监督学习问题
构建 LSTM 模型,使用训练集训练模型
使用训练好的模型预测时间序列的未来值
计算预测值与实际值之间的误差
设定阈值 ϵ \epsilon ϵ
Prophet 异常检测方法
输入时间序列数据,包含两列数据,时间戳 d s ds d s y y y
使用 Prophet 拟合时间序列数据,捕捉趋势和季节性
使用训练好的模型预测时间序列的未来值
计算预测值与实际值之间的残差
设定阈值 ϵ \epsilon ϵ
STL 异常检测方法
输入时间序列数据
使用 STL 方法将时间序列分解为趋势,季节性和残差
计算残差项的统计特性
根据残差的分布,设定异常检测的阈值
将残差超过阈值的点标记为异常点
异常检测方法的对比选择
方法
适用场景
优点
缺点
高斯分布
单变量数据,正态分布数据,多变量数据
简单易用,计算效率高,无需标注数据
对非正态分布数据效果差
箱线图
单变量数据
简单直观,适合初步分析,无需标注数据
仅适用于单变量数据,对多变量数据无效
Z-Score
单变量数据,正态分布数据
简单易用,计算效率高
对非正态分布数据效果差
K 近邻
低维数据,点异常
简单直观,适合局部异常检测
对高维数据效果差,计算复杂度高
局部异常因子
低维数据,局部异常
能够检测局部异常,适合密度不均匀的数据
对高维数据效果差,计算复杂度高
K-means 聚类
低维数据,集体异常
简单易用,适合聚类分析
对异常点敏感,需要预先指定簇数量
DBSCAN
低维数据,点异常
能够识别任意形状的簇
对参数敏感,不适用于高维数据
孤立森林
高维数据,点异常
高效,无需标注数据
对局部异常检测效果差
One-Class SVM
高维数据,低比例异常
对低比例异常敏感
对参数敏感,训练时间较长
自编码器
高维数据,非线性数据
能够捕捉复杂的数据分布
训练时间较长,对参数敏感
生成对抗网络
图像数据,复杂分布数据
能够生成高质量的数据
训练不稳定,计算复杂度高
变分自编码器
高维数据,非线性数据
能够捕捉概率分布
训练时间较长,对参数敏感
ARIMA 模型
时间序列数据,点异常
简单易用,适合线性时间序列
对非线性关系建模能力有限
LSTM 长短期记忆网络
时间序列数据,上下文异常
能够捕捉长期依赖关系
训练时间较长,需要大量数据
Prophet
时间序列数据,季节性和趋势
自动捕捉趋势和季节性,支持节假日效应
对非线性关系建模能力有限
STL
时间序列数据,季节性和趋势
能够分解时间序列,适合季节性和趋势分析
对非线性关系建模能力有限