一些定义
对于一个函数 F:Rn→Rm 是一个将欧式 n 维空间的函数,该函数由 m 个实函数构成, y1(x1,…,xn),…,ym(x1,…,xn)
Jacobian 矩阵
函数 F 的偏导数组成一个 m 行 n 列的矩阵,就是 Jacobian 矩阵
JF(x1,...,xn)=⎣⎢⎡∂x1∂y1...∂x1∂ym.........∂xn∂y1...∂xn∂ym⎦⎥⎤
也可以表示为 ∂(x1,…,xn)∂(y1,…,ym)。如果对于一个 p∈Rn ,函数 F 在 p 点可微,则 F 在这一点的导数由 JF(p) 给出
Hessian 矩阵
如果 F 的所有二阶导数都存在,则 F 的 Hessian 矩阵为
HF(x1,...,xn)=⎣⎢⎢⎡∂x12∂2F...∂xn∂x1∂2F.........∂x1∂xn∂2F...∂xn2∂2F⎦⎥⎥⎤
可以利用二阶导数的值判断梯度下降的速度
二次规划 QP
二次规划(QP, Quadratic Programming)定义:目标函数为二次函数,约束条件为线性约束,属于最简单的一种非线性规划。说白了就是一种对于控制理论的一种优化,约束条件和线性规划问题的约束条件一样,都是线性等式或线性不等式。即
⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧min21xTGx+HTxaiTx≤biaiTx=bii∈I={1...m}i∈ε={m+1,...m+l}
其中 ε 表示等式约束的指标集, I 表示不等式约束的指标集
一般二次规划问题可以分成以下几类
- 凸二次规划问题:G半正定,问题有全局解
- 严格凸二次规划问题:G正定,问题有唯一全局解
- 一般二次规划问题:G不定,问题有稳定点或局部解
Language 乘数法
求函数 f(x,y) 在条件 ϕ(x,y)=0 约束下的可能极值点,构造 language 函数,即
L(x,y,λ)=f(x,y)+λϕ(x.y)
求偏导得
Lx=fx+λϕxLy=fy+λϕyLλ=ϕ
令上式均为 0 可以解出 x,y,λ 的值,其中的 x,y 就是可能的极值点的坐标。对于多个约束条件可以引入多个 λ ,求解与上述一致
KKT 条件
-
KKT 条件核心思想
对于一个不等式约束的方程
最小化问题
minf(x)g(x)≤0
最大化问题
maxf(x)g(x)≥0
首先先不考虑约束 g(x),直接对 f(x) 求导,最终能得到一个最优值 $x^\star $,接下来把最优值带入到约束中,会有三种情况
-
满足 g(x) 约束但是 g(x)=0
正好满足约束,最优解为 $x^\star $,但是实际上这个约束并没有起作用,问题实际上转化为无约束优化问题,但是同样的构造 Language 函数
L(x,λ)=f(x)+λg(x)
由于此时约束无用,也就可以把 λ=0,最终实际上是把约束条件给转为 0,也就没有约束
-
g(x)=0
最优解 $x^\star $ 使得约束为等号,正好在约束的边界上,此时就是 Language 乘数法所能解决的,构造函数
L(x,λ)=f(x)+λg(x)
-
不满足 g(x) 的约束
显然此时不满足约束,结果被舍弃,最终的结果一定在满足约束条件的范围内
最终满足条件的两种情况中的 Language 方程可以统一为 λg(x⋆)=0,这就是 KKT 条件的精髓
-
公式
首先给出一个仅含有不等式约束
{minf(x)g(x)≤0⇒KKT⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧▽f(x⋆)+λ▽g(x⋆)=0λg(x⋆)=0λ≥0g(x⋆)≤0
依旧需要引入 Language 函数
L(x,λ)=f(x)+λg(x)
对于上述 KKT 条件中
- 1式:对拉格朗日函数求梯度(若X一维就是求导),其中,下三角表示梯度
- 2式:核心公式 λ=0 或 g(x⋆)=0,但是此处要求不能同时为 0
- 3式:Language 乘子 λ 必须是正的
- 4式:原约束
上述中 1,2式可以求出最优的 $x^\star ,\lambda^\star $,但是由于 2 式需要两种情况,所以存在多个最优解,而3,4 式主要是验证先前的结果是否满足条件。一般问题的解析分为两种情况
- λ=0 计算 $x^\star $ 并且验证 4式条件
- λ=0 计算 $x^\star ,\lambda^\star $,并且验证3,4式条件
将不等式与等式条件推广,可以得到多个约束的公式
minf(x)gi(x)≤0,i∈[1,m]⇒m个不等式约束hj(x)=0,j∈[1,n]⇒n个等式约束
对应的 Language 函数为
L(x,{λi},{μj})=f(x)+i=1∑mλigi(x)+j=1∑nμjhj(x)
其中的参数 {λi},{μj} 表示多个约束
对应的 KKT 条件为
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧▽f(x⋆)+i=1∑mλi▽gi(x⋆)+j=1∑nμj▽hj(x⋆)=0λigi(x⋆)=0,i∈[1,m]λi≥0,i∈[1,m]g(x⋆)≤0,i∈[1,m]hj(x⋆)=0,j∈[1,n]
这个实质上是几个不等式与等式约束,与之前的解法一致,利用等式求解,用不等式验证。由于上述公式中有 m 个 Language 乘子,每个都有两种情况,所以就是 2m 种。但是能解出最优解的一定是等式,而不等式是排除解的方法。
-
充分性必要性说明
KKT 条件是判断某点是极值点的必要条件,不是充分条件。KKT 的解不一定是最优解,但是最优解一定满足 KKT 条件。
对于 凸规划,KKT 条件是充要条件,只要满足 KKT 条件,则一定极值点,并且得到的一定是全局最优解。
凸规划是指目标函数为凸函数,不等式约束函数也为凸函数,等式约束函数是仿射的(理解为线性的也可以)。对于凹函数实际上就是凸函数加负号,本质是一样的。
-
Min/Max与 ≤0/≥0 的规定
也就是
- 如果目标为最小化Min问题,那么不等式约束就要整理为 ≤0 形式
- 如果目标为最小化Max问题,那么不等式约束就要整理为 ≥0 形式
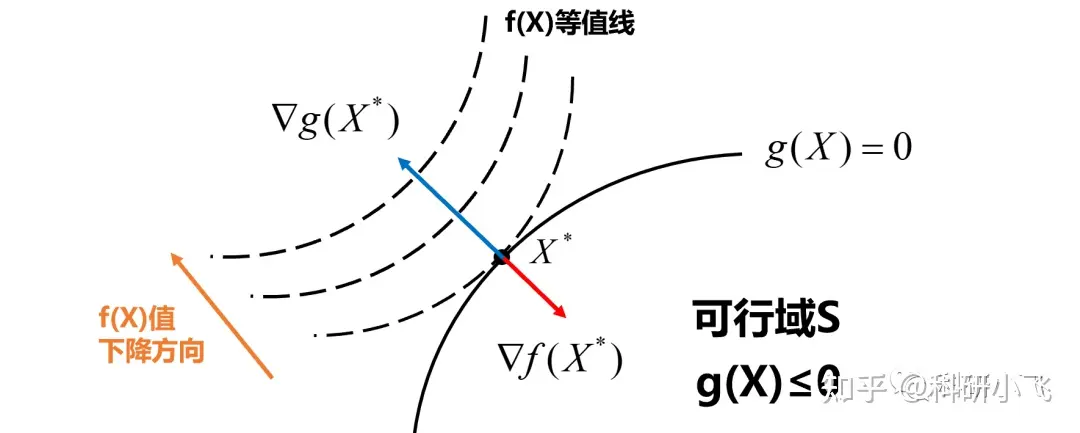
由于梯度指的是函数下降的方向,所以垂直于等值线。如图在最优解点, f(x⋆) 和 g(x⋆) 梯度方向共线方向相反,这在数学上写法是
−▽f(x⋆)=λ▽g(x⋆)⇓▽f(x⋆)+λ▽g(x⋆)=0
这实际上就是 KKT 条件的第一个等式,而且由于 g(x) 的梯度方向与 f(x) 负梯度方向相同,这就是KKT条件中的一个条件 λ≥0
但是如果对于最大化问题,约束为 g(x)≤0,此时 g(x⋆) 梯度方向与 f(x⋆) 方向相同,所以上述公式就变为 两项做差 或者 λ<0,实际上结果是没有变化的。
对于两个约束来说
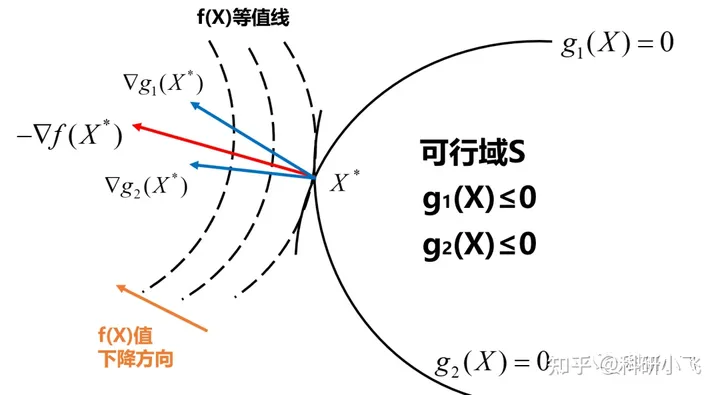
那就可以表示为向量相加的结果
−▽f(x⋆)=λ1▽g1(x⋆)+λ2▽g2(x⋆)⇓▽f(x⋆)+λ1▽g1(x⋆)+λ2▽g2(x⋆)=0
这也是 KKT 条件的第一个等式
-
正则性条件/约束规范说明
KKT 条件对于目标函数和约束函数也是有要求的,目标函数和约束函数均可为连续可微函数。
正则性条件/约束规范:以下方程组是线性独立的
▽gi(x⋆):i∈I(x⋆)∪▽hj(x⋆):j∈[1,n]
其中 I(x⋆) 指的是起作用约束的集合
下面的KKT,以后再来探索吧
KKT条件,原来如此简单 | 理论+算例实践 - 知乎 (zhihu.com)
最优化(3)KKT条件为什么用不了了_哔哩哔哩_bilibili
QP——等式约束
一般形式
⎩⎪⎨⎪⎧min 21xTGx+hTxATx=b
其中 b∈Rm,A∈Rn×m,rank(A)=m,n>m
其中 G 是由二阶导构成的 hessian 矩阵
求解方法
变量消去法
步骤
- 将 x 分成基本变量 xB与非基本变量 xN 两部分,利用等式约束将基本变量用非基本变量表示出来
- 再将基本变量带入目标函数,从而消去基本变量,把问题化为一个关于非基本变量的无约束最优化问题
- 最后求解无约束最优化问题的方法解之
具体步骤
将 A 分块,使其包含一个 m×m 非奇异矩阵 AB,x,h 做对应的分块
x=[xBxN],A=[ABAN],G=[GBBGNBGBNGNN],h=[hBhN]
所以等式约束 ATx=b 转化为
[ABAN]T[xBxN]=b→ABxB+ANxN=b
更换以下变量位置
xB=AB−1b−AB−1ANxN
则
x=[xBxN]=[AB−1b−AB−1ANxNxN]=[AB−10]+[−AB−1ANI]xN=x0+ZxN
转变为一个 x=x0+ZxN 的形式,将其带入目标函数,消去基本变量,问题变为一个关于非基本变量的无约束最优化问题
将上式带入目标函数中
min f(x)=21xTGx+hTx=21(x0+ZxN)TG(x0+ZxN)+hT(x0+ZxN)
其中除了 xN 其他都是已知的常数项,由于常数项不影响优化结果,所以优化过程中省略常数项。另外找到所有的 xNTPxN 和 QxN 的形式的项,可得如下形式:
⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧min f(x)PQ=21xNTPxN+21ZTxNTGx0+21x0TGZxN+21x0TGx0+QxN=ZTGZ=x0TGZ+hTZ
求最值实际上求 f(x)˙=0 即可,即
f(x)˙=21ZT(G+GT)ZxN+21ZT(G+GT)x0+QT=0
如果想要有唯一最优解,必须满足 ZT(G+GT)Z 正定
Language 法
步骤
等式约束的二次规划的 Lagrange 函数为
L(x,λ)=21xTGx+hTx+λ(ATx−b)
其中 λ 称为 Lagrange 乘数,正负都有可能。Lagrange乘数法将原本的约束优化问题转换成等价的无约束优化问题,即
x,λmin L(x,λ)
计算 L 对 x 和 λ 的偏导,并且设为零,可得最优解的必要条件
⎩⎪⎪⎪⎨⎪⎪⎪⎧∂x∂L∂λ∂L=Gx+h+λ=0=ATx−b=0定常方程式约束条件
表示为方程组
[GATA0][xλ]=[−hb]
求解之后得到最优解
方法对比
变量消去法其实是转化成了一个 n - m 维的问题,也就是说求解 n − m 个方程组就能解决这个问题。而 Lagrange法是将其转化成一个 n + m 维的问题,即 n 个变量, m 个乘子。所以可见,如果模型维度太大,建议使用变量消去法,很直观,使用非基数来表示基变量,但是由于需要计算 AB−1 ,当 AB 接近奇异时会导致误差很大
QP——不等式约束
一个标准的等式不等式联合约束 QP 原模型
min21xTHx+gTxaiTx=bi,i∈EhjTx≤tj,j∈I
i∈E 表示的是 m 个等式约束集合, i∈I 表示的是 n 个不等式约束集合。对于不等式约束下的 QP 问题有多种求解方法
并且由
f(x)=21xTHx+gTxgi(x)=axi−bihi(x)=hiTu−ti
求解方法
Lagrange乘数法与KKT条件
一般形式
{min f(x)˙g(x)≤0
其中约束不等式 g(x)≤0 称为原始可行性,可以定义可行域
K={x∈Rn∣g(x)≤0}
假设 $x^\star $ 为满足约束条件的最佳解,分两种情况讨论
-
g(x⋆)<0 最佳解位于 K 的内部,称为内部解(interior solution),这时约束条件是无效的 (inactive)
必要条件
约束条件无效的情况下, g(x) 不起作用,约束优化问题退化为无约束优化问题, 因此驻点 $x^\star $ 满足 ∇f=0且λ=0
-
g(x⋆)=0 最佳解位于 K 的边界,称为边界解(boundarysolution),这时约束条件是有效的 (active)
必要条件
在约束条件有效的情形下,约束不等式变成等式 g(x)=0,这与前述 Lagrange 乘数法的情况相同,可以证明驻点 $x^\star $ 发生于 ∇f∈span∇g,其中 span 是生成子空间。即 ∃λ→∇f=−λ∇g,并且这里的正负号有意义。因此我们希望最小化 f,梯度 ∇f (函数 f 在点 x 的最陡上升方向),应该指向可行域 K 的内部,因为最优解是在边界取到的,但同时 ∇g 指向 K 的外部( g(x)>0 )的区域,因为约束是 g(x)≤0,因此 λ≥0 ,称为对偶可行性
因此,不论是内部解或者边界解, λg(x)=0 恒成立,称为互补松弛性。综合上述两种情况,最佳解的必要条件包括 Lagrange 函数 L(x,λ) 的定常方程式,原始可行性,对偶可行性,互补松弛性
⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧∇xL=∇f+λ∇g=0g(x)≤0λ≥0λg(x)=0
这些条件合称为Karush-Kuhn-Tucker (KKT)条件。如果我们要最大化 f(x) 且受限于 g(x)≤0,那么对偶可行性要改成 λ≤0
标准约束优化
考虑标准优化问题,即非线性规则
⎩⎪⎪⎨⎪⎪⎧min f(x)gj(x)=0hk(x)≤0j=1…mk=1…p
定义 Lagrange 函数
L(x,{λj},{uk})=f(x)+j=1∑mλjgj(x)+k=1∑pukhk(x)
其中 λj 是对应 gj(x)=0 的 Lagrange 乘数, uk 是对应 hk(x)≤0 的 Lagrange 乘数,或称为 KKT乘数。KKT条件包括定常方程式,原始可行性,对偶可行性,互补松弛性
⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧∇xL=0g(x)=0hk(x)≤0uk≥0ukhk(x)=0j=1...mk=1...p
栗子
-
对于这个问题
⎩⎪⎪⎨⎪⎪⎧min x12+x22x1+x2=1x2≤α
其中 (x1,x2)∈R2 , α 为实数,写出 Lagrange 函数
L(x1,x2,λ,μ)=x12+x22+λ(1−x1−x2)+μ(x2−α)
KKT 方程组
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧∂xi∂L=0x1+x2=1x2−α≤0u≥0u(x2−α)=0i=1,2
求偏导为
⎩⎪⎪⎪⎨⎪⎪⎪⎧∂x1∂L∂x2∂L=2x1−λ=0=2x2−λ+μ=0
解得
⎩⎪⎪⎪⎨⎪⎪⎪⎧x1x2=2λ=2λ−μ
带入约束等式,得
x1+x2=λ−2μ=1
合并结果为
⎩⎪⎪⎨⎪⎪⎧x1x2=4μ+21=−4μ+21
加入约束不等式
−4μ+21≤α⇒μ≥2−4α
分3种情况讨论
- α>21 则对于 u=0>2−4α 满足所有的KKT条件,约束不等式无效, x1⋆=x2⋆=21 是内部解,目标函数的极小值为 21
- α=21 则 u=0=2−4α 满足所有的KKT条件, x1⋆=x2⋆=21 是内部解,因为 x2⋆=α,即满足 x2⋆−α=0
- α<21 这时约束不等式是有效的,u=2−4α>0,则 x1⋆=1−α 且 x2⋆=alpha,目标函数的极小值为 (1−α)2+α2
-
标准约束优化
⎩⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎧min f(x)=−2x12−x12x12+x22−x=0−x1+x2≥0x1≥0,x2≥0
试验证 x⋆=(1,1)T 为KKT点,并求出问题的 KKT 对
⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧f(x)g(x)h1(x)h2(x)h3(x)=−2x12−x12=x12+x22−2=x1−x2=−x1=−x2
求梯度,得到
∇f(x)=[−4x1−2x2],∇g(x)=[2x12x2]∇h1(x)=[1−1],∇h2(x)=[−10],∇h3(x)=[0−1]
把 x⋆=(1,1)T 带入以上的式子,由KKT条件得
{−4+2λ+μ1−μ2=0−2+2λ−μ1+μ3=0
由于
{μ2h2(x)=0μ3h3(x)=0→{μ2⋆=0μ3⋆=0⇒{−4+2λ+μ1=0−2+2λ−μ1=0⇒{λ⋆=1.5μ1⋆=1
这表明 $x^\star $ 是KKT点, (x⋆,(λ⋆,μ⋆))是KKT对,其中
{λ=1.5μ⋆=[100]T
内点法
基本思想
将优化问题的可行域视为一个凸集,并通过一个内点序列来逐步接近最优解,而不是像单纯形法那样在顶点上进行搜索。在内点法中,每个内点表示一个可行解,而算法将不断迭代,使内点逐渐接近最优解。通过在内点附近构造一个特定的路径,内点法可以在有限的步数内找到最优解
步骤
⎩⎪⎪⎨⎪⎪⎧min f(x)gj(x)=0h(x)≤0j=1…mk=1…p
写出对应的 Lagrange 函数
L(x,{λj},{uk})=f(x)+j=1∑mλjgj(x)+k=1∑pukhk(x)
对应的 KKT 条件为
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧Gx+c−AεTλ−AITμ=0aiTx≤biaiTx=biμi≥0μi(aiTx−bi)=0i∈Ii∈εi∈Ii∈I
其中
{Aε={aiT}i∈ε∈Rm1×nAI={aiT}i∈I∈Rm2×n
相当于把两组不同的约束做了拆分。
可以添加一组松弛变量
⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧Gx+c−AεTλ−AITμ=0Aε−bε=0AIx−bI−y=0(μ,y)≥0μiyi=0i∈Ii∈I
这里的 bε,bI 和之前的意思类似,就是根据不同的指标集把b区分成不同的两个列向量
写成函数的形式
F(x,y,λ,μ)=⎣⎢⎢⎢⎡Gx+c−AεTλ−AITμAε−bεAIx−bI−yUY1⎦⎥⎥⎥⎤
其中 U,Y∈Rn2×n2,最终的目的就是 F(x,y,λ,μ)=0,再加上 (μ,y)≥0 就是完整的KKT条件了
可以适当添加一个松弛条件,即解方程
F(x,y,λ,μ)=⎣⎢⎢⎢⎡000τ1⎦⎥⎥⎥⎤
由于要求 (μ,y)>0 ,所以不断缩小 τ→0,就是最终的解
求解这个方程的解就需要求解 jacobi 矩阵
⎣⎢⎢⎢⎡GAεAI000−IU−AεT000−AIT00Y⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡ΔxΔyΔλΔμ⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡−rd−rp−ry−UY1+σβ1⎦⎥⎥⎥⎤
其中
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧β=m2yTλσ∈(0,1)作为一个系数rd=Gx+c−AεTλ−AITμrp=Aε−bεry=AIx−bI−y
积极集法
积极集法就是一堆active的约束条件的集合。active的定义是:给定任意一个在可行域内的点x,即可行解,在x下,不等式约束条件取到等号。即在 $x=x^\star $ 这个可行解下 g(x)≥0⇒g(x⋆)=0
active set 里面包括了所有的等式约束以及一些可以取到等号的不等式约束
方法核心思想:如果我们知道最优点处的active的约束,就可以把那些inactive的约束条件都剔除掉,将带不等式约束的二次规划问题转变为等式约束的二次规划问题,降低搜索解的复杂度。但其有一个前提,给定的迭代的起始点要是一个可行解。
算法流程
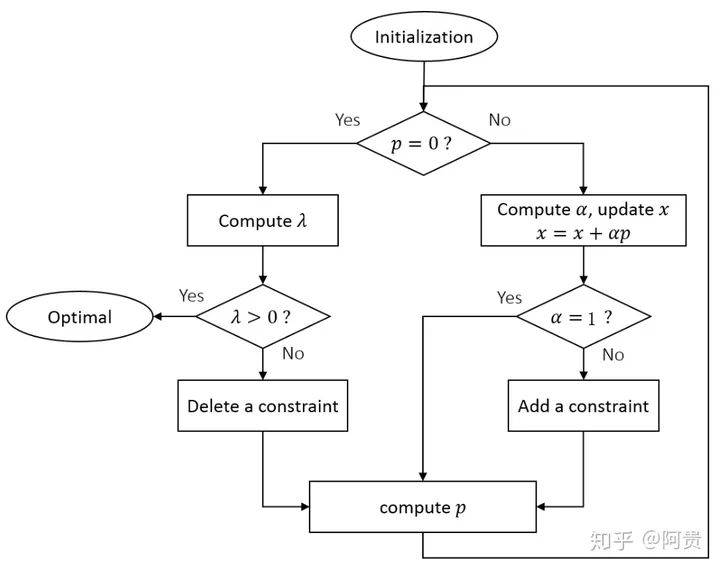
图中的p是一个当前迭代点的改进方向,每次迭代,我们把从约束条件集合中拿出来的约束条件假设为active约束条件进行尝试,加入的集合称为工作集,这个集合是随着迭代不断变化的。如果第k次的迭代点 xk 不是当前工作集下的最优点,就通过求解当前工作集下的active约束的QP问题来得到一个最优解x,工作集也有可能为空,即求解原QP问题在无约束条件下的最优解,方向 p=x⋆−xk, xk 朝着p移动可以使得QP目标函数值下降,求出方向p后,如果 xk+1=xk+p 满足原QP里的所有约束,就将这个点作为下一个迭代点 ,如果不满足所有约束(朝p走的这一步可能会走的太大了,走出了可行域),则将步子迈的小一点,来使得所有约束条件满足,即给p加一个系数α,系数小于1。即
xk+1=xk+αp {α=10<α<1满足所有约束有约束不满足
公式
假设求解的 QP 问题为
xminf(x)=21xTGx+xTcAix≥b,i∈I
则在工作集 W 的积极集约束满足的条件下的第 k 次迭代下的最优点为
f(x⋆)=f(xk+p)=21(xk+p)TG(xk+p)+(xk+p)Tc=21pTGp+(Gxk+c)Tp+21xkTGxk+xkcsubject to Ai(xk+p)=bi,i∈W
上式中与 p 无关的变量可以看作是常数,不需要管?也就是优化下列式子
min21pTGp+(Gx+c)TpAip=0,i∈W
解出 p 后,下一个迭代点
xk+1=xk+αp
然后就是考虑工作集之外的约束条件的满足情况,因为工作集内的约束已经考虑过,所有条件满足。首先判断 Aip 符号,若 Aip≥0 则可以知道它满足所有约束,因为
Aixk+1=Ai(xk+αp)≥b,α>0
如果 Aip≤0 则为了满足 Ai(xk+αp)≥b 条件,可以得到
α≤Aipb−Aixk
所以可得
α=min(1,minAipb−Aixk)
就是沿着工作集下的active的可行域边界走,如果某次迭代没有约束条件(工作集为空),就朝着无约束下最优点在可行域内走,走到新的边界,然后将新的边界约束加入到工作集中,再沿着新的边界走,不断迭代,直到找到最优解。找到最优解的条件是 xk满足KKT条件,即所有的 λ 都大于0,则说明当前迭代点为最优解,退出迭代
其中求 λ 的公式为
∂f(x)=Gx+cAix≥b,i∈I
看作等式约束时,可以使用 lagrange 乘子法
∂L=Gx+c−λAi=0,i∈W
则可以得到
Aiλ=Gx+c
Active set method介绍 - 知乎 (zhihu.com)
Karush-Kuhn-Tucker (KKT)条件 - 知乎 (zhihu.com)
优化理论——二次规划 - 知乎 (zhihu.com)
KKT条件,原来如此简单 | 理论+算例实践 - 知乎 (zhihu.com)
